Enhancing Gaze Reasoning in Vision Foundation Models for Gaze Following
Pith reviewed 2026-05-22 06:42 UTC · model grok-4.3
The pith
Head-conditioned local LoRA plus out-of-cone penalty strengthens gaze reasoning in vision foundation models for gaze following.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
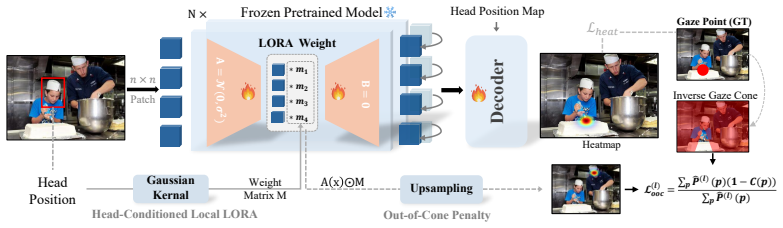
The paper claims that VFM-based gaze following methods suffer from weak gaze reasoning despite strong scene understanding, leading them to rely on semantically salient objects rather than true gaze cues. This limitation is addressed by a head-conditioned local LoRA that enables localized adaptation to improve head token learning for gaze reasoning while preserving scene token learning, combined with an out-of-cone penalty that injects gaze cues into head tokens and aligns them with scene tokens. Experiments confirm this yields state-of-the-art results on GazeFollow and VAT datasets, with the largest gains when targets are not semantically salient.
What carries the argument
head-conditioned local LoRA for localized adaptation of head tokens to boost gaze reasoning while protecting scene learning, together with an out-of-cone penalty that injects directional gaze cues and aligns head tokens with scene tokens
If this is right
- The method reaches state-of-the-art performance on the GazeFollow and VAT datasets.
- Gains are especially large when gaze targets are not semantically salient.
- The approach supplies concrete insights for future gaze following work that emphasize explicit gaze reasoning.
- The training changes keep overall scene understanding intact while adding gaze-specific capability.
Where Pith is reading between the lines
- The same pattern of local adaptation plus alignment penalty could help other vision tasks where models must reason past visual saliency.
- This suggests targeted fine-tuning strategies can add task-specific cues to foundation models without full retraining or loss of generality.
- It motivates creation of test sets that deliberately separate gaze reasoning from object saliency to better measure progress.
Load-bearing premise
That existing VFM-based methods rely mainly on salient objects due to missing gaze reasoning, and that the local LoRA and out-of-cone penalty directly supply and align those cues without harming scene understanding.
What would settle it
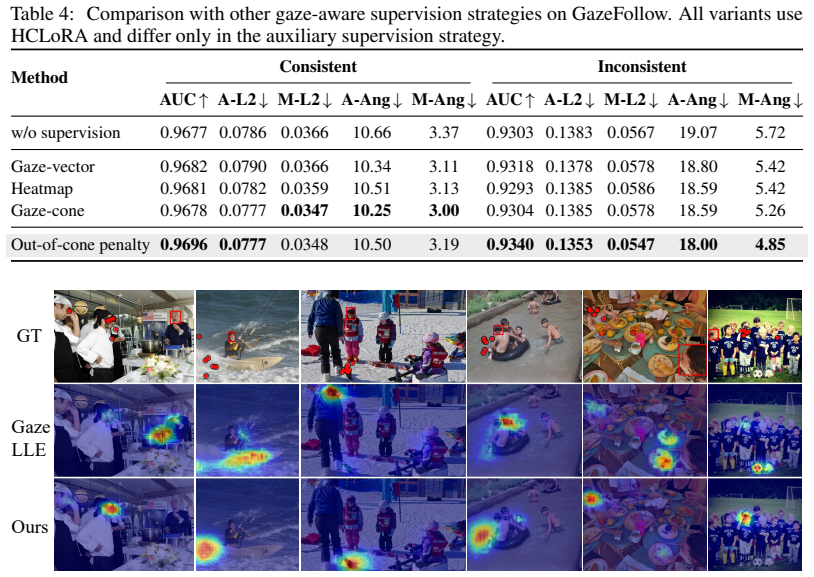
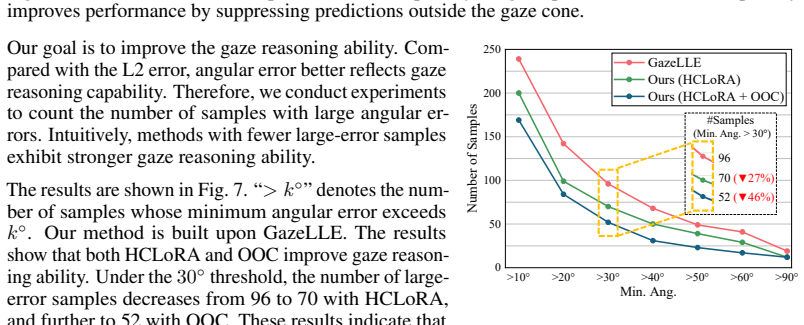
Ablation experiments that remove either the head-conditioned local LoRA or the out-of-cone penalty and measure the resulting drop in accuracy on the GazeFollow dataset, particularly for examples with non-salient gaze targets.
Figures





read the original abstract
