Which Changes Matter? Towards Trustworthy Legal AI via Relevance-Sensitive Evaluation and Solver-Grounded Reasoning
Pith reviewed 2026-06-29 18:37 UTC · model grok-4.3
The pith
Legal AI achieves calibrated sensitivity to relevant changes by formalizing statutes as executable constraints verified by solvers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
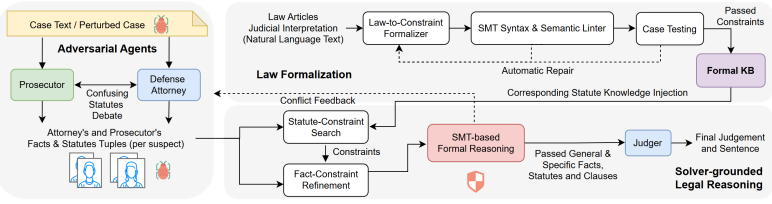
The paper claims that legal trustworthiness requires not only accuracy but calibrated sensitivity to legally material changes, and that LexGuard meets this requirement by formalizing statutes into executable constraints, using adversarial agents to extract competing fact-statute arguments, and invoking SMT solvers to verify legal satisfaction and logical consistency, thereby reducing vulnerability to manipulative framing, improving disambiguation among similar statutes, limiting the influence of legally irrelevant attributes, and increasing consistency under benign reformulations.
What carries the argument
LexGuard, the adversarial multi-agent framework that formalizes statutes into executable SMT constraints to verify legal satisfaction and logical consistency.
If this is right
- Reduces vulnerability to manipulative framing in legal queries.
- Improves disambiguation among similar statutes.
- Limits the influence of legally irrelevant attributes on model outputs.
- Increases consistency under benign reformulations of the same legal scenario.
Where Pith is reading between the lines
- The same formalization-plus-adversarial approach could be adapted to other rule-based domains that require distinguishing material from immaterial facts.
- Benchmarks pairing should-change and should-not-change examples may become necessary for any high-stakes AI evaluation.
- Alignment between solver outputs and practicing lawyers' judgments on ambiguous cases would provide a direct test of the formalization step.
Load-bearing premise
Statutes can be faithfully formalized into executable constraints without losing legally material distinctions that human interpreters would still treat as relevant.
What would settle it
A statute where the SMT formalization and solver output produce a different conclusion from human legal experts on an edge case that turns on a subtle but material distinction.
Figures
read the original abstract
Legal reasoning requires distinguishing changes that matter from those that do not. Legal AI should remain stable under legally irrelevant perturbations, but should change when perturbations alter legally material points. We formulate this requirement as a legal-relevance-sensitive evaluation problem: LLMs should only be sensitive to the legally relevant change. We introduce a unified evaluation suite covering should-change and should-not-change evaluation across judicial fairness, robustness, and statute-confusion scenarios. Our evaluation shows that existing legal LLMs are systematically sensitive to legally irrelevant variations and often fail to distinguish related legal elements and statutory rules. To mitigate these failures, we present LexGuard, an adversarial multi-agent framework grounded in formal reasoning. LexGuard formalizes statutes into executable constraints, uses adversarial agents to extract competing fact-statute arguments, and invokes SMT solvers to verify legal satisfaction and logical consistency. Experiments show that LexGuard improves legal reasoning reliability by reducing vulnerability to manipulative framing, improving disambiguation among similar statutes, limiting the influence of legally irrelevant attributes, and increasing consistency under benign reformulations. We show that legal trustworthiness requires not only accuracy, but calibrated sensitivity to legally material changes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that legal LLMs must be sensitive only to legally material changes and insensitive to irrelevant perturbations. It introduces a unified evaluation suite for should-change and should-not-change scenarios across judicial fairness, robustness, and statute confusion. Existing models are shown to fail these tests. LexGuard is proposed as an adversarial multi-agent framework that formalizes statutes into SMT constraints, extracts competing arguments, and uses solvers for verification; the abstract states that experiments demonstrate gains in framing robustness, statute disambiguation, reduced influence of irrelevant attributes, and consistency under reformulations.
Significance. If the empirical claims hold and the SMT formalization preserves legally material distinctions, the work would offer a concrete method for calibrating LLM sensitivity to legal relevance, combining adversarial agents with solver-grounded verification. The relevance-sensitive evaluation framing and the unified suite are useful contributions even if the specific LexGuard implementation requires further validation.
major comments (2)
- [Abstract] Abstract: the central claim that 'Experiments show that LexGuard improves legal reasoning reliability...' is unsupported by any quantitative metrics, error bars, dataset descriptions, or baseline comparisons, rendering the reported gains in framing robustness and statute disambiguation unverifiable.
