Rubric-Guided Self-Distillation: Post-Training Without Rubric Verifiers
Pith reviewed 2026-06-27 10:11 UTC · model grok-4.3
The pith
Rubric-conditioned base policies can distill their distributions token-by-token into unconditioned students to match verifier-based training results without any judge calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
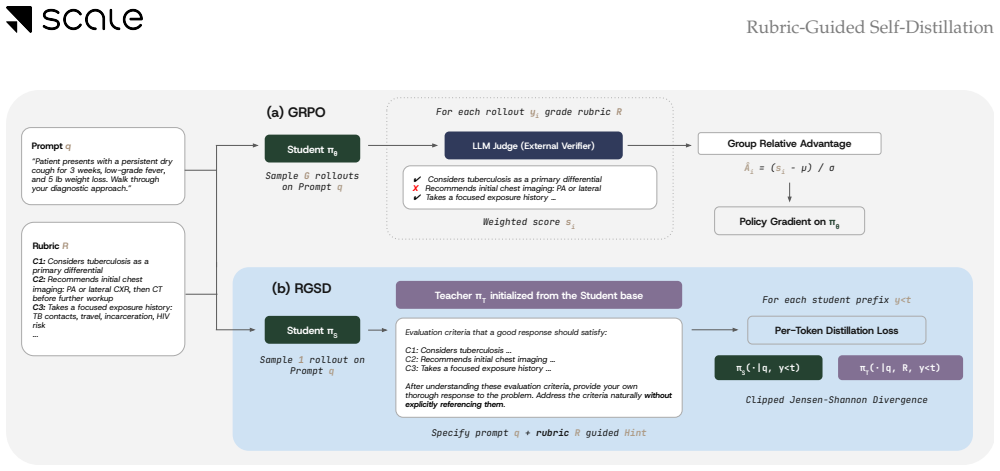
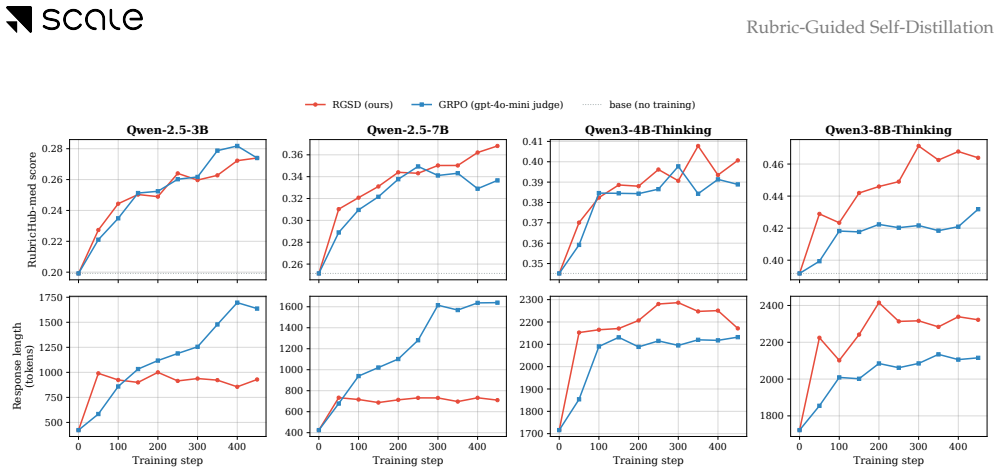
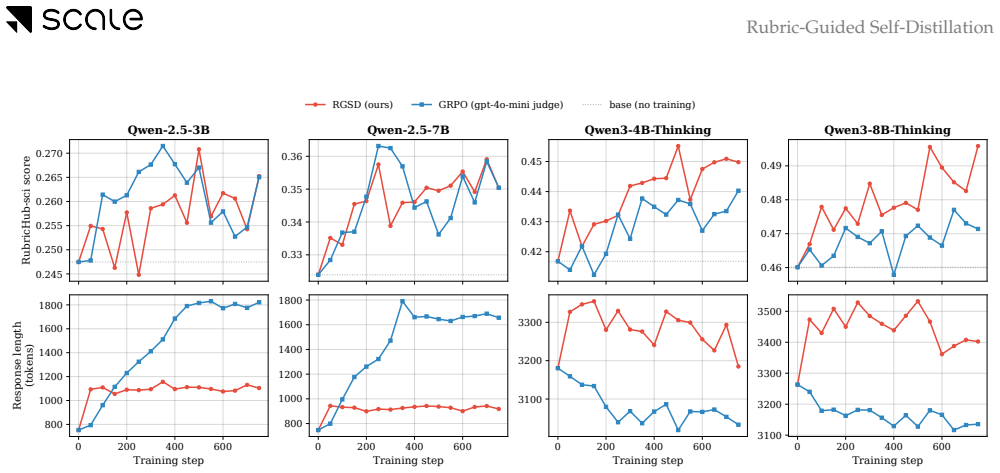
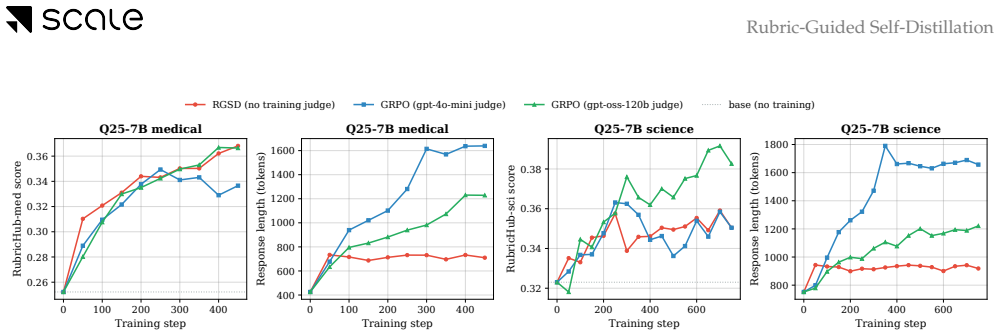
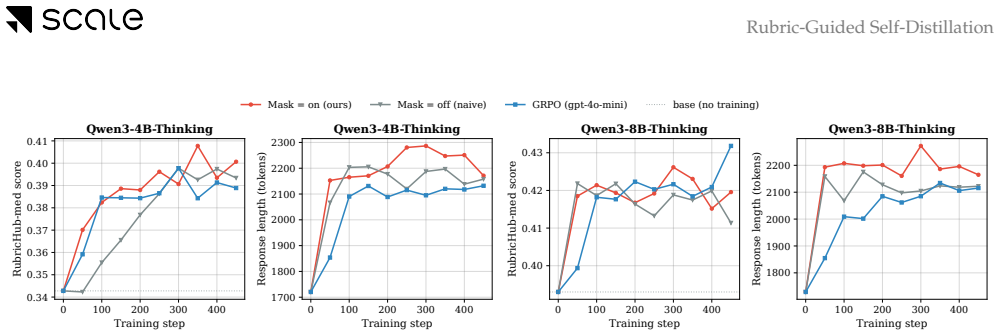
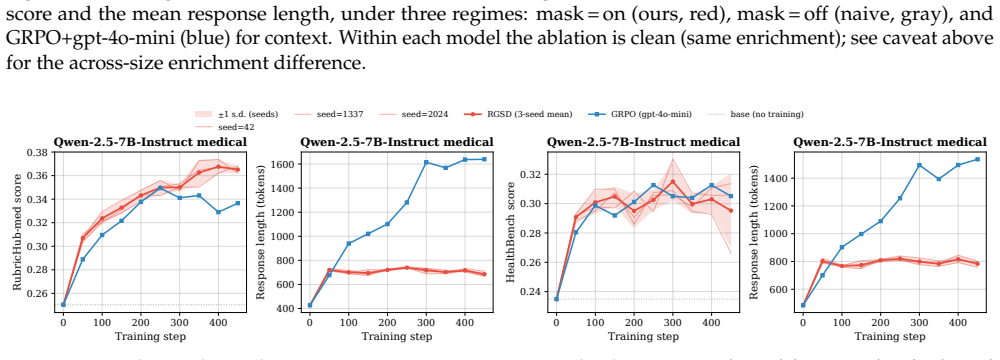
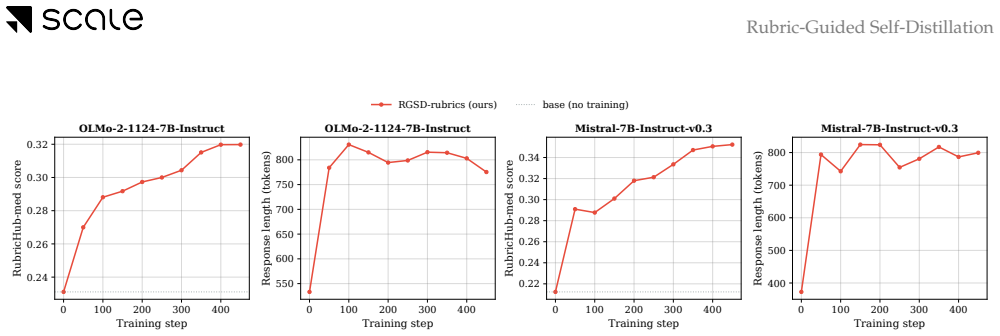
Rubric-Guided Self-Distillation lets the rubric-conditioned base policy serve as teacher and transfers its distribution to the unconditioned student via token-by-token distillation, producing