When Languages Disagree: Self-Evolving Multilingual LLM Judges
Pith reviewed 2026-06-27 19:59 UTC · model grok-4.3
The pith
Multilingual inconsistencies in LLM judgments contain complementary signals that self-reflection can turn into more accurate and consistent evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
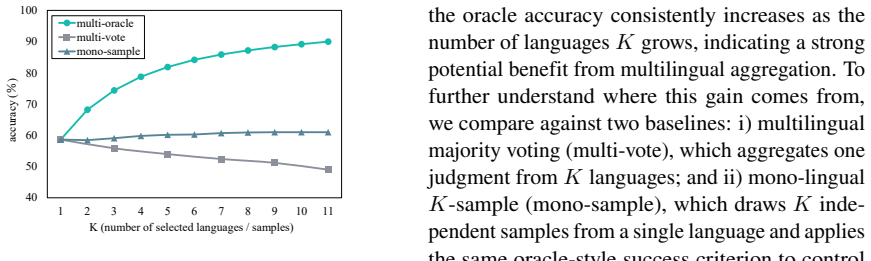
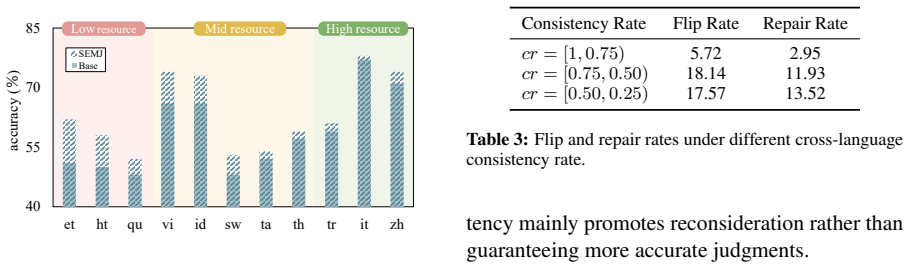
The paper claims that multilingual inconsistency supplies complementary evaluation signals. By constructing multilingual variants of each input, collecting independent judgments and rationales, and feeding inconsistent outputs back for self-reflection and re-evaluation, the resulting SEMJ system produces higher-quality judgments. Oracle analysis confirms a higher performance upper bound from cross-language sampling, and experiments show consistent outperformance of voting and reflection baselines on accuracy and consistency, with further analysis attributing gains to inconsistency-triggered re-evaluation.
What carries the argument
SEMJ, the self-evolving multilingual judge that builds multilingual input variants, gathers independent judgments, and routes inconsistencies back for self-reflection and re-evaluation.
If this is right
- Cross-lingual inconsistency functions as a source of complementary signals rather than noise to be suppressed.
- Iterative self-reflection on disagreements raises both judgment accuracy and consistency above voting baselines.
- The performance upper bound increases when judgments are sampled across languages instead of confined to one.
- No external supervision is required for the refinement process once inconsistencies are identified.
Where Pith is reading between the lines
- The same disagreement-driven loop could be tested on other multilingual tasks such as summarization or translation quality estimation.
- Models might surface latent complementary knowledge across languages more generally if disagreement is deliberately elicited.
- Extending the approach to disagreements across model sizes or architectures could reveal additional refinement signals.
Load-bearing premise
Feeding inconsistent multilingual judgments and rationales back into the model produces useful self-reflection and improved re-evaluation instead of amplifying errors.
What would settle it
Running the self-reflection step on the same benchmarks and finding no accuracy gain or a drop in cross-lingual consistency would falsify the claim that inconsistency triggers productive refinement.
