RoIt-XMASA: Multi-Domain Multilingual Sentiment Analysis Dataset for Romanian and Italian
Pith reviewed 2026-05-25 06:34 UTC · model grok-4.3
The pith
A new dataset and meta-learned adversarial method improve cross-lingual sentiment analysis for Romanian and Italian.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the RoIt-XMASA dataset, extending prior Amazon sentiment data to Italian and Romanian, combined with a multi-target adversarial training framework using loss reversal and meta-learned coefficients, enables XLM-R to achieve 66.23% F1-score on the task of cross-lingual and cross-domain sentiment analysis, surpassing the baseline by 4.64%.
What carries the argument
Multi-target adversarial training framework with loss reversal and meta-learned coefficients for balancing sentiment discrimination against domain and language invariance.
If this is right
- The proposed framework dynamically balances multiple objectives without manual coefficient tuning.
- XLM-R with the approach outperforms baseline training on the new dataset.
- Few-shot prompting with Llama-3.1-8B provides an alternative at lower performance of 58.43% F1.
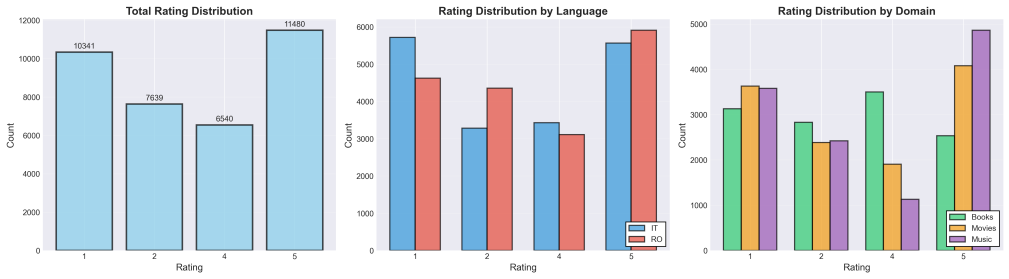
- The dataset covers three domains and two languages to test invariance.
Where Pith is reading between the lines
- If the meta-learning balances invariance well, similar techniques could apply to other multi-objective NLP tasks like translation or classification across many languages.
- With 202,141 unlabeled samples, the dataset could support semi-supervised methods beyond the supervised results shown.
- The performance difference suggests that task-specific fine-tuning remains superior for accuracy in this setting compared to prompting.
Load-bearing premise
The meta-learned coefficients successfully balance sentiment discrimination against domain and language invariance on held-out data without instability or overfitting to the particular training distribution.
What would settle it
A test where the model is evaluated on entirely new domains or languages not seen during meta-learning, checking if the F1 improvement holds or if training becomes unstable due to the coefficients.
Figures





read the original abstract
We present RoIt-XMASA, a multilingual dataset that extends the Cross-lingual Multi-domain Amazon Sentiment Analysis to Italian and Romanian, comprising 36,000 labeled reviews across three domains (books, movies, and music) and 202,141 unlabeled samples. To address cross-lingual and cross-domain challenges, we propose a multi-target adversarial training framework that employs loss reversal with meta-learned coefficients to dynamically balance sentiment discrimination with domain and language invariance. XLM-R achieves an F1-score of 66.23% with our approach, outperforming the baseline by 4.64%. Few-shot evaluation shows that Llama-3.1-8B achieves 58.43% F1-score, revealing a meaningful trade-off between the efficiency of prompting-based approaches and the higher performance of task-specific fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RoIt-XMASA, a multilingual multi-domain sentiment analysis dataset extending prior cross-lingual Amazon review resources to Italian and Romanian. It contains 36,000 labeled reviews across books, movies, and music plus 202,141 unlabeled samples. The authors propose a multi-target adversarial training framework that applies loss reversal with meta-learned coefficients to balance sentiment discrimination against domain and language invariance. They report that XLM-R fine-tuned under this framework reaches 66.23% F1, outperforming a baseline by 4.64 points, while few-shot prompting with Llama-3.1-8B achieves 58.43% F1.
Significance. If the meta-optimization procedure is shown to generalize via proper held-out validation, the dataset would constitute a useful public resource for cross-lingual and cross-domain sentiment analysis, and the framework would demonstrate a concrete method for trading off multiple invariance objectives. The explicit efficiency-performance comparison between fine-tuning and prompting is also of practical value. The contribution is primarily empirical and resource-oriented rather than theoretical.
major comments (2)
- [§4] §4 (Proposed Framework): The description of the meta-optimization loop for the loss-reversal coefficients does not specify whether a separate meta-validation set is maintained that respects the three-domain / two-language partition. Without such separation, the reported 4.64-point gain over baseline cannot be confidently attributed to stable trade-offs rather than memorization of the training distribution.
- [§5] §5 (Experiments) and associated result tables: The headline XLM-R F1 of 66.23% and the baseline comparison are presented without error bars, statistical significance tests, explicit data-split definitions, or baseline implementation details. These omissions make the central performance claim impossible to verify or reproduce from the reported information.
minor comments (2)
- [Abstract] Abstract: The phrase 'with our approach' is used without a one-sentence characterization of the meta-learned loss-reversal mechanism, which would improve readability for a broad audience.
