TARN: Temporal Attentive Relation Network for Few-Shot and Zero-Shot Action Recognition
Pith reviewed 2026-05-24 18:27 UTC · model grok-4.3
The pith
Temporal attention aligns videos of variable length so a relation network can compare them for few-shot and zero-shot action recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
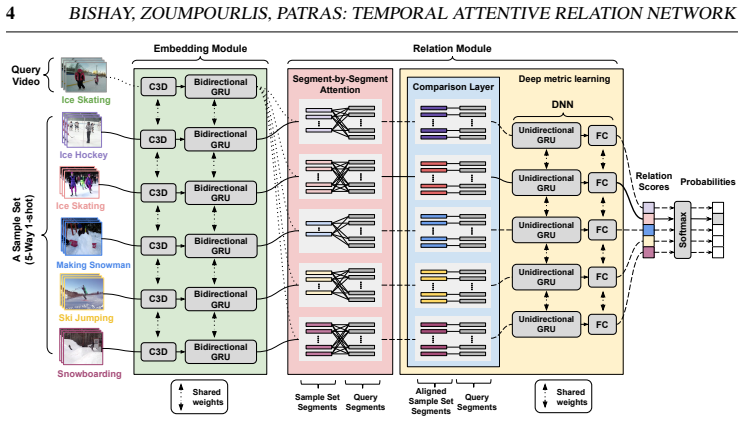
TARN uses attention to align variable-length videos or video-to-semantic representations, then learns a deep distance on the aligned segment features. An episode-based training scheme lets the network train end-to-end; the resulting model outperforms prior few-shot action recognition methods and matches them on zero-shot tasks without target-domain fine-tuning or additional memory representations.
What carries the argument
Temporal Attentive Relation Network that performs attention-based temporal alignment followed by segment-level learned distance computation.
Load-bearing premise
Attention will reliably align videos of different lengths and the learned segment distance will generalize to unseen action classes without target fine-tuning or extra memory.
What would settle it
On a held-out action dataset the method fails to exceed baseline accuracy in the few-shot setting when no target-domain fine-tuning or memory augmentation is allowed.
Figures
read the original abstract
In this paper we propose a novel Temporal Attentive Relation Network (TARN) for the problems of few-shot and zero-shot action recognition. At the heart of our network is a meta-learning approach that learns to compare representations of variable temporal length, that is, either two videos of different length (in the case of few-shot action recognition) or a video and a semantic representation such as word vector (in the case of zero-shot action recognition). By contrast to other works in few-shot and zero-shot action recognition, we a) utilise attention mechanisms so as to perform temporal alignment, and b) learn a deep-distance measure on the aligned representations at video segment level. We adopt an episode-based training scheme and train our network in an end-to-end manner. The proposed method does not require any fine-tuning in the target domain or maintaining additional representations as is the case of memory networks. Experimental results show that the proposed architecture outperforms the state of the art in few-shot action recognition, and achieves competitive results in zero-shot action recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TARN, a Temporal Attentive Relation Network for few-shot and zero-shot action recognition. It employs an episode-based meta-learning framework that uses attention mechanisms to align variable-length video segments and learns a deep distance metric at the segment level. The same architecture handles both video-video (few-shot) and video-semantic (zero-shot) comparisons without target-domain fine-tuning or additional memory representations. Experiments are reported to show outperformance over state-of-the-art methods in few-shot action recognition and competitive results in zero-shot action recognition.
Significance. If the experimental claims hold under full scrutiny of the datasets, baselines, and ablations, the work would provide a unified, memory-free meta-learning approach for variable-length video comparison that generalizes across few-shot and zero-shot regimes. This addresses a practical limitation in prior memory-network and fine-tuning-heavy methods for video action recognition.
minor comments (2)
- [Abstract] The abstract states that the method 'outperforms the state of the art' but does not name the specific datasets (e.g., HMDB51, UCF101) or the exact baselines against which gains are measured; this information should appear in the abstract or be cross-referenced to §4.
