NebulaExp-8B: An Empirical Post-Training Pipeline via Full-Scale Ablation Research
Pith reviewed 2026-06-26 04:58 UTC · model grok-4.3
The pith
A transparent post-training pipeline on Qwen3-8B raises average benchmark scores from 55.01 to 61.85 via staged SFT and GRPO RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
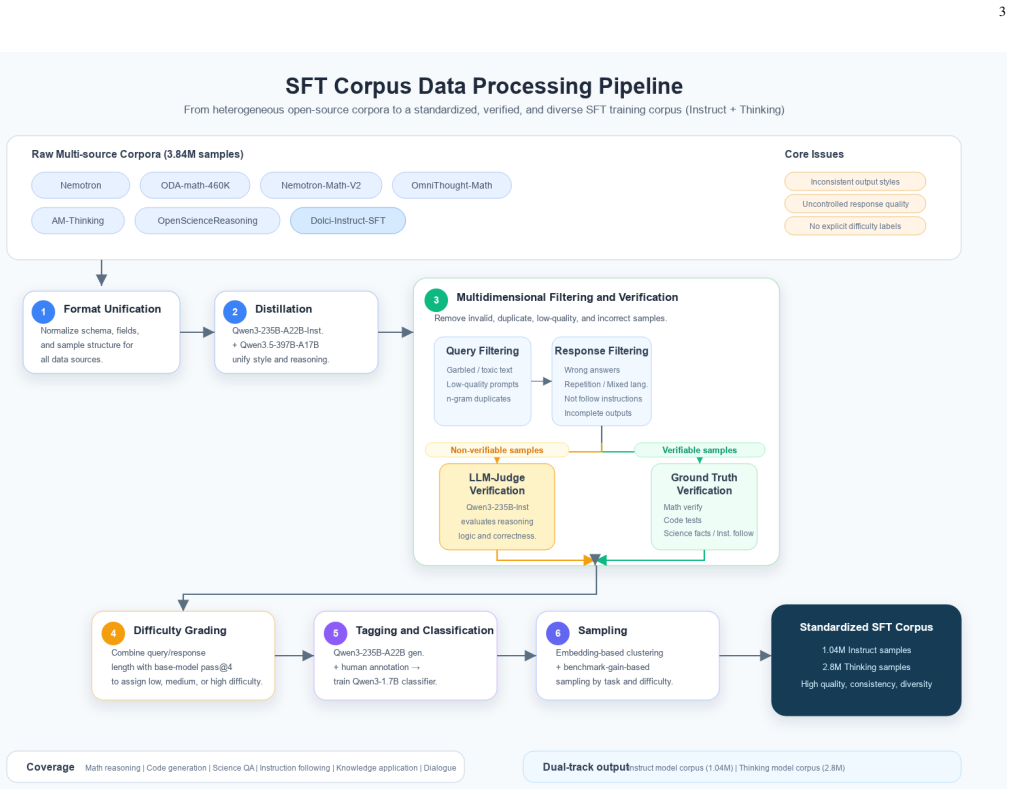
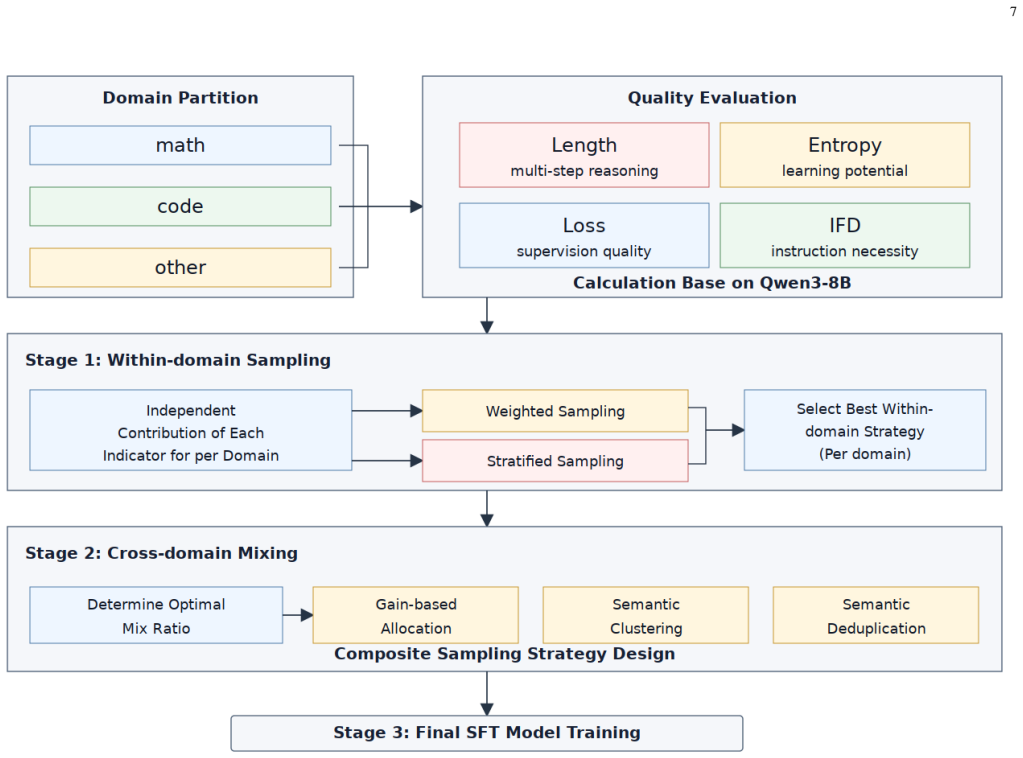
The central claim is that an end-to-end data processing stack of response distillation, multi-dimensional cross-verification filtering, fine-grained difficulty grading, task classification and diversity-aware sampling, when combined with three-stage optimized SFT and GRPO reinforcement learning, produces the reported benchmark gains, and that multi-teacher OPD (MOPD) can substitute for RL while using far fewer samples to achieve comparable or larger lifts.
What carries the argument
The end-to-end data processing stack of multi-dimensional cross-verification filtering, difficulty grading and diversity-aware sampling that prepares data for three-stage SFT, GRPO RL, and MOPD.
If this is right
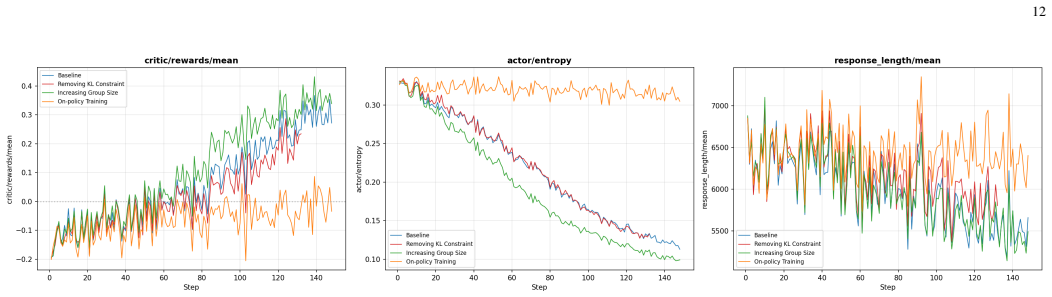
- Three-stage SFT followed by GRPO RL adds roughly 6.84 points to the average benchmark score.
- Medium-difficulty GRPO RL raises the average reasoning score by 1.29 points.
- MOPD with only 4K samples outperforms an RL baseline by 3.26 points on IFEval and 4.43 points overall.
- MOPD with 10K samples produces a 4.18-point average gain over the base model.
Where Pith is reading between the lines
- The same filtering and grading rules could be tested on larger base models to check whether data volume requirements scale down.
- Running ablations that isolate each filtering step would show which component drives most of the measured gains.
- Pairing MOPD with a light RL stage might combine the sample efficiency of distillation with the verifier-based refinement of RL.
Load-bearing premise
That the benchmark score increases reflect genuine capability improvements rather than artifacts from the specific test distributions used during data filtering and evaluation.
What would settle it
Apply the identical data rules and training stages to a different base model, then measure performance on a fresh set of benchmarks that played no role in filtering or training.
