Skill is Not One-Size-Fits-All: Model-Aware Skill Alignment for LLM Agents
Pith reviewed 2026-06-28 22:54 UTC · model grok-4.3
The pith
LLM agent skills must be rewritten for each model backbone rather than reused across them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
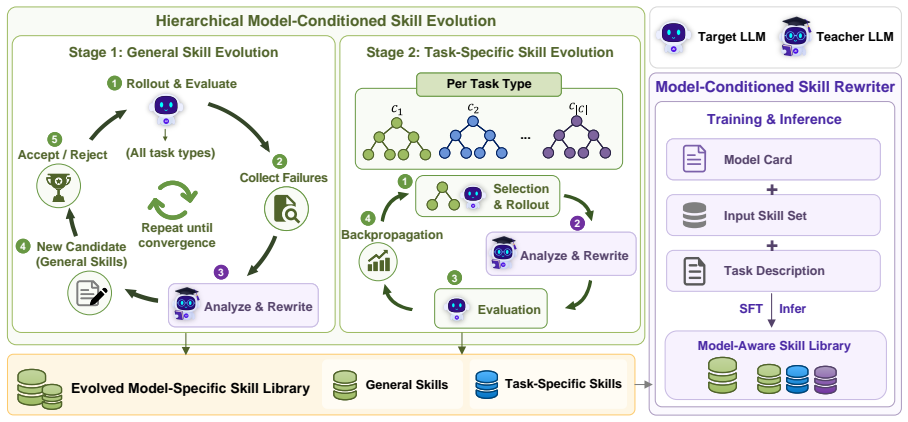
MASA adapts skills to each target backbone through a hierarchical skill evolution pipeline that iteratively rewrites general and task-specific skills using hill climbing and UCB-driven tree search guided by environment feedback and model capability profiles, then trains a lightweight model-conditioned skill rewriter on the resulting trajectories so that adaptation occurs in a single forward pass.
What carries the argument
The hierarchical skill evolution pipeline together with the model-conditioned skill rewriter that adapts instructions to model capability profiles.
If this is right
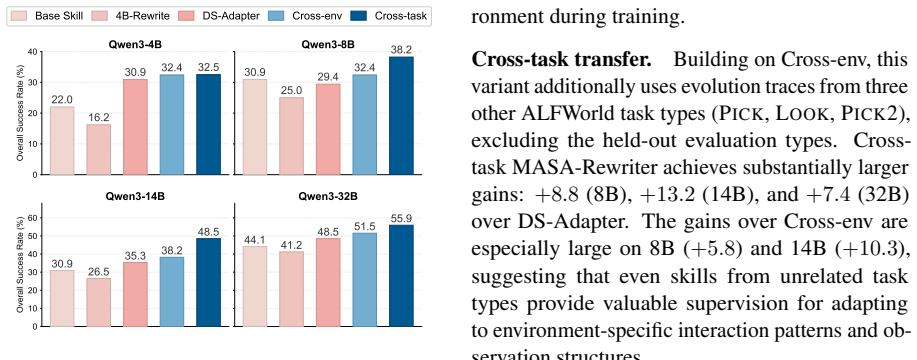
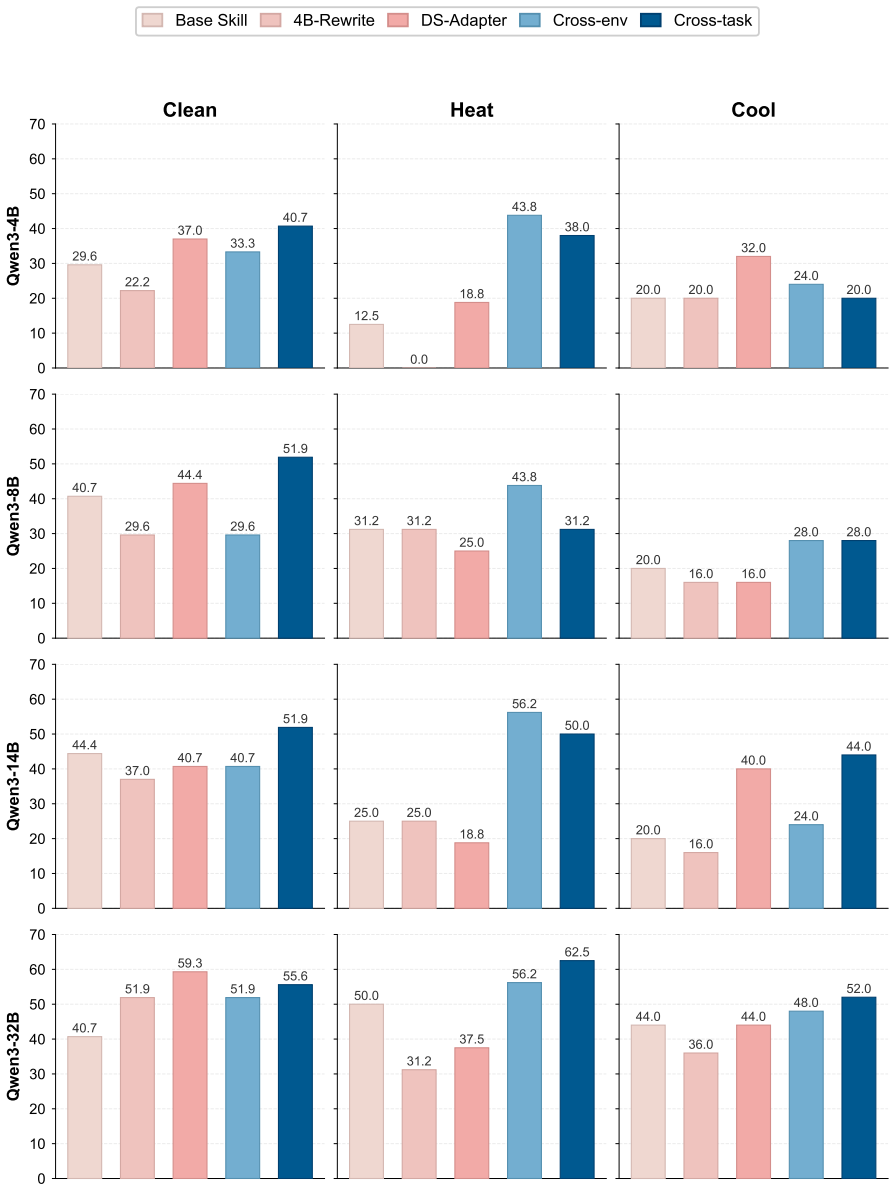
- MASA-adapted skills raise overall performance by up to 25.8 points over the strongest baseline across three environments and four backbones.
- The learned rewriter applies the adaptation to unseen tasks and environments without running further search.
- The rewriter lets a smaller model outperform a much larger teacher LLM while using far less inference cost.
- Model capability profiles can be used to guide skill rewriting without any change to the underlying agent weights.
Where Pith is reading between the lines
- Agent skill libraries may need to be stored and served as model-specific versions rather than as single shared collections.
- Smaller open models could close more of the gap with larger closed models if each receives its own adapted skill set.
- The same evolution-plus-rewriter pattern could be applied to other forms of agent memory such as tool descriptions or prompt templates.
- Measuring how much the capability profiles themselves must be updated when a new model version appears would test long-term maintenance cost.
Load-bearing premise
Environment feedback during the evolution pipeline supplies reliable signals of skill quality that generalize across tasks and do not overfit.
What would settle it
A controlled test on a held-out backbone or environment in which MASA-adapted skills produce no gain or lower success rates than the original shared skills.
Figures
read the original abstract
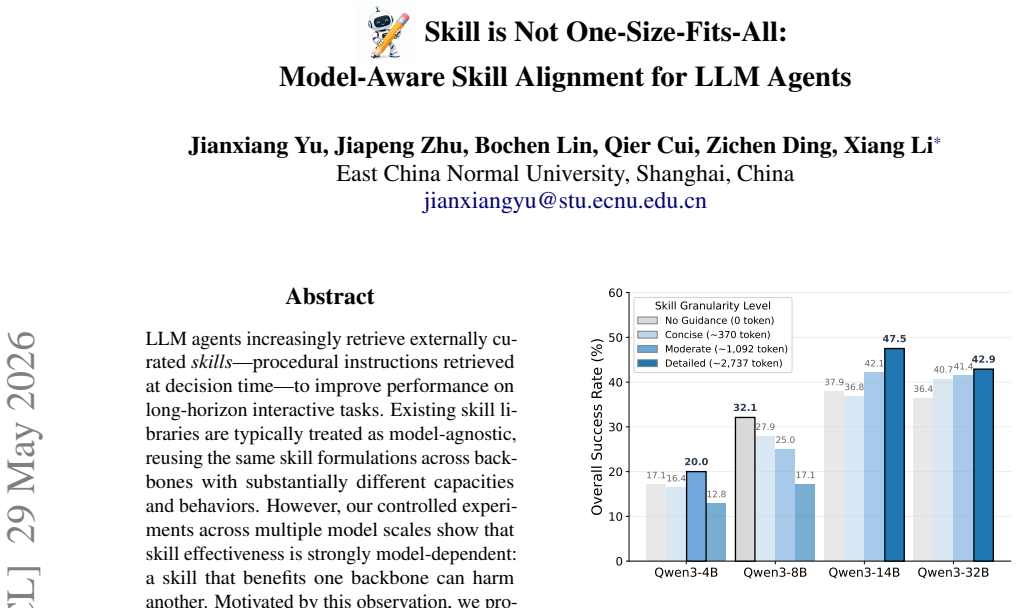