- [Method] Notation for the attention alignment and segment-level distance (presumably defined in the method section) should be introduced with explicit variable definitions before the first equation to improve readability for readers unfamiliar with relation networks.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work and the recommendation of minor revision. No major comments were listed in the report, so we have no specific points requiring rebuttal or clarification.
Circularity Check
No significant circularity detected
full rationale
The paper introduces TARN as a new end-to-end trainable architecture that uses attention for temporal alignment of variable-length videos and learns a segment-level deep distance metric within an episode-based meta-learning framework. Claims of outperformance rest on experimental results rather than any self-referential equations, fitted parameters renamed as predictions, or load-bearing self-citations. No derivation step reduces by construction to its inputs; the method description is internally consistent and externally falsifiable via standard benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Episode-based meta-learning training enables generalization to unseen action classes without target-domain fine-tuning
Reference graph
Works this paper leans on
-
[1]
Evaluation of output embeddings for fine-grained image classification
Zeynep Akata, Scott Reed, Daniel Walter, Honglak Lee, and Bernt Schiele. Evaluation of output embeddings for fine-grained image classification. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2927–2936, 2015
work page 2015
-
[2]
Neural machine translation by jointly learning to align and translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015
work page 2015
-
[3]
Learning phrase representations using rnn encoder–decoder for statistical machine translation
Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder–decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages 1724–1734. Association for Comput...
work page 2014
-
[4]
Jeff Donahue, Lisa Anne Hendricks, Marcus Rohrbach, Subhashini Venugopalan, Ser- gio Guadarrama, Kate Saenko, and Trevor Darrell. Long-term recurrent convolutional networks for visual recognition and description.IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(4):677–691, April 2017
work page 2017
-
[5]
One-shot learning of object categories
Li Fei-Fei, Rob Fergus, and Pietro Perona. One-shot learning of object categories. IEEE Transactions on Pattern Analysis and Machine Intelligence , 28(4):594–611, 2006
work page 2006
-
[6]
Unsupervised human action de- tection by action matching
Basura Fernando, Sareh Shirazi, and Stephen Gould. Unsupervised human action de- tection by action matching. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 1–9, 2017
work page 2017
-
[7]
Model-agnostic meta-learning for fast adaptation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, pages 1126–1135, 2017
work page 2017
-
[8]
Chuang Gan, Ming Lin, Yi Yang, Yueting Zhuang, and Alexander G. Hauptmann. Ex- ploring semantic inter-class relationships (SIR) for zero-shot action recognition. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, January 25-30, 2015, Austin, Texas, USA., pages 3769–3775, 2015
work page 2015
-
[9]
Learning attributes equals multi-source domain generalization
Chuang Gan, Tianbao Yang, and Boqing Gong. Learning attributes equals multi-source domain generalization. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV , USA, June 27-30, 2016, pages 87–97, 2016
work page 2016
-
[10]
Recognizing an action using its name: A knowledge-based approach
Chuang Gan, Yi Yang, Linchao Zhu, Deli Zhao, and Yueting Zhuang. Recognizing an action using its name: A knowledge-based approach. International Journal of Com- puter Vision, 120(1):61–77, 2016
work page 2016
-
[11]
Pairwise word interaction modeling with deep neural networks for semantic similarity measurement
Hua He and Jimmy Lin. Pairwise word interaction modeling with deep neural networks for semantic similarity measurement. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 937–948, 2016. 12 BISHA Y , ZOUMPOURLIS, PA TRAS: TEMPORAL A TTENTIVE RELA TION NETWORK
work page 2016
-
[12]
Identity mappings in deep residual networks
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part IV, pages 630– 645, 2016
work page 2016
-
[13]
Going deeper into action recog- nition: A survey