Gaze following requires both scene understanding and gaze reasoning to localize the gaze target of an in-scene person. Recently, vision foundation models (VFMs) have demonstrated strong performance on this task, enabling simpler architectures while outperforming prior methods. However, we observe a key limitation of VFM-based approaches: while VFMs substantially improve scene understanding, they contribute little to gaze reasoning. As a result, existing methods often rely on semantically salient objects rather than true gaze cues, leading to degraded performance when targets are not salient. To address this, we propose a novel training mechanism to enhance gaze reasoning in VFMs for gaze following. Our method includes: (1) a head-conditioned local LoRA, which enables localized adaptation to preserve scene token learning while improving head token learning for gaze reasoning; and (2) an out-of-cone penalty, which injects gaze cues into head tokens while aligning them with scene tokens. Experiments on the GazeFollow and VAT datasets demonstrate that our method achieves state-of-the-art performance, with particularly strong improvements when gaze targets are not semantically salient. Our findings offer valuable insights for advancing future gaze following research. We will release the code once the paper is accepted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that vision foundation models (VFMs) improve scene understanding for gaze following but contribute little to gaze reasoning, causing reliance on semantically salient objects. It proposes two components—a head-conditioned local LoRA for localized adaptation that preserves scene token learning while improving head token learning, and an out-of-cone penalty to inject gaze cues into head tokens and align them with scene tokens—to address this limitation. Experiments on GazeFollow and VAT datasets are reported to achieve state-of-the-art performance, with particularly strong gains when targets are not semantically salient.
Significance. If the gains are demonstrated to arise specifically from the proposed gaze-reasoning enhancements rather than generic adaptation, the work could offer a practical way to adapt large VFMs for tasks requiring targeted reasoning beyond general visual understanding. The planned code release would support reproducibility and further research in this area.
major comments (2)
- [§4 Experiments] §4 (Experiments) and associated ablation tables: the central attribution of SOTA gains (especially on non-salient targets) to improved gaze cue injection via the two components requires controlled ablations that hold base VFM capacity and scene-understanding features fixed while varying only the head-conditioned local LoRA and out-of-cone penalty. Without such isolation, the mechanism remains an interpretation rather than a demonstrated cause of the reported improvements.
- [Results section] Results on non-salient subsets (GazeFollow/VAT): the manuscript claims particularly strong improvements on non-salient targets but does not report per-subset metrics with error bars, statistical significance tests, or quantitative deltas relative to baselines. This information is load-bearing for verifying the key claim that the method addresses reliance on salient objects.
minor comments (2)
- [Abstract] Abstract: the statement of 'particularly strong improvements' would be strengthened by including at least one concrete numerical delta or percentage gain on the non-salient subset.
