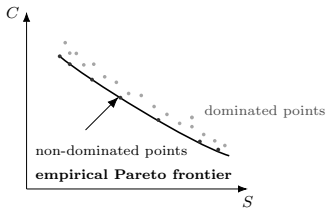
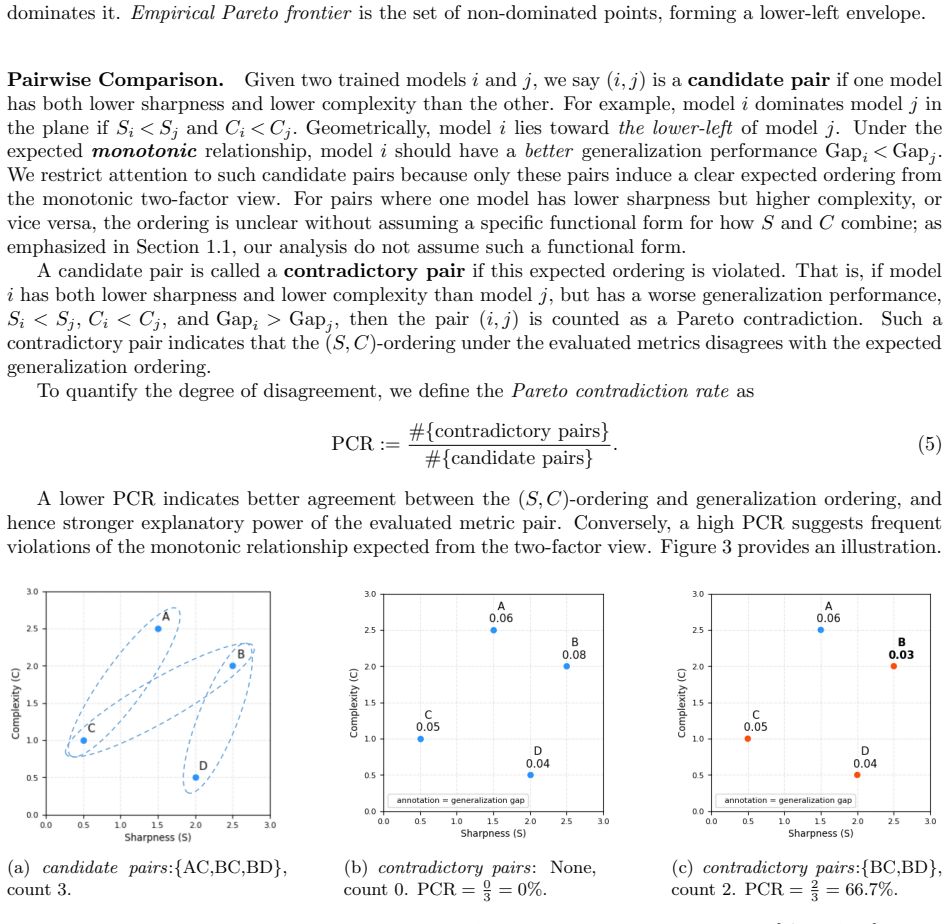
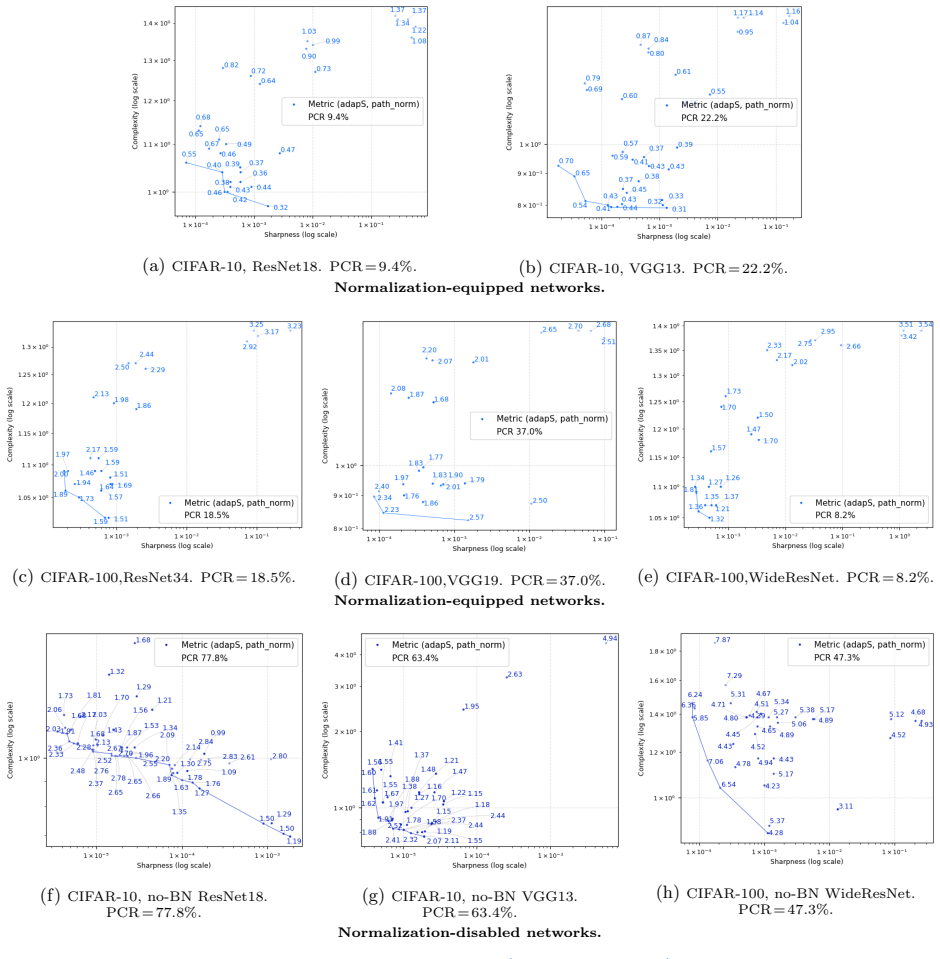
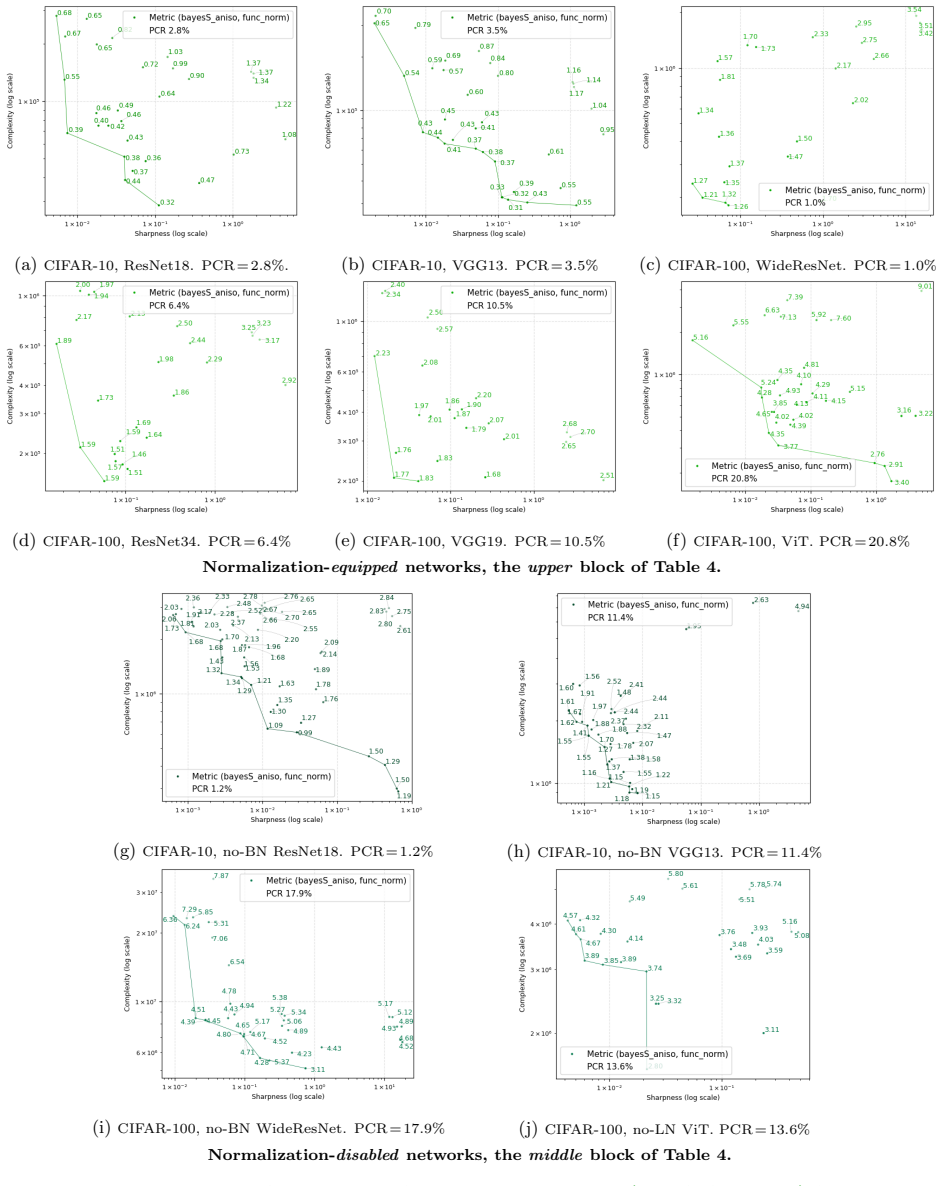
How Far Can Sharpness and Complexity Jointly Explain Generalization?
Pith reviewed 2026-06-30 09:23 UTC · model grok-4.3
The pith
Function-oriented sharpness and complexity jointly explain generalization in neural networks more broadly than parameter-level versions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Function-oriented realizations of sharpness and complexity expand the explanatory scope of the two-factor view beyond what is achieved by existing parameter-level metrics, as shown by linear regression and Pareto-based analysis on multiple datasets. The results support the sharpness-complexity perspective as an informative lens for understanding generalization across diverse settings, while the remaining unexplained cases leave open whether this view can serve as a complete theory.
What carries the argument
Pareto-based analysis applied to linear regression models that combine function-oriented sharpness and complexity measures
If this is right
- Function-oriented definitions increase the share of generalization cases covered by the sharpness-complexity pair relative to parameter-level definitions.
- The two-factor perspective supplies an informative account across diverse network settings and tasks.
- Unexplained cases persist, indicating the view cannot yet serve as a complete account of generalization.
- The joint analysis framework quantifies explanatory power through regression coefficients and Pareto dominance.
Where Pith is reading between the lines
- The same regression-plus-Pareto method could be reapplied after introducing a third factor to test whether unexplained variance shrinks further.
- One could examine whether the function-oriented measures remain predictive when the training procedure or loss function changes.
- The approach offers a template for comparing any pair of candidate generalization factors on equal quantitative footing.
Load-bearing premise
Linear regression combined with Pareto analysis on the chosen datasets and measures provides a reliable quantitative assessment of joint explanatory power.
What would settle it
An experiment on the same datasets where parameter-level sharpness and complexity achieve equal or higher joint explanatory power under the same regression and Pareto procedure would falsify the claimed expansion of scope.
