Multi-Token Residual Prediction
Pith reviewed 2026-05-20 22:40 UTC · model grok-4.3
The pith
Diffusion language models can denoise multiple tokens per forward pass by predicting residuals between adjacent logit distributions from hidden states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
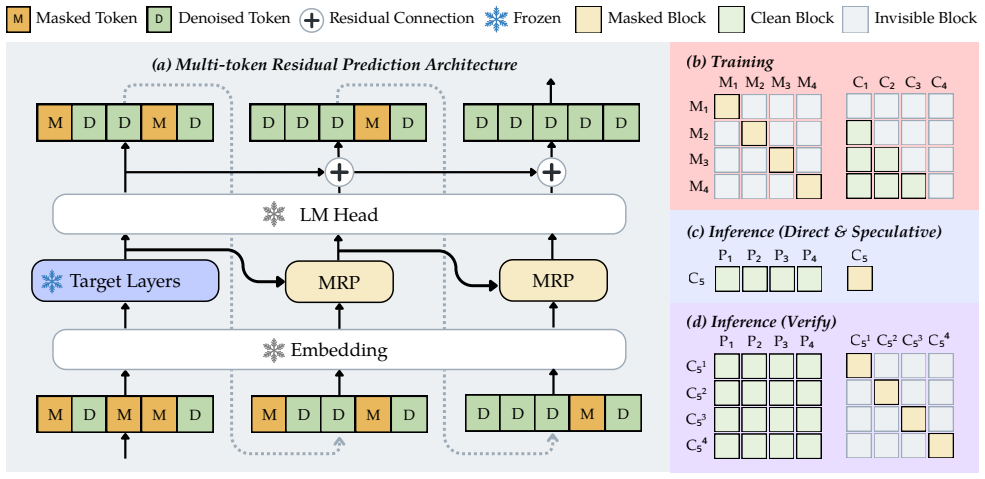
MRP is a lightweight module attached to a diffusion language model backbone that predicts the residual between the logit distribution at the current denoising step and the distribution at the next step, using only the hidden states already computed by the backbone. Because adjacent logit distributions are similar, the residual is small and can be modeled accurately by a cheap head rather than by running the entire network again. The corrected logits then support either direct multi-token denoising or speculative proposals that are verified for exact equivalence to the original model.
What carries the argument
Multi-Token Residual Prediction (MRP) module, which forecasts the logit residual between successive denoising steps from the backbone hidden states.
If this is right
- Direct decoding mode allows a continuous quality-speed curve by accepting more or fewer MRP proposals.
- Speculative decoding mode guarantees output identical to the original model while still reducing the number of full backbone evaluations.
- The method scales from 1.7B to 8B parameter models on both reasoning and code-generation tasks.
- No change to the pre-trained backbone weights is required; only the small MRP head is trained.
Where Pith is reading between the lines
- The same residual-prediction idea could be tested in other iterative refinement processes such as masked image generation where consecutive predictions are also highly correlated.
- If the hidden states already encode most of the next-step information, further compression of the MRP head itself may be possible without retraining.
- The approach suggests that diffusion models may not need full re-inference at every step, opening the door to hybrid schedules that mix full and residual steps dynamically.
Load-bearing premise
Logit distributions at adjacent denoising steps are similar enough that their difference can be predicted accurately from the current hidden states alone.
What would settle it
Run MRP on a held-out set of denoising trajectories and measure whether the predicted logits produce token sequences whose quality matches the original backbone within the paper's reported thresholds; if the quality gap exceeds those thresholds, the claimed speedups are not achievable without loss.
Figures


read the original abstract
Diffusion Language Models (DLMs) generate text by iteratively denoising masked token sequences, offering a tradeoff between parallelism and quality compared to autoregressive models. In current practice, the number of tokens decoded per step is controlled by a confidence threshold, and quality degrades monotonically as more tokens are denoised per step. We introduce Multi-token Residual Prediction (MRP), a lightweight module that enables dependency-aware multi-token denoising within a single backbone forward pass. MRP exploits a key property of the denoising process: the logit distributions at adjacent denoising steps are remarkably similar. Rather than running the backbone a second time to obtain the next-step logits, MRP predicts the residual between steps from the backbone's hidden states, effectively denoising more tokens per backbone forward at a fraction of the cost. We deploy MRP in two inference modes: direct decoding, which uses the corrected logits without verification for a tunable quality--speed tradeoff; and speculative decoding, which verifies MRP's proposals against the backbone for lossless acceleration. Experiments on SDAR models at the 1.7B, 4B, and 8B scales across reasoning and code generation benchmarks demonstrate up to $1.42\times$ lossless speedup in SGLang.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Multi-Token Residual Prediction (MRP), a lightweight auxiliary module for diffusion language models (DLMs). MRP predicts the residual between logit distributions at adjacent denoising steps directly from the backbone hidden states, enabling dependency-aware multi-token denoising in a single forward pass. The approach is deployed in direct-decoding mode (tunable quality-speed tradeoff) and speculative-decoding mode (lossless acceleration via verification). Experiments on SDAR models at 1.7B, 4B, and 8B scales report up to 1.42× lossless speedup on reasoning and code-generation benchmarks.