rubric satisfaction comparable to judge-based GRPO on Qwen-2.5 (3B, 7B) and Qwen3-Thinking (4B, 8B) models in medical and science domains while requiring only one on-policy rollout per prompt and zero training-time verifier calls.
What carries the argument
The rubric-conditioned base policy used as teacher to supply per-token probability targets to the unconditioned student policy.
If this is right
- Eliminates all training-time calls to LLM verifiers.
- Replaces sparse trajectory-level rewards with dense per-token learning signals.
- Achieves parity with GRPO using only one on-policy rollout per prompt.
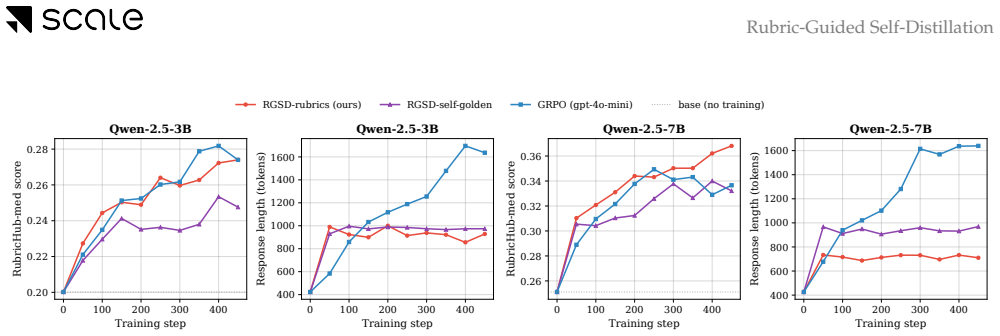
- Raw rubrics provide a stronger teacher signal than self-generated reference responses.
- Serves as a complementary option when verifier cost or reliability is the limiting factor.
Where Pith is reading between the lines
- The approach could reduce overall training compute by removing repeated verifier evaluations.
- Any systematic biases present in the base policy may be transferred to the student through distillation.
- The method might combine with other conditioning signals beyond rubrics for broader post-training use.
- Scaling to much larger models becomes more practical once verifier overhead is removed.
Load-bearing premise
The rubric-conditioned base policy must generate a sufficiently rich and unbiased teacher distribution that can be distilled without losing effectiveness or adding new biases.
What would settle it
Apply both RGSD and GRPO to the same set of prompts and models, then measure final rubric satisfaction; a consistent and sizable gap favoring GRPO would falsify the comparability claim.
