Beyond Trajectory Imitation: Strategy-Guided Policy Optimization for LLM Reasoning
Pith reviewed 2026-06-26 00:37 UTC · model grok-4.3
The pith
SGPO replaces trajectory imitation with reusable strategy distillation via token-level forward-KL to improve LLM reasoning generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
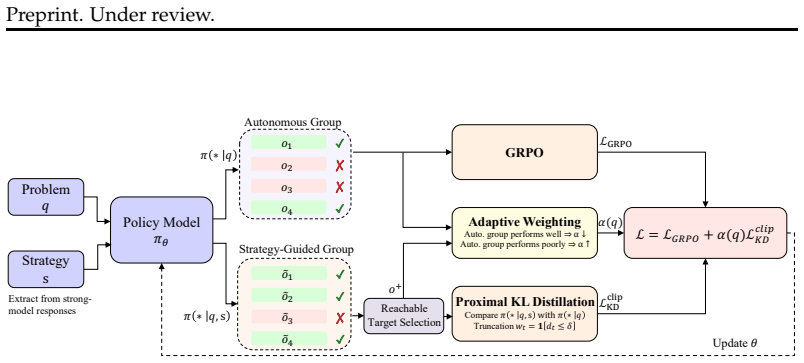
Strategy-Guided Policy Optimization (SGPO) extracts structured strategy descriptions from strong-model responses and constructs both autonomous and strategy-guided trajectories for each problem. It applies a token-level forward-KL objective with proximal constraints to selectively transfer the distributional shift from strategy conditioning into the unguided policy, combined with adaptive instance-level weighting that adjusts guidance based on the model's autonomous performance. On four mathematical benchmarks across two model families, SGPO improves average scores by 2.2 points over the strongest baseline on Qwen2.5-7B-Instruct, with the forward-KL objective proving more effective than dire
What carries the argument
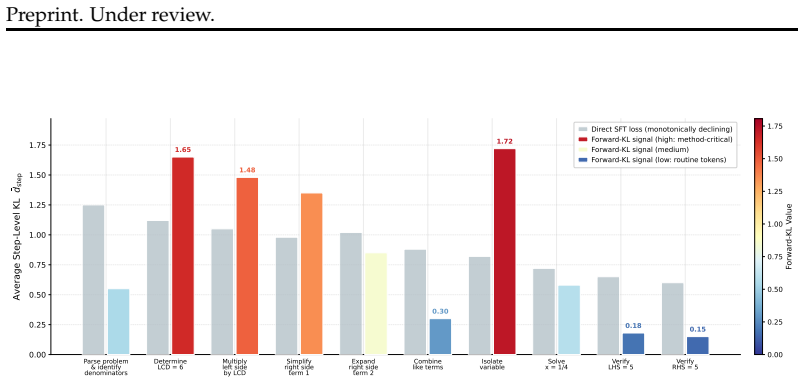
Token-level forward-KL objective that selectively distills the distributional shift induced by strategy conditioning into the unguided policy, with proximal constraints and adaptive instance weighting.
If this is right
- SGPO outperforms SFT, on-policy RL, and hybrid-policy baselines by 2.2 points on average across math benchmarks.
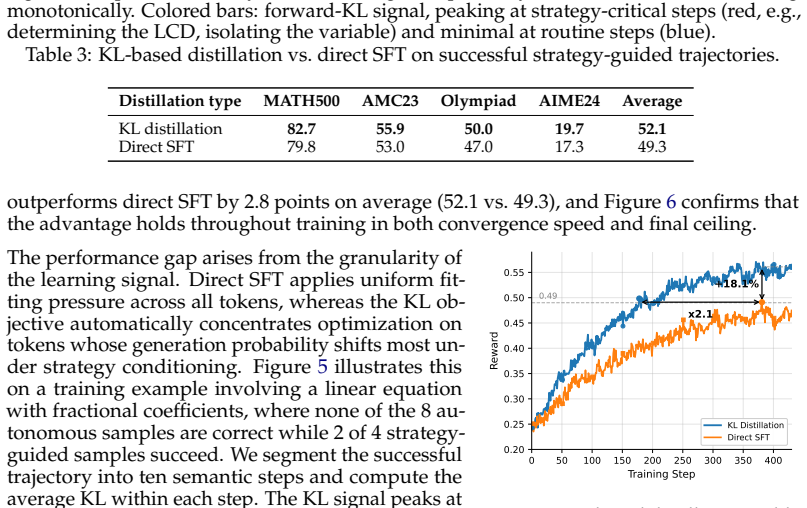
- The forward-KL objective supplies a more selective distillation signal than direct trajectory imitation.
