The Shape of Reasoning: Topological Analysis of Reasoning Traces in Large Language Models
Pith reviewed 2026-05-22 13:00 UTC · model grok-4.3
The pith
Topological features from reasoning traces predict large language model quality better than graph metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a topological data analysis (TDA)-based evaluation framework that captures the geometry of reasoning traces and enables label-efficient, automated assessment. In our empirical study, topological features yield substantially higher predictive power for assessing reasoning quality than standard graph metrics, suggesting that effective reasoning is better captured by higher-dimensional geometric structures rather than purely relational graphs. We further show that a compact, stable set of topological features reliably indicates trace quality, offering a practical signal for future reinforcement learning algorithms.
What carries the argument
Topological data analysis applied to reasoning traces to extract geometric features that represent the shape and structure of the reasoning process.
If this is right
- Topological features can automate the assessment of reasoning trace quality with less reliance on manual labeling.
- These features provide a reliable signal that can guide reinforcement learning algorithms to improve model reasoning.
- Effective reasoning in language models is better represented by higher-dimensional geometric structures than by simple relational graphs.
Where Pith is reading between the lines
- Applying this topological approach to other sequential decision processes could reveal similar geometric patterns in successful strategies.
- Training models to optimize for these topological features might produce more robust reasoning capabilities.
- Comparison with other geometric or manifold learning methods could test if topology specifically adds unique value here.
Load-bearing premise
The quality labels assigned by humans to the reasoning traces are accurate and free from bias or inconsistency.
What would settle it
Re-annotating the same reasoning traces with multiple independent groups of experts and finding that topological features lose their predictive advantage over graph metrics would challenge the main result.
Figures






read the original abstract
Evaluating the quality of reasoning traces from large language models remains understudied, labor-intensive, and unreliable: current practice relies on expert rubrics, manual annotation, and slow pairwise judgments. Automated efforts are dominated by graph-based proxies that quantify structural connectivity but do not clarify what constitutes high-quality reasoning; such abstractions can be overly simplistic for inherently complex processes. We introduce a topological data analysis (TDA)-based evaluation framework that captures the geometry of reasoning traces and enables label-efficient, automated assessment. In our empirical study, topological features yield substantially higher predictive power for assessing reasoning quality than standard graph metrics, suggesting that effective reasoning is better captured by higher-dimensional geometric structures rather than purely relational graphs. We further show that a compact, stable set of topological features reliably indicates trace quality, offering a practical signal for future reinforcement learning algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a topological data analysis (TDA) framework for assessing the quality of reasoning traces produced by large language models. It claims that topological features capture higher-dimensional geometric structures in these traces and deliver substantially higher predictive power for reasoning quality than standard graph metrics, while also identifying a compact, stable subset of such features as a reliable quality signal suitable for reinforcement learning applications.
Significance. If the empirical superiority holds under rigorous validation, the work could shift automated LLM reasoning evaluation from simplistic connectivity proxies toward geometric invariants, supporting more label-efficient assessment and improved training signals. This addresses an important gap in reliable, scalable evaluation of complex reasoning processes.
major comments (2)
- Abstract: the central claim that topological features yield substantially higher predictive power than graph metrics is stated without any supporting numbers, accuracy metrics, statistical tests, dataset sizes, or controls for confounding variables, preventing verification of the empirical result.
- Empirical study section: the supervised comparison relies on human-provided quality labels as ground truth, yet no inter-annotator agreement statistics, label-validation procedures, or reliability measures are reported; systematic errors or low agreement in these labels would undermine the claimed superiority of TDA features.
minor comments (1)
- Abstract: the phrase 'label-efficient' assessment is used while the reported comparison still depends on ground-truth labels; clarifying this distinction would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, indicating the changes made to strengthen the presentation and verifiability of our results.
read point-by-point responses
-
Referee: [—] Abstract: the central claim that topological features yield substantially higher predictive power than graph metrics is stated without any supporting numbers, accuracy metrics, statistical tests, dataset sizes, or controls for confounding variables, preventing verification of the empirical result.
