Blending Proxy Metrics with a North Star
Pith reviewed 2026-06-26 13:14 UTC · model grok-4.3
The pith
An optimal blending method combines proxy metrics with the north star metric using weights that depend on experiment power and proxy quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
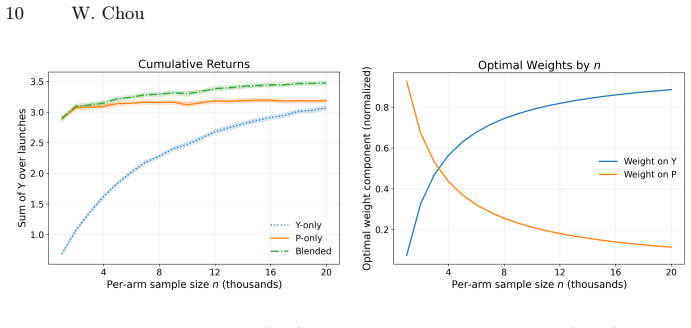
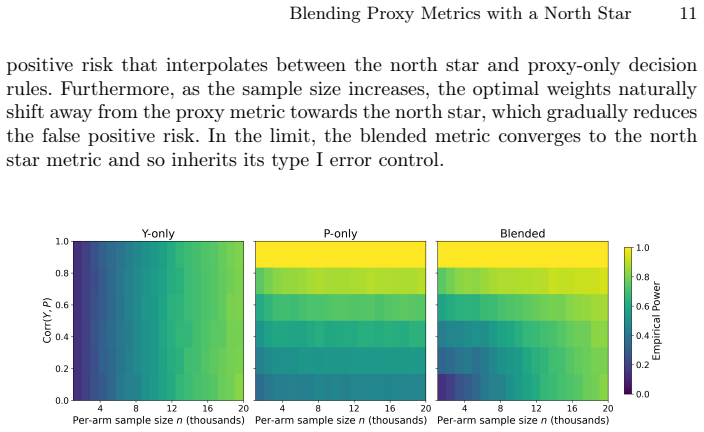
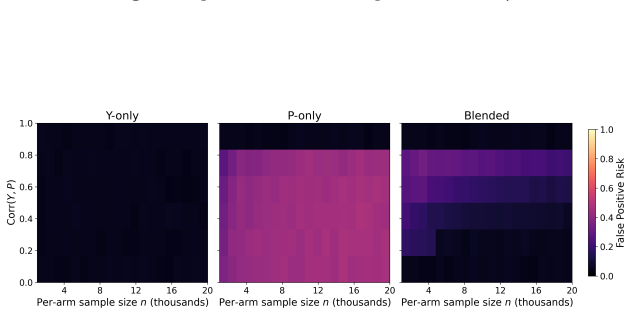
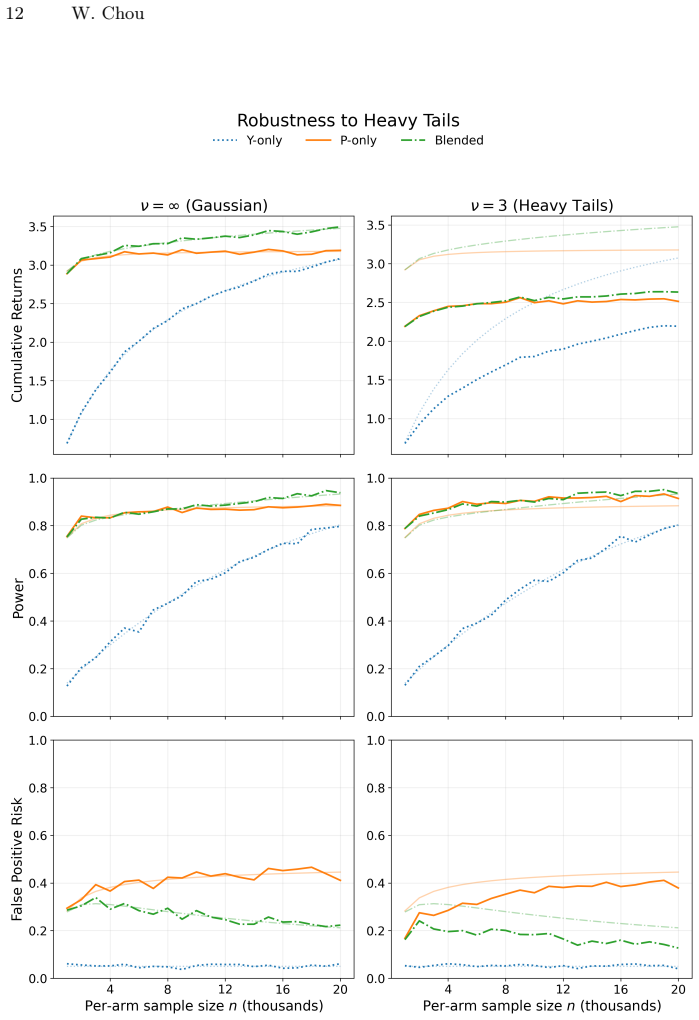
The paper claims that an optimal blending approach exists which smoothly guides decision-making towards the north star as the power of the experiment increases and away from the north star as the quality of the proxy metric improves. This decision-making framework carries direct implications for the design of individual experiments and of entire experimentation programs: experimenters equipped with better proxy metrics should run smaller and more experiments, while those with worse proxies should run larger and fewer ones. The optimal blending weights and experiment sizes can be estimated from past experiments, and the approach has been applied in practice to an experimentation program.
What carries the argument
Optimal blending weights that vary with experiment power and a quantifiable measure of proxy quality relative to the north star.
If this is right
- With better proxy metrics, experimenters should run smaller and more experiments.
- With higher-powered experiments, more weight should shift to the north star metric.
- Worse proxy metrics imply running larger and fewer experiments.
- Historical experiments can be used to estimate the optimal weights and sizes for future tests.
Where Pith is reading between the lines
- The same blending logic could apply to any setting that trades off fast but noisy signals against slower but accurate outcomes.
- Organizations could reduce overall experimentation costs by investing in higher-quality proxies that allow more tests per unit of time.
- The framework could be tested by comparing blended versus single-metric decisions in controlled simulations where the true long-term effect is known in advance.
Load-bearing premise
A quantifiable and stable measure of proxy quality relative to the north star exists, and historical experiments provide unbiased estimates of the optimal blending weights.