- Strategy distillation produces complementary performance gains as base model capability increases.
- The framework applies successfully across two model families on four separate mathematical benchmarks.
Where Pith is reading between the lines
- If the extracted strategies prove reusable in non-mathematical domains, the same distillation approach could transfer to coding or scientific reasoning tasks.
- The selective property of forward-KL may reduce overfitting to specific training instances compared with full-trajectory imitation.
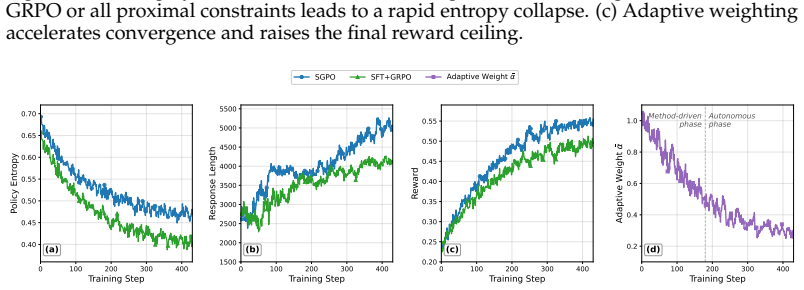
- Adaptive weighting offers a route to training regimes in which external guidance is automatically phased out as the model improves.
- The method implies that conditioning signals during optimization can transfer problem-solving skills more efficiently than final-answer supervision alone.
Load-bearing premise
Structured strategy descriptions extracted from strong-model responses remain sufficiently reusable and effective when transferred to new problems for weaker models.
What would settle it
Performance gains disappear on a held-out test set of problems whose underlying strategies differ markedly from those extracted in the training distribution.
Figures

read the original abstract
Distilling reasoning capabilities from strong to weak language models typically involves imitating specific solution trajectories, effectively transferring what to answer rather than how to reason. This trajectory-level imitation encourages memorization of instance-specific steps rather than acquisition of transferable problem-solving skills, limiting generalization to novel problems. We propose Strategy-Guided Policy Optimization (SGPO), which replaces instance-level trajectory imitation with reusable strategy distillation. SGPO extracts structured strategy descriptions from strong-model responses and, for each problem, constructs both autonomous and strategy-guided trajectories to enable direct comparison of the model's behavior with and without strategic guidance. The framework then addresses two key questions. For how to distill, a token-level forward-KL objective selectively transfers the distributional shift induced by strategy conditioning into the unguided policy, with proximal constraints ensuring stability. For when to distill, adaptive instance-level weighting strengthens guidance when autonomous exploration falls short and reduces it as the model's own competence grows. Experiments on four mathematical benchmarks across two model families show that SGPO consistently outperforms SFT, on-policy RL, and hybrid-policy baselines, improving the average score by 2.2 points over the strongest baseline on Qwen2.5-7B-Instruct. Analysis reveals that the forward-KL objective provides an inherently selective distillation signal that outperforms direct trajectory imitation, and that strategy distillation exhibits complementary scaling with base model capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Strategy-Guided Policy Optimization (SGPO) to distill reasoning from strong to weak LLMs by extracting reusable structured strategy descriptions rather than imitating instance-specific trajectories. For each problem it constructs autonomous and strategy-guided trajectories, then applies a token-level forward-KL objective with proximal constraints to selectively transfer beneficial distributional shifts into the unguided policy, together with adaptive instance-level weighting that strengthens guidance when autonomous performance is weak. Experiments across four mathematical reasoning benchmarks and two model families report that SGPO outperforms SFT, on-policy RL, and hybrid-policy baselines, with a 2.2-point average gain over the strongest baseline on Qwen2.5-7B-Instruct; analysis attributes the gains to the selective nature of the forward-KL signal and complementary scaling with base-model capability.
