AxisGuide: Grounding Robot Action Coordinate System in RGB Observations for Robust Visuomotor Manipulation
Pith reviewed 2026-06-28 00:44 UTC · model grok-4.3
The pith
AxisGuide renders robot base-frame axes into RGB images to help policies map actions to image space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
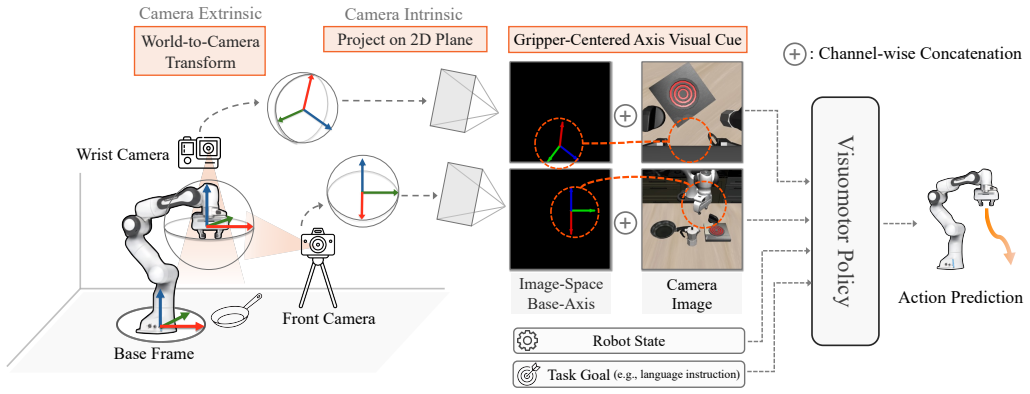
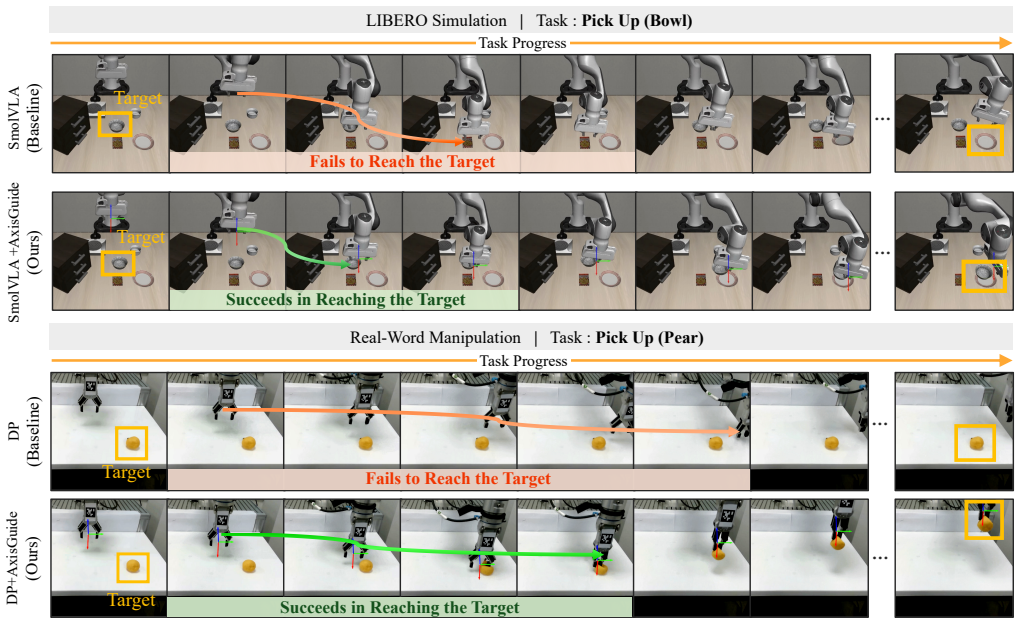
AxisGuide renders the robot base-frame axes in each camera view using known camera parameters and end-effector poses, then augments the RGB input with a small set of cue channels that explicitly visualize the meaning of +x, +y, and +z base-frame motions in image space. This explicit grounding bridges semantic scene understanding and action-coordinate interpretation, allowing standard behavior-cloned policies to execute reliable actions under distribution shifts.