Figures
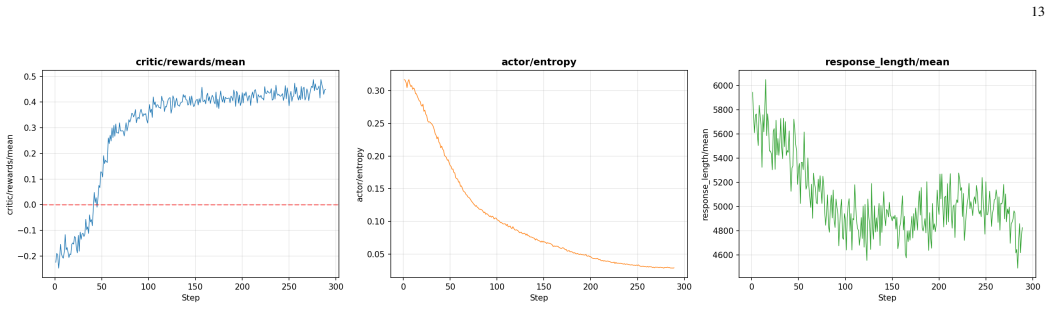
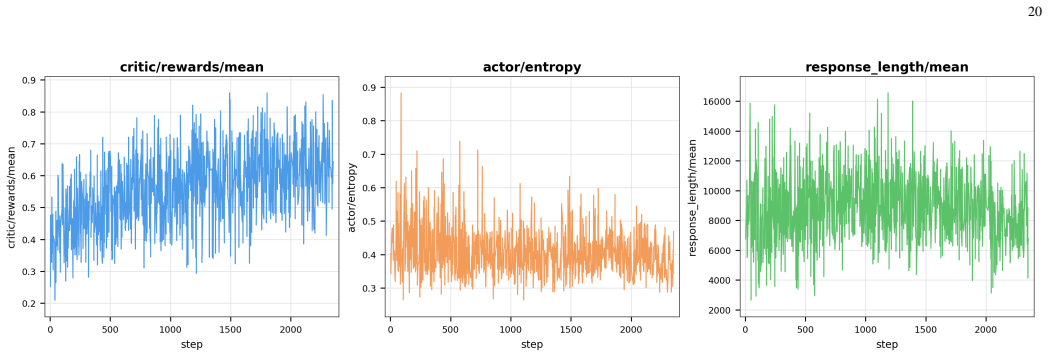
read the original abstract
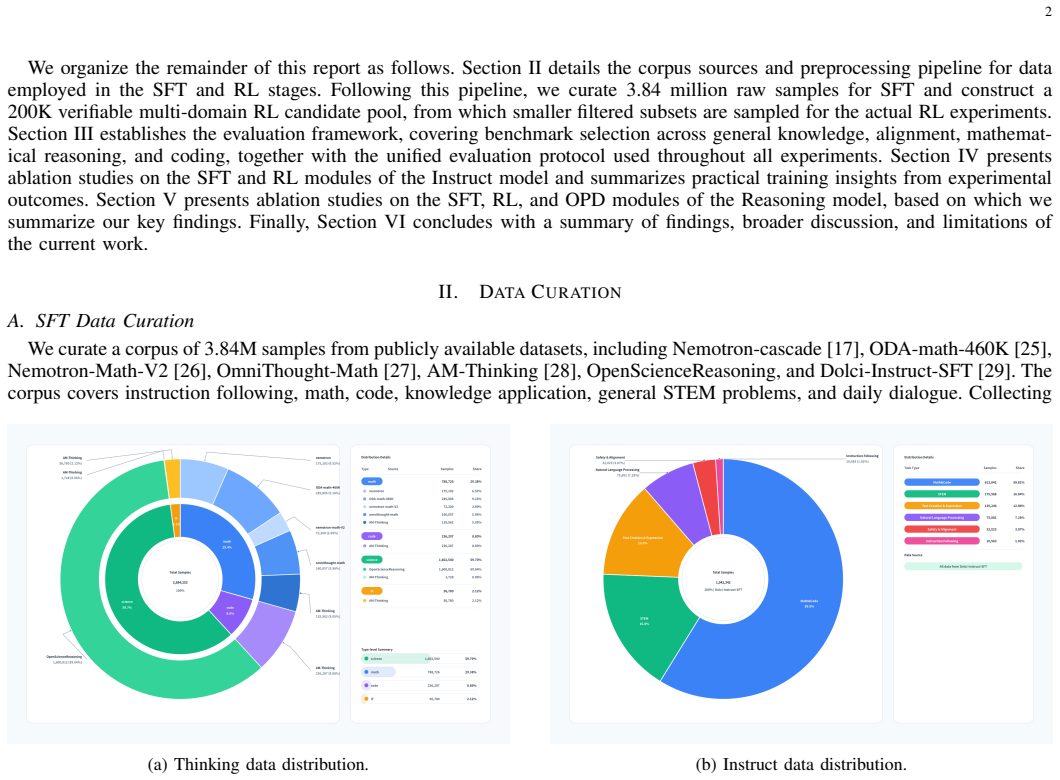
Post-training alignment determines the reasoning and human preference following capabilities of large language models, yet most existing works withhold detailed data construction, filtering rules and training recipes, which hinders community reproducibility and lightweight model optimization. This work presents NebulaExp, a fully transparent, ablation-driven post-training pipeline built on Qwen3-8B-base, covering two orthogonal model branches: general instruct model and complex reasoning-specialized model. We curate a raw corpus of 3.84M multi-source SFT samples and a 200K verifiable RL candidate pool, and design an end-to-end data processing stack including response distillation, multi-dimensional cross-verification filtering, fine-grained difficulty grading, task classification and diversity-aware sampling. For the Instruct branch, our three-stage optimized supervised fine-tuning approach NebulaExp-Ins-SFT improves the average benchmark score from the 55.01 baseline of Qwen3-8B-nothink to 60.99. GRPO reinforcement learning then further elevates the average score to 61.85. For the Reasoning branch, medium-difficulty GRPO RL improves average reasoning score from 73.88 to 75.17. To address RL's dependency on task verifiers, we systematically investigate single-teacher and multi-teacher OPD (MOPD): utilizing merely 4K instruction-following samples and outperforms RL baseline by 3.26 points on IFEval with +4.43 average overall gain; MOPD fuses four domain-specialist teachers with merely 10K samples, lifting average performance by 4.18 over the base model. This report provides a fully reproducible empirical post-training recipe for 8B-scale LLMs, and comprehensively dissects the capability trade-offs among instruction adherence, mathematical reasoning, code generation and general knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents NebulaExp, a transparent ablation-driven post-training