Figures




read the original abstract
Multilingual LLM-as-a-judge is widely used to evaluate model outputs across languages, but suffers from cross-lingual inconsistency (Fu and Liu, 2025). Existing methods typically treat this inconsistency as noise and mitigate it through voting or aggregation. In this work, we instead show that multilingual inconsistency can provide complementary evaluation signals. Our oracle analysis finds that sampling judgments across languages yields a higher performance upper bound than single-language judging, indicating that different languages potentially include complementary judgments. Motivated by this finding, we propose SEMJ, a self-evolving multilingual judge that leverages cross-lingual inconsistency for iterative refinement. SEMJ constructs multilingual variants of each input, collects independent judgments and rationales, and feeds inconsistent outputs back for self-reflection and re-evaluation. Experiments on multiple benchmarks show that SEMJ consistently outperforms voting and reflection baselines in both accuracy and cross-lingual consistency. Further analysis shows that inconsistency triggers useful re-evaluation, which improves judgment quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that cross-lingual inconsistency in LLM-as-a-judge systems, typically treated as noise, can instead supply complementary evaluation signals. An oracle analysis is said to show that sampling judgments across languages yields a higher performance upper bound than single-language judging. Motivated by this, the authors propose SEMJ, a self-evolving multilingual judge that generates multilingual input variants, collects independent judgments and rationales, and feeds inconsistencies back into the model for self-reflection and iterative re-evaluation. Experiments on multiple benchmarks are reported to show that SEMJ outperforms voting and reflection baselines in both accuracy and cross-lingual consistency, with further analysis claiming that inconsistency triggers useful re-evaluation.
Significance. If the empirical claims hold after proper controls and ablations, the work would meaningfully reframe multilingual inconsistency as a potential resource rather than a defect, offering a new direction for improving LLM judges in multilingual settings. The oracle result, if rigorously constructed, would provide concrete evidence of complementarity across languages.
major comments (3)
- [Abstract, Experiments] Abstract and Experiments section: the central claims of outperformance and that "inconsistency triggers useful re-evaluation" are stated without any reported details on the number of languages tested, benchmark construction, statistical significance testing, number of runs, or controls for prompt variation and additional inference passes; this makes it impossible to assess whether the data support the claims or isolate the effect of the self-reflection step from extra compute.
- [Method (SEMJ construction)] SEMJ description (method section): the procedure of feeding inconsistent multilingual judgments and rationales back for self-reflection is presented as producing useful re-evaluation, but no ablation isolates this mechanism from error amplification, hallucination, or simple averaging; the weakest assumption identified in the reader note is therefore load-bearing and untested.
- [Oracle analysis / Results] Oracle analysis (results section): the claim of a higher performance upper bound from multilingual sampling is central to motivating SEMJ, yet no description is given of how the oracle is constructed, how the bound is computed, or what controls ensure the complementarity is not an artifact of prompt or model variation.
minor comments (3)
- [Method] Notation for multilingual variants and inconsistency metrics is introduced without explicit definitions or equations, making the procedural description harder to follow.
- [Experiments] The paper would benefit from a clearer statement of the exact benchmarks used and the precise definition of cross-lingual consistency metric.
- [Introduction] References to prior work on multilingual inconsistency (e.g., Fu and Liu, 2025) should include a brief summary of their findings to situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater experimental transparency and controls. We address each major comment below and will revise the manuscript to incorporate the requested details, ablations, and clarifications.
read point-by-point responses
-
Referee: [Abstract, Experiments] Abstract and Experiments section: the central claims of outperformance and that "inconsistency triggers useful re-evaluation" are stated without any reported details on the number of languages tested, benchmark construction, statistical significance testing, number of runs, or controls for prompt variation and additional inference passes; this makes it impossible to assess whether the data support the claims or isolate the effect of the self-reflection step from extra compute.
Authors: We agree that these details are necessary for rigorous evaluation. In the revised manuscript we will explicitly report the number of languages used, the construction process for each benchmark, the number of independent runs performed, results of statistical significance testing (including p-values), and controls that fix prompts across conditions while accounting for the additional inference cost of the self-reflection step. These additions will allow readers to isolate the contribution of the inconsistency-driven reflection from extra compute. revision: yes
-
Referee: [Method (SEMJ construction)] SEMJ description (method section): the procedure of feeding inconsistent multilingual judgments and rationales back for self-reflection is presented as producing useful re-evaluation, but no ablation isolates this mechanism from error amplification, hallucination, or simple averaging; the weakest assumption identified in the reader note is therefore load-bearing and untested.