Samitha Herath, Mehrtash Harandi, and Fatih Porikli. Going deeper into action recog- nition: A survey. Image and vision computing, 60:4–21, 2017
work page 2017
- [14]
-
[15]
Large-scale video classification with convolutional neural networks
Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classification with convolutional neural networks. In Proceedings of International Computer Vision and Pattern Recognition, 2014
work page 2014
-
[16]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vi- jayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015
work page 2015
-
[18]
Siamese neural networks for one-shot image recognition
Gregory Koch, Richard Zemel, and Ruslan Salakhutdinov. Siamese neural networks for one-shot image recognition. In ICML deep learning workshop, volume 2, 2015
work page 2015
-
[19]
Unsupervised domain adaptation for zero-shot learning
Elyor Kodirov, Tao Xiang, Zhenyong Fu, and Shaogang Gong. Unsupervised domain adaptation for zero-shot learning. InProceedings of the IEEE International Conference on Computer Vision, pages 2452–2460, 2015
work page 2015
-
[20]
Hildegard Kuehne, Hueihan Jhuang, Estíbaliz Garrote, Tomaso A. Poggio, and Thomas Serre. HMDB: A large video database for human motion recognition. InIEEE Interna- tional Conference on Computer Vision, ICCV 2011, Barcelona, Spain, November 6-13, 2011, pages 2556–2563, 2011
work page 2011
-
[21]
Zero-data learning of new tasks
Hugo Larochelle, Dumitru Erhan, and Yoshua Bengio. Zero-data learning of new tasks. In Proceedings of the 23rd National Conference on Artificial Intelligence - Volume 2 , AAAI’08, pages 646–651. AAAI Press, 2008. ISBN 978-1-57735-368-3
work page 2008
-
[22]
Jingen Liu, B. Kuipers, and S. Savarese. Recognizing human actions by attributes. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recogni- tion, CVPR ’11, pages 3337–3344. IEEE Computer Society, 2011. ISBN 978-1-4577- 0394-2
work page 2011
-
[23]
Distributed representations of words and phrases and their compositionality
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. InAdvances in neural information processing systems, pages 3111–3119, 2013
work page 2013
-
[24]
A generative approach to zero-shot and few-shot action recog- nition
Ashish Mishra, Vinay Kumar Verma, M Shiva Krishna Reddy, S Arulkumar, Piyush Rai, and Anurag Mittal. A generative approach to zero-shot and few-shot action recog- nition. In 2018 IEEE Winter Conference on Applications of Computer Vision , pages 372–380. IEEE, 2018. BISHA Y , ZOUMPOURLIS, PA TRAS: TEMPORAL A TTENTIVE RELA TION NETWORK 13
work page 2018
-
[25]
Tsendsuren Munkhdalai and Hong Yu. Meta networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 2554–2563, 2017
work page 2017
-
[26]
Discriminative convolutional Fisher vector network for action recognition
Petar Palasek and Ioannis Patras. Discriminative convolutional fisher vector network for action recognition. arXiv preprint arXiv:1707.06119, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Zero-shot learning with semantic output codes
Mark Palatucci, Dean Pomerleau, Geoffrey E Hinton, and Tom M Mitchell. Zero-shot learning with semantic output codes. In Advances in Neural Information Processing Systems 22, pages 1410–1418. Curran Associates, Inc., 2009
work page 2009
-
[28]
A decomposable attention model for natural language inference
Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. A decomposable attention model for natural language inference. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2249–2255, November 2016
work page 2016
-
[29]
Zero-shot action recognition with error-correcting output codes
Jie Qin, Li Liu, Ling Shao, Fumin Shen, Bingbing Ni, Jiaxin Chen, and Yunhong Wang. Zero-shot action recognition with error-correcting output codes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 2833– 2842, 2017
work page 2017
-
[30]
Optimization as a model for few-shot learning
Sachin Ravi and Hugo Larochelle. Optimization as a model for few-shot learning. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings, 2017
work page 2017
-
[31]
Reasoning about entailment with neural attention
Tim Rocktäschel, Edward Grefenstette, Karl Moritz Hermann, Tomas Kocisky, and Phil Blunsom. Reasoning about entailment with neural attention. In International Conference on Learning Representations (ICLR), 2016
work page 2016
-
[32]
An embarrassingly simple approach to zero-shot learning
Bernardino Romera-Paredes and Philip Torr. An embarrassingly simple approach to zero-shot learning. In International Conference on Machine Learning , pages 2152– 2161, 2015
