UOL@IDEM at BEA 2026 Shared Task 1: Neural Fusion and Feature-Rich Modeling for L1-Aware Vocabulary Difficulty Prediction
Pith reviewed 2026-06-25 23:59 UTC · model grok-4.3
The pith
Multilingual sentence embeddings fused with frequency and cognate features improve L1-aware vocabulary difficulty regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
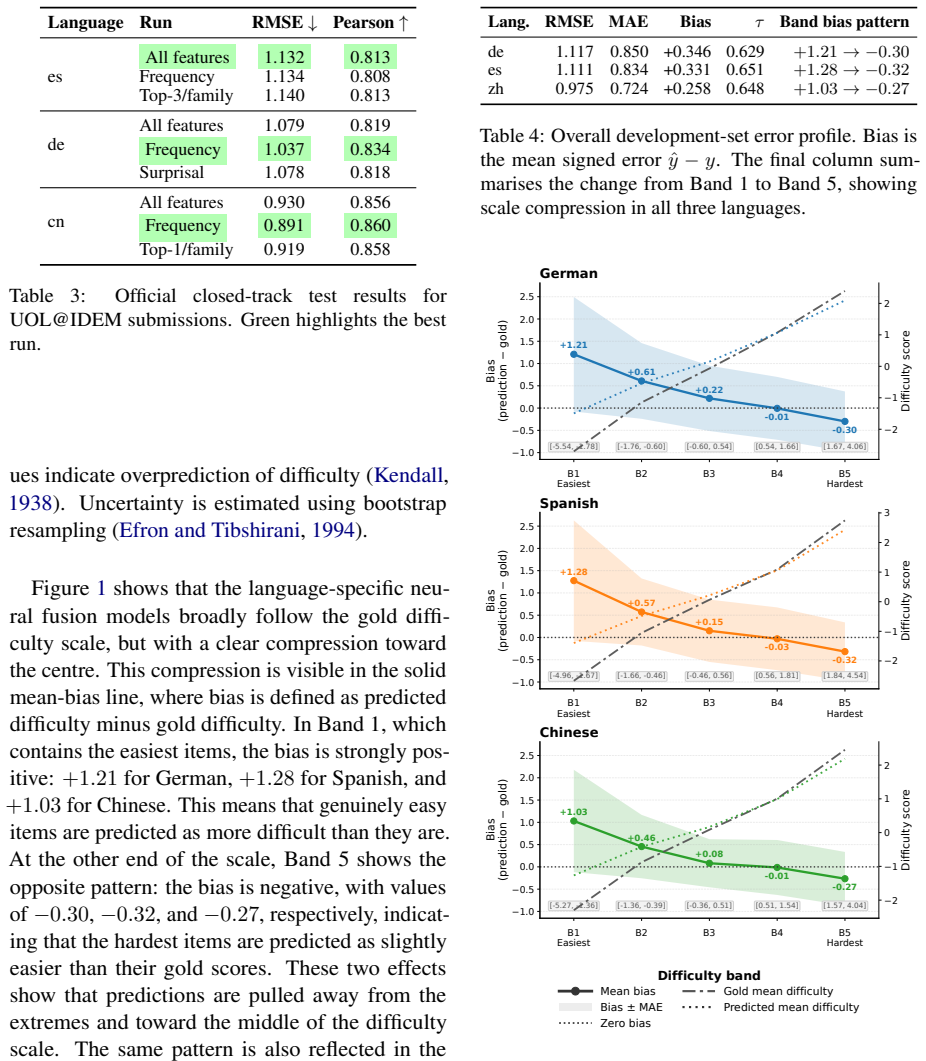
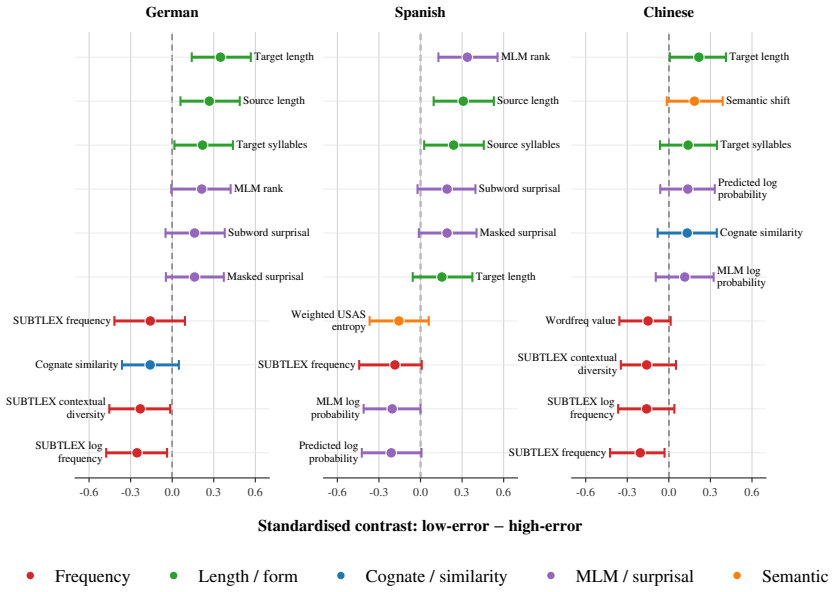
Our system combines multilingual contextual representations with engineered features capturing frequency, surface form, retrieval evidence, semantic alignment, cognate similarity, and masked-language-model predictability. Development results show consistent gains over the official closed-track baselines, with sentence-embedding encoders such as BGE-M3, multilingual E5, and LaBSE performing best. Official submissions achieve RMSE scores of 1.132, 1.037, and 0.891 for Spanish, German, and Chinese, respectively. Feature analysis identifies frequency as the most stable predictor, while contextual predictability, form similarity, retrieval, and semantic features provide complementary L1-sensitive
What carries the argument
Fusion of sentence-embedding encoders (BGE-M3, multilingual E5, LaBSE) with six L1-sensitive engineered features for regression.
If this is right
- Frequency remains the single most stable predictor across the three target languages.
- Contextual predictability and cognate similarity add measurable L1-specific value on top of raw embeddings.
- The resulting models rank items reliably but tend to over-predict difficulty for the easiest words.
- Separate per-language models outperform a single multilingual model under the closed-track constraints.
Where Pith is reading between the lines
- The same feature set could be tested on additional learner languages without retraining the encoders from scratch.
- Error patterns on easy items suggest that calibration adjustments might further reduce RMSE without changing the feature set.
Load-bearing premise
The selected engineered features supply complementary L1-sensitive signals that produce measurable gains over the provided baselines.
What would settle it