pipeline on Qwen3-8B-base with two branches (general instruct and reasoning-specialized). It curates 3.84M multi-source SFT samples and 200K RL candidates, applying response distillation, multi-dimensional cross-verification filtering, difficulty grading, task classification, and diversity-aware sampling. Reported results include NebulaExp-Ins-SFT raising average benchmark score from 55.01 to 60.99, GRPO RL to 61.85; medium-difficulty GRPO RL raising reasoning score from 73.88 to 75.17; and MOPD variants (single-teacher with 4K samples outperforming RL by 3.26 on IFEval with +4.43 overall; multi-teacher with 10K samples lifting average by 4.18 over base). The work claims to provide a fully reproducible recipe dissecting trade-offs across instruction, math, code, and knowledge.
Significance. If the reported gains reflect genuine capability improvements rather than curation artifacts, the work supplies a valuable, fully documented empirical recipe and ablation study for 8B-scale post-training, including RL alternatives like MOPD. The emphasis on transparency, full-scale ablations, and explicit trade-off analysis would strengthen reproducibility in the field.
major comments (3)
- [Data curation / filtering stack] Data curation and filtering sections: The manuscript reports no decontamination procedures (e.g., n-gram overlap, membership inference, or held-out validation against the specific benchmarks contributing to the 55.01 baseline and subsequent 60.99/61.85 averages). This is load-bearing for the central claim that the end-to-end stack (response distillation + multi-dimensional filtering + diversity sampling) produces genuine gains rather than benchmark-specific artifacts or leakage.
- [Results / benchmark tables] Results and evaluation sections: No error bars, standard deviations across runs, or statistical significance tests are supplied for any reported deltas (e.g., +5.98 from SFT, +0.86 from GRPO, +4.18 from MOPD). Without these, the numeric improvements cannot be assessed for robustness, undermining interpretation of the ablation-driven claims.