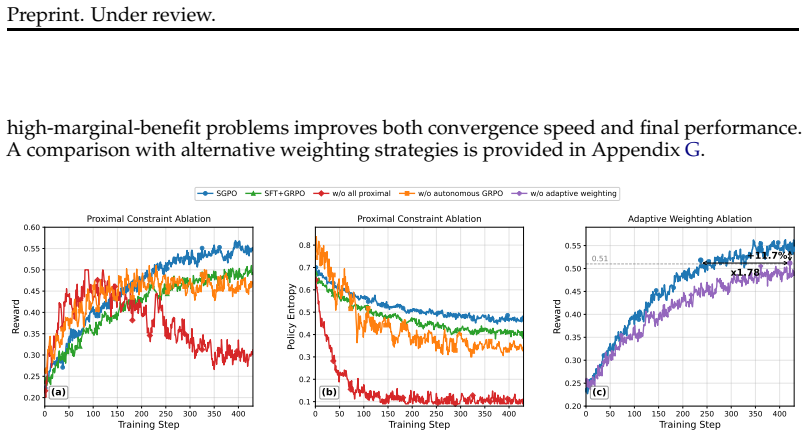
Significance. If the central performance claim and its attribution to reusable strategy distillation hold after proper verification, the work would be significant for LLM reasoning research. It directly targets the memorization-vs-generalization limitation of trajectory imitation and introduces a concrete mechanism (token-level forward-KL plus proximal constraints) for selective transfer. The reported complementary scaling with model size is a useful empirical observation. The absence of quantitative checks on strategy reuse and divergence control, however, prevents the result from being treated as a settled advance at present.
major comments (3)
- [Abstract / experimental results] Abstract and experimental results section: the reported 2.2-point average improvement and consistent outperformance over SFT, on-policy RL, and hybrid baselines are stated without error bars, number of runs, data-split details, or statistical significance tests. This information is required to assess whether the delta can be confidently attributed to the forward-KL strategy distillation rather than variance or implementation differences.
- [Method (strategy extraction)] Method description (strategy extraction and reuse): the central claim that structured strategy descriptions are reusable across problems rests on the assumption that they generalize beyond source instances, yet no quantitative evidence (e.g., cross-problem transfer rates, strategy similarity metrics, or ablation removing strategy conditioning) is supplied to verify this reusability.
- [Method (forward-KL objective)] Forward-KL objective and proximal constraints: the paper asserts that the token-level forward-KL with proximal constraints transfers only beneficial shifts without instability or unintended bias, but reports no divergence metrics, policy-collapse diagnostics, or ablation isolating the proximal term. Without these checks the selective-distillation explanation for the observed gains remains unverified.
minor comments (2)
- [Method] The abstract and method sections would benefit from an explicit equation defining the token-level forward-KL objective and the form of the proximal constraint.
- [Experiments] Figure or table captions should clarify whether reported scores are means over multiple seeds or single-run results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and commit to revisions that will strengthen the verification of our claims without misrepresenting the current manuscript.
read point-by-point responses
-
Referee: [Abstract / experimental results] Abstract and experimental results section: the reported 2.2-point average improvement and consistent outperformance over SFT, on-policy RL, and hybrid baselines are stated without error bars, number of runs, data-split details, or statistical significance tests. This information is required to assess whether the delta can be confidently attributed to the forward-KL strategy distillation rather than variance or implementation differences.