Figures

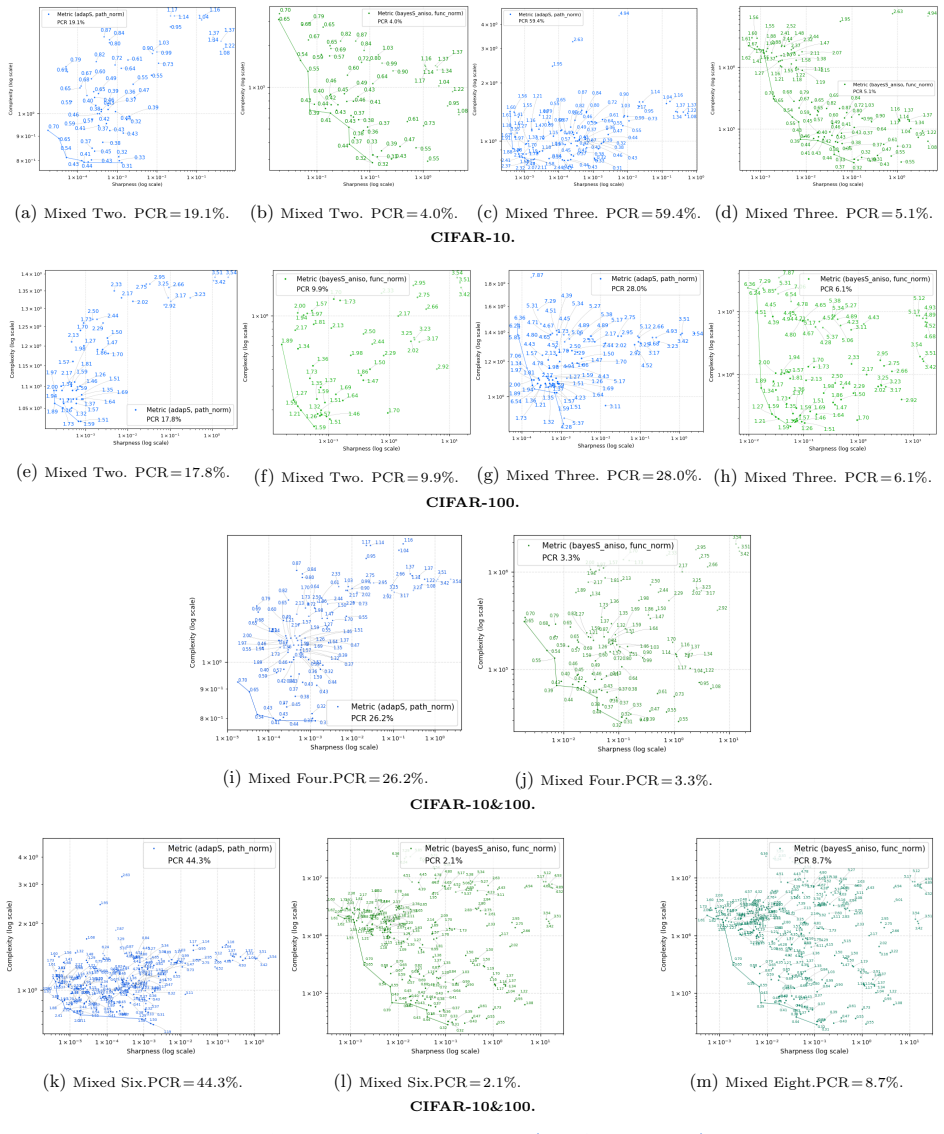
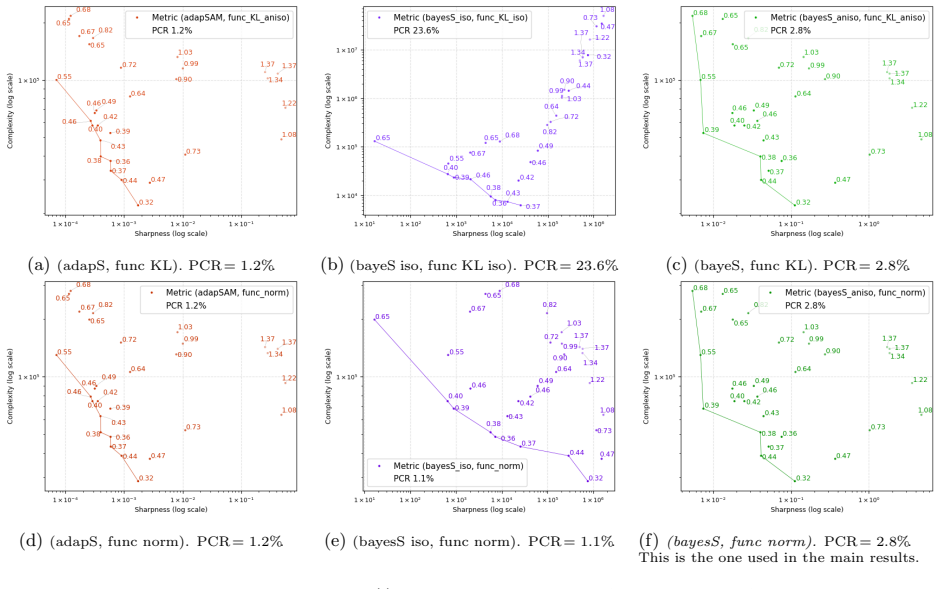
read the original abstract
Sharpness and complexity are two central factors in the generalization analysis of deep neural networks. Existing quantitative evaluations of generalization measures have largely focused on individual scalar measures, leaving the joint explanatory power of sharpness and complexity largely unexplored. This work studies how far sharpness and complexity can jointly explain generalization. We use linear regression and introduce a Pareto-based analysis to quantitatively evaluate the joint explanatory power of these two factors. Beyond the existing parameter-level definitions, we further propose realizations of sharpness and complexity that are closer to function space and less dependent on raw parameter representations. We find that function-oriented definitions of these two quantities expand the explanatory scope of the two-factor view beyond what is achieved by existing parameter-level metrics. Overall, our results support the sharpness-complexity perspective as an informative lens for understanding generalization across diverse settings. At the same time, the remaining failures indicate that whether this two-factor view can serve as a complete theory of generalization remains open.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that sharpness and complexity jointly explain generalization in deep neural networks, with function-oriented definitions (closer to function space and less dependent on raw parameters) expanding the explanatory scope beyond existing parameter-level metrics. It supports this via linear regression to quantify variance explained in generalization error combined with a Pareto-based analysis to assess joint coverage, across diverse settings. The work concludes that the two-factor view is informative but not necessarily complete, given remaining unexplained failures.