What carries the argument
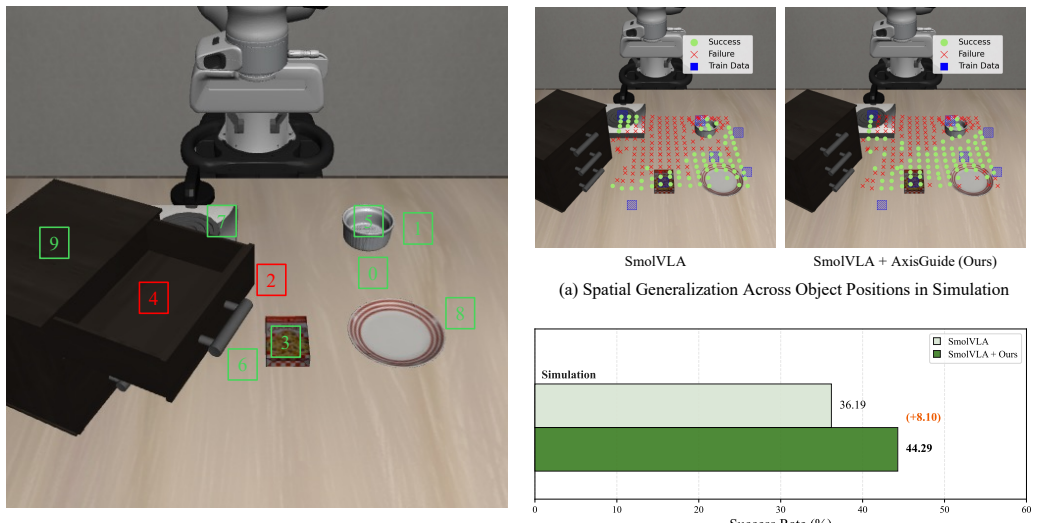
AxisGuide rendering of base-frame axes as additional cue channels in RGB observations.
Load-bearing premise
The rendered axes supply clear, non-conflicting visual information that a standard policy network can use to correctly interpret base-frame actions.
What would settle it
Train identical policies with and without the axis cues on LIBERO tasks that place objects at unseen locations, then measure whether success rates stay the same or improve only for the cued version.
Figures






read the original abstract
Visuomotor manipulation policies trained via large-scale behavior cloning have achieved strong semantic scene understanding, yet often fail to reliably execute correct low-level actions under distribution shifts. For example, even in a simple pickup task with identical scene layouts, camera viewpoints, and illumination, performance can degrade substantially when the object is placed at unseen locations. We argue that this gap arises from insufficient action understanding, namely the inability to interpret the robot's base-frame action coordinate system in image space. To address this issue, we introduce AxisGuide, a lightweight guidance method that bridges semantic scene understanding and action-coordinate interpretation. Using camera parameters and end-effector poses, AxisGuide renders the robot base-frame axes in each camera view and augments RGB observations with a small set of cue channels that explicitly visualize the meaning of the +x, +y, and +z motions in image space. Extensive evaluations in both the LIBERO simulation and real-world environments demonstrate that AxisGuide yields substantial performance gains and improved generalization, highlighting the effectiveness of explicit action-coordinate cues for learning reliable and transferable generalist visuomotor policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that visuomotor policies trained via behavior cloning often fail to interpret the robot's base-frame action coordinate system in image space, leading to poor generalization under distribution shifts. To address this, it introduces AxisGuide, a lightweight method that uses camera parameters and end-effector poses to render the robot base-frame axes (+x, +y, +z) as additional cue channels overlaid on RGB observations. This explicit visualization is said to bridge semantic understanding and action-coordinate interpretation without architecture changes or auxiliary losses. Extensive evaluations in the LIBERO simulation benchmark and real-world environments are reported to show substantial performance gains and improved generalization for generalist visuomotor policies.
Significance. If the results hold, the work could be significant for robot learning by demonstrating that explicit, rendered action-coordinate cues can improve policy robustness and transfer without modifying the underlying network or training objective. The approach is lightweight and additive, and the dual evaluation in simulation (LIBERO) and real-world settings provides a concrete test of the idea. The absence of architecture changes or extra losses is a positive design choice that keeps the method practical for existing behavior-cloning pipelines.
major comments (2)
- [§4] §4 (real-world experiments): The central claim that AxisGuide yields substantial generalization gains rests on the rendered axes supplying accurate, non-conflicting visual cues. However, the rendering depends on precise camera intrinsics/extrinsics and end-effector poses; the manuscript provides no quantitative analysis of sensitivity to typical real-world calibration errors (millimeter/degree level), which could produce misaligned cues that degrade rather than improve policy performance.