What would settle it
Apply the estimated blending weights to a new set of experiments with known long-term north star outcomes and check whether the blended decisions match the north star outcomes more closely than decisions based on the proxy or north star alone.
Figures
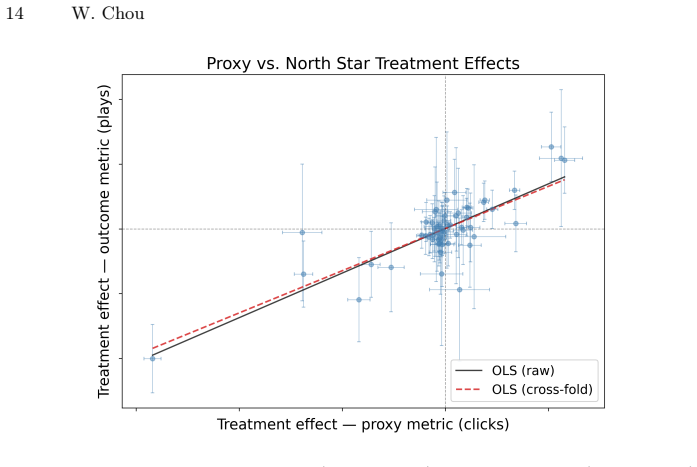
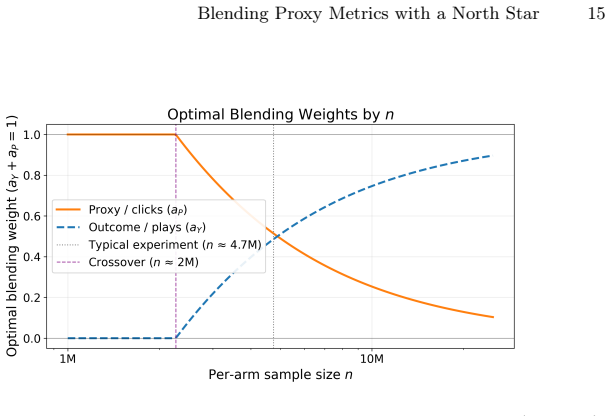
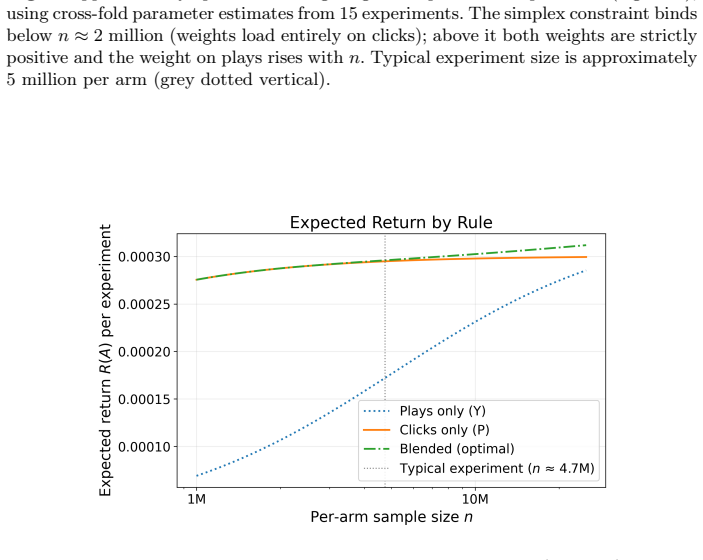
read the original abstract
Proxy metrics are widely used to improve the precision and velocity of online experimentation (aka A/B testing). Although proxies are often motivated by long-term outcomes that the experimenter does not observe, in many settings they are used alongside a contemporaneous but statistically insensitive north star. This can lead to a practical dilemma: when should experimenters trust the proxy metric, and when should they trust the north star? In this paper, I propose an optimal blending approach that smoothly guides decision-making towards the north star as the power of the experiment increases and away from the north star as the quality of the proxy metric improves. I study the implications of this decision-making framework for the design of experiments and of experimentation programs. Equipped with better (worse) proxy metrics, experimenters should run smaller and more (larger and fewer) experiments. I show how to leverage past experiments to estimate optimal blending weights and experiment sizes. Lastly, I describe the real-world application of the methodology to an experimentation program at Netflix.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an optimal blending framework for proxy metrics and a contemporaneous but low-powered north star in online A/B testing. Blending weights are derived to shift decision-making toward the north star as experiment power grows and away from it as proxy quality improves; the weights and recommended experiment sizes are estimated from historical experiments. The paper examines design implications (smaller/more experiments with better proxies) and reports a real-world application at Netflix.