Authors: We acknowledge that an explicit ablation isolating the self-reflection step is required. The revised version will include a new ablation study comparing (i) the full SEMJ pipeline, (ii) a variant that performs multilingual sampling but replaces self-reflection with simple majority voting or averaging, and (iii) a variant that disables reflection entirely. This will directly test whether the observed gains stem from the inconsistency-triggered re-evaluation rather than from error amplification or additional averaging. revision: yes
-
Referee: [Oracle analysis / Results] Oracle analysis (results section): the claim of a higher performance upper bound from multilingual sampling is central to motivating SEMJ, yet no description is given of how the oracle is constructed, how the bound is computed, or what controls ensure the complementarity is not an artifact of prompt or model variation.
Authors: We agree that the oracle construction and controls must be described in detail. The revised results section will specify the exact procedure for constructing the multilingual oracle (including how judgments are sampled across languages and how the upper-bound performance is calculated), and will add controls that hold the underlying model and prompt template fixed while varying only the language of the input. These controls will demonstrate that the reported complementarity is not an artifact of prompt or model differences. revision: yes
Circularity Check
Minor self-citation for problem setup; SEMJ method and oracle analysis are procedurally independent with no reduction to fitted inputs or self-defined quantities.
full rationale
The paper states the existence of cross-lingual inconsistency via citation to Fu and Liu (2025) and then presents an oracle analysis (sampling across languages for higher upper bound) followed by a procedural construction of SEMJ (generate multilingual variants, collect judgments, feed inconsistencies back for reflection). No equations, parameters, or derivations are present. The central empirical claim that inconsistency triggers useful re-evaluation is tested against baselines rather than derived by construction from any prior fit or self-citation chain. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-lingual inconsistency in LLM judgments can provide complementary evaluation signals rather than being mere noise.
Reference graph
Works this paper leans on
-
[1]
The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.0
-
[2]
Council of LLM s: Evaluating Capability of Large Language Models to Annotate Propaganda
Sharma, Vivek and Jain, Shweta and Shokri, Mohammad and Levitan, Sarah Ita and Filatova, Elena. Council of LLM s: Evaluating Capability of Large Language Models to Annotate Propaganda. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.1
-
[3]
Emoji Reactions on Telegram: Unreliable Indicators of Emotional Resonance
Tardelli, Serena and Alvisi, Lorenzo and Cima, Lorenzo and Cresci, Stefano and Tesconi, Maurizio. Emoji Reactions on Telegram: Unreliable Indicators of Emotional Resonance. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.2
-
[4]
Quantifying Social Sentiment in Hostels Using A Domain-Specific Transformer Pipeline
McMurry, Ian W. Quantifying Social Sentiment in Hostels Using A Domain-Specific Transformer Pipeline. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.3
-
[5]
Predicting Convincingness in Political Speech: How Emotional Tone Shapes Persuasive Strength
Verma, Bhuvanesh and Marreddy, Mounika and Mehler, Alexander. Predicting Convincingness in Political Speech: How Emotional Tone Shapes Persuasive Strength. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.4
-
[6]
Measuring LLM s' Sensitivity to Paraphrased Opinion Prompts
Alhetelah, Bushra and Ahmad, Irfan. Measuring LLM s' Sensitivity to Paraphrased Opinion Prompts. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.5
-
[7]
The Impact of Highlighting Subjective Language on Perceived News Trustworthiness
Shokri, Mohammad and Sharma, Vivek and Klapper, Emily and Jain, Shweta and Filatova, Elena and Levitan, Sarah Ita. The Impact of Highlighting Subjective Language on Perceived News Trustworthiness. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.6
-
[8]
Appraisal Trajectories in Narratives Reveal Distinct Patterns of Emotion Evocation
Sch. Appraisal Trajectories in Narratives Reveal Distinct Patterns of Emotion Evocation. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.7