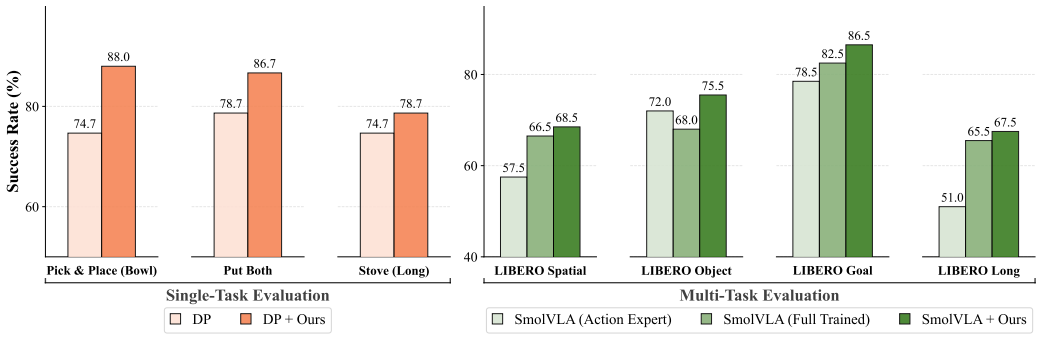
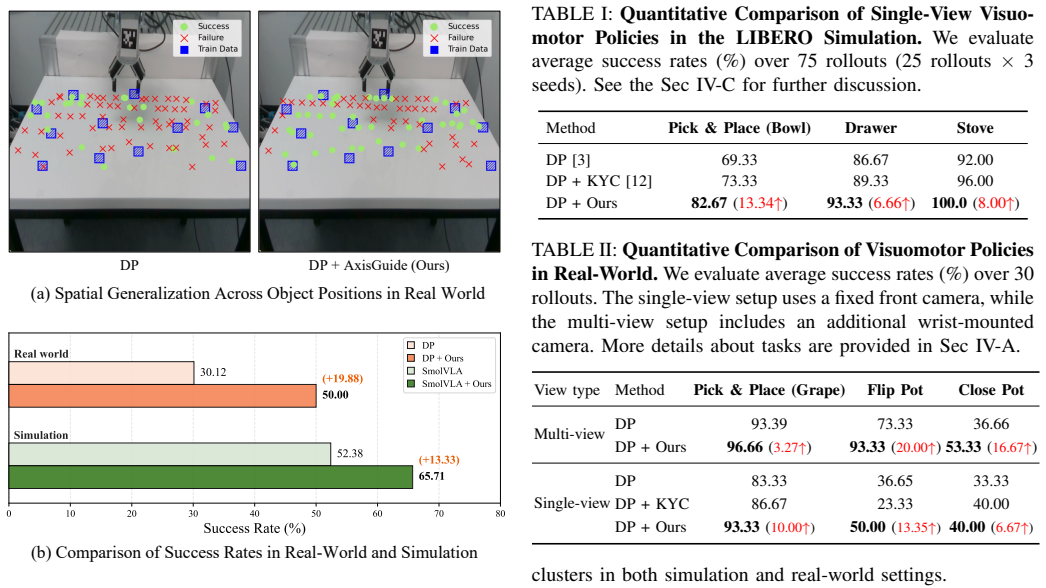
- [Table 2 / Figure 5] Table 2 / Figure 5 (LIBERO and real-world results): The abstract and results claim 'substantial performance gains' and 'improved generalization,' yet the provided text does not report concrete metrics, baseline comparisons, statistical significance, or ablation studies isolating the contribution of the cue channels versus other factors; this makes it impossible to evaluate whether the gains are load-bearing or reproducible.
minor comments (2)
- [§3] Notation for the rendered cue channels (e.g., how the three axis channels are normalized and concatenated to RGB) is described only at a high level; a precise equation or pseudocode would improve reproducibility.
- [§3] The paper does not discuss whether the method assumes perfect end-effector pose estimates during both training and deployment; a short clarification on this assumption would help readers assess deployment feasibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§4] §4 (real-world experiments): The central claim that AxisGuide yields substantial generalization gains rests on the rendered axes supplying accurate, non-conflicting visual cues. However, the rendering depends on precise camera intrinsics/extrinsics and end-effector poses; the manuscript provides no quantitative analysis of sensitivity to typical real-world calibration errors (millimeter/degree level), which could produce misaligned cues that degrade rather than improve policy performance.