LLM agents increasingly retrieve externally curated skills-procedural instructions retrieved at decision time-to improve performance on long-horizon interactive tasks. Existing skill libraries are typically treated as model-agnostic, reusing the same skill formulations across backbones with substantially different capacities and behaviors. However, our controlled experiments across multiple model scales show that skill effectiveness is strongly model-dependent: a skill that benefits one backbone can harm another. Motivated by this observation, we propose MASA Model-Aware Skill Alignment, a framework that adapts skills to each target backbone without modifying agent weights. MASA operates in two stages: (1) a hierarchical skill evolution pipeline that iteratively rewrites general and task-specific skills using hill climbing and UCB-driven tree search, guided by environment feedback and model capability profiles; and (2) a lightweight model-conditioned skill rewriter trained on evolution trajectories to reproduce the adaptation in a single forward pass. Experiments across three interactive environments and four backbones show that MASA consistently achieves the best overall performance, with gains of up to 25.8 points over the strongest baseline. The learned rewriter further generalizes to unseen tasks and environments without additional search, consistently outperforming a much larger teacher LLM at a fraction of the inference cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that skill effectiveness for LLM agents is strongly model-dependent, as shown by controlled experiments across model scales. It proposes MASA, a two-stage Model-Aware Skill Alignment framework: (1) a hierarchical skill evolution pipeline that rewrites skills via hill climbing and UCB-driven tree search guided by environment feedback and model capability profiles; (2) a lightweight model-conditioned rewriter trained on the resulting trajectories. Experiments on three interactive environments and four backbones report that MASA achieves the best performance (gains up to 25.8 points over the strongest baseline) and that the learned rewriter generalizes to unseen tasks/environments while outperforming a larger teacher LLM at lower inference cost.
Significance. If the empirical results and generalization claims hold under scrutiny, the work is significant for LLM agent research: it provides concrete evidence against model-agnostic skill libraries and demonstrates a practical, weight-free adaptation method that reduces reliance on expensive search at inference time. The combination of environment-guided evolution with a distilled rewriter is a clear strength, offering both performance gains and efficiency.
major comments (2)