Significance. If the empirical results hold under scrutiny, the work offers a quantitative two-factor lens for generalization that could guide measure design and highlight when sharpness and complexity suffice versus when other factors dominate. The introduction of Pareto analysis for joint coverage is a methodological strength worth building on. The explicit acknowledgment of remaining failures is a credit to the paper's balanced framing.
major comments (1)
- [Methodology paragraph (abstract) and corresponding experimental sections] The central claim that function-oriented definitions expand explanatory scope rests on linear regression (to measure variance explained) and Pareto analysis (to assess joint coverage). The abstract's methodology paragraph provides no robustness details on linearity assumptions, multicollinearity between the two factors, or sensitivity to dataset/measure choice. If relationships are nonlinear or unmodeled factors dominate, the reported expansion relative to parameter-level metrics could be overstated. This is load-bearing for the main result.
minor comments (1)
- [Abstract] The abstract packs the methodology and results into dense sentences; splitting the description of the regression and Pareto steps would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive critique of our methodology. The concern regarding robustness is well-taken and we will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Methodology paragraph (abstract) and corresponding experimental sections] The central claim that function-oriented definitions expand explanatory scope rests on linear regression (to measure variance explained) and Pareto analysis (to assess joint coverage). The abstract's methodology paragraph provides no robustness details on linearity assumptions, multicollinearity between the two factors, or sensitivity to dataset/measure choice. If relationships are nonlinear or unmodeled factors dominate, the reported expansion relative to parameter-level metrics could be overstated. This is load-bearing for the main result.