Significance. If the optimality derivation holds and the historical estimation is shown to be robust, the framework would supply a concrete, tunable rule for the common proxy-versus-north-star dilemma, directly affecting experiment sizing and program-level resource allocation in large-scale experimentation platforms.
major comments (2)
- [Abstract / estimation procedure] The central optimality claim rests on the existence of a stable, unbiased estimate of proxy quality (correlation with the north star) obtained from past experiments. The abstract states that historical experiments are used to estimate the weights, but supplies no derivation showing that this estimation remains valid under non-stationarity or selection on observed proxy effects; if either violation occurs, the derived weights become mis-calibrated for future use.
- [Implications for experiment design] The claim that experimenters should run smaller and more (larger and fewer) experiments when equipped with better (worse) proxies follows directly from the blending rule, yet the manuscript does not report a sensitivity analysis or simulation demonstrating that the recommended sizes remain approximately optimal when the proxy-north-star correlation is estimated with sampling error.
minor comments (2)
- Notation for the blending weights and the proxy-quality parameter should be introduced with explicit definitions and distinguished from any data-dependent estimates.
- The Netflix application section would benefit from a table contrasting the blended decisions against a pure-proxy and a pure-north-star baseline on the same set of experiments.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the assumptions and robustness of our proposed framework. We address each major comment in turn.
read point-by-point responses
-
Referee: [Abstract / estimation procedure] The central optimality claim rests on the existence of a stable, unbiased estimate of proxy quality (correlation with the north star) obtained from past experiments. The abstract states that historical experiments are used to estimate the weights, but supplies no derivation showing that this estimation remains valid under non-stationarity or selection on observed proxy effects; if either violation occurs, the derived weights become mis-calibrated for future use.