work page 2015
-
[33]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. Interna- tional Journal of Computer Vision (IJCV), 115(3):211–252, 2015
work page 2015
-
[34]
Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy P. Lillicrap. Meta-learning with memory-augmented neural networks. In Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, pages 1842–1850, 2016
work page 2016
-
[35]
Two-stream convolutional networks for ac- tion recognition in videos
Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for ac- tion recognition in videos. In Advances in Neural Information Processing Systems , pages 568–576, 2014
work page 2014
-
[36]
Prototypical networks for few-shot learning
Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. In Advances in Neural Information Processing Systems, 2017
work page 2017
-
[37]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012. 14 BISHA Y , ZOUMPOURLIS, PA TRAS: TEMPORAL A TTENTIVE RELA TION NETWORK
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[38]
Learning to compare: Relation network for few-shot learning
Flood Sung, Yongxin Yang, Li Zhang, Tao Xiang, Philip HS Torr, and Timothy M Hospedales. Learning to compare: Relation network for few-shot learning. In Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1199–1208, 2018
work page 2018
-
[39]
Learning spatiotemporal features with 3d convolutional networks
Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 4489–4497, 2015
work page 2015
-
[40]
Matching networks for one shot learning
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Koray Kavukcuoglu, and Daan Wierstra. Matching networks for one shot learning. In Proceedings of the 30th In- ternational Conference on Neural Information Processing Systems , NIPS’16, pages 3637–3645, 2016
work page 2016
-
[41]
Action recognition with improved trajectories
Heng Wang and Cordelia Schmid. Action recognition with improved trajectories. In Proceedings of the IEEE international conference on computer vision , pages 3551– 3558, 2013
work page 2013
-
[42]
Zero-shot visual recognition via bidirectional latent embed- ding
Qian Wang and Ke Chen. Zero-shot visual recognition via bidirectional latent embed- ding. Int. J. Comput. Vision, 124(3):356–383, September 2017. ISSN 0920-5691
work page 2017
-
[43]
Machine comprehension using match-lstm and answer pointer
Shuohang Wang and Jing Jiang. Machine comprehension using match-lstm and answer pointer. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings, 2017
work page 2017
-
[44]
A compare-aggregate model for matching text se- quences
Shuohang Wang and Jing Jiang. A compare-aggregate model for matching text se- quences. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings, 2017
work page 2017
-
[45]
Dense dilated network for few shot action recognition
Baohan Xu, Hao Ye, Yingbin Zheng, Heng Wang, Tianyu Luwang, and Yu-Gang Jiang. Dense dilated network for few shot action recognition. InProceedings of the 2018 ACM on International Conference on Multimedia Retrieval, pages 379–387. ACM, 2018
work page 2018
-
[46]
Semantic embedding space for zero-shot action recognition
Xun Xu, Timothy Hospedales, and Shaogang Gong. Semantic embedding space for zero-shot action recognition. In 2015 IEEE International Conference on Image Pro- cessing (ICIP), pages 63–67. IEEE, 2015
work page 2015
-
[47]
Multi-task zero-shot action recognition with prioritised data augmentation
Xun Xu, Timothy M Hospedales, and Shaogang Gong. Multi-task zero-shot action recognition with prioritised data augmentation. In European Conference on Computer Vision, pages 343–359. Springer, 2016
work page 2016
-
[48]
Learning a deep embedding model for zero-shot learning
Li Zhang, Tao Xiang, and Shaogang Gong. Learning a deep embedding model for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2021–2030, 2017
work page 2021
-
[49]
Compound memory networks for few-shot video classifica- tion
Linchao Zhu and Yi Yang. Compound memory networks for few-shot video classifica- tion. In Proceedings of the European Conference on Computer Vision, pages 751–766, 2018
work page 2018
-
[50]
Towards universal representation for unseen action recognition
Yi Zhu, Yang Long, Yu Guan, Shawn Newsam, and Ling Shao. Towards universal representation for unseen action recognition. In 2018 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, jun 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.