- [MOPD / OPD experiments] MOPD experiments: The claims that single-teacher MOPD with 4K samples outperforms the RL baseline by 3.26 on IFEval (+4.43 overall) and multi-teacher MOPD with 10K samples lifts average performance by 4.18 require explicit specification of the exact benchmark suite, the RL baseline configuration being compared, and confirmation that the 10K samples were selected without reference to test performance.
minor comments (2)
- [Abstract / Introduction] The baseline 'Qwen3-8B-nothink' is referenced without a clear definition or citation in the abstract or early sections; this notation should be expanded on first use.
- [Ablation study] The paper claims 'full-scale ablation research' and 'comprehensively dissects' trade-offs, yet the provided text does not enumerate the specific ablation tables or figures that isolate each pipeline component (filtering, grading, sampling).
Simulated Author's Rebuttal
We thank the referee for the insightful comments. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: Data curation and filtering sections: The manuscript reports no decontamination procedures (e.g., n-gram overlap, membership inference, or held-out validation against the specific benchmarks contributing to the 55.01 baseline and subsequent 60.99/61.85 averages). This is load-bearing for the central claim that the end-to-end stack (response distillation + multi-dimensional filtering + diversity sampling) produces genuine gains rather than benchmark-specific artifacts or leakage.
Authors: We agree that explicit documentation of decontamination is essential for validating the claims. Although our multi-dimensional cross-verification and filtering stack was intended to address potential contamination, we did not detail specific n-gram overlap or membership inference checks in the manuscript. We will revise the data curation section to include a description of the decontamination procedures applied, including n-gram overlap analysis against the evaluation benchmarks and use of held-out validation sets. revision: yes
-
Referee: Results and evaluation sections: No error bars, standard deviations across runs, or statistical significance tests are supplied for any reported deltas (e.g., +5.98 from SFT, +0.86 from GRPO, +4.18 from MOPD). Without these, the numeric improvements cannot be assessed for robustness, undermining interpretation of the ablation-driven claims.
Authors: We acknowledge that the lack of error bars and statistical tests makes it difficult to assess the robustness of the reported improvements. Given the substantial computational resources required for each full-scale training run, we performed single runs for the reported configurations. We will add a note in the results section acknowledging this limitation and discussing the consistency of gains across the ablation studies as supporting evidence for the trends observed. revision: partial
-
Referee: MOPD experiments: The claims that single-teacher MOPD with 4K samples outperforms the RL baseline by 3.26 on IFEval (+4.43 overall) and multi-teacher MOPD with 10K samples lifts average performance by 4.18 require explicit specification of the exact benchmark suite, the RL baseline configuration being compared, and confirmation that the 10K samples were selected without reference to test performance.
Authors: We will update the MOPD experiments section to explicitly list the full benchmark suite used for the averages and IFEval, provide the precise configuration details for the GRPO RL baseline (including hyperparameters and training setup), and add a statement confirming that the selection of the 10K samples was performed solely based on the training data properties and diversity criteria, without any access to or reference to test set performance. revision: yes
Circularity Check
No circularity: purely empirical reporting of training runs and benchmarks
full rationale
The manuscript describes data curation (3.84M SFT samples, 200K RL pool), filtering rules, SFT stages, GRPO RL, and MOPD variants, then reports benchmark deltas (55.01→60.99→61.85, etc.). No equations, predictions, or derivations appear that reduce results to fitted inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core claims. All performance numbers are direct experimental outcomes, so the work is self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthramet al., “Openai gpt-5 system card,” arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[3]
Deepseek-v4: Towards highly efficient million-token context intelligence,
DeepSeek-AI, “Deepseek-v4: Towards highly efficient million-token context intelligence,”arXiv preprint, 2026
2026
-
[4]
The llama 4 herd: Architecture, training, evaluation, and deployment notes,
A. Adcock, A. Srivastava, A. Dubey, A. Jauhri, A. Pande, A. Pandey, A. Sharma, A. Kadian, A. Kumawat, A. Kelseyet al., “The llama 4 herd: Architecture, training, evaluation, and deployment notes,”arXiv preprint arXiv:2601.11659, 2026
arXiv 2026
-
[5]
Measuring massive multitask language understanding,
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,”arXiv preprint arXiv:2009.03300, 2020
Pith/arXiv arXiv 2009
-
[6]
Training verifiers to solve math word problems, 2021,
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakanoet al., “Training verifiers to solve math word problems, 2021,”URL https://arxiv. org/abs/2110.14168, vol. 9, 2021
Pith/arXiv arXiv 2021
-
[7]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[9]
Livecodebench: Holistic and contamination free evaluation of large language models for code,
N. Jain, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica, “Livecodebench: Holistic and contamination free evaluation of large language models for code,” inInternational Conference on Learning Representations, 2025
2025
-
[10]
Let’s verify step by step,
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe, “Let’s verify step by step,” in International Conference on Learning Representations, 2024
2024
-
[11]
(2025) Aime problems and solutions, 2025
Art of Problem Solving. (2025) Aime problems and solutions, 2025. [Online]. Available: https://artofproblemsolving.com/wiki/index.php/AIME Problems and Solutions
2025
-
[13]
Are we done with mmlu?