Figures






read the original abstract
Rubrics have emerged as an alternative to RLVR in open-ended domains where a single ground-truth final answer is not available. Existing rubric-based training methods rely on an LLM verifier that scores each rollout against rubrics. This introduces substantial training-time overhead, exposes optimization to verifier-specific biases, and reduces rubric feedback to a sparse end-of-trajectory signal. We propose Rubric-Guided Self-Distillation (RGSD), a verifier-free training method in which the base policy, conditioned on the rubric, serves as the teacher for the unconditioned student. RGSD distills the rubric-conditioned teacher distribution into the student token-by-token, replacing sparse trajectory-level rewards with dense per-token learning signals and removing the LLM judge from the training loop entirely. Across Qwen-2.5 (3B, 7B) and Qwen3-Thinking (4B, 8B) models on medical and science domains, RGSD achieves rubric satisfaction comparable to judge-based GRPO while using one on-policy rollout per prompt and no training-time verifier calls. Ablations show that raw rubrics provide a stronger teacher enrichment signal than self-generated reference responses, while a stronger GRPO judge can outperform RGSD in some settings, positioning RGSD as a complementary verifier-free alternative when verifier cost or reliability is the bottleneck.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Rubric-Guided Self-Distillation (RGSD), a verifier-free post-training approach in which a rubric-conditioned base policy acts as teacher and its token distribution is distilled per-token into an unconditioned student policy. This replaces sparse trajectory-level verifier signals with dense per-token learning and eliminates LLM judges from the training loop. On Qwen-2.5 (3B/7B) and Qwen3-Thinking (4B/8B) models in medical and science domains, RGSD is reported to reach rubric satisfaction levels comparable to judge-based GRPO while using only one on-policy rollout per prompt and no training-time verifier calls; ablations indicate raw rubrics outperform self-generated references as the conditioning signal.
Significance. If the core mechanism holds, RGSD would supply a lower-cost, lower-bias alternative to existing rubric-based RL methods for open-ended domains, replacing end-of-trajectory rewards with dense token-level supervision and removing verifier overhead. The positioning as a complementary method when verifier reliability or cost is the bottleneck is potentially useful for scaling post-training.
major comments (3)
- [Method / §3] The central claim that rubric conditioning produces a meaningfully richer teacher distribution (and thereby an effective distillation signal) is load-bearing yet untested. No quantitative evidence of distribution shift (e.g., KL divergence, token-level rubric-adherence gain, or per-token reward correlation) between the conditioned and unconditioned policies is provided, leaving open the possibility that the reported parity with GRPO arises from other factors.
- [Experiments] Experimental results (Abstract and Experiments section) assert comparability to GRPO on rubric satisfaction for the listed model sizes and domains, but supply no details on evaluation protocol, number of evaluation prompts, statistical significance, variance across runs, or full set of baselines and ablations. Without these, the claim that RGSD matches judge-based performance cannot be assessed.
- [Ablations] The ablation claiming raw rubrics yield a stronger enrichment signal than self-generated references is presented as supporting evidence, yet does not isolate the effect of rubric conditioning itself (e.g., by comparing conditioned vs. unconditioned teacher distributions on the same rubric set). This leaves the weakest assumption unaddressed.
minor comments (2)
- [Method] Notation for the distillation objective (per-token cross-entropy between teacher and student) should be stated explicitly with the conditioning variable made visible.
- [Abstract / Experiments] The statement that RGSD uses “one on-policy rollout per prompt” should be accompanied by a direct comparison of total forward passes or wall-clock cost versus GRPO to substantiate the efficiency claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below, indicating where the manuscript will be revised to address the concerns raised.
read point-by-point responses
-
Referee: [Method / §3] The central claim that rubric conditioning produces a meaningfully richer teacher distribution (and thereby an effective distillation signal) is load-bearing yet untested. No quantitative evidence of distribution shift (e.g., KL divergence, token-level rubric-adherence gain, or per-token reward correlation) between the conditioned and unconditioned policies is provided, leaving open the possibility that the reported parity with GRPO arises from other factors.
Authors: We agree that direct quantitative evidence of the distribution shift would strengthen the central claim. The current manuscript relies on downstream performance parity and ablations as indirect support. In the revision we will add a new analysis subsection reporting KL divergence between rubric-conditioned and unconditioned teacher distributions, together with token-level rubric-adherence gains measured on a held-out prompt set. revision: yes
-
Referee: [Experiments] Experimental results (Abstract and Experiments section) assert comparability to GRPO on rubric satisfaction for the listed model sizes and domains, but supply no details on evaluation protocol, number of evaluation prompts, statistical significance, variance across runs, or full set of baselines and ablations. Without these, the claim that RGSD matches judge-based performance cannot be assessed.