A replication in which the same sentence encoders plus the six engineered features yield equal or higher RMSE than the official baselines on the hidden test set.
Figures
read the original abstract
This paper describes UOL@IDEM's closed-track submission to the BEA 2026 shared task on L1-aware vocabulary difficulty prediction. We model the task as regression and train separate systems for Spanish, German, and Mandarin Chinese\footnote{Below we use \emph{Chinese} for brevity.}. Our system combines multilingual contextual representations with engineered features capturing frequency, surface form, retrieval evidence, semantic alignment, cognate similarity, and masked-language-model predictability. Development results show consistent gains over the official closed-track baselines, with sentence-embedding encoders such as BGE-M3, multilingual E5, and LaBSE performing best. Official submissions achieve RMSE scores of 1.132, 1.037, and 0.891 for Spanish, German, and Chinese, respectively. Feature analysis identifies frequency as the most stable predictor, while contextual predictability, form similarity, retrieval, and semantic features provide complementary L1-sensitive signals. Error analysis shows strong ranking performance but weaker calibration for the easiest items, which are often overpredicted. See https://github.com/Nouran-Khallaf/UoL-IDEM-BEA2026-Vocabulary-Difficulty-Prediction
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes UOL@IDEM's closed-track submission to the BEA 2026 Shared Task 1 on L1-aware vocabulary difficulty prediction. The authors frame the task as regression and train separate models for Spanish, German, and Chinese. Their approach fuses multilingual sentence embeddings (BGE-M3, multilingual E5, LaBSE) with engineered features capturing frequency, surface form, retrieval evidence, semantic alignment, cognate similarity, and masked-language-model predictability. Development results show gains over official closed-track baselines; official submissions report RMSE values of 1.132 (Spanish), 1.037 (German), and 0.891 (Chinese). Feature analysis identifies frequency as the most stable predictor while the remaining features supply complementary L1-sensitive signals. Error analysis notes strong ranking performance but weaker calibration on the easiest items.