-
[9]
Exploring Subjective Tasks in F arsi: A Survey Analysis and Evaluation of Language Models
Rooein, Donya and Plaza-del-Arco, Flor Miriam and Nozza, Debora and Hovy, Dirk. Exploring Subjective Tasks in F arsi: A Survey Analysis and Evaluation of Language Model. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.8
-
[10]
Iaroshenko, Polina V. and Loukachevitch, Natalia V. Emotional Lexicons: How Large Language Models Predict Emotional Ratings of R ussian Words. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.9
-
[11]
Emotion-aware text simplification of user generated content using LLM s
Bezobrazova, Anastasiia and Sokova, Daria and Orasan, Constantin. Emotion-aware text simplification of user generated content using LLM s. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.10
-
[12]
Aranberri, Nora. Crowd-Based Evaluation of Emotion Intensity Preservation in S panish -- B asque Tweet Machine Translation. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.11
-
[13]
and Markov, Ilia and Vossen, Piek
Schouten, Stefan F. and Markov, Ilia and Vossen, Piek. A Position Paper on Toxic Reasoning: Grounding Categories of Toxic Language in Implications and Attitudes. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.12
-
[14]
Is Sentiment Banana-Shaped? Exploring the Geometry and Portability of Sentiment Concept Vectors
Lyngbaek, Laurits and Feldkamp, Pascale and Bizzoni, Yuri and Nielbo, Kristoffer and Enevoldsen, Kenneth. Is Sentiment Banana-Shaped? Exploring the Geometry and Portability of Sentiment Concept Vectors. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/20...
-
[15]
Disentangling Emotion Understanding and Generation in Large Language Models
Jafari, Sadegh and Lefever, Els and Hoste, Veronique. Disentangling Emotion Understanding and Generation in Large Language Models. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.14
-
[16]
News Credibility Assessment by LLM s and Humans: Implications for Political Bias
Neves, Pia Wenzel and Jakob, Charlott and Schmitt, Vera. News Credibility Assessment by LLM s and Humans: Implications for Political Bias. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.15
-
[17]
Schwager, Nils and M. Towards Simulating Social Media Users with LLM s: Evaluating the Operational Validity of Conditioned Comment Prediction. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.16
-
[18]
Label-Consistent Data Generation for Aspect-Based Sentiment Analysis Using LLM Agents
Monfared, Mohammad Hossein Akbari and Flek, Lucie and Karimi, Akbar. Label-Consistent Data Generation for Aspect-Based Sentiment Analysis Using LLM Agents. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.17
-
[19]
Antisocial Behavior Prediction: A Survey and Practical Guide
Ollagnier, Ana. Antisocial Behavior Prediction: A Survey and Practical Guide. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.18
-
[20]
Real-Time Mitigation of Negative Emotion in Customer Care Calls
Gangopadhyay, Surupendu and Mehrabani, Mahnoosh. Real-Time Mitigation of Negative Emotion in Customer Care Calls. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.19
-
[21]
Says Who? Argument Convincingness and Reader Stance Are Correlated with Perceived Author Personality
Weber, Sabine and Greschner, Lynn and Klinger, Roman. Says Who? Argument Convincingness and Reader Stance Are Correlated with Perceived Author Personality. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.20
-
[22]
A Transformer and Prototype-based Interpretable Model for Contextual Sarcasm Detection
Wen, Ximing and Rezapour, Rezvaneh. A Transformer and Prototype-based Interpretable Model for Contextual Sarcasm Detection. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.21
-
[23]
Multimodal Claim Extraction for Fact-Checking
Teo, Joycelyn and Cao, Rui and Deng, Zhenyun and Ding, Zifeng and Schlichtkrull, Michael Sejr and Vlachos, Andreas. Multimodal Claim Extraction for Fact-Checking. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.22
-
[24]
A Multi-Aspect Evaluation Framework for Synthetic Data: Case Study on Irony and Sarcasm
Majer, Laura and Bari \'c , Ana and Sandalj, Florijan and Unkovi \'c , Ivan and Puva c a, Bojan and S najder, Jan. A Multi-Aspect Evaluation Framework for Synthetic Data: Case Study on Irony and Sarcasm. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2...