Authors: The evaluation protocol (500 prompts per domain, 3 random seeds with reported standard deviations, paired t-tests for significance, and the complete baseline set including SFT and multiple GRPO variants) appears in Section 4.2 and Appendix B. We will revise the main Experiments section to include an explicit summary paragraph and table of the evaluation setup so that these details are immediately visible. revision: partial
-
Referee: [Ablations] The ablation claiming raw rubrics yield a stronger enrichment signal than self-generated references is presented as supporting evidence, yet does not isolate the effect of rubric conditioning itself (e.g., by comparing conditioned vs. unconditioned teacher distributions on the same rubric set). This leaves the weakest assumption unaddressed.
Authors: The reported ablation isolates the choice of conditioning signal while holding the distillation procedure fixed. To isolate the conditioning effect itself we will add, in the revised manuscript, an explicit comparison of the rubric-conditioned teacher against an otherwise identical unconditioned teacher on the same rubric set. revision: yes
Circularity Check
No circularity: empirical method with no derivations or self-referential steps
full rationale
The paper describes an empirical post-training procedure (RGSD) that conditions a base policy on rubrics to generate teacher distributions for token-level distillation into an unconditioned student. No equations, derivations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. The central claim rests on experimental comparisons (Qwen models on medical/science tasks) rather than any reduction to self-citations, ansatzes, or definitional loops. The method is presented as a practical alternative to judge-based GRPO without invoking prior author work to force its validity. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The rubric-conditioned base policy produces a high-quality teacher distribution suitable for token-level distillation into the unconditioned student.
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. 2024. URL https://arxiv.org/abs/2306.13649
arXiv 2024
-
[2]
Prbench: Large-scale expert rubrics for evaluating high-stakes professional reasoning, 2025
Afra Feyza Akyürek, Advait Gosai, Chen Bo Calvin Zhang, Vipul Gupta, Jaehwan Jeong, Anisha Gunjal, Tahseen Rabbani, Maria Mazzone, David Randolph, Mohammad Mahmoudi Meymand, Gurshaan Chattha, Paula Rodriguez, Diego Mares, Pavit Singh, Michael Liu, Subodh Chawla, Pete Cline, Lucy Ogaz, Ernesto Hernandez, Zihao Wang, Pavi Bhatter, Marcos Ayestaran, Bing Liu...
arXiv 2025
-
[3]
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero-Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. Healthbench: Evaluating large language models towards improved human health, 2025. URL https://arxiv.org/abs/2505.08775
Pith/arXiv arXiv 2025
-
[4]
Mcp-atlas: A large-scale benchmark for tool-use competency with real mcp servers, 2026
Chaithanya Bandi, Razvan-Gabriel Dumitru, Ben Hertzberg, Divyansh Agarwal, Geobio Boo, Tejas Polakam, Sami Hassaan, Jeff Da, HiJae Kim, Vipul Gupta, Manasi Sharma, Andrew Park, Martin Dimakis, Ernesto Gabriel Hernandez Montoya, Dan Rambado, Ivan Salazar, Rafael Cruz, MohammadHossein Rezaei, Chetan Rane, Ben Levin, Daniel Yue Zhang, Brad Kenstler, and Bing...
Pith/arXiv arXiv 2026
-
[5]
and Yue, Summer and Xing, Chen
Kaustubh Deshpande, Ved Sirdeshmukh, Johannes Baptist Mols, Lifeng Jin, Ed-Yeremai Hernandez-Cardona, Dean Lee, Jeremy Kritz, Willow E. Primack, Summer Yue, and Chen Xing. M ulti C hallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier LLM s. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar...