Authors: We agree that error bars, run counts, split details, and significance tests are necessary for robust interpretation. In the revised manuscript we will report results aggregated over multiple independent runs with standard deviations, specify the exact data splits and evaluation protocol, and include statistical significance tests for the reported improvements. revision: yes
-
Referee: [Method (strategy extraction)] Method description (strategy extraction and reuse): the central claim that structured strategy descriptions are reusable across problems rests on the assumption that they generalize beyond source instances, yet no quantitative evidence (e.g., cross-problem transfer rates, strategy similarity metrics, or ablation removing strategy conditioning) is supplied to verify this reusability.
Authors: The performance gains and complementary scaling with base-model size provide supporting evidence that the strategies are not merely instance-specific. To supply the requested quantitative verification, we will add an ablation that removes strategy conditioning and report strategy similarity metrics together with cross-problem transfer statistics in the revision. revision: yes
-
Referee: [Method (forward-KL objective)] Forward-KL objective and proximal constraints: the paper asserts that the token-level forward-KL with proximal constraints transfers only beneficial shifts without instability or unintended bias, but reports no divergence metrics, policy-collapse diagnostics, or ablation isolating the proximal term. Without these checks the selective-distillation explanation for the observed gains remains unverified.
Authors: We concur that explicit diagnostics would strengthen the selective-distillation argument. The revision will include token- and policy-level divergence measurements, policy-collapse diagnostics, and an ablation isolating the proximal constraints to confirm their contribution to stability and selectivity. revision: yes
Circularity Check
No circularity; derivation uses external inputs and independent comparisons
full rationale
The paper's method extracts structured strategies from external strong-model responses, constructs autonomous and guided trajectories for comparison, and applies a token-level forward-KL objective with proximal constraints and adaptive weighting. No equations, fitted parameters, or predictions reduce by construction to the inputs (e.g., no self-definitional ratios or renamed fitted quantities). No load-bearing self-citations, uniqueness theorems from the same authors, or ansatzes smuggled via prior work are invoked in the abstract or description. The reported gains rest on experimental benchmarks against SFT, on-policy RL, and hybrid baselines rather than tautological redefinitions. This is the common case of a self-contained empirical proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Step 3.5 flash: Open frontier-level intelligence with 11b active parameters, 2026
Aobo Kong et.al Ailin Huang, Ang Li. Step 3.5 flash: Open frontier-level intelligence with 11b active parameters, 2026. URL https://arxiv.org/abs/2602.10604
arXiv 2026
-
[2]
Sft or rl? an early investigation into training r1-like reasoning large vision-language models, 2025
Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, and Cihang Xie. Sft or rl? an early investigation into training r1-like reasoning large vision-language models, 2025. URL https://arxiv.org/abs/2504.11468
Pith/arXiv arXiv 2025
-
[3]
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V. Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training, 2025. URL https://arxiv.org/abs/2501.17161
Pith/arXiv arXiv 2025
-
[6]
Srft: A single-stage method with supervised and reinforcement fine-tuning for reasoning, 2025
Yuqian Fu, Tinghong Chen, Jiajun Chai, Xihuai Wang, Songjun Tu, Guojun Yin, Wei Lin, Qichao Zhang, Yuanheng Zhu, and Dongbin Zhao. Srft: A single-stage method with supervised and reinforcement fine-tuning for reasoning, 2025. URL https://arxiv.org/abs/2506.19767