- [Method] Method description: the exact mathematical form of the out-of-cone penalty (e.g., loss term or alignment objective) should be stated explicitly, ideally with an equation, to allow precise reproduction.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4 Experiments] §4 (Experiments) and associated ablation tables: the central attribution of SOTA gains (especially on non-salient targets) to improved gaze cue injection via the two components requires controlled ablations that hold base VFM capacity and scene-understanding features fixed while varying only the head-conditioned local LoRA and out-of-cone penalty. Without such isolation, the mechanism remains an interpretation rather than a demonstrated cause of the reported improvements.
Authors: We agree that more tightly controlled ablations are needed to isolate the causal contribution of the two proposed components. Our current experiments already fix the base VFM backbone across all variants and retain the same scene-understanding features while ablating each component individually. To directly address the referee’s concern, we will add new ablation tables in the revised §4 that strictly hold base VFM capacity and all scene-understanding modules fixed, varying only the head-conditioned local LoRA and the out-of-cone penalty. These additional results will be reported with the same evaluation protocol. revision: yes
-
Referee: [Results section] Results on non-salient subsets (GazeFollow/VAT): the manuscript claims particularly strong improvements on non-salient targets but does not report per-subset metrics with error bars, statistical significance tests, or quantitative deltas relative to baselines. This information is load-bearing for verifying the key claim that the method addresses reliance on salient objects.
Authors: We acknowledge that the current presentation lacks the granular statistics required to fully substantiate the non-salient-target claim. In the revised manuscript we will add dedicated per-subset results for the non-salient targets on both GazeFollow and VAT. These will include mean performance with error bars (standard deviation over multiple random seeds), statistical significance tests against the strongest baselines, and explicit quantitative deltas. The new numbers will be placed in the Results section alongside the existing overall metrics. revision: yes
Circularity Check
No circularity: empirical training modifications with independent experimental validation
full rationale
The paper proposes two explicit training components (head-conditioned local LoRA and out-of-cone penalty) to address an observed limitation in VFM-based gaze following. Claims of SOTA performance and stronger gains on non-salient targets rest on direct experiments on GazeFollow and VAT datasets rather than any derivation, equation, or parameter fit that reduces to its own inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the described method or results. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Social eye gaze in human-robot interaction: a review
Henny Admoni and Brian Scassellati. Social eye gaze in human-robot interaction: a review. Journal of Human-Robot Interaction, 6(1):25–63, 2017
work page 2017
-
[2]
Multimae: Multi-modal multi-task masked autoencoders
Roman Bachmann, David Mizrahi, Aleksandar Atanov, et al. Multimae: Multi-modal multi-task masked autoencoders. InEuropean Conference on Computer Vision, pages 348–367. Springer Nature Switzerland, 2022
work page 2022
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Tracking the leader: Gaze behavior in group interactions.Iscience, 16:242–249, 2019
Francesca Capozzi, Cigdem Beyan, Antonio Pierro, Atesh Koul, Vittorio Murino, Stefano Livi, Andrew P Bayliss, Jelena Ristic, and Cristina Becchio. Tracking the leader: Gaze behavior in group interactions.Iscience, 16:242–249, 2019
work page 2019
-
[5]
Detecting attended visual targets in video
Eunji Chong, Yongxin Wang, Nataniel Ruiz, and James M Rehg. Detecting attended visual targets in video. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5396–5406, 2020
work page 2020
-
[6]
Dual attention guided gaze target detection in the wild
Yi Fang, Jiapeng Tang, Wang Shen, Wei Shen, Xiao Gu, Li Song, and Guangtao Zhai. Dual attention guided gaze target detection in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11390–11399, 2021