- [LexGuard description] LexGuard framework (formalization step): the assumption that statutes can be reduced to executable SMT constraints without omitting or distorting open-textured legal concepts, balancing tests, or purposive considerations is not justified; if material distinctions are lost, downstream verification cannot reliably separate should-change from should-not-change cases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Experiments show that LexGuard improves legal reasoning reliability...' is unsupported by any quantitative metrics, error bars, dataset descriptions, or baseline comparisons, rendering the reported gains in framing robustness and statute disambiguation unverifiable.
Authors: The abstract is intentionally concise and summarizes findings whose details appear in the full manuscript. Sections 5 and 6 report quantitative results, including accuracy deltas, robustness percentages with standard deviations, dataset sizes and sources, and explicit baseline comparisons against unmodified legal LLMs and non-solver adversarial methods. To improve verifiability at the abstract level, we will revise the abstract to include one or two representative quantitative highlights (e.g., percentage-point gains) drawn directly from those sections. revision: yes
-
Referee: [LexGuard description] LexGuard framework (formalization step): the assumption that statutes can be reduced to executable SMT constraints without omitting or distorting open-textured legal concepts, balancing tests, or purposive considerations is not justified; if material distinctions are lost, downstream verification cannot reliably separate should-change from should-not-change cases.
Authors: We agree that SMT encoding is necessarily an approximation and cannot capture every nuance of open-textured language or purposive interpretation. The manuscript (Section 4.2) restricts the formalization to statutes whose core logical predicates can be expressed without loss of the should-change/should-not-change distinction, and validates each encoding against expert legal annotations. We will add an expanded limitations paragraph that explicitly discusses the scope of this approximation and the conditions under which the method is intended to apply. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents LexGuard as an external framework that formalizes statutes into SMT constraints, deploys adversarial agents, and invokes solvers for verification. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described structure. The central claims rest on empirical evaluation against an independently motivated relevance-sensitive criterion rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Statutes can be formalized into executable logical constraints without loss of legally material distinctions.
- standard math SMT solvers correctly decide satisfiability and consistency for the encoded legal constraints.
invented entities (1)
-
LexGuard adversarial multi-agent framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Logic tensor networks.Artificial Intelligence, 303:103649, 2022
Samy Badreddine, Artur d’Avila Garcez, Luciano Serafini, and Michael Spranger. Logic tensor networks.Artificial Intelligence, 303:103649, 2022
2022
-
[2]
Guhong Chen, Liyang Fan, Zihan Gong, Nan Xie, Zixuan Li, Ziqiang Liu, Chengming Li, Qiang Qu, Shiwen Ni, and Min Yang. Agentcourt: Simulating court with adversarial evolvable lawyer agents.arXiv preprint arXiv:2408.08089, 2024
-
[3]
Chatlaw: A Multi-Agent Legal Assistant based on a Role-Aligned Mixture-of-Experts Architecture
Jiaxi Cui, Zongjian Li, Yang Yan, Bohua Chen, and Li Yuan. ChatLaw: Open-source legal large language model with integrated external knowledge bases.CoRR, abs/2306.16092, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Z3: an efficient smt solver
Leonardo De Moura and Nikolaj Bjørner. Z3: an efficient smt solver. InProceedings of the Theory and Practice of Software, 14th International Conference on Tools and Algorithms for the Construction and Analysis of Systems, TACAS’08/ETAPS’08, page 337–340, Berlin, Heidelberg, 2008. Springer-Verlag
2008
-
[5]
Lawbench: Bench- marking legal knowledge of large language models
Zhiwei Fei, Xiaoyu Shen, Dawei Zhu, Fengzhe Zhou, Zhuo Han, Alan Huang, Songyang Zhang, Kai Chen, Zhixin Yin, Zongwen Shen, Jidong Ge, and Vincent Ng. Lawbench: Bench- marking legal knowledge of large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7933–7962. Association for Computational Li...