arXiv 2025
-
[7]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems, 2024. URL https://arxiv.org/abs/2402.14008
Pith/arXiv arXiv 2024
-
[8]
Measuring mathematical problem solving with the math dataset, 2021
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset, 2021. URL https://arxiv.org/abs/2103.03874
Pith/arXiv arXiv 2021
-
[9]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention, 2023. URL https://arxiv.org/abs/2309.06180
Pith/arXiv arXiv 2023
-
[10]
Math-verify: Math verification library, 2025
Hynek Kydlíček. Math-verify: Math verification library, 2025. URL https://github.com/huggingface/math-verify
2025
-
[11]
Uft: Unifying supervised and reinforcement fine-tuning, 2025
Mingyang Liu, Gabriele Farina, and Asuman Ozdaglar. Uft: Unifying supervised and reinforcement fine-tuning, 2025. URL https://arxiv.org/abs/2505.16984
arXiv 2025
-
[12]
Towards a unified view of large language model post-training, 2026
Xingtai Lv, Yuxin Zuo, Youbang Sun, Hongyi Liu, Yuntian Wei, Zhekai Chen, Xuekai Zhu, Kaiyan Zhang, Bingning Wang, Ning Ding, and Bowen Zhou. Towards a unified view of large language model post-training, 2026. URL https://arxiv.org/abs/2509.04419
arXiv 2026
-
[13]
Lu Ma, Hao Liang, Meiyi Qiang, Lexiang Tang, Xiaochen Ma, Zhen Hao Wong, Junbo Niu, Chengyu Shen, Runming He, Yanhao Li, Bin Cui, and Wentao Zhang. Learning what reinforcement learning can't: Interleaved online fine-tuning for hardest questions, 2026. URL https://arxiv.org/abs/2506.07527
arXiv 2026
-
[14]
Overcoming exploration in reinforcement learning with demonstrations, 2018
Ashvin Nair, Bob McGrew, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. Overcoming exploration in reinforcement learning with demonstrations, 2018. URL https://arxiv.org/abs/1709.10089
Pith/arXiv arXiv 2018
-
[15]
OpenAI, :, Aaron Jaech, and Adam Kalai et.al. Openai o1 system card, 2024. URL https://arxiv.org/abs/2412.16720
Pith/arXiv arXiv 2024
-
[16]
Supervised fine tuning on curated data is reinforcement learning (and can be improved), 2025
Chongli Qin and Jost Tobias Springenberg. Supervised fine tuning on curated data is reinforcement learning (and can be improved), 2025. URL https://arxiv.org/abs/2507.12856
arXiv 2025
-
[17]
Learning complex dexterous manipulation with deep reinforcement learning and demonstrations, 2018
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations, 2018. URL https://arxiv.org/abs/1709.10087
Pith/arXiv arXiv 2018
-
[18]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/2402.03300
Pith/arXiv arXiv 2024
-
[20]
On the generalization of sft: A reinforcement learning perspective with reward rectification, 2026
Yongliang Wu, Yizhou Zhou, Zhou Ziheng, Yingzhe Peng, Xinyu Ye, Xinting Hu, Wenbo Zhu, Lu Qi, Ming-Hsuan Yang, and Xu Yang. On the generalization of sft: A reinforcement learning perspective with reward rectification, 2026. URL https://arxiv.org/abs/2508.05629
arXiv 2026
-
[21]
Learning to reason under off-policy guidance, 2025
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance, 2025. URL https://arxiv.org/abs/2504.14945
Pith/arXiv arXiv 2025
-
[22]
Qwen2.5 technical report, 2025
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
Pith/arXiv arXiv 2025
-
[23]
Limo: Less is more for reasoning, 2025
Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu. Limo: Less is more for reasoning, 2025. URL https://arxiv.org/abs/2502.03387
Pith/arXiv arXiv 2025
-
[24]
Dapo: An open-source llm reinforcement learning system at scale, 2025
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
Pith/arXiv arXiv 2025
-
[25]
More than one teacher: Adaptive multi-guidance policy optimization for diverse exploration, 2025
Xiaoyang Yuan, Yujuan Ding, Yi Bin, Wenqi Shao, Jinyu Cai, Jingkuan Song, Yang Yang, and Heng Tao Shen. More than one teacher: Adaptive multi-guidance policy optimization for diverse exploration, 2025. URL https://arxiv.org/abs/2510.02227