-
[25]
Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.0
-
[26]
Robinson, Nathaniel R. and Abdelmoneim, Shahd and Kantharuban, Anjali and Alsboul, Otba and Lamsiyah, Salima and Marchisio, Kelly and Murray, Kenton. AMIYA Shared Task: A rabic Modeling In Your Accent at V ar D ial 2026. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.1
-
[27]
Far Out: Evaluating Language Models on Slang in A ustralian and I ndian E nglish
Dilsiz, Deniz Kaya and Srirag, Dipankar and Joshi, Aditya. Far Out: Evaluating Language Models on Slang in A ustralian and I ndian E nglish. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.2
-
[28]
Kuparinen, Olli. Effects of Speaker Bias in Dialect Identification and Automatic Transcription with Self-Supervised Speech Models. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.3
-
[29]
O c W iki D ialects: A W ikipedia Dataset With Rich Metadata for O ccitan Dialect Identification
N \'e dey, Oriane and Bawden, Rachel and Cl \'e rice, Thibault and Sagot, Beno \^i t. O c W iki D ialects: A W ikipedia Dataset With Rich Metadata for O ccitan Dialect Identification. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.4
-
[30]
Irastortza-Urbieta, Xabier and Garc \'i a-Miguel, Jos \'e M. and Garcia, Marcos. Language Mixture to Develop Accurate G alician Dependency Parsers: An Exploration of Its Effects. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.5
-
[31]
Crowdsourcing P iedmontese to Test LLM s on Non-Standard Orthography
Vico, Gianluca and Libovick \'y , Jind r ch. Crowdsourcing Piedmontese to Test LLM s on Non-Standard Orthography. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.6
-
[32]
G erman- E nglish Code-Switching in Large Language Models
Aks. G erman- E nglish Code-Switching in Large Language Models. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.7
-
[33]
Perplexity as a Metric for Dialectal Distance: A Computational Study of G reek Varieties
Chatzikyriakidis, Stergios and Psaltaki, Erofili and Papadakis, Dimitrios and Henriksson, Erik and Laippala, Veronika. Perplexity as a Metric for Dialectal Distance: A Computational Study of G reek Varieties. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.8
-
[34]
A Subword Embedding Approach for Variation Detection in L uxembourgish User Comments
Lutgen, Anne-Marie and Plum, Alistair and Purschke, Christoph. A Subword Embedding Approach for Variation Detection in L uxembourgish User Comments. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.9
-
[35]
Onomasiological Sense Alignment Across Dialect Dictionaries
Mederake, Nathalie and Urbach, Nico and Fischer, Hanna and Lameli, Alfred. Onomasiological Sense Alignment Across Dialect Dictionaries. A Taxonomy-Constrained LLM Classification. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.10
-
[36]
and Uban, Ana Sabina and Marchitan, Teodor-George and Iordache, Ioan-Bogdan and Georgescu, Simona
Dinu, Liviu P. and Uban, Ana Sabina and Marchitan, Teodor-George and Iordache, Ioan-Bogdan and Georgescu, Simona. On the Intelligibility of R omance Language Varieties: S panish and P ortuguese in E urope and A merica. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.11
-
[37]
Dialect Matters: Cross-Lingual ASR Transfer for Low-Resource I ndic Language Varieties
Dhasmana, Akriti and Srivastava, Aarohi and Chiang, David. Dialect Matters: Cross-Lingual ASR Transfer for Low-Resource I ndic Language Varieties. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.12
-
[38]
Alabdullah, Abdullah and Han, Lifeng and Lin, Chenghua. Ara- HOPE : Human-Centric Post-Editing Evaluation for Dialectal A rabic to M odern S tandard A rabic Translation. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.13