Authors: The manuscript assumes that the proxy quality, measured by the correlation with the north star, can be reliably estimated from historical experiments and remains stable. We do not provide a formal proof of unbiasedness under non-stationarity or selection bias, as the focus is on the blending framework itself. However, we recognize this as a valid concern. In the revision, we will expand the estimation section to include a discussion of these assumptions, potential biases, and practical recommendations for mitigating them, such as using time-weighted historical data or monitoring for drift. We will also note this as a limitation. revision: yes
-
Referee: [Implications for experiment design] The claim that experimenters should run smaller and more (larger and fewer) experiments when equipped with better (worse) proxies follows directly from the blending rule, yet the manuscript does not report a sensitivity analysis or simulation demonstrating that the recommended sizes remain approximately optimal when the proxy-north-star correlation is estimated with sampling error.
Authors: We agree that a sensitivity analysis would be valuable to assess how sampling variability in the estimated correlation affects the recommended experiment sizes. We will add a simulation study in the revised manuscript that introduces noise to the correlation estimate based on the number of historical experiments and evaluates the resulting variation in optimal sizes and blending weights. This will demonstrate the conditions under which the design recommendations remain robust. revision: yes
Circularity Check
No significant circularity: derivation self-contained with standard historical estimation
full rationale
The paper derives an optimal blending rule that trades proxy quality against experiment power and then separately shows how to estimate the resulting weights from historical experiments. This estimation is a conventional calibration step using external data and does not reduce the claimed optimality condition to a tautology or fitted input by construction. No self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the abstract or description. The central proposal remains independent of the fitted values it later calibrates.
Axiom & Free-Parameter Ledger
free parameters (1)
- blending weights
axioms (1)
- domain assumption A stable and quantifiable relationship exists between proxy metric quality and the north star that permits optimal blending.
Reference graph
Works this paper leans on
-
[1]
The Review of Economic Studies (2025)
Athey, S., Chetty, R., Imbens, G.W., Kang, H.: The surrogate index: Combining short-term proxies to estimate long-term treatment effects more rapidly and precisely. The Review of Economic Studies (2025). https://doi.org/10.1093/restud/rdaf087, advance article
-
[2]
In: AEA Papers and Proceedings
Azevedo, E.M., Deng, A., Montiel Olea, J.L., Weyl, E.G.: Empirical bayes estimation of treatment effects with many a/b tests: An overview. In: AEA Papers and Proceedings. vol. 109, pp. 43–47. American Economic Associa- tion (2019)
2019
-
[3]
Journal of Political Economy128(12) (2020)
Azevedo, E.M., Deng, A., Olea, J.L.M., Rao, J., Weyl, E.G.: A/b testing with fat tails. Journal of Political Economy128(12) (2020). https://doi.org/10.1086/710607, https://www.journals.uchicago.edu/doi/abs/10.1086/710607
-
[4]
Journal of Economic Theory210, 105646 (2023)
Azevedo, E.M., Mao, D., Olea, J.L.M., Velez, A.: The a/b testing problem with gaussian priors. Journal of Economic Theory210, 105646 (2023)
2023
-
[5]
In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Bibaut, A., Chou, W., Ejdemyr, S., Kallus, N.: Learning the covariance of treatment effects across many weak experiments. In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. pp. 153–162 (2024). https://doi.org/10.1145/3637528.3672034
-
[6]
Biostatistics1(1), 49–67 (2000)
Buyse, M., Molenberghs, G., Burzykowski, T., Renard, D., Geys, H.: The validation of surrogate endpoints in meta-analyses of randomized experi- ments. Biostatistics1(1), 49–67 (2000)
2000
-
[7]
In: Proceed- ings of the 31st ACM SIGKDD Conference on Knowledge Discov- ery and Data Mining (2025)
Chou, W., Gray, C., Kallus, N., Bibaut, A., Ejdemyr, S.: Eval- uating decision rules across many weak experiments. In: Proceed- ings of the 31st ACM SIGKDD Conference on Knowledge Discov- ery and Data Mining (2025). https://doi.org/10.1145/3711896.3737217, https://doi.org/10.1145/3711896.3737217