Significance. If the reported RMSE gains and feature rankings hold under proper controls, the work supplies a competitive system description and concrete evidence that frequency remains dominant while contextual and L1-specific features add value. The explicit identification of complementary signals and the error patterns on easy items are useful observations for the lexical difficulty modeling community.
minor comments (3)
- [Abstract / Feature analysis] The abstract states that 'contextual predictability, form similarity, retrieval, and semantic features provide complementary L1-sensitive signals' but does not report the quantitative ablation or permutation importance values that would substantiate the complementarity claim; add these numbers (with confidence intervals) in the feature-analysis section.
- [Development results] The manuscript reports official RMSE scores but does not indicate whether the development-set gains were obtained with a single fixed train/dev split or with cross-validation; clarify the evaluation protocol and any statistical significance tests performed against the baselines.
- [Abstract] The GitHub link appears inline in the abstract; move it to a footnote or proper reference entry for conventional formatting.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper is a standard shared-task system description reporting regression performance (RMSE) on development and official test sets for L1-aware vocabulary difficulty prediction. It combines sentence embeddings with engineered features and notes frequency as the strongest predictor with others providing complementary signals. No equations, self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text or abstract. Results are presented as empirical outcomes on held-out shared-task data rather than any derivation that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- regression fusion weights and embedding fine-tuning parameters
axioms (1)
- domain assumption The official closed-track baselines and the shared-task test data constitute a fair and stable evaluation of L1-aware difficulty prediction.
Reference graph
Works this paper leans on
-
[1]
2026 , howpublished =
BEA 2026 Shared Task:. 2026 , howpublished =
2026
-
[2]
Proceedings of the 21st Workshop on Innovative Use of NLP for Building Educational Applications (
Felice, Mariano and Skidmore, Lucy , title =. Proceedings of the 21st Workshop on Innovative Use of NLP for Building Educational Applications (. 2026 , address =
2026
-
[3]
Proceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2025) , year =
Transformer Architectures for Vocabulary Test Item Difficulty Prediction , author =. Proceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2025) , year =
2025
-
[4]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year =
Unsupervised Cross-lingual Representation Learning at Scale , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year =
-
[5]
2019 , pages =
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle =. 2019 , pages =
2019
-
[6]
Language-agnostic
Feng, Fangxiaoyu and Yang, Yinfei and Cer, Daniel and Arivazhagan, Naveen and Wang, Wei , booktitle =. Language-agnostic. 2022 , pages =
2022
-
[7]
Multilingual
Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu , journal =. Multilingual. 2024 , url =
2024
-
[8]
Sentence-
Reimers, Nils and Gurevych, Iryna , booktitle =. Sentence-. 2019 , pages =
2019
-
[9]
2024 , pages =
Chen, Jianlv and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng , booktitle =. 2024 , pages =
2024
-
[10]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year =
Masked Language Model Scoring , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year =
-
[11]
2021 , pages =
Shardlow, Matthew and Evans, Richard and Zampieri, Marcos , booktitle =. 2021 , pages =
2021
-
[12]
Predicting lexical complexity in
Shardlow, Matthew and Evans, Richard and Zampieri, Marcos , journal =. Predicting lexical complexity in. 2022 , volume =. doi:10.1007/s10579-022-09588-2 , url =
-
[13]
arXiv preprint arXiv:2303.04851 , year =
Lexical Complexity Prediction: An Overview , author =. arXiv preprint arXiv:2303.04851 , year =
-
[14]
The UCREL Semantic Analysis System , author =. Proceedings of the Workshop on Beyond Named Entity Recognition: Semantic Labelling for NLP Tasks in Association with the 4th International Conference on Language Resources and Evaluation (LREC 2004) , year =