Authors: We agree that explicit robustness details strengthen the central claim. The abstract is space-constrained, but the full experimental sections already span multiple datasets, architectures, and measure variants to probe sensitivity. In revision we will add: (i) variance inflation factor (VIF) diagnostics for all reported regressions to quantify multicollinearity between sharpness and complexity; (ii) side-by-side results from nonlinear models (e.g., random-forest regression and kernel ridge) to test whether the reported R² gains persist; and (iii) a concise sensitivity table summarizing how the function-space advantage varies across the main experimental axes. These additions will appear in the methodology and results sections and will be referenced from the abstract if space permits. If any check materially weakens the expansion claim we will qualify the conclusions. revision: yes
Circularity Check
No circularity: empirical regression and Pareto analysis are external to the proposed measures
full rationale
The paper evaluates joint explanatory power via linear regression (variance explained in generalization error) and Pareto analysis applied to observed sharpness, complexity, and error values across datasets. These statistical procedures operate on independently computed quantities and do not reduce any reported result to a fitted parameter or self-referential definition by construction. Function-oriented realizations are introduced as new proposals and then tested against parameter-level baselines without invoking self-citations, uniqueness theorems, or ansatzes that presuppose the target conclusion. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
User-friendly introduction to pac-bayes bounds.Foundations and Trends in Machine Learning, 17(2):174–303, 2024
Pierre Alquier. User-friendly introduction to pac-bayes bounds.Foundations and Trends in Machine Learning, 17(2):174–303, 2024
2024
-
[2]
Properties of variational approximations of gibbs posteriors.Journal of Machine Learning Research, 17(236):1–41, 2016
Pierre Alquier, James Ridgway, and Nicolas Chopin. Properties of variational approximations of gibbs posteriors.Journal of Machine Learning Research, 17(236):1–41, 2016
2016
-
[3]
Towards understanding sharpness-aware minimiza- tion
Maksym Andriushchenko and Nicolas Flammarion. Towards understanding sharpness-aware minimiza- tion. InInternational Conference on Machine Learning, pages 639–668. PMLR, 2022
2022
-
[4]
Spectrally-normalized margin bounds for neural networks.Advances in neural information processing systems, 30, 2017
Peter L Bartlett, Dylan J Foster, and Matus Telgarsky. Spectrally-normalized margin bounds for neural networks.Advances in neural information processing systems, 30, 2017
2017
-
[5]
Bartlett, Philip M
Peter L. Bartlett, Philip M. Long, G´ abor Lugosi, and Alexander Tsigler. Benign overfitting in linear regression.Proceedings of the National Academy of Sciences, 117(48):30063–30070, 2020
2020
-
[6]
Ortega, Aritz P´ erez, and Andr´ es R
Ioar Casado, Luis A. Ortega, Aritz P´ erez, and Andr´ es R. Masegosa. Pac-bayes-chernoff bounds for unbounded losses.Advances in Neural Information Processing Systems, 37, 2024
2024
-
[7]
Springer, 2004
Olivier Catoni.Statistical Learning Theory and Stochastic Optimization: Ecole d’Ete de Probabilites de Saint-Flour XXXI–2001, volume 1851. Springer, 2004
2001
-
[8]
Pac-Bayesian Supervised Classification: The Thermodynamics of Statistical Learning
Olivier Catoni. Pac-bayesian supervised classification: the thermodynamics of statistical learning.arXiv preprint arXiv:0712.0248, 2007
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[9]
Sharp minima can generalize for deep nets