A. P. Gema, J. O. J. Leang, G. Hong, A. Devoto, A. C. M. Mancino, R. Saxena, X. He, Y . Zhao, X. Du, M. R. G. Madaniet al., “Are we done with mmlu?” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 5069–5096
2025
-
[14]
Q. Zhu, F. Huang, R. Peng, K. Lu, B. Yu, Q. Cheng, X. Qiu, X. Huang, and J. Lin, “Autologi: Automated generation of logic puzzles for evaluating reasoning abilities of large language models,”arXiv preprint arXiv:2502.16906, 2025. 28
arXiv 2025
-
[15]
Zebralogic: On the scaling limits of llms for logical reasoning,
B. Y . Lin, R. L. Bras, K. Richardson, A. Sabharwal, R. Poovendran, P. Clark, and Y . Choi, “Zebralogic: On the scaling limits of llms for logical reasoning,” arXiv preprint arXiv:2502.01100, 2025
arXiv 2025
-
[17]
Nemotron-cascade: Scaling cascaded reinforcement learning for general-purpose reasoning models,
B. Wang, C. Lee, N. Lee, S.-C. Lin, W. Dai, Y . Chen, Y . Chen, Z. Yang, Z. Liu, M. Shoeybiet al., “Nemotron-cascade: Scaling cascaded reinforcement learning for general-purpose reasoning models,”arXiv preprint arXiv:2512.13607, 2025
arXiv 2025
-
[18]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huanget al., “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023
Pith/arXiv arXiv 2023
-
[19]
Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model,
A. Liu, B. Feng, B. Wang, B. Wang, B. Liu, C. Zhao, C. Dengr, C. Ruan, D. Dai, D. Guoet al., “Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model,”arXiv preprint arXiv:2405.04434, 2024
Pith/arXiv arXiv 2024
-
[20]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huang, G. Dong, H. Wei, H. Lin, J. Tang, J. Wang, J. Yang, J. Tu, J. Zhang, J. Ma, J. Yang, J. Xu, J. Zhou, J. Bai, J. He, J. Lin, K. Dang, K. Lu, K. Chen, K. Yang, M. Li, M. Xue, N. Ni, P. Zhang, P. Wang, R. Peng, R. Men, R. Gao, R. Lin, S. Wang, S. Bai, S. Tan, T. Zhu, T. Li, T...