-
[39]
I ndic- T uned L ens: Interpreting Multilingual Models in I ndian Languages
Panchal, Mihir and Varshney, Deeksha and ., Mamta and Ekbal, Asif. I ndic- T uned L ens: Interpreting Multilingual Models in I ndian Languages. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.14
-
[40]
Building ASR Resources for the Hutsul Dialect of U krainian
Kyslyi, Roman and Orlovskyi, Artem and Khomenko, Pavlo and Onyshchenko, Bohdan and Guzii, Zakhar. Building ASR Resources for the Hutsul Dialect of U krainian. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.15
-
[41]
From F us H a to Folk: Exploring Cross-Lingual Transfer in A rabic Language Models
Khalak, Abdulmuizz and Issam, Abderrahmane and Spanakis, Gerasimos. From F us H a to Folk: Exploring Cross-Lingual Transfer in A rabic Language Models. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.16
-
[42]
Extending ASR Evaluation Resources for M odern G reek Dialects
Tsoukala, Chara and Bompolas, Stavros and Margariti, Antigoni and Panagiotou, Konstantina and Plaiti, Maria Elisavet and Tzanakaki, Nefeli and Karatsareas, Petros and Ralli, Angela and Anastasopoulos, Antonios and Markantonatou, Stella. Extending ASR Evaluation Resources for M odern G reek Dialects. Proceedings of the 13th Workshop on NLP for Similar Lang...
-
[43]
How Should We Model the Probability of a Language?
Dent, Rasul and Ortiz Suarez, Pedro and Cl \'e rice, Thibault and Sagot, Beno \^i t. How Should We Model the Probability of a Language?. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.18
-
[44]
Bridging Dialectal Variation: A Phonetic Transcription Tool for T amil
Mahaganapathy, Ahrane and Karunakaran, Sumirtha and Navakulan, Kavitha and Sarveswaran, Kengatharaiyer. Bridging Dialectal Variation: A Phonetic Transcription Tool for T amil. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.19
-
[45]
Regional Variation in the Performance of ASR Models on C roatian and S erbian
Samard z i \'c , Tanja and Rupnik, Peter and Ljube s i \'c , Nikola. Regional Variation in the Performance of ASR Models on C roatian and S erbian. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.20
-
[46]
Syllable Structures Across A rabic Varieties
Qaddoumi, Abdelrahim and Kodner, Jordan and Khalifa, Salam and Broselow, Ellen and Rambow, Owen. Syllable Structures Across A rabic Varieties. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.21
-
[47]
Mekky, Ali and El Zeftawy, Mohamed and Hassan, Lara and Keleg, Amr and Nakov, Preslav. Curriculum Learning and Pseudo-Labeling Improve the Generalization of Multi-Label A rabic Dialect Identification Models. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.22
-
[48]
Fedorova, Mariia and Arefyev, Nikolay and Buljan, Maja and Helcl, Jind r ich and Oepen, Stephan and R nningstad, Egil and Scherrer, Yves. O pen LID -v3: Improving the Precision of Closely Related Language Identification -- An Experience Report. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/202...
-
[49]
Improving Dialect Robustness in Large Language Models via L o RA and Mixture-of-Experts
Maheshwari, Sanjh and Rajpoot, Aniket Singh and Cocarascu, Oana and ., Mamta. Improving Dialect Robustness in Large Language Models via L o RA and Mixture-of-Experts. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.24
-
[50]
Evaluation Framework for Transfer Learning between Closely Related Lects: A Case Study of Lemko
Afanasev, Ilia. Evaluation Framework for Transfer Learning between Closely Related Lects: A Case Study of Lemko. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.25
-
[51]
Do Large Language Models Adapt to Language Variation across Socioeconomic Status?