- [§3] Dataset description: The split between labeled and unlabeled portions across languages and domains is stated in aggregate; a per-language/domain breakdown table would clarify coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of clarity and reproducibility. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [§4] §4 (Proposed Framework): The description of the meta-optimization loop for the loss-reversal coefficients does not specify whether a separate meta-validation set is maintained that respects the three-domain / two-language partition. Without such separation, the reported 4.64-point gain over baseline cannot be confidently attributed to stable trade-offs rather than memorization of the training distribution.
Authors: We agree that §4 does not explicitly describe the meta-validation procedure. In the revised manuscript we will expand this section to state that a held-out meta-validation set was maintained throughout meta-optimization, constructed by reserving entire domain-language combinations (one domain per language) so that the three-domain / two-language structure is preserved. This separation ensures the learned coefficients reflect stable trade-offs rather than training-distribution memorization, directly addressing the concern about attribution of the 4.64-point improvement. revision: yes
-
Referee: [§5] §5 (Experiments) and associated result tables: The headline XLM-R F1 of 66.23% and the baseline comparison are presented without error bars, statistical significance tests, explicit data-split definitions, or baseline implementation details. These omissions make the central performance claim impossible to verify or reproduce from the reported information.
Authors: We acknowledge these omissions limit verifiability. In the revised version we will (i) report mean and standard deviation F1 scores over five random seeds, (ii) add paired statistical significance tests against the baseline, (iii) provide explicit train/validation/test split definitions that document the domain-language partitioning, and (iv) include additional baseline implementation details (hyperparameters, optimizer settings, and a pointer to the released code). These additions will make the central claims reproducible. revision: yes
Circularity Check
No significant circularity; empirical results on new dataset are independent of inputs
full rationale
The paper creates a new labeled dataset (RoIt-XMASA) and reports XLM-R F1 of 66.23% under a proposed multi-target adversarial framework using meta-learned loss coefficients. This is a standard empirical evaluation against a stated baseline on held-out reviews; the performance number is not shown to reduce by construction to any fitted parameter, self-citation, or renamed input. No equations, uniqueness theorems, or ansatzes are invoked that collapse the central claim into the training distribution itself. The meta-learning step is an explicit component of the method rather than a hidden tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- meta-learned coefficients
axioms (1)
- domain assumption Adversarial training with loss reversal can produce representations that are invariant to language and domain while remaining discriminative for sentiment.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 31st annual ACM symposium on applied computing, 1140–1145
An evaluation of machine translation for multilingual sentence-level sentiment analysis. InProceedings of the 31st annual ACM symposium on applied computing, 1140–1145. Augustyniak, L.; Wo´zniak, S.; Gruza, M.; Gramacki, P.; Ra- jda, K.; Morzy, M.; and Kajdanowicz, T. 2023. Massively multilingual corpus of sentiment datasets and multi-faceted sentiment cl...
-
[2]
UDAPDR: unsupervised domain adaptation via LLM prompting and distillation of rerankers. InProceedings of the 2023 conference on empirical methods in natural lan- guage processing, 11265–11279. Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. At- tention is all you need.Advances in neural in...
work page 2023
-
[3]
For most authors... (a) Would answering this research question advance sci- ence without violating social contracts, such as violat- ing privacy norms, perpetuating unfair profiling, exac- erbating the socio-economic divide, or implying disre- spect to societies or cultures? Yes, this work introduces a multilingual dataset to improve sentiment analy- sis ...
-
[4]
Additionally, if your study involves hypotheses testing... (a) Did you clearly state the assumptions underlying all theoretical results? N/A (b) Have you provided justifications for all theoretical re- sults? N/A (c) Did you discuss competing hypotheses or theories that might challenge or complement your theoretical re- sults? N/A (d) Have you considered ...
-
[5]
Additionally, if you are including theoretical proofs... (a) Did you state the full set of assumptions of all theoret- ical results? N/A (b) Did you include complete proofs of all theoretical re- sults? N/A
-
[6]
Additionally, if you ran machine learning experiments... (a) Did you include the code, data, and instructions needed to reproduce the main experimental results (ei- ther in the supplemental material or as a URL)? Yes, the dataset is released on HuggingFace (see Footnote 1). (b) Did you specify all the training details (e.g., data splits, hyperparameters, ...
-
[7]
Additionally, if you are using existing assets (e.g., code, data, models) or curating/releasing new assets,without compromising anonymity... (a) If your work uses existing assets, did you cite the cre- ators? Yes, we cite the original XMASA dataset cre- ators and the developers of models like XLM-R and Llama-3.1. (b) Did you mention the license of the ass...
-
[8]
Additionally, if you used crowdsourcing or conducted research with human subjects,without compromising anonymity... (a) Did you include the full text of instructions given to participants and screenshots? N/A (b) Did you describe any potential participant risks, with mentions of Institutional Review Board (IRB) ap- provals? N/A (c) Did you include the est...
work page 2007
-
[9]
This includes ellipses (”......”→”...”) and mixed punctuation patterns
while preserving essential, semantic, and syntactic in- formation for sentiment analysis: 1.Punctuation normalization: Multiple consecutive punctuation marks were reduced to a maximum of three instances (e.g., ”!!!!!”→”!!!”), preserving emphasis while preventing excessive repetition. This includes ellipses (”......”→”...”) and mixed punctuation patterns. ...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.