Significance. If the core empirical observation holds and residual prediction remains sufficiently accurate when multiple tokens are updated per step, MRP offers a practical, low-overhead route to higher parallelism in DLM inference without sacrificing the lossless property in the speculative path. The method is notable for its simplicity—an independent lightweight predictor rather than architectural changes to the backbone—and for explicitly separating the quality-speed tradeoff from the acceleration claim.
major comments (2)
- [Experiments] Experiments section: the abstract and results claim up to 1.42× lossless speedup across three model scales, yet no information is provided on the number of evaluation runs, standard deviations, exact baseline implementations (including confidence-threshold schedules), or hardware/software stack. This absence makes it impossible to assess whether the reported factor is robust or sensitive to implementation details.
- [Method] Method and speculative-decoding description: the central claim that MRP sustains high acceptance rates relies on the logit distributions remaining 'remarkably similar' even when multiple tokens are denoised per step. When the sequence fed to the next backbone call differs in several positions, the true residual can enlarge; the manuscript should include either an ablation measuring prediction error and acceptance rate as a function of tokens-per-step or a theoretical bound showing why error remains controlled.
minor comments (2)
- [Method] Notation: the distinction between the MRP module output and the final corrected logits should be made explicit with consistent symbols throughout the equations.
- [Method] Figure clarity: the diagram illustrating the single-pass residual prediction versus the two-pass baseline would benefit from explicit arrows showing which tensors are reused versus recomputed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract and results claim up to 1.42× lossless speedup across three model scales, yet no information is provided on the number of evaluation runs, standard deviations, exact baseline implementations (including confidence-threshold schedules), or hardware/software stack. This absence makes it impossible to assess whether the reported factor is robust or sensitive to implementation details.
Authors: We agree that the current manuscript lacks sufficient details for full reproducibility and robustness assessment. In the revised version, we will expand the Experiments section to report the number of evaluation runs (conducted with 3 independent random seeds), include standard deviations alongside the speedup figures, provide exact specifications of the baseline implementations including the confidence-threshold schedules, and detail the hardware (NVIDIA H100 GPUs) and software stack (SGLang version and dependencies). These additions will allow readers to better evaluate the stability of the reported speedups. revision: yes
-
Referee: [Method] Method and speculative-decoding description: the central claim that MRP sustains high acceptance rates relies on the logit distributions remaining 'remarkably similar' even when multiple tokens are denoised per step. When the sequence fed to the next backbone call differs in several positions, the true residual can enlarge; the manuscript should include either an ablation measuring prediction error and acceptance rate as a function of tokens-per-step or a theoretical bound showing why error remains controlled.
Authors: We acknowledge the value of this request for stronger validation of the multi-token regime. In the revised manuscript we will add an ablation study that reports MRP prediction error (measured via KL divergence to the true residual) and speculative-decoding acceptance rates as a function of tokens updated per step (sweeping from 1 to 8 tokens). This empirical analysis will directly address whether error growth remains controlled. Deriving a general theoretical bound is difficult without strong assumptions on the diffusion trajectory, so we opt for the requested ablation instead. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces MRP as an independent lightweight module trained to predict residuals between adjacent-step logit distributions from backbone hidden states, exploiting an empirically observed similarity in the denoising process rather than any self-referential equation or fitted parameter renamed as a prediction. No load-bearing step reduces by the paper's own equations or self-citation to its inputs; the central claim rests on training a separate predictor and verifying it against external benchmarks, making the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- MRP module parameters
axioms (1)
- domain assumption Logit distributions at adjacent denoising steps are remarkably similar.