-
[6]
Advait Gosai, Tyler Vuong, Utkarsh Tyagi, Steven Li, Wenjia You, Miheer Bavare, Arda Uçar, Zhongwang Fang, Brian Jang, Bing Liu, and Yunzhong He. Audio multichallenge: A multi-turn evaluation of spoken dialogue systems on natural human interaction, 2025. URL https://arxiv.org/abs/2512.14865
arXiv 2025
-
[7]
Minillm: On-policy distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: On-policy distillation of large language models. 2026. URL https://arxiv.org/abs/2306.08543
Pith/arXiv arXiv 2026
-
[8]
Rubrics as rewards: Reinforcement learning beyond verifiable domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains. arXiv preprint arXiv:2507.17746, 2025. URL https://arxiv.org/abs/2507.17746
Pith/arXiv arXiv 2025
-
[9]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[10]
Yun He, Wenzhe Li, Hejia Zhang, Songlin Li, Karishma Mandyam, Sopan Khosla, Yuanhao Xiong, Nanshu Wang, Xiaoliang Peng, Beibin Li, Shengjie Bi, Shishir G. Patil, Qi Qi, Shengyu Feng, Julian Katz-Samuels, Richard Yuanzhe Pang, Sujan Gonugondla, Hunter Lang, Yue Yu, Yundi Qian, Maryam Fazel-Zarandi, Licheng Yu, Amine Benhalloum, Hany Awadalla, and Manaal Fa...
arXiv 2025
-
[11]
Jonas H \"u botter, Frederike L \"u beck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement learning via self-distillation. arXiv preprint arXiv:2601.20802, 2026. URL https://arxiv.org/abs/2601.20802
Pith/arXiv arXiv 2026
-
[12]
Sunzhu Li, Jiale Zhao, Miteto Wei, Huimin Ren, Yang Zhou, Jingwen Yang, Shunyu Liu, Kaike Zhang, and Wei Chen. Rubrichub: A comprehensive and highly discriminative rubric dataset via automated coarse-to-fine generation. arXiv preprint arXiv:2601.08430, 2026 a . URL https://arxiv.org/abs/2601.08430
arXiv 2026
-
[13]
Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe. arXiv preprint arXiv:2604.13016, 2026 b . URL https://arxiv.org/abs/2604.13016
Pith/arXiv arXiv 2026
-
[14]
Tianci Liu, Ran Xu, Tony Yu, Ilgee Hong, Carl Yang, Tuo Zhao, and Haoyu Wang. Openrubrics: Towards scalable synthetic rubric generation for reward modeling and llm alignment, 2026. URL https://arxiv.org/abs/2510.07743
arXiv 2026
-
[15]
On-policy distillation
Kevin Lu and Thinking Machines . On-policy distillation. https://thinkingmachines.ai/blog/on-policy-distillation/, 2025. Blog post
2025
-
[16]
Reward hacking in rubric-based reinforcement learning
Anas Mahmoud, MohammadHossein Rezaei, Zihao Wang, Anisha Gunjal, Bing Liu, and Yunzhong He. Reward hacking in rubric-based reinforcement learning. arXiv preprint arXiv:2605.12474, 2026. URL https://arxiv.org/abs/2605.12474
Pith/arXiv arXiv 2026
-
[17]
Qwen, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Ti...
Pith/arXiv arXiv 2025
-
[18]
Swe atlas: Benchmarking coding agents beyond issue resolution, 2026
Mohit Raghavendra, Soham Dan, Miguel Romero Calvo, Yannis Yiming He, Johannes Baptist Mols, Gautam Anand, Cole McCollum, Edgar Arakelyan, Vijay Bharadwaj, Andrew Park, Jeff Da, MohammadHossein Rezaei, Bing Liu, Brad Kenstler, and Yunzhong He. Swe atlas: Benchmarking coding agents beyond issue resolution, 2026. URL https://arxiv.org/abs/2605.08366
Pith/arXiv arXiv 2026
-
[19]
Online rubrics elicitation from pairwise comparisons
MohammadHossein Rezaei, Robert Vacareanu, Zihao Wang, Clinton Wang, Bing Liu, Yunzhong He, and Afra Feyza Aky \"u rek. Online rubrics elicitation from pairwise comparisons. arXiv preprint arXiv:2510.07284, 2025. URL https://arxiv.org/abs/2510.07284
arXiv 2025
-
[20]
A reduction of imitation learning and structured prediction to no-regret online learning
Stephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In Geoffrey Gordon, David Dunson, and Miroslav Dudík, editors, Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 of Proceedings of Machine Learning Research, p...