Authors: We agree that sensitivity to calibration errors is an important practical consideration. The current manuscript does not include a quantitative analysis of this. In the revision we will add experiments that inject millimeter- and degree-level perturbations into camera intrinsics, extrinsics, and end-effector poses, re-render the axis cues, and measure the resulting change in policy success rates. This will directly test whether typical real-world calibration inaccuracies degrade or preserve the reported gains. revision: yes
-
Referee: [Table 2 / Figure 5] Table 2 / Figure 5 (LIBERO and real-world results): The abstract and results claim 'substantial performance gains' and 'improved generalization,' yet the provided text does not report concrete metrics, baseline comparisons, statistical significance, or ablation studies isolating the contribution of the cue channels versus other factors; this makes it impossible to evaluate whether the gains are load-bearing or reproducible.
Authors: Table 2 in the manuscript already reports per-task success rates for AxisGuide against the listed baselines on LIBERO, and Figure 5 reports real-world success rates. Ablation results isolating the cue channels appear in the supplementary material. We acknowledge, however, that statistical significance (standard deviations across seeds) and explicit isolation of the cue contribution are not sufficiently prominent in the main text. In the revision we will move key numerical results, baseline comparisons, and significance indicators into the main body and add a dedicated ablation subsection to improve evaluability and reproducibility. revision: yes
Circularity Check
No significant circularity; AxisGuide is an independent input augmentation
full rationale
The paper introduces AxisGuide as a rendering step that augments RGB inputs with base-frame axis cues computed from camera parameters and end-effector poses. This preprocessing is external to the policy network and training loop. Claims of performance gains rest on empirical evaluations in LIBERO and real-world settings rather than any mathematical derivation, fitted parameter renamed as prediction, or self-citation chain. No equations or steps reduce by construction to the inputs; the method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Camera intrinsic/extrinsic parameters and end-effector poses are known and accurate enough to render base-frame axes correctly in each view.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2410.24164, 2024
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision- language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[2]
Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jas- mine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J. Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang- Huei Lee, Sergey Levine, Yao Lu, Ut...
-
[3]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[4]
Aimbot: A simple auxiliary visual cue to enhance spatial awareness of visuomotor policies
Yinpei Dai, Jayjun Lee, Yichi Zhang, Ziqiao Ma, Jianing Yang, Amir Zadeh, Chuan Li, Nima Fazeli, and Joyce Chai. Aimbot: A simple auxiliary visual cue to enhance spatial awareness of visuomotor policies. InConference on Robot Learning, pages 2409–2429. PMLR, 2025
2025
-
[5]
Irving Fang, Juexiao Zhang, Shengbang Tong, and Chen Feng. From intention to execution: Probing the gener- alization boundaries of vision-language-action models. arXiv preprint arXiv:2506.09930, 2025. URL https: //arxiv.org/abs/2506.09930
arXiv 2025
-
[6]
Libero- plus: In-depth robustness analysis of vision-language- action models, 2025
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, Jinlan Fu, Jingjing Gong, and Xipeng Qiu. Libero- plus: In-depth robustness analysis of vision-language- action models, 2025. URL https://arxiv.org/abs/2510. 13626
2025
-
[7]
prentice hall professional technical reference, 2002
David A Forsyth and Jean Ponce.Computer vision: a modern approach. prentice hall professional technical reference, 2002
2002
-
[8]
Jiayuan Gu, Sean Kirmani, Paul Wohlhart, Yao Lu, Montserrat Gonzalez Arenas, Kanishka Rao, Wenhao Yu, Chuyuan Fu, Keerthana Gopalakrishnan, Zhuo Xu, et al. Rt-trajectory: Robotic task generalization via hindsight trajectory sketches.arXiv preprint arXiv:2311.01977, 2023
arXiv 2023
-
[9]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[10]
Vipe: Video pose engine for 3d geometric perception.arXiv preprint arXiv:2508.10934, 2025
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Korovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, et al. Vipe: Video pose engine for 3d geometric perception.arXiv preprint arXiv:2508.10934, 2025
Pith/arXiv arXiv 2025
-
[11]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[12]
Tianchong Jiang, Jingtian Ji, Xiangshan Tan, Jiading Fang, Anand Bhattad, Vitor Guizilini, and Matthew R. Walter. Do you know where your camera is? View- invariant policy learning with camera conditioning.arXiv preprint arXiv:2510.02268, 2025
arXiv 2025
-
[13]
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ash- win Balakrishna, Sudeep Dasari, Siddharth Karam- cheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, Peter David Fagan, Joey Hejna, Masha Itkina, Marion Lepert, Yecheng Jason Ma, Patrick Tree Miller, Jimmy Wu, Suneel Belkhale, Shivin Dass, Huy Ha, Arhan Jain, Abra- ham Le...