invented entities (1)
-
MRP residual predictor module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MRP exploits a key property of the denoising process: the logit distributions at adjacent denoising steps are remarkably similar... predicts the residual between steps from the backbone’s hidden states
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1 (One-step contraction)... D_TV(π_i^{t-1}, π_i^t) ≤ κ·|R_t|/L·max embedding distance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Sudhanshu Agrawal, Risheek Garrepalli, Raghavv Goel, Mingu Lee, Christopher Lott, and Fatih Porikli. “Spiffy: Multiplying Diffusion LLM Acceleration via Lossless Speculative Decoding”. In:arXiv preprint arXiv:2509.18085 (2025)
-
[2]
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. “Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models”. In: ICLR. 2025
work page 2025
-
[3]
Structured Denoising Diffusion Models in Discrete State-Spaces
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. “Structured Denoising Diffusion Models in Discrete State-Spaces”. In:NeurIPS. 2021
work page 2021
-
[4]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. “Program Synthesis with Large Language Models”. In:arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
https : //huggingface.co/datasets/BAAI/Infinity-Instruct
BAAI.Infinity Instruct: Scaling Instruction Selection and Synthesis to Enhance Language Models. https : //huggingface.co/datasets/BAAI/Infinity-Instruct. 2024
work page 2024
-
[6]
Learning to Parallel: Accelerating Diffusion Large Language Models via Learnable Parallel Decoding
Wenrui Bao, Zhiben Chen, Dan Xu, and Yuzhang Shang. “Learning to Parallel: Accelerating Diffusion Large Language Models via Learnable Parallel Decoding”. In:ICLR. 2026
work page 2026
-
[7]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. “Language models are few-shot learners”. In:Advances in neural information processing systems33 (2020), pp. 1877–1901
work page 2020
-
[8]
GenQA: Generating Millions of Instructions from a Handful of Prompts
Jiuhai Chen, Rifaa Qadri, Yuxin Wen, Neel Jain, John Kirchenbauer, Tianyi Zhou, and Tom Goldstein. “GenQA: Generating Millions of Instructions from a Handful of Prompts”. In:arXiv preprint arXiv:2406.10323(2024)
-
[9]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. “Evaluating Large Language Models Trained on Code”. In:arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wenhai Wang, Qipeng Guo, Kai Chen, Biqing Qi, and Bowen Zhou. “SDAR: A Synergistic Diffusion-AutoRegression Paradigm for Scalable Sequence Generation”. In:arXiv preprint arXiv:2510.06303(2025)
-
[11]
Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion
Jacob K. Christopher, Brian R. Bartoldson, Tal Ben-Nun, Michael Cardei, Bhavya Kailkhura, and Ferdinando Fioretto. “Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion”. In:NAACL. 2025
work page 2025
-
[12]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. “Training Verifiers to Solve Math Word Problems”. In:arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Self speculative decoding for diffusion large language models
Yifeng Gao, Ziang Ji, Yuxuan Wang, Biqing Qi, Hanlin Xu, and Linfeng Zhang. “Self Speculative Decoding for Diffusion Large Language Models”. In:arXiv preprint arXiv:2510.04147(2025)
-
[14]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. “Deep residual learning for image recognition”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016, pp. 770–778. 10
work page 2016
-
[15]
Measuring Mathematical Problem Solving with the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. “Measuring Mathematical Problem Solving with the MATH Dataset”. In:NeurIPS Datasets and Benchmarks. 2021
work page 2021
-
[16]
Wide-In, Narrow-Out: Revokable Decoding for Efficient and Effective DLLMs
Feng Hong, Geng Yu, Yushi Ye, Haicheng Huang, Huangjie Zheng, Ya Zhang, Yanfeng Wang, and Jiangchao Yao. “Wide-In, Narrow-Out: Revokable Decoding for Efficient and Effective DLLMs”. In:arXiv preprint arXiv:2507.18578 (2025)
-
[17]
Residual Context Diffusion Language Models
Yuezhou Hu, Harman Singh, Monishwaran Maheswaran, Haocheng Xi, Coleman Hooper, Jintao Zhang, Aditya Tomar, Michael W Mahoney, Sewon Min, Mehrdad Farajtabar, et al. “Residual Context Diffusion Language Models”. In:arXiv preprint arXiv:2601.22954(2026)