2024
-
[6]
Enhancing legal case retrieval via scaling high-quality synthetic query–candidate pairs
Cheng Gao, Chaojun Xiao, Zhenghao Liu, Huimin Chen, Zhiyuan Liu, and Maosong Sun. Enhancing legal case retrieval via scaling high-quality synthetic query–candidate pairs. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7086–7100. Association for Computational Linguistics, 2024
2024
-
[7]
Lexguard artifact.https://sites.google.com/view/ legalai-aaai/home, 2026
Anonymous GitHub. Lexguard artifact.https://sites.google.com/view/ legalai-aaai/home, 2026
2026
-
[8]
Neel Guha, Julian Nyarko, Daniel E. Ho, Christopher R ´e, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel Rockmore, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory Dickinson, Haggai Porat, Jason Hegland, Jessica Wu, et al. Legalbench: A collaboratively built benchmark fo...
2023
-
[9]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InProc. ICLR 2021, 2021
2021
-
[10]
Incorporating legal structure in retrieval- augmented generation: A case study on copyright fair use, 2025
Justin Ho, Alexandra Colby, and William Fisher. Incorporating legal structure in retrieval- augmented generation: A case study on copyright fair use, 2025
2025
-
[11]
Gaps or hallucinations? gazing into machine-generated legal analysis for fine-grained text evaluations, 2024
Abe Bohan Hou, William Jurayj, Nils Holzenberger, Andrew Blair-Stanek, and Benjamin Van Durme. Gaps or hallucinations? gazing into machine-generated legal analysis for fine-grained text evaluations, 2024
2024
-
[12]
Yiran Hu, Huanghai Liu, Qingjing Chen, Ning Zheng, Chong Wang, Yun Liu, Charles L. A. Clarke, and Weixing Shen. J&h: Evaluating the robustness of large language models under knowledge-injection attacks in legal domain. InProceedings of the AAAI Conference on Arti- ficial Intelligence, volume 39, pages 28106–28114, 2025
2025
-
[13]
J&h: Evaluating the robustness of large language models under knowledge-injection attacks in legal domain
Yiran Hu, Huanghai Liu, Qingjing Chen, Ning Zheng, Chong Wang, Yun Liu, Charles LA Clarke, and Weixing Shen. J&h: Evaluating the robustness of large language models under knowledge-injection attacks in legal domain. InProceedings of the AAAI Conference on Arti- ficial Intelligence, volume 39, pages 28106–28115, 2025
2025
-
[14]
Cong Jiang and Xiaolei Yang. Agents on the bench: Large language model based multi agent framework for trustworthy digital justice.arXiv preprint arXiv:2412.18697, 2024. 11
-
[15]
Manuj Kant, Sareh Nabi, Manav Kant, Roland Scharrer, Megan Ma, and Marzieh Nabi. To- wards robust legal reasoning: Harnessing logical llms in law.arXiv preprint arXiv:2502.17638, 2025
-
[16]
Katz, Michael J
Daniel M. Katz, Michael J. Bommarito II, Shang Gao, and Pablo Arredondo. GPT-4 passes the bar exam.Philosophical Transactions of the Royal Society A, 2024. First posted as SSRN 4389233, 2023
2024
-
[17]
A legal framework for explain- able artificial intelligence.Center for Law & Economics Working Paper Series, 9, 2024
Aniket Kesari, Daniela Sele, Elliott Ash, and Stefan Bechtold. A legal framework for explain- able artificial intelligence.Center for Law & Economics Working Paper Series, 9, 2024
2024
-
[18]
Lexilaw: A scalable legal language model for comprehensive legal understanding.https://github.com/CSHaitao/LexiLaw, 2024
Haitao Li, Qingyao Ai, Qian Dong, and Yiqun Liu. Lexilaw: A scalable legal language model for comprehensive legal understanding.https://github.com/CSHaitao/LexiLaw, 2024
2024
-
[19]
Legalagentbench: Eval- uating llm agents in legal domain
Haitao Li, Junjie Chen, Jingli Yang, Qingyao Ai, Wei Jia, Youfeng Liu, Kai Lin, Yueyue Wu, Guozhi Yuan, Yiran Hu, Wuyue Wang, Yiqun Liu, and Minlie Huang. Legalagentbench: Eval- uating llm agents in legal domain. InProceedings of the 63rd Annual Meeting of the Associ- ation for Computational Linguistics (Volume 1: Long Papers), pages 2322–2344. Associatio...