-
[14]
doi: 10.15607/RSS.2024.XX.120
-
[15]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model. In Pulkit Agrawal, Oliver Kroemer, and W...
2025
-
[16]
Molmoact: Action reason- ing models that can reason in space.arXiv preprint arXiv:2508.07917, 2025
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, et al. Molmoact: Action reason- ing models that can reason in space.arXiv preprint arXiv:2508.07917, 2025
Pith/arXiv arXiv 2025
-
[17]
Behavior generation with latent actions.arXiv preprint arXiv:2403.03181, 2024
Seungjae Lee, Yibin Wang, Haritheja Etukuru, H Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Behavior generation with latent actions.arXiv preprint arXiv:2403.03181, 2024
arXiv 2024
-
[18]
Hamster: Hierarchical action models for open-world robot manipulation
Yi Li, Yuquan Deng, Jesse Zhang, Joel Jang, Marius Memmel, Caelan Garrett, Fabio Ramos, Dieter Fox, Anqi Li, Abhishek Gupta, and Ankit Goyal. Hamster: Hierarchical action models for open-world robot manipulation. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors, International Conference on Representation Learning, volume 2025, pages 24040–24068, 2...
2025
-
[19]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776– 44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776– 44791, 2023
2023
-
[20]
Ctrnet-x: Camera-to-robot pose estimation in real-world conditions using a single camera
Jingpei Lu, Zekai Liang, Tristin Xie, Florian Richter, Shan Lin, Sainan Liu, and Michael C Yip. Ctrnet-x: Camera-to-robot pose estimation in real-world conditions using a single camera. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 1914–1920. IEEE, 2025
1914
-
[21]
Fmb: a functional manipulation benchmark for generalizable robotic learning.The International Journal of Robotics Research, 44(4):592–606, 2025
Jianlan Luo, Charles Xu, Fangchen Liu, Liam Tan, Zipeng Lin, Jeffrey Wu, Pieter Abbeel, and Sergey Levine. Fmb: a functional manipulation benchmark for generalizable robotic learning.The International Journal of Robotics Research, 44(4):592–606, 2025
2025
-
[22]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Ab- hishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[23]
Behavior transformers: Cloningkmodes with one stone.Advances in neural information processing systems, 35:22955–22968, 2022
Nur Muhammad Shafiullah, Zichen Cui, Ariuntuya Arty Altanzaya, and Lerrel Pinto. Behavior transformers: Cloningkmodes with one stone.Advances in neural information processing systems, 35:22955–22968, 2022
2022
-
[24]
Mustafa Shukor, Dana Aubakirova, Francesco Ca- puano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, An- dres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[25]
Be- havioral cloning from observation
Faraz Torabi, Garrett Warnell, and Peter Stone. Be- havioral cloning from observation. InProceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, pages 4950–4957. In- ternational Joint Conferences on Artificial Intelligence Organization, 7 2018. doi: 10.24963/ijcai.2018/687
-
[26]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision- language encoders with improved semantic understand- ing, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[27]
Bridgedata v2: A dataset for robot learning at scale
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, An- dre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pages 1723–
-
[28]
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Ar- salan Mousavian, and Dieter Fox. Robopoint: A vision- language model for spatial affordance prediction for robotics.arXiv preprint arXiv:2406.10721, 2024
arXiv 2024
-
[29]
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to- end object detection.arXiv preprint arXiv:2203.03605, 2022
Pith/arXiv arXiv 2022
-
[30]
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted trans- former as scalable cross-embodiment vision-language- action model.arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[31]
Tracevla: Visual trace prompting en- hances spatial-temporal awareness for generalist robotic policies
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daum ´e III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting en- hances spatial-temporal awareness for generalist robotic policies. InThe Thirteenth International Conference on Learning Representations
-
[32]
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language- action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. VII. SUPPLEMENTARYMATERIAL A. Real World Setup Details Fig. 7 shows the UR5e robot se...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.