-
[8]
In: The World Wide Web Conference
Coey, D., Cunningham, T.: Improving treatment effect estimators through experiment splitting. In: The World Wide Web Conference. pp. 285–295 (2019)
2019
-
[9]
Cunningham, T., Kim, J.: Interpreting experiments with multiple outcomes (2022)
2022
-
[10]
In: Proceedings of the 30th ACM SIGKDD Con- ference on Knowledge Discovery and Data Mining
Deng, A., Hagar, L., Stevens, N.T., Xifara, T., Gandhi, A.: Metric decom- position in a/b tests. In: Proceedings of the 30th ACM SIGKDD Con- ference on Knowledge Discovery and Data Mining. pp. 4885–4895 (2024). https://doi.org/10.1145/3637528.3671556
-
[11]
In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Min- ing
Deng, A., Shi, X.: Data-driven metric development for online controlled experiments: Seven lessons learned. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Min- ing. pp. 77–86 (2016)
2016
-
[12]
Perspectives on psychological science9(6), 641–651 (2014) 18 W
Gelman, A., Carlin, J.: Beyond power calculations: Assessing type s (sign) and type m (magnitude) errors. Perspectives on psychological science9(6), 641–651 (2014) 18 W. Chou
2014
-
[13]
In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Kohavi, R., Chen, N.: False positives in a/b tests. In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. pp. 5240–5250 (2024). https://doi.org/10.1145/3637528.3671631
-
[14]
The American Statistician78(2), 135–149 (2024)
Larsen, N., Stallrich, J., Sengupta, S., Deng, A., Kohavi, R., Stevens, N.T.: Statistical challenges in online controlled experiments: A review of a/b test- ing methodology. The American Statistician78(2), 135–149 (2024)
2024
-
[15]
In: Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining
Lee, M.R., Shen, M.: Winner’s curse: Bias estimation for total effects of features in online controlled experiments. In: Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. pp. 491–499 (2018)
2018
-
[16]
Controlled clinical trials23(6), 607–625 (2002)
Molenberghs,G.,Buyse,M.,Geys,H.,Renard,D.,Burzykowski,T.,Alonso, A.:Statisticalchallengesintheevaluationofsurrogateendpointsinrandom- ized trials. Controlled clinical trials23(6), 607–625 (2002)
2002
-
[17]
Statistics in medicine8(4), 431–440 (1989)
Prentice, R.L.: Surrogate endpoints in clinical trials: definition and opera- tional criteria. Statistics in medicine8(4), 431–440 (1989)
1989
-
[18]
In: Proceed- ings of the 26th ACM Conference on Economics and Com- putation (2025)
Sudijono, T., Ejdemyr, S., Lal, A., Tingley, M.: Optimiz- ing returns from experimentation programs. In: Proceed- ings of the 26th ACM Conference on Economics and Com- putation (2025). https://doi.org/10.1145/3736252.3742638, https://dl.acm.org/doi/abs/10.1145/3736252.3742638
-
[19]
In: Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining
Tang, D., Agarwal, A., O’Brien, D., Meyer, M.: Overlapping experiment infrastructure: More, better, faster experimentation. In: Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. pp. 17–26 (2010)
2010
-
[20]
In: Proceedings of the 41st International Conference on Machine Learning
Tran, A., Bibaut, A., Kallus, N.: Inferring the long-term causal effects of long-term treatments from short-term experiments. In: Proceedings of the 41st International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 235, pp. 48565–48577. PMLR (2024), https://proceedings.mlr.press/v235/tran24b.html
2024
-
[21]
In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Tripuraneni, N., Richardson, L., D’Amour, A., Soriano, J., Yadlowsky, S.: Choosing a proxy metric from past experiments. In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. pp. 5803–5812 (2024). https://doi.org/10.1145/3637528.3671543
-
[22]
arXiv preprint arXiv:2311.11922 (2023)
Zhang, V., Zhao, M., Le, A., Kallus, N., et al.: Evaluating the surrogate index as a decision-making tool using 200 a/b tests at netflix. arXiv preprint arXiv:2311.11922 (2023)
arXiv 2023
-
[23]
Applied Stochastic Models in Business and Industry41(2), e70003 (2025)
Zito, A., Greaves, D., Soriano, J., Richardson, L.: Pareto optimal proxy metrics. Applied Stochastic Models in Business and Industry41(2), e70003 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.