Laurent Dinh, Razvan Pascanu, Samy Bengio, and Yoshua Bengio. Sharp minima can generalize for deep nets. InInternational Conference on Machine Learning, pages 1019–1028, 2017
2017
-
[10]
Gintare Karolina Dziugaite and Daniel M. Roy. Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data. InProceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence, 2017
2017
-
[11]
Sharpness-aware minimization for efficiently improving generalization
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware minimization for efficiently improving generalization. InInternational Conference on Learning Representations, 2020
2020
-
[12]
A primer on pac-bayesian learning.ArXiv, abs/1901.05353,
Benjamin Guedj. A primer on pac-bayesian learning.arXiv preprint arXiv:1901.05353, 2019. 22
-
[13]
Lee, Daniel Soudry, and Nathan Srebro
Suriya Gunasekar, Jason D. Lee, Daniel Soudry, and Nathan Srebro. Implicit bias of gradient descent on linear convolutional networks. InAdvances in Neural Information Processing Systems, 2018
2018
-
[14]
Pac-bayes unleashed: Generalisation bounds with unbounded losses.Entropy, 23(10):1330, 2021
Maxime Haddouche, Benjamin Guedj, Omar Rivasplata, and John Shawe-Taylor. Pac-bayes unleashed: Generalisation bounds with unbounded losses.Entropy, 23(10):1330, 2021
2021
-
[15]
Flat minima
Sepp Hochreiter and J¨ urgen Schmidhuber. Flat minima. InNeural Computation, volume 9, pages 1–42, 1997
1997
-
[16]
Fantastic gen- eralization measures and where to find them
Yiding Jiang, Behnam Neyshabur, Hossein Mobahi, Dilip Krishnan, and Samy Bengio. Fantastic gen- eralization measures and where to find them. InInternational Conference on Learning Representations, 2019
2019
-
[17]
Cohen, and Zachary C
Simran Kaur, Jeremy M. Cohen, and Zachary C. Lipton. On the maximum hessian eigenvalue and generalization. InProceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, pages 1048–1059. PMLR, 2023
2023
-
[18]
On large-batch training for deep learning: Generalization gap and sharp minima
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: Generalization gap and sharp minima. InInternational Conference on Learning Representations, 2017
2017
-
[19]
A simple weight decay can improve generalization
Anders Krogh and John Hertz. A simple weight decay can improve generalization. InAdvances in Neural Information Processing Systems, volume 4, 1991
1991
-
[20]
Asam: Adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks
Jungmin Kwon, Jeongmin Kim, Hyunseo Park, and In Kwon Choi. Asam: Adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks. InInternational Conference on Ma- chine Learning, pages 5905–5914. PMLR, 2021
2021
-
[21]
Yucong Liu, Shixing Yu, and Tong Lin. Regularizing deep neural networks with stochastic estimators of hessian trace.arXiv preprint arXiv:2208.05924, 2022
-
[22]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[23]
Gradient descent maximizes the margin of homogeneous neural networks
Kaifeng Lyu and Jian Li. Gradient descent maximizes the margin of homogeneous neural networks. In International Conference on Learning Representations, 2020
2020
-
[24]
A note on the PAC bayesian theorem, 2004
Andreas Maurer. A note on the PAC bayesian theorem, 2004
2004
-
[25]
Some pac-bayesian theorems
David A McAllester. Some pac-bayesian theorems. InProceedings of the eleventh annual conference on Computational learning theory, pages 230–234, 1998
1998
-
[26]
Pac-bayesian model averaging
David A McAllester. Pac-bayesian model averaging. InProceedings of the twelfth annual conference on Computational learning theory, pages 164–170, 1999
1999
-
[27]
Simplified pac-bayesian margin bounds