-
[18]
Accelerating Diffusion LLMs via Adaptive Parallel Decoding
Daniel Israel, Guy Van den Broeck, and Aditya Grover. “Accelerating Diffusion LLMs via Adaptive Parallel Decoding”. In:NeurIPS. 2025
work page 2025
-
[19]
Guanghao Li, Zhihui Fu, Min Fang, Qibin Zhao, Ming Tang, Chun Yuan, and Jun Wang. “DiffuSpec: Unlocking Diffusion Language Models for Speculative Decoding”. In:arXiv preprint arXiv:2510.02358(2025)
-
[20]
Diffusion Language Models Know the Answer Before Decoding
Pengxiang Li, Yefan Zhou, Dilxat Muhtar, Lu Yin, Shilin Yan, Li Shen, Soroush Vosoughi, and Shiwei Liu. “Diffusion Language Models Know the Answer Before Decoding”. In:NeurIPS. 2025
work page 2025
-
[21]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. “Eagle: Speculative sampling requires rethinking feature uncertainty”. In:arXiv preprint arXiv:2401.15077(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. “Let’s Verify Step by Step”. In:ICLR. 2024
work page 2024
-
[23]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. “Deepseek-v3 technical report”. In:arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. “Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution”. In:ICML. 2024
work page 2024
-
[25]
Fast-Decoding Diffusion Language Models via Progress-Aware Confidence Schedules
Amr Mohamed, Yang Zhang, Michalis Vazirgiannis, and Guokan Shang. “Fast-Decoding Diffusion Language Models via Progress-Aware Confidence Schedules”. In:arXiv preprint arXiv:2512.02892(2025)
-
[26]
Softmax is1 /2-Lipschitz: A tight bound across all ℓ𝑝 norms
Pravin Nair. “Softmax is1 /2-Lipschitz: A tight bound across all ℓ𝑝 norms”. In:arXiv preprint arXiv:2510.23012(2025)
-
[27]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. “Large Language Diffusion Models”. In:NeurIPS. 2025
work page 2025
-
[28]
Simple and Effective Masked Diffusion Language Models
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T. Chiu, Alexander Rush, and Volodymyr Kuleshov. “Simple and Effective Masked Diffusion Language Models”. In:NeurIPS. 2024
work page 2024
-
[29]
Fast and Fluent Diffusion Language Models via Convolutional Decoding and Rejective Fine-tuning
Yeongbin Seo, Dongha Lee, Jaehyung Kim, and Jinyoung Yeo. “Fast and Fluent Diffusion Language Models via Convolutional Decoding and Rejective Fine-tuning”. In:NeurIPS. 2025
work page 2025
-
[30]
Teknium.OpenHermes 2.5: An Open Dataset of Synthetic Data for Generalist LLM Assistants. https://huggingface. co/datasets/teknium/OpenHermes-2.5. 2024
work page 2024
-
[31]
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
Junxiong Wang, Daniele Paliotta, Avner May, Alexander M. Rush, and Tri Dao. “The Mamba in the Llama: Distilling and Accelerating Hybrid Models”. In:NeurIPS. 2024
work page 2024
-
[32]
Diffusion LLMs Can Do Faster-Than-AR Inference via Discrete Diffusion Forcing
Xu Wang, Chenkai Xu, Yijie Jin, Jiachun Jin, Hao Zhang, and Zhijie Deng. “Diffusion LLMs Can Do Faster-Than-AR Inference via Discrete Diffusion Forcing”. In:ICLR. 2026
work page 2026
-
[33]
Fast- dllm v2: Efficient block-diffusion llm.arXiv preprint arXiv:2509.26328,
Chengyue Wu, Hao Zhang, Shuchen Xue, Shizhe Diao, Yonggan Fu, Zhijian Liu, Pavlo Molchanov, Ping Luo, Song Han, and Enze Xie. “Fast-dllm v2: Efficient block-diffusion llm”. In:arXiv preprint arXiv:2509.26328(2025)
-
[34]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. “Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding”. In:ICLR. 2026
work page 2026
-
[35]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. “Qwen3 technical report”. In:arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. “Dream 7B: Diffusion Large Language Models”. In:arXiv preprint arXiv:2508.15487(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Sglang: Efficient execution of structured language model programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. “Sglang: Efficient execution of structured language model programs”. In:Advances in neural information processing systems37 (2024), pp. 62557–62583. 11 A Related Work A.1 Diffusion Language Models Discrete-se...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.