Bassignana, Elisa and Zhang, Mike and Hovy, Dirk and Cercas Curry, Amanda. Do Large Language Models Adapt to Language Variation across Socioeconomic Status?. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.26
-
[52]
Mutal, Jonathan and Al Almaoui, Perla and Hengchen, Simon and Bouillon, Pierrette. Aladdin- FTI @ AMIYA Three Wishes for A rabic NLP : Fidelity, Diglossia, and Multidialectal Generation. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.27
-
[53]
Alali, Abdulhai and Issam, Abderrahmane. Maastricht University at AMIYA : Adapting LLM s for Dialectal A rabic using Fine-tuning and MBR Decoding. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.28
-
[54]
SDNLP at AMIYA 2026: S yrian A rabic Dialect Modeling with L o RA
Alkhder, Hasan and Abboush, Mohammad. SDNLP at AMIYA 2026: S yrian A rabic Dialect Modeling with L o RA. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.29
-
[55]
Gollapalli, Sujatha Das and Hakam, Mouad and Du, Mingzhe and Ng, See-Kiong. NUS - IDS at AMIYA / V ar D ial 2026: Improving A rabic Dialectness in LLM s with Reinforcement Learning. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.30
-
[56]
MBZUAI at AMIYA Shared Task 2026: Adapting Open-Source LLM s for Dialectal A rabic
Gaber, Rana and Allam, Yara and Amin, Serag and Aly, Ranwa and Alhafni, Bashar. MBZUAI at AMIYA Shared Task 2026: Adapting Open-Source LLM s for Dialectal A rabic. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.31
-
[57]
A Closed-Track System for Palestinian A rabic in the AMIYA Shared Task
Hamad, Khaleel and Al-Najjar, Ahmad. A Closed-Track System for Palestinian A rabic in the AMIYA Shared Task. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.32
-
[58]
Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.0
-
[59]
A nimated LLM : Explaining LLM s with Interactive Visualizations
Kasner, Zden e k and Dusek, Ondrej. A nimated LLM : Explaining LLM s with Interactive Visualizations. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.1
-
[60]
Narra, Sruti. Pedagogic Applications of Argument Maps to Enhance Critical Thinking: Thought Seeds, Argument Mapping, Collaborative Mapping. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.2
-
[61]
From Code-Centric to Concept-Centric: Teaching NLP with LLM -Assisted ``Vibe Coding''
Al-Khalifa, Hend. From Code-Centric to Concept-Centric: Teaching NLP with LLM -Assisted ``Vibe Coding''. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.3
-
[62]
Linguistics to LLM s: Teaching with and about Chatbots
Pado, Ulrike and Pampel, Barbara. Linguistics to LLM s: Teaching with and about Chatbots. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.4
-
[63]
Skadina, Inguna and Kuzmina, Jana and Platonova, Marina and Smirnova, Tatjana and Kruk, Sergei. Language Technology Initiative: Framework for Teaching NLP and Computational Linguistics at the Universities in L atvia. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.5
-
[64]
Teaching NLP in the AI Era: Experiences from the U niversity of L atvia
Skadina, Inguna and Barzdins, Guntis and Boj \= a rs, Uldis and Gruzitis, Normunds and Paikens, P \= e teris. Teaching NLP in the AI Era: Experiences from the U niversity of L atvia. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.6
-
[65]
A Hands-on Approach to NLP Fundamentals for External Domain Experts in the LLM Era
Daza, Angel. A Hands-on Approach to NLP Fundamentals for External Domain Experts in the LLM Era. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.7
-
[66]
and Chervyakov, Artem and Zaytsev, Alexey and Panchenko, Alexander
Tikhonova, Maria and Chekalina, Viktoriia A. and Chervyakov, Artem and Zaytsev, Alexey and Panchenko, Alexander. From Standard Transformers to M odern LLM s: Bringing Dialogue Models, RAG , and Agents to the Classroom. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.8
-
[67]
Which course? Discourse! Teaching Discourse and Generation in the Era of LLM s