2011
-
[21]
Rulin Shao, Akari Asai, Shannon Zejiang Shen, Hamish Ivison, Varsha Kishore, Jingming Zhuo, Xinran Zhao, Molly Park, Samuel G. Finlayson, David Sontag, Tyler Murray, Sewon Min, Pradeep Dasigi, Luca Soldaini, Faeze Brahman, Wen tau Yih, Tongshuang Wu, Luke Zettlemoyer, Yoon Kim, Hannaneh Hajishirzi, and Pang Wei Koh. Dr tulu: Reinforcement learning with ev...
Pith/arXiv arXiv 2025
-
[22]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/2402.03300
Pith/arXiv arXiv 2024
-
[23]
Hendryx, Brad Kenstler, and Bing Liu
Manasi Sharma, Chen Bo Calvin Zhang, Chaithanya Bandi, Clinton Wang, Ankit Aich, Huy Nghiem, Tahseen Rabbani, Ye Htet, Brian Jang, Sumana Basu, Aishwarya Balwani, Denis Peskoff, Marcos Ayestaran, Sean M. Hendryx, Brad Kenstler, and Bing Liu. Researchrubrics: A benchmark of prompts and rubrics for evaluating deep research agents, 2025. URL https://arxiv.or...
arXiv 2025
-
[24]
Not every rubric teaches equally: Policy-aware rubric rewards for rlvr, 2026
Utkarsh Tyagi, Xingang Guo, MohammadHossein Rezaei, Daniel George, Anas Mahmoud, Jackson Lee, Bing Liu, and Yunzhong He. Not every rubric teaches equally: Policy-aware rubric rewards for rlvr, 2026. URL https://arxiv.org/abs/2605.20164
Pith/arXiv arXiv 2026
-
[25]
Checklists are better than reward models for aligning language models
Vijay Viswanathan, Yanchao Sun, Shuang Ma, Xiang Kong, Meng Cao, Graham Neubig, and Tongshuang Wu. Checklists are better than reward models for aligning language models. arXiv preprint arXiv:2507.18624, 2025. URL https://arxiv.org/abs/2507.18624
arXiv 2025
-
[26]
Profbench: Multi-domain rubrics requiring professional knowledge to answer and judge, 2025
Zhilin Wang, Jaehun Jung, Ximing Lu, Shizhe Diao, Ellie Evans, Jiaqi Zeng, Pavlo Molchanov, Yejin Choi, Jan Kautz, and Yi Dong. Profbench: Multi-domain rubrics requiring professional knowledge to answer and judge, 2025. URL https://arxiv.org/abs/2510.18941
Pith/arXiv arXiv 2025
-
[27]
Writingbench: A comprehensive benchmark for generative writing, 2025
Yuning Wu, Jiahao Mei, Ming Yan, Chenliang Li, Shaopeng Lai, Yuran Ren, Zijia Wang, Ji Zhang, Mengyue Wu, Qin Jin, and Fei Huang. Writingbench: A comprehensive benchmark for generative writing, 2025. URL https://arxiv.org/abs/2503.05244
arXiv 2025
-
[28]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[29]
Yifei, Allen Chang, Chaitanya Malaviya, and Mark Yatskar
Li S. Yifei, Allen Chang, Chaitanya Malaviya, and Mark Yatskar. Researchqa: Evaluating scholarly question answering at scale across 75 fields with survey-mined questions and rubrics, 2025. URL https://arxiv.org/abs/2509.00496
arXiv 2025
-
[30]
Chasing the tail: Effective rubric-based reward modeling for large language model post-training
Junkai Zhang, Zihao Wang, Lin Gui, Swarnashree Mysore Sathyendra, Jaehwan Jeong, Victor Veitch, Wei Wang, Yunzhong He, Bing Liu, and Lifeng Jin. Chasing the tail: Effective rubric-based reward modeling for large language model post-training. arXiv preprint arXiv:2509.21500, 2025. URL https://arxiv.org/abs/2509.21500
arXiv 2025
-
[31]
Self-distilled reasoner: On-policy self-distillation for large language models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models. arXiv preprint arXiv:2601.18734, 2026. URL https://arxiv.org/abs/2601.18734
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.