- [§4] §4 (Experiments) and the description of the hierarchical skill evolution pipeline: the central performance claims (up to 25.8-point gains and rewriter generalization) rest on the reliability of environment feedback signals and the accuracy of model capability profiles, yet no ablation or sensitivity analysis is reported on how profile construction or feedback noise affects the evolved skills. This is load-bearing for the model-aware claim.
- [Table 2] Table 2 (or equivalent results table) and the baseline comparisons: the reported gains are presented as consistent across four backbones, but the manuscript does not detail whether the same skill library size, search budget, or number of evolution iterations were used for all methods; unequal compute or hyperparameter tuning would undermine the cross-model comparison.
minor comments (2)
- [§3.1] The notation for UCB-driven tree search and hill climbing in the evolution pipeline should be formalized with explicit equations or pseudocode to improve reproducibility.
- [Figure 3] Figure 3 (or the generalization plot) would benefit from error bars or multiple random seeds to support the claim that the rewriter consistently outperforms the teacher LLM.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater experimental transparency. We address both major comments below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and the description of the hierarchical skill evolution pipeline: the central performance claims (up to 25.8-point gains and rewriter generalization) rest on the reliability of environment feedback signals and the accuracy of model capability profiles, yet no ablation or sensitivity analysis is reported on how profile construction or feedback noise affects the evolved skills. This is load-bearing for the model-aware claim.
Authors: We agree that sensitivity analysis on profile construction and feedback noise is important for substantiating the model-aware claim. Our current experiments already employ consistent feedback mechanisms and profile construction across backbones, but we did not report explicit ablations. In the revised manuscript we will add a new subsection in §4 with (i) controlled perturbations to model capability profiles and (ii) simulated feedback noise at varying levels, showing that performance gains remain stable. These results will directly support the load-bearing role of model conditioning. revision: yes
-
Referee: [Table 2] Table 2 (or equivalent results table) and the baseline comparisons: the reported gains are presented as consistent across four backbones, but the manuscript does not detail whether the same skill library size, search budget, or number of evolution iterations were used for all methods; unequal compute or hyperparameter tuning would undermine the cross-model comparison.
