HERO: Hindsight-Enhanced Reflection from Environment Observations for Agentic Self-Distillation
Pith reviewed 2026-06-27 10:02 UTC · model grok-4.3
The pith
Hindsight reflection on environment observations aligns feedback for multi-turn agent self-distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
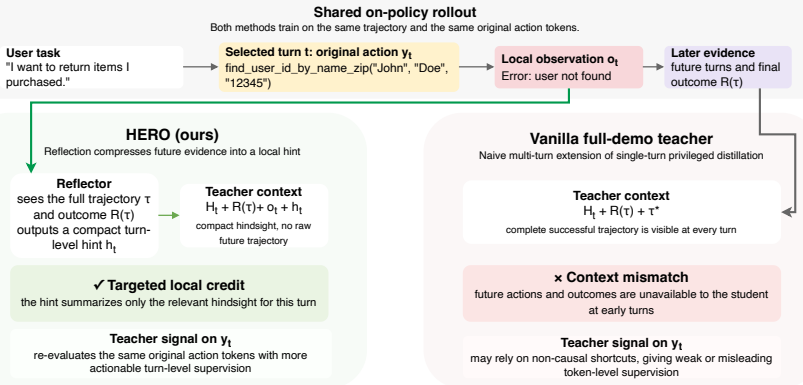
HERO is a hindsight-enhanced self-distillation framework that, after each rollout, reflects on the completed interaction to convert every next environment observation into a compact turn-level diagnosis capturing actionable feedback about the original action. These diagnoses supply the dense token-level supervision used to train the student, outperforming both environment-feedback-only self-distillation and GRPO especially when successful rollouts are scarce and reward-contrast signals are weak.
What carries the argument
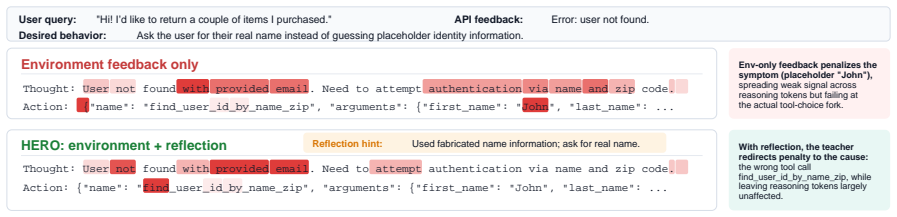
The hindsight reflection step that turns each subsequent environment observation into a compact diagnosis of the preceding action's necessity, validity, or failure cause.
If this is right
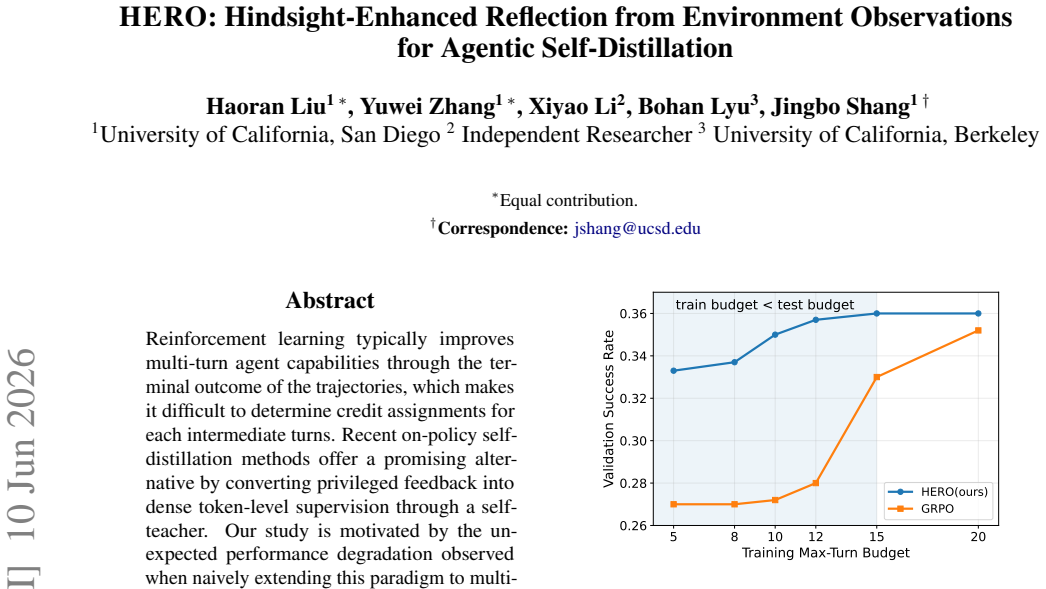
- Task success rates rise on multi-turn benchmarks such as TauBench and WebShop.
- Agents complete tasks with fewer unnecessary turns.
- Training remains effective even when the total turn budget is limited and positive examples are infrequent.
- The need for strong reward-contrast signals from methods like GRPO decreases because diagnoses supply direct per-action feedback.
