Active Learning Solution on Distributed Edge Computing
Pith reviewed 2026-05-25 15:46 UTC · model grok-4.3
The pith
Active learning on edge devices plus federated learning on fog nodes reduces the samples and communication needed to train image classifiers in distributed setups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By decomposing data aggregation and processing between edge devices and fog nodes, active learning at the edges selects fewer samples and federated learning at the fog node aggregates models without centralizing raw data, thereby lowering both training sample count and communication cost for image classification in the two distribution regimes.
What carries the argument
Intelligent division of active learning (edge) and federated learning (fog) that performs sample selection locally and model aggregation centrally.
If this is right
- Fewer raw data samples need to be stored or transmitted from edge devices.
- Communication volume between edges and fog decreases because only model updates or selected samples move.
- Local processing at edges supports privacy by limiting data sharing.
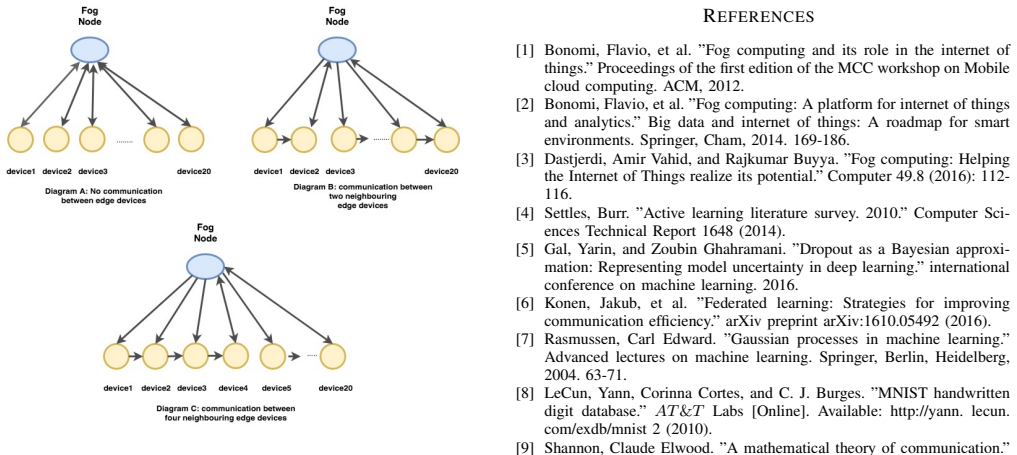
- Separate solutions are offered for massively distributed versus non-massively distributed device populations.
Where Pith is reading between the lines
- The method may extend to other supervised tasks if active learning query strategies remain effective on edge hardware.
- Energy use on battery-powered edges could drop if fewer samples are processed locally.
- Deployment would still require verifying that the fog node can handle the federated aggregation load without becoming a bottleneck.
Load-bearing premise
The split of tasks between edges and fog nodes can be arranged so that accuracy stays acceptable and no new overheads erase the claimed reductions in samples and communication.
What would settle it
A direct comparison on the same image classification task showing that the active-plus-federated method requires at least as many samples or as much communication as a baseline centralized or non-active approach while matching accuracy.
Figures









read the original abstract
Industry 4.0 becomes possible through the convergence between Operational and Information Technologies. All the requirements to realize the convergence is integrated on the Fog Platform. Fog Platform is introduced between the cloud server and edge devices when the unprecedented generation of data causes the burden of the cloud server, leading the ineligible latency. In this new paradigm, we divide the computation tasks and push it down to edge devices. Furthermore, local computing (at edge side) may improve privacy and trust. To address these problems, we present a new method, in which we decompose the data aggregation and processing, by dividing them between edge devices and fog nodes intelligently. We apply active learning on edge devices; and federated learning on the fog node which significantly reduces the data samples to train the model as well as the communication cost. To show the effectiveness of the proposed method, we implemented and evaluated its performance for an image classification task. In addition, we consider two settings: massively distributed and non-massively distributed and offer the corresponding solutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hybrid active learning and federated learning approach for distributed edge computing in Industry 4.0 settings. Active learning is performed on edge devices to select informative samples, while federated learning aggregates models at fog nodes. This is claimed to reduce the number of training samples and communication costs. The method is evaluated on an image classification task under both massively distributed and non-massively distributed settings.
Significance. If the reported experimental reductions in samples and communication hold with maintained accuracy, the work could provide a practical technique for lowering overhead in fog-edge deployments while preserving privacy. The explicit handling of two distribution regimes is a useful contribution, and the presence of concrete accuracy and communication metrics in the experimental section strengthens the central claim.
minor comments (2)
- The abstract asserts significant reductions in data samples and communication cost but provides no quantitative results, baselines, or error bars; adding a