Authors: We agree that the abstract would be strengthened by including quantitative support for the central claim. In the revised manuscript we have expanded the abstract to report key empirical metrics from the study, including predictive accuracy and AUC values for TDA versus graph features, the size of the evaluation dataset, and references to the statistical tests and controls detailed in the empirical study section. These additions allow readers to assess the claimed improvement directly from the abstract. revision: yes
-
Referee: [—] Empirical study section: the supervised comparison relies on human-provided quality labels as ground truth, yet no inter-annotator agreement statistics, label-validation procedures, or reliability measures are reported; systematic errors or low agreement in these labels would undermine the claimed superiority of TDA features.
Authors: We acknowledge that explicit reporting of annotation reliability is necessary to support the validity of the supervised evaluation. We have revised the empirical study section to include inter-annotator agreement statistics, a description of the label-validation procedures used, and additional reliability checks. These additions confirm that the ground-truth labels meet acceptable consistency thresholds and do not introduce biases that would invalidate the reported superiority of the topological features. revision: yes
Circularity Check
Empirical comparison of TDA features to graph metrics exhibits no circularity
full rationale
The paper advances an empirical framework that extracts topological features from reasoning traces and compares their predictive power for human-annotated quality labels against standard graph metrics. The central claim rests on observed performance differences in a supervised evaluation setting rather than any algebraic derivation, parameter fit, or self-referential definition that reduces the reported superiority to quantities defined by the same inputs. No equations are presented that equate a 'prediction' to a fitted quantity by construction, and the abstract contains no load-bearing self-citations or uniqueness theorems imported from prior author work. The result is therefore self-contained against external human labels and remains falsifiable outside any internal fitting loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotations provide accurate ground-truth labels for reasoning quality
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
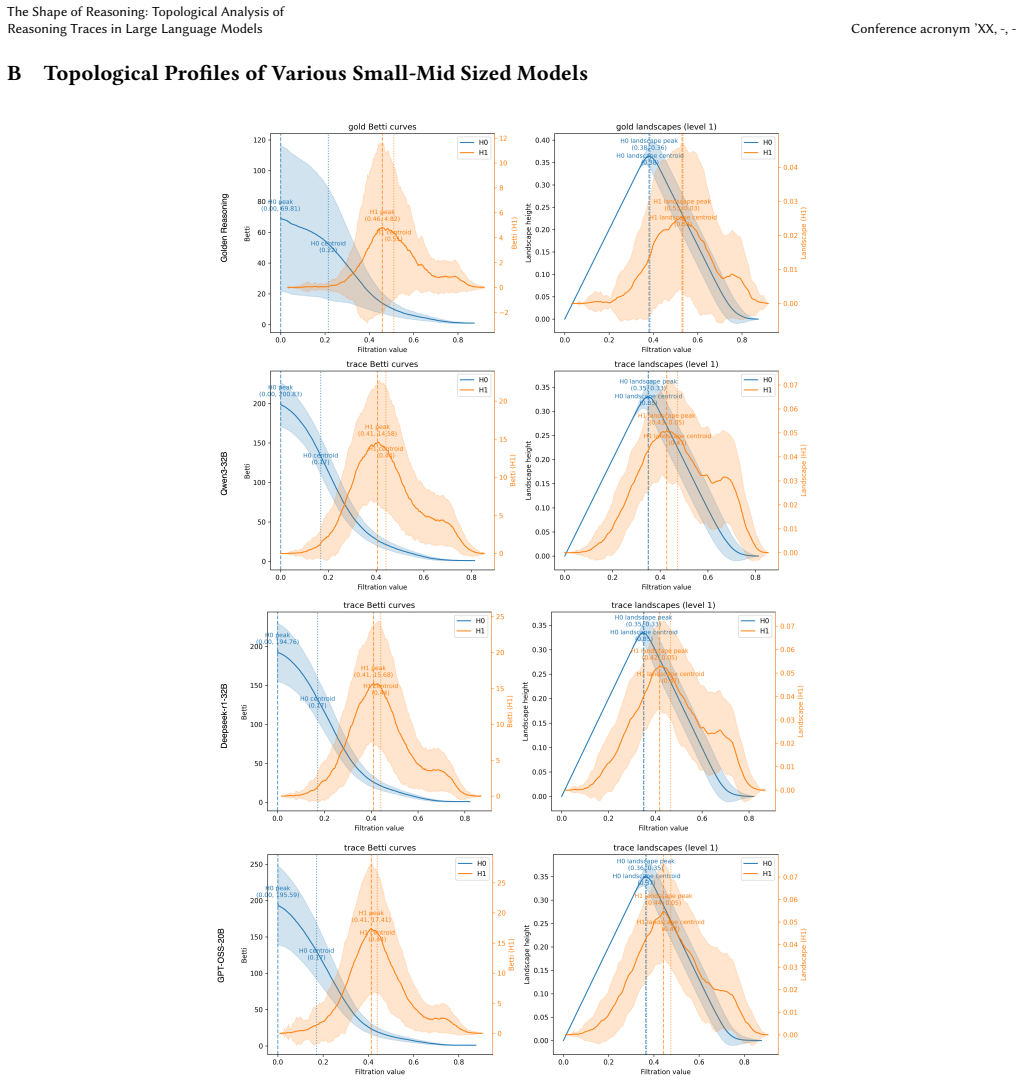
We compute k∈{0,1} (connected components and 1-cycles). Topological features... VR summary statistics, Betti-curve summaries, and persistence landscapes
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
SARL: Label-Free Reinforcement Learning by Rewarding Reasoning Topology
SARL rewards reasoning topology to improve label-free RL, outperforming baselines with gains up to 44.7% on math and 34.6% on open-ended tasks while maintaining more stable training.