Li, Junyi Jessy and Liu, Yang Janet and Misra, Kanishka and Pyatkin, Valentina and Sheffield, William. Which course? Discourse! Teaching Discourse and Generation in the Era of LLM s. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.9
-
[68]
From Mixed Backgrounds to NLP Skills
Barak, Libby and Feldman, Anna. From Mixed Backgrounds to NLP Skills. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.10
-
[69]
Teaching and Critiquing Conceptualization and Operationalization in NLP
Gautam, Vagrant. Teaching and Critiquing Conceptualization and Operationalization in NLP. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.11
-
[70]
Bridging Applied Experience and Research Contexts in U krainian NLP Education
Paniv, Yurii and Makovska, Viktoriia. Bridging Applied Experience and Research Contexts in U krainian NLP Education. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.12
-
[71]
Kyslyi, Roman and Bazdyrev, Anton. Teaching M odern NLP and LLM s at Kyiv School of Economics: A Practice-Oriented Course with U krainian Language Focus. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.13
-
[72]
Practising responsibility: Ethics in NLP as a hands-on course
Nissim, Malvina and Patti, Viviana and Savoldi, Beatrice. Practising responsibility: Ethics in NLP as a hands-on course. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.14
-
[73]
Abraar, Mohammed and Dandekar, Raj and Dandekar, Rajat and Panat, Sreedath. Beyond Passive Viewing: A Pilot Study of a Hybrid Learning Platform Augmenting Video Lectures with Conversational AI. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.15
-
[74]
Bilstrup, Karl-Emil Kj r and Degn, Kirstine Nielsen and Schultz, Morten and Conroy, Alexander and Bjerring-Hansen, Jens and Hershcovich, Daniel. From Sentiment to Interpretation: Teaching NLP for Literary Understanding Across Educational Contexts. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10....
-
[75]
Novel or Drivel? Variants of Invariants for Teaching NLP in the LLM Era
Micluța-C \^a mpeanu, Marius. Novel or Drivel? Variants of Invariants for Teaching NLP in the LLM Era. Proceedings of the Seventh Workshop on Teaching Natural Language Processing ( T each NLP 2026). 2026. doi:10.18653/v1/2026.teachingnlp-1.17
-
[76]
A ctive LLM : Large Language Model-Based Active Learning for Textual Few-Shot Scenarios
Bayer, Markus and Lutz, Justin and Reuter, Christian. A ctive LLM : Large Language Model-Based Active Learning for Textual Few-Shot Scenarios. Transactions of the Association for Computational Linguistics. 2026. doi:10.1162/tacl.a.63
-
[77]
M o N a C o: More Natural and Complex Questions for Reasoning Across Dozens of Documents
Wolfson, Tomer and Trivedi, Harsh and Geva, Mor and Goldberg, Yoav and Roth, Dan and Khot, Tushar and Sabharwal, Ashish and Tsarfaty, Reut. M o N a C o: More Natural and Complex Questions for Reasoning Across Dozens of Documents. Transactions of the Association for Computational Linguistics. 2026. doi:10.1162/tacl.a.64
-
[78]
D eep T rans: Deep Reasoning Translation via Reinforcement Learning
Wang, Jiaan and Meng, Fandong and Zhou, Jie. D eep T rans: Deep Reasoning Translation via Reinforcement Learning. Transactions of the Association for Computational Linguistics. 2026. doi:10.1162/tacl.a.65
-
[79]
C oref I nst: Leveraging LLM s for Multilingual Coreference Resolution
Pamay Arslan, Tu. C oref I nst: Leveraging LLM s for Multilingual Coreference Resolution. Transactions of the Association for Computational Linguistics. 2026. doi:10.1162/tacl.a.593
-
[80]
and Josyula, Yasasvi and Choi, Jinho D
Finch, James D. and Josyula, Yasasvi and Choi, Jinho D. Generative Induction of Dialogue Task Schemas with Streaming Refinement and Simulated Interactions. Transactions of the Association for Computational Linguistics. 2026. doi:10.1162/tacl.a.66
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.