arXiv 2025
-
[27]
Proximal supervised fine-tuning, 2025
Wenhong Zhu, Ruobing Xie, Rui Wang, Xingwu Sun, Di Wang, and Pengfei Liu. Proximal supervised fine-tuning, 2025. URL https://arxiv.org/abs/2508.17784
Pith/arXiv arXiv 2025
-
[28]
2024 , eprint=
OpenAI o1 System Card , author=. 2024 , eprint=
2024
-
[29]
URLhttps://doi.org/10.1038/s41586-025-09422-z
Guo Daya and Yang Dejian and Zhang Haowei et.al , year=. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , volume=. Nature , publisher=. doi:10.1038/s41586-025-09422-z , number=
-
[30]
2025 , eprint=
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training , author=. 2025 , eprint=
2025
-
[31]
2026 , eprint=
On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification , author=. 2026 , eprint=
2026
-
[32]
2025 , eprint=
LIMO: Less is More for Reasoning , author=. 2025 , eprint=
2025
-
[33]
2025 , eprint=
Proximal Supervised Fine-Tuning , author=. 2025 , eprint=
2025
-
[34]
2026 , eprint=
Towards a Unified View of Large Language Model Post-Training , author=. 2026 , eprint=
2026
-
[35]
2025 , eprint=
Learning to Reason under Off-Policy Guidance , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
SRFT: A Single-Stage Method with Supervised and Reinforcement Fine-Tuning for Reasoning , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling , author=. 2025 , eprint=
2025
-
[38]
2025 , eprint=
StepHint: Multi-level Stepwise Hints Enhance Reinforcement Learning to Reason , author=. 2025 , eprint=
2025
-
[39]
BREAD: Branched Rollouts from Expert Anchors Bridge
Xuechen Zhang and Zijian Huang and Yingcong Li and Chenshun Ni and Jiasi Chen and Samet Oymak , year=. BREAD: Branched Rollouts from Expert Anchors Bridge. 2506.17211 , archivePrefix=
-
[40]
2026 , eprint=
Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions , author=. 2026 , eprint=
2026
-
[41]
2024 , eprint=
Deep Reinforcement Learning for Robotics: A Survey of Real-World Successes , author=. 2024 , eprint=
2024
-
[42]
nature , volume=
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
2015
-
[43]
2025 , eprint=
More Than One Teacher: Adaptive Multi-Guidance Policy Optimization for Diverse Exploration , author=. 2025 , eprint=
2025
-
[44]
2025 , eprint=
SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models , author=. 2025 , eprint=
2025
-
[45]
2025 , eprint=
Supervised Fine Tuning on Curated Data is Reinforcement Learning (and can be improved) , author=. 2025 , eprint=
2025
-
[46]
2025 , eprint=
UFT: Unifying Supervised and Reinforcement Fine-Tuning , author=. 2025 , eprint=
2025
-
[47]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[48]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[49]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[50]
2021 , eprint=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. 2021 , eprint=
2021
-
[51]
2018 , eprint=
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations , author=. 2018 , eprint=
2018
-
[52]
2018 , eprint=
Overcoming Exploration in Reinforcement Learning with Demonstrations , author=. 2018 , eprint=
2018
-
[53]
Hybridflow: A flexible and efficient rlhf framework
Sheng, Guangming and Zhang, Chi and Ye, Zilingfeng and Wu, Xibin and Zhang, Wang and Zhang, Ru and Peng, Yanghua and Lin, Haibin and Wu, Chuan , year=. HybridFlow: A Flexible and Efficient RLHF Framework , url=. doi:10.1145/3689031.3696075 , booktitle=
-
[54]
2023 , eprint=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. 2023 , eprint=
2023
-
[55]
2025 , title =
Kydlíček, Hynek , license =. 2025 , title =
2025
-
[56]
2024 , eprint=
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems , author=. 2024 , eprint=
2024
-
[57]
2025 , eprint=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
2025
-
[58]
2026 , eprint=
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.