-
CoDA: Towards Effective Cross-domain Knowledge Transfer via CoT-guided Domain Adaptation
CoDA aligns cross-domain latent reasoning representations in LLMs via CoT distillation and MMD to enable effective knowledge transfer without in-domain demonstrations.
Reference graph
Works this paper leans on
- [1]
-
[2]
Art of Problem Solving. 2025. AIME Problems and Solutions. https:// artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions. Ac- cessed on 29 September 2025
work page 2025
-
[3]
Luis Balderas, Miguel Lastra, and Jose M Benitez. 2025. A Green AI Methodology Based on Persistent Homology for Compressing BERT.Applied Sciences15, 1 (2025), 390
work page 2025
-
[4]
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. 2024. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 17682–17690
work page 2024
-
[5]
Theodore W Gamelin and Robert Everist Greene. 1999.Introduction to topology. Courier Corporation
work page 1999
-
[6]
Yuri Gardinazzi, Karthik Viswanathan, Giada Panerai, Alberto Cazzaniga, Matteo Biagetti, et al. [n. d.]. Persistent Topological Features in Large Language Models. InForty-second International Conference on Machine Learning
- [7]
- [8]
-
[9]
Thi Nguyen, Linhao Luo, Fatemeh Shiri, Dinh Phung, Yuan-Fang Li, Thuy Vu, and Gholamreza Haffari. 2024. Direct Evaluation of Chain-of-Thought in Multi-hop Reasoning with Knowledge Graphs. InFindings of the Association for Computa- tional Linguistics ACL 2024. 2862–2883
work page 2024
-
[10]
Miao Peng, Nuo Chen, Zongrui Suo, and Jia Li. 2025. Rewarding graph reasoning process makes llms more generalized reasoners. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 2257–2268
work page 2025
-
[11]
Benjamin Matthias Ruppik, Michael Heck, Carel van Niekerk, Renato Vukovic, Hsien-Chin Lin, Shutong Feng, Marcus Zibrowius, and Milica Gasic. 2024. Local Topology Measures of Contextual Language Model Latent Spaces with Applica- tions to Dialogue Term Extraction. InProceedings of the 25th Annual Meeting of the Special Interest Group on Discourse and Dialog...
work page 2024
-
[12]
Temple F Smith, Michael S Waterman, et al . 1981. Identification of common molecular subsequences.Journal of molecular biology147, 1 (1981), 195–197
work page 1981
- [13]
- [14]
-
[15]
Jean-Francois Ton, Muhammad Faaiz Taufiq, and Yang Liu. [n. d.]. Understand- ing Chain-of-Thought in LLMs through Information Theory. InForty-second International Conference on Machine Learning
-
[16]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InThe Eleventh International Conference on Learning Representations
work page 2022
-
[17]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
work page 2022
- [18]
-
[19]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems36 (2023), 11809–11822. Conference acronym ’XX, -, - Tan et al. A Correlation Tables for TDA Features Figure 3: Correlation Heatmap...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.