2004
-
[15]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =
CogNet: A Large-Scale Cognate Database , author =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =. 2019 , address =
2019
-
[16]
Language Resources and Evaluation , year =
A Large and Evolving Cognate Database , author =. Language Resources and Evaluation , year =. doi:10.1007/s10579-021-09544-6 , url =
-
[17]
Advances in Neural Information Processing Systems , volume=
A Unified Approach to Interpreting Model Predictions , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Nature Machine Intelligence , volume=
From local explanations to global understanding with explainable AI for trees , author=. Nature Machine Intelligence , volume=. 2020 , doi=
2020
-
[19]
Statistical Applications in Genetics and Molecular Biology , volume =
Super Learner , author =. Statistical Applications in Genetics and Molecular Biology , volume =. 2007 , doi =
2007
-
[20]
The Prague Bulletin of Mathematical Linguistics , volume =
Language Adaptation for Extending Post-editing Estimates for Closely Related Languages , author =. The Prague Bulletin of Mathematical Linguistics , volume =. 2016 , url =
2016
-
[21]
Language Resources and Evaluation , volume =
Kilgarriff, Adam and Charalabopoulou, Frieda and Gavrilidou, Maria and Johannessen, Janne Bondi and Khalil, Saussan and Johansson Kokkinakis, Sofie and Lew, Robert and Sharoff, Serge and Vadlapudi, Ravikiran and Volodina, Elena , title =. Language Resources and Evaluation , volume =. 2014 , doi =
2014
-
[22]
2001 , url =
Common European Framework of Reference for Languages: Learning, Teaching, Assessment , publisher =. 2001 , url =
2001
-
[23]
doi:10.5281/zenodo.1443582 , url =
Robyn Speer and Joshua Chin and Andrew Lin and Sara Jewett and Lance Nathan , title =. doi:10.5281/zenodo.1443582 , url =
-
[24]
Behavior Research Methods , volume =
Brysbaert, Marc and New, Boris , title =. Behavior Research Methods , volume =. 2009 , doi =
2009
-
[25]
van Heuven, Walter J. B. and Mandera, Pawel and Keuleers, Emmanuel and Brysbaert, Marc , title =. The Quarterly Journal of Experimental Psychology , volume =. 2014 , doi =
2014
-
[26]
Serge Sharoff and Dirk Goldhahn and Uwe Quasthoff , title =
-
[27]
Honnibal, Matthew and Montani, Ines and Van Landeghem, Sofie and Boyd, Adriane , title =. 2020 , publisher =. doi:10.5281/zenodo.1212303 , url =
-
[28]
How Multilingual is Multilingual BERT ?
How Multilingual is Multilingual BERT? , author =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =. 2019 , publisher =. doi:10.18653/v1/P19-1493 , url =
-
[29]
The Annals of Statistics , volume =
Efron, Bradley , title =. The Annals of Statistics , volume =. 1979 , doi =
1979
-
[30]
Kendall, M. G. , title =. Biometrika , volume =. 1938 , doi =
1938
-
[31]
and Whitney, Donald R
Mann, Henry B. and Whitney, Donald R. , title =. The Annals of Mathematical Statistics , volume =. 1947 , doi =
1947
-
[32]
Biometrics Bulletin , volume =
Wilcoxon, Frank , title =. Biometrics Bulletin , volume =. 1945 , doi =
1945
-
[33]
Journal of the Royal Statistical Society: Series B (Methodological) , volume =
Benjamini, Yoav and Hochberg, Yosef , title =. Journal of the Royal Statistical Society: Series B (Methodological) , volume =. 1995 , doi =
1995
-
[34]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume =
Zou, Hui and Hastie, Trevor , title =. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume =. 2005 , doi =
2005
-
[35]
MacQueen, J. B. , title =. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics , editor =. 1967 , publisher =
1967
-
[36]
Quantifying the Contribution of MWE s and Polysemy in Translation Errors for E nglish -- I gbo MT
Ohuoba, Adaeze and Sharoff, Serge and Walker, Callum. Quantifying the Contribution of MWE s and Polysemy in Translation Errors for E nglish -- I gbo MT. Proceedings of the 25th Annual Conference of the European Association for Machine Translation (Volume 1). 2024
2024
-
[37]
1994 , publisher =
An Introduction to the Bootstrap , author =. 1994 , publisher =
1994
-
[38]
Journal of the Royal Statistical Society: Series B , volume =
Regularization and Variable Selection via the Elastic Net , author =. Journal of the Royal Statistical Society: Series B , volume =. 2005 , doi =
2005
-
[39]
Psychological Bulletin , year =
Cliff, Norman , title =. Psychological Bulletin , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.