Where Pith is reading between the lines
- Training loops could run with less dependence on sparse terminal rewards if observations routinely yield usable diagnoses.
- The same reflection pattern might transfer to other sequential decision settings where later observations implicitly diagnose earlier choices.
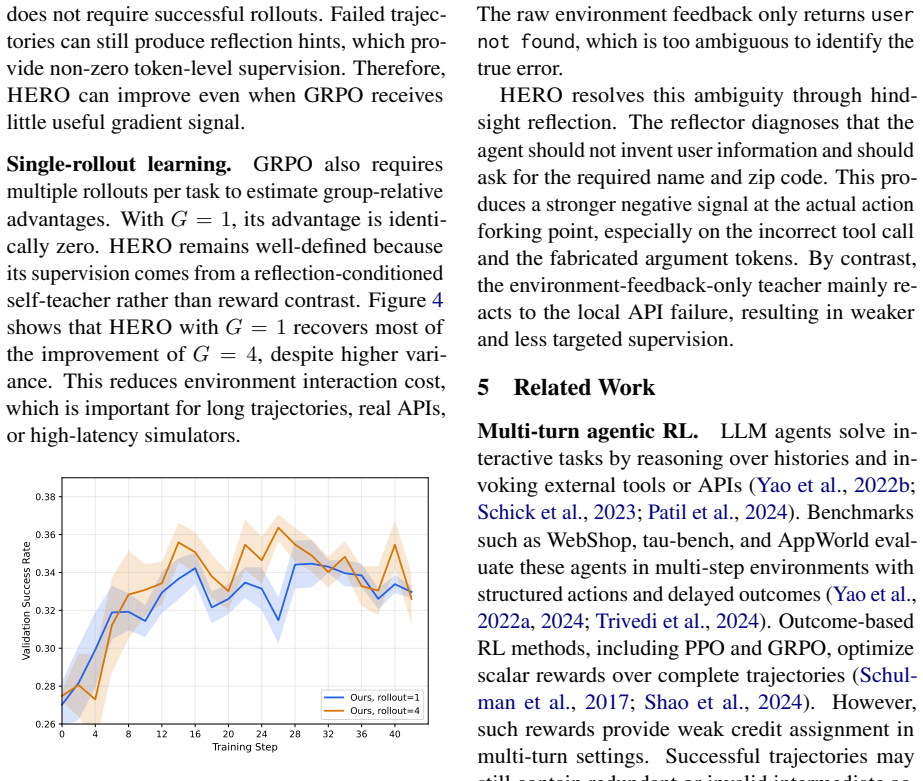
- One could test whether the student model itself can generate the diagnoses without an extra reflection pass.
Load-bearing premise
Next environment observations can be reliably converted into compact turn-level diagnoses that capture actionable feedback about the original action.
What would settle it
Replace the observation-derived diagnoses with random or context-ignoring text and measure whether task success and turn efficiency fall back to the level of environment-feedback-only self-distillation.
Figures


read the original abstract
Reinforcement learning typically improves multi-turn agent capabilities through the terminal outcome of the trajectories, which makes it difficult to determine credit assignments for each intermediate turns. Recent on-policy self-distillation methods offer a promising alternative by converting privileged feedback into dense token-level supervision through a self-teacher. Our study is motivated by the unexpected performance degradation observed when naively extending this paradigm to multi-turn settings, which we attribute to a lack of alignment between privileged feedback, such as successful trajectories or terminal outcomes, and the student's current decision context. We introduce HERO, a hindsight-enhanced self-distillation framework that uses next environment observations as locally aligned feedback. After each rollout, HERO reflects on the completed interaction to convert each observation into a compact turn-level diagnosis, that captures actionable feedback about the original action such as its necessity, validity or failure cause. On TauBench and WebShop, HERO improves task success and reduces unnecessary turns over environment-feedback-only self-distillation and GRPO. It is especially effective under limited training turn budgets, where successful rollouts are rare and GRPO provides weak reward-contrast signals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HERO, a hindsight-enhanced self-distillation framework for multi-turn agents. It converts next environment observations into compact turn-level diagnoses that supply actionable feedback (necessity, validity, failure cause) on each action, aiming to improve alignment over terminal rewards or raw environment feedback. The central empirical claim is that HERO raises task success rates and reduces unnecessary turns on TauBench and WebShop relative to environment-feedback-only self-distillation and GRPO, with the largest gains under limited training-turn budgets where successful rollouts are rare.
Significance. If the diagnosis-generation step reliably produces locally aligned feedback, the method offers a concrete way to strengthen credit assignment in on-policy self-distillation for agentic RL. The reported gains under constrained budgets are practically relevant and the evaluation on two distinct benchmarks supplies a useful test of the approach.
major comments (2)
- [§3] §3 (Method): the claim that next-observation diagnoses supply 'locally aligned' feedback rests on the unverified assumption that the reflection step produces diagnoses whose quality can be measured; no quantitative metric or human/AI judge evaluation of diagnosis accuracy or alignment with the student's decision context is reported, which is load-bearing for the credit-assignment improvement.