2025
-
[20]
Lecardv2: A large-scale chinese legal case retrieval dataset.arXiv preprint arXiv:2310.17609, 2023
Haitao Li, Yunqiu Shao, Yueyue Wu, Qingyao Ai, Yixiao Ma, and Yiqun Liu. Lecardv2: A large-scale chinese legal case retrieval dataset.arXiv preprint arXiv:2310.17609, 2023
-
[21]
Judicial requirements for generative ai in legal reasoning.arXiv preprint arXiv:2508.18880, 2025
Eljas Linna and Tuula Linna. Judicial requirements for generative ai in legal reasoning.arXiv preprint arXiv:2508.18880, 2025
-
[22]
Deepproblog: Neural probabilistic logic programming
Robin Manhaeve, Sebastijan Duman ˇci´c, Angelika Kimmig, Thomas Demeester, and Luc De Raedt. Deepproblog: Neural probabilistic logic programming. InAdvances in Neural Information Processing Systems, volume 31, 2018
2018
-
[23]
LEXTREME: A multi-lingual and multi-task benchmark for the legal domain
Joel Niklaus, Veton Matoshi, Pooja Rani, Andrea Galassi, Matthias St ¨urmer, and Ilias Chalkidis. LEXTREME: A multi-lingual and multi-task benchmark for the legal domain. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 3016–3054. Association for Computational Linguistics, 2023
2023
- [24]
-
[25]
On verifiable legal reasoning: A multi-agent framework with formalized knowledge representations
Albert Sadowski and Jaroslaw A Chudziak. On verifiable legal reasoning: A multi-agent framework with formalized knowledge representations. InProceedings of the 34th ACM Inter- national Conference on Information and Knowledge Management, pages 2535–2545, 2025
2025
-
[26]
Unlocking practical applications in the legal domain: Evaluation of GPT for zero-shot semantic annotation of legal texts
Jaromir Savelka. Unlocking practical applications in the legal domain: Evaluation of GPT for zero-shot semantic annotation of legal texts. InProc. ICAIL 2023, pages 447–451, 2023
2023
-
[27]
Lawllm: Law large language model for the us legal system
Dong Shu, Haoran Zhao, Xukun Liu, David Demeter, Mengnan Du, and Yongfeng Zhang. Lawllm: Law large language model for the us legal system. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, CIKM ’24, page 4882–4889. ACM, October 2024
2024
-
[28]
Logic rules as explana- tions for legal case retrieval (ns-lcr)
Zhongxiang Sun, Kepu Zhang, Weijie Yu, Haoyu Wang, and Jun Xu. Logic rules as explana- tions for legal case retrieval (ns-lcr). InProceedings of LREC-COLING 2024, 2024
2024
-
[29]
Leec for judicial fairness: A legal element extraction dataset with extensive extra-legal labels
Zongyue Xue, Huanghai Liu, Yiran Hu, Yuliang Qian, Yajing Wang, Kangle Kong, Chenlu Wang, Yun Liu, and Weixing Shen. Leec for judicial fairness: A legal element extraction dataset with extensive extra-legal labels. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, pages 7527–7535, 2024
2024
-
[30]
Lawyer gpt: A legal large language model with enhanced domain knowledge and reasoning capabilities
Shunyu Yao, Qingqing Ke, Qiwei Wang, Kangtong Li, and Jie Hu. Lawyer gpt: A legal large language model with enhanced domain knowledge and reasoning capabilities. InProceed- ings of the 3rd International Symposium on Robotics, Artificial Intelligence and Information Engineering (RAIIE ’24), pages 108–112. ACM, 2024. 12
2024
-
[31]
Llms on trial: Evaluating judicial fairness for large language models
HU Yiran, Zongyue Xue, Haitao Li, Siyuan Zheng, Qingjing Chen, Shaochun Wang, Xihan Zhang, Ning Zheng, Yun Liu, Qingyao Ai, et al. Llms on trial: Evaluating judicial fairness for large language models. InWorkshop on Socially Responsible Language Modelling Research
-
[32]
the suspect intentionally caused serious injury
Shengbin Yue, Wei Chen, Siyuan Wang, Bingxuan Li, Chenchen Shen, Shujun Liu, Yuxuan Zhou, Yao Xiao, Song Yun, Xuanjing Huang, and Zhongyu Wei. Disc-lawllm: Fine-tuning large language models for intelligent legal services.arXiv preprint arXiv:2309.11325, 2023. 13 A Cost Statistics Table 7: Average cost per case of LexGuard. Metric Average LLM calls per cas...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.