work page 2021
-
[7]
Anshul Gupta, Samy Tafasca, and Jean-Marc Odobez. A modular multimodal architecture for gaze target prediction: Application to privacy-sensitive settings. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5041–5050, 2022
work page 2022
-
[8]
Exploring the zero-shot capabilities of vision-language models for improving gaze following
Anshul Gupta, Pierre Vuillecard, Arya Farkhondeh, and Jean-Marc Odobez. Exploring the zero-shot capabilities of vision-language models for improving gaze following. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, pages 615–624, 2024
work page 2024
-
[9]
Roy S Hessels, Toshiki Iwabuchi, Diederick C Niehorster, Ren Funawatari, Jeroen S Benjamins, Sayaka Kawakami, Marcus Nyström, Momoka Suda, Ignace TC Hooge, Motofumi Sumiya, et al. Gaze behavior in face-to-face interaction: A cross-cultural investigation between japan and the netherlands.Cognition, 263:106174, 2025
work page 2025
-
[10]
Nora Horanyi, Linfang Zheng, Eunji Chong, Aleš Leonardis, and Hyung Jin Chang. Where are they looking in the 3d space? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2678–2687, 2023
work page 2023
-
[11]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, and Shean Wang
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, and Shean Wang. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations (ICLR), 2022
work page 2022
-
[12]
Nayeon Kim and Hyunsoo Lee. Assessing consumer attention and arousal using eye-tracking technology in virtual retail environment.Frontiers in Psychology, 12:665658, 2021
work page 2021
-
[13]
Jing Li, Zejin Chen, Yihao Zhong, Hak-Keung Lam, Junxia Han, Gaoxiang Ouyang, Xiaoli Li, and Honghai Liu. Appearance-based gaze estimation for asd diagnosis.IEEE transactions on cybernetics, 52(7):6504–6517, 2022
work page 2022
-
[14]
Patch-level gaze distribution prediction for gaze following
Qiaomu Miao, Minh Hoai, and Dimitris Samaras. Patch-level gaze distribution prediction for gaze following. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 880–889, 2023
work page 2023
-
[15]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc’Aurelio Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaa El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Rodrigo Chacón Quesada, Fernando Estévez Casado, and Yiannis Demiris. An integrated 3d eye-gaze tracking framework for assessing trust in human–robot interaction.ACM Transactions on Human-Robot Interaction, 14(3):1–28, 2025. 10
work page 2025
-
[17]
Where are they looking? Advances in neural information processing systems, 28, 2015
Adria Recasens, Aditya Khosla, Carl V ondrick, and Antonio Torralba. Where are they looking? Advances in neural information processing systems, 28, 2015
work page 2015
-
[18]
Gaze- lle: Gaze target estimation via large-scale learned encoders
Fiona Ryan, Ajay Bati, Sangmin Lee, Daniel Bolya, Judy Hoffman, and James M Rehg. Gaze- lle: Gaze target estimation via large-scale learned encoders. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28874–28884, 2025
work page 2025
-
[19]
Samy Tafasca, Anshul Gupta, Nada Kojovic, Mirko Gelsomini, Thomas Maillart, Michela Papandrea, Marie Schaer, and Jean-Marc Odobez. The ai4autism project: A multimodal and interdisciplinary approach to autism diagnosis and stratification. InCompanion Publication of the 25th International Conference on Multimodal Interaction, pages 414–425, 2023
work page 2023
-
[20]
Sharingan: A transformer architecture for multi-person gaze following
Samy Tafasca, Anshul Gupta, and Jean-Marc Odobez. Sharingan: A transformer architecture for multi-person gaze following. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2008–2017, 2024
work page 2008
-
[21]
End-to-end human-gaze-target detection with transformers
Danyang Tu, Xiongkuo Min, Huiyu Duan, Guodong Guo, Guangtao Zhai, and Wei Shen. End-to-end human-gaze-target detection with transformers. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2192–2200. IEEE, 2022
work page 2022
-
[22]
Zejia Zhang, Bo Yang, Xinxing Chen, Weizhuang Shi, Haoyuan Wang, Wei Luo, and Jian Huang. Mindeye-omniassist: A gaze-driven llm-enhanced assistive robot system for implicit intention recognition and task execution. In2025 IEEE International Conference on Cyborg and Bionic Systems (CBS), pages 1–6. IEEE, 2025. 11
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.