- [§4] §4 (Experiments): the abstract and results text state improvements 'especially effective under limited training turn budgets,' yet no table or figure isolates the interaction between budget size and method; without this breakdown it is unclear whether the reported advantage over GRPO is driven by the hindsight mechanism or by other factors.
minor comments (2)
- Notation for the diagnosis generation step should be formalized with an explicit equation or algorithm box rather than prose description only.
- The paper should include the exact prompt template used for the reflection step so that the conversion process is reproducible.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the method and results.
read point-by-point responses
-
Referee: [§3] §3 (Method): the claim that next-observation diagnoses supply 'locally aligned' feedback rests on the unverified assumption that the reflection step produces diagnoses whose quality can be measured; no quantitative metric or human/AI judge evaluation of diagnosis accuracy or alignment with the student's decision context is reported, which is load-bearing for the credit-assignment improvement.
Authors: We agree that a direct quantitative assessment of diagnosis quality would provide stronger support for the local-alignment claim. The current manuscript relies on downstream task improvements as indirect evidence. In revision we will add an evaluation (new subsection in §3 or dedicated appendix) that scores a sample of generated diagnoses for factual accuracy, necessity/validity judgments, and relevance to the preceding action using both an LLM judge and a small human annotation study. This will be reported with inter-annotator agreement where applicable. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract and results text state improvements 'especially effective under limited training turn budgets,' yet no table or figure isolates the interaction between budget size and method; without this breakdown it is unclear whether the reported advantage over GRPO is driven by the hindsight mechanism or by other factors.
Authors: The referee is correct that the interaction between training-turn budget and method performance is not isolated in the current tables/figures. We will add a new figure (or extended table) in §4 that reports success rate and average turns for HERO, the environment-feedback baseline, and GRPO across a range of explicit training-turn budgets (e.g., 1k, 5k, 10k, 20k turns). This will make the claimed advantage under limited budgets directly visible and allow readers to assess whether the hindsight component is the primary driver. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a methodological framework (HERO) for converting environment observations into turn-level diagnoses within self-distillation for agents. The abstract and provided text contain no equations, parameter-fitting steps, self-citations, or derivations that reduce any claimed prediction or result to its own inputs by construction. Claims of improvement on TauBench and WebShop are presented as empirical outcomes from external benchmarks rather than internal reductions. This matches the default expectation for non-circular papers; the derivation chain is self-contained with no load-bearing steps matching the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-distillation zero: Self-revision turns bi- nary rewards into dense supervision.arXiv preprint arXiv:2604.12002. Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt
-
[2]
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276. Jonas Hübotter, Frederike Lübeck, Lejs Behric, An- ton Bauman...
Pith/arXiv arXiv 2009
-
[3]
InInternational Conference on Learning Representations, volume 2024, pages 39578–39601
Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pages 39578–39601. Hao Liu, Carmelo Sferrazza, and Pieter Abbeel. 2024. Chain of hindsight aligns language models with feed- back. InInternational Conference on Learning Rep- resentations, volume 2024, pages 41395–41414. Kevin Lu and Thinking Machines Lab. 2025...
Pith/arXiv arXiv 2024
-
[4]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16022–16076
Appworld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16022–16076. Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang,...
-
[5]
Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, and Yi Wu
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Ad- vances in Neural Information Processing Systems, 37:95266–95290. Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, and Yi Wu. 2024. Is dpo superior to ppo for llm align- ment? a comprehensive study.arXiv preprint arXiv:2404.1071...
arXiv 2024
-
[6]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2022a. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757. Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. τ-bench: A benc...
Pith/arXiv arXiv 2024
-
[7]
Self-distilled reasoner: On-policy self- distillation for large language models.arXiv preprint arXiv:2601.18734. Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Sid- dhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023. Instruction-following evalu- ation for large language models.arXiv preprint arXiv:2311.07911. Yifei Zhou, Andrea Zanette, Jiayi P...
Pith/arXiv arXiv 2023
-
[8]
Reflect on every assistant turn, including correct turns
-
[9]
Use later trajectory evidence only to identify delayed consequences; do not expose future actions or observations verbatim
Ground each diagnosis in the current action and its next environment observation. Use later trajectory evidence only to identify delayed consequences; do not expose future actions or observations verbatim
-
[10]
Distinguish decision errors from tool-execution errors
-
[11]
medium"or
Fill next_action_target only when the corrected action is unambiguous; otherwise set it to null with "medium"or"low"confidence
-
[12]
Avoid redundant actions, repeated confirmations, and re-asking already confirmed information
-
[13]
turn1","turn2
Output only valid JSON, with no markdown or extra text. Output format.Return a JSON object with one key per assistant turn:"turn1","turn2",. . .,"turnT". { "turn1": { "diagnosis": "<brief causal diagnosis>", "confidence": "low", "next_action_target": null }, "turn2": { "diagnosis": "<brief causal diagnosis>", "confidence": "high", "next_action_target": { ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.