David A McAllester. Simplified pac-bayesian margin bounds. InLearning Theory and Kernel Ma- chines: 16th Annual Conference on Learning Theory and 7th Kernel Workshop, COLT/Kernel 2003, Washington, DC, USA, August 24-27, 2003. Proceedings, pages 203–215. Springer, 2003
2003
-
[28]
Deep double descent: Where bigger models and more data hurt
Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. Deep double descent: Where bigger models and more data hurt. InInternational Conference on Learning Representations, 2020
2020
-
[29]
A pac-bayesian approach to spectrally-normalized margin bounds for neural networks
Behnam Neyshabur, Srinadh Bhojanapalli, David McAllester, and Nathan Srebro. A pac-bayesian approach to spectrally-normalized margin bounds for neural networks. InInternational Conference on Learning Representations, 2018
2018
-
[30]
Exploring generalization in deep learning.Advances in neural information processing systems, 30, 2017
Behnam Neyshabur, Srinadh Bhojanapalli, David McAllester, and Nati Srebro. Exploring generalization in deep learning.Advances in neural information processing systems, 30, 2017. 23
2017
-
[31]
In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning
Behnam Neyshabur, Ryota Tomioka, and Nathan Srebro. In search of the real inductive bias: On the role of implicit regularization in deep learning.arXiv preprint arXiv:1412.6614, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Norm-based capacity control in neural net- works
Behnam Neyshabur, Ryota Tomioka, and Nathan Srebro. Norm-based capacity control in neural net- works. InConference on Learning Theory, pages 1376–1401. PMLR, 2015
2015
-
[33]
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 5389–5400, 2019
2019
-
[34]
More pac-bayes bounds: From bounded losses, to losses with general tail behaviors, to anytime validity.Journal of Machine Learning Research, 25(192):1–78, 2024
Borja Rodr´ ıguez-G´ alvez, Ragnar Thobaben, and Mikael Skoglund. More pac-bayes bounds: From bounded losses, to losses with general tail behaviors, to anytime validity.Journal of Machine Learning Research, 25(192):1–78, 2024
2024
-
[35]
Pac-bayesian generalisation error bounds for gaussian process classification
Matthias Seeger. Pac-bayesian generalisation error bounds for gaussian process classification. InJournal of Machine Learning Research, pages 233–269, 2002
2002
-
[36]
Smith, Benoit Dherin, David G
Samuel L. Smith, Benoit Dherin, David G. T. Barrett, and Soham De. On the origin of implicit regularization in stochastic gradient descent. InInternational Conference on Learning Representations, 2021
2021
-
[37]
The implicit bias of gradient descent on separable data.Journal of Machine Learning Research, 19(70):1–57, 2018
Daniel Soudry, Elad Hoffer, Mor Shpigel Nacson, Suriya Gunasekar, and Nathan Srebro. The implicit bias of gradient descent on separable data.Journal of Machine Learning Research, 19(70):1–57, 2018
2018
-
[38]
Understanding deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization. InInternational Conference on Learning Representations, 2017
2017
-
[39]
Three mechanisms of weight decay regularization
Guodong Zhang, Chaoqi Wang, Bowen Xu, and Roger Grosse. Three mechanisms of weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[40]
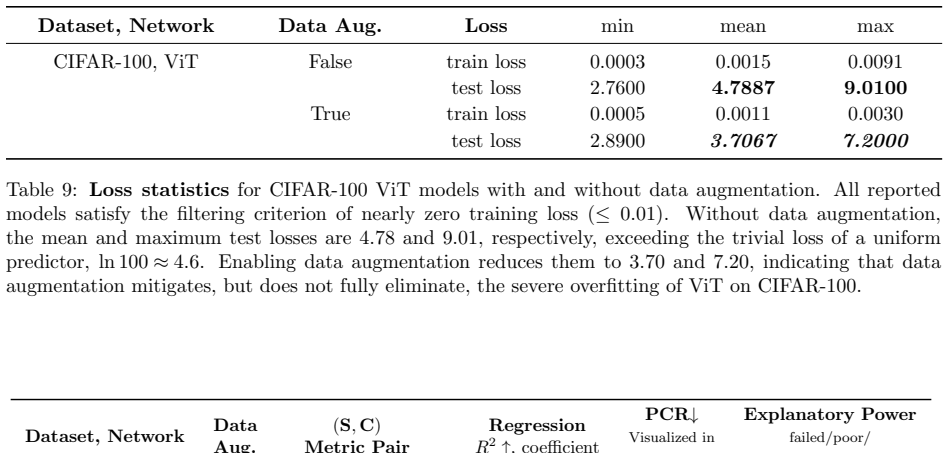
Xitong Zhang, Avrajit Ghosh, Guangliang Liu, and Rongrong Wang. Improving generalization of complex models under unbounded loss using PAC-Bayes bounds.Transactions on Machine Learning Research, 2024. 24 A Experimental Protocol We report several implementation choices that are important for conducting and interpreting the linear regression and Pareto analy...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.