Pith/arXiv arXiv 2024
-
[21]
A. Y . et al., “Qwen2.5 technical report,”arXiv preprint arXiv:2412.15115, 2024
Pith/arXiv arXiv 2024
-
[22]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[23]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[24]
Qwen3. 5: Accelerating productivity with native multimodal agents, february 2026,
Q. Team, “Qwen3. 5: Accelerating productivity with native multimodal agents, february 2026,”URL https://qwen. ai/blog, 2026
2026
-
[25]
Closing the data loop: Using opendataarena to engineer superior training datasets,
X. Gao, X. Wang, Y . Zhu, M. Cai, C. He, and L. Wu, “Closing the data loop: Using opendataarena to engineer superior training datasets,”arXiv preprint arXiv:2601.09733, 2025
arXiv 2025
-
[26]
W. Du, S. Toshniwal, B. Kisacanin, S. Mahdavi, I. Moshkov, G. Armstrong, S. Ge, E. Minasyan, F. Chen, and I. Gitman, “Nemotron-math: Efficient long-context distillation of mathematical reasoning from multi-mode supervision,”arXiv preprint arXiv:2512.15489, 2025
arXiv 2025
-
[27]
Reasoning with omnithought: A large cot dataset with verbosity and cognitive difficulty annotations,
W. Cai, C. Wang, J. Yan, J. Huang, and X. Fang, “Reasoning with omnithought: A large cot dataset with verbosity and cognitive difficulty annotations,” arXiv preprint arXiv:2505.10937, 2025
arXiv 2025
-
[28]
Not all correct answers are equal: Why your distillation source matters,
X. Tian, Y . Ji, H. Wang, S. Chen, S. Zhao, Y . Peng, H. Zhao, and X. Li, “Not all correct answers are equal: Why your distillation source matters,”arXiv preprint arXiv:2505.14464, 2025
arXiv 2025
-
[29]
T. Olmo, A. Ettinger, A. Bertsch, B. Kuehl, D. Graham, D. Heineman, D. Groeneveld, F. Brahman, F. Timbers, H. Ivison, J. Morrison, J. Poznanski, K. Lo, L. Soldaini, M. Jordan, M. Chen, M. Noukhovitch, N. Lambert, P. Walsh, P. Dasigi, R. Berry, S. Malik, S. Shah, S. Geng, S. Arora, S. Gupta, T. Anderson, T. Xiao, T. Murray, T. Romero, V . Graf, A. Asai, A....
Pith/arXiv arXiv 2025
-
[30]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[31]
Instruction-following evaluation for large language models,
J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y . Luan, D. Zhou, and L. Hou, “Instruction-following evaluation for large language models,”arXiv preprint arXiv:2311.07911, 2023
Pith/arXiv arXiv 2023
-
[32]
Glm-5: from vibe coding to agentic engineering,
A. Zeng, X. Lv, Z. Hou, Z. Du, Q. Zheng, B. Chen, D. Yin, C. Ge, C. Huang, C. Xieet al., “Glm-5: from vibe coding to agentic engineering,”arXiv preprint arXiv:2602.15763, 2026
Pith/arXiv arXiv 2026
-
[33]
Eurus-2-rl-data,
PRIME-RL, “Eurus-2-rl-data,” 2024. [Online]. Available: https://huggingface.co/datasets/PRIME-RL/Eurus-2-RL-Data
2024
-
[34]
Generalizing verifiable instruction following,
V . Pyatkin, S. Malik, V . Graf, H. Ivison, S. Huang, P. Dasigi, N. Lambert, and H. Hajishirzi, “Generalizing verifiable instruction following,” 2025
2025
-
[35]
Gpqa: A graduate-level google-proof q&a benchmark,
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y . Pang, J. Dirani, J. Michael, and S. R. Bowman, “Gpqa: A graduate-level google-proof q&a benchmark,” arXiv preprint arXiv:2311.12022, 2023
Pith/arXiv arXiv 2023
-
[36]
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models,
Y . Huang, Y . Bai, Z. Zhu, J. Zhang, J. Zhang, T. Su, J. Liu, C. Lv, Y . Zhang, Y . Fuet al., “C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models,”Advances in Neural Information Processing Systems, vol. 36, pp. 62 991–63 010, 2023
2023
-
[37]
Livebench: A challenging, contamination- free llm benchmark,
C. White, S. Dooley, M. Roberts, A. Pal, B. Feuer, S. Jain, R. Shwartz-Ziv, N. Jain, K. Saifullah, S. Naiduet al., “Livebench: A challenging, contamination- free llm benchmark,”arXiv preprint arXiv:2406.19314, 2024
Pith/arXiv arXiv 2024
-
[38]
From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning,
M. Li, Y . Zhang, Z. Li, J. Chen, L. Chen, N. Cheng, J. Wang, T. Zhou, and J. Xiao, “From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Pap...
2024
-
[39]
Deepseekmath: Pushing the limits of mathematical reasoning in open language models,
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[40]
Distilling the knowledge in a neural network,
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[41]
On-policy distillation of language models: Learning from self- generated mistakes,
R. Agarwal, N. Vieillard, Y . Zhou, P. Stanczyk, S. Ramos, M. Geist, and O. Bachem, “On-policy distillation of language models: Learning from self- generated mistakes,” inInternational Conference on Learning Representations (ICLR), 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.