Authors: All comparisons in Table 2 were performed under identical experimental controls: the same skill library size (K=50), search budget (UCB iterations and hill-climbing steps), and evolution iteration count were used for every backbone and every baseline. These shared settings are described in the experimental setup paragraph preceding Table 2, but the manuscript does not explicitly restate them in the table caption. We will revise the caption and add a short paragraph confirming the uniform hyperparameter regime, thereby removing any ambiguity about cross-model fairness. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical framework (MASA) consisting of a hierarchical skill evolution pipeline using hill-climbing and UCB search guided by external environment feedback plus model capability profiles, followed by supervised training of a lightweight rewriter on the resulting trajectories. All performance claims (gains up to 25.8 points, generalization to unseen tasks) are supported by controlled experiments across three environments and four backbones rather than by any derivation that reduces to fitted parameters, self-definitions, or self-citations. No equations, uniqueness theorems, or ansatzes are invoked that collapse to the inputs by construction; the rewriter is a standard imitation step whose outputs are evaluated externally. This is a self-contained empirical pipeline with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Os-genesis: Automating gui agent trajectory construction via reverse task synthesis. InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 5555–5579. Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. Musique: Multi- hop questions via single-hop question ...
Pith/arXiv arXiv 2022
-
[2]
Yiheng Xu, Dunjie Lu, Zhennan Shen, Junli Wang, Zekun Wang, Yuchen Mao, Caiming Xiong, and Tao Yu
Skillrl: Evolving agents via recursive skill- augmented reinforcement learning.arXiv preprint arXiv:2602.08234. Yiheng Xu, Dunjie Lu, Zhennan Shen, Junli Wang, Zekun Wang, Yuchen Mao, Caiming Xiong, and Tao Yu. 2025. Agenttrek: Agent trajectory synthesis via guiding replay with web tutorials. InInternational Conference on Learning Representations, volume ...
Pith/arXiv arXiv 2025
-
[3]
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen
-
[4]
InIn- ternational Conference on Learning Representations, volume 2024, pages 12028–12068
Large language models as optimizers. InIn- ternational Conference on Learning Representations, volume 2024, pages 12028–12068. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christo- pher D Manning. 2018. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conf...
Pith/arXiv arXiv 2024
-
[5]
and EvoPrompt (Guo et al., 2024) iteratively refine a single instruction for a given task, yet treat 11 the target model as fixed context—the same out- put applies regardless of backbone. MAPO (Chen et al., 2023) and PromptBridge (Wang et al., 2025b) further account for model identity by optimizing or transferring individual task instructions across backb...
2024
-
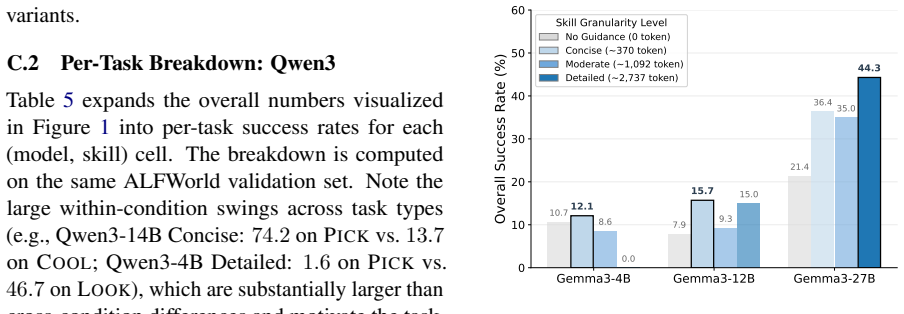
[6]
Architecture metadata.Model family, variant name, parameter count, architecture type, lay- er/attention configuration, context window, and vocabulary size—sourced directly from the pub- lished model card or config files. Gemma3-4B Gemma3-12B Gemma3-27B 0 10 20 30 40 50 60Overall Success Rate (%) 10.7 7.9 21.4 12.1 15.7 36.4 8.6 9.3 35.0 0.0 15.0 44.3 Skil...
-
[7]
Training provenance.Whether the checkpoint is base or instruction-tuned, the alignment pipeline (e.g., SFT + DPO + GRPO), training data scale, and multilingual support—sourced from official documentation
-
[8]
strong at math and code generation
Capability profile.Strengths are extracted from the model’s official release notes (e.g., “strong at math and code generation”). Weaknesses are generated by the teacher LLM summarizing be- havioral patterns observed during a small set of preliminary rollouts (Section 2), produced automatically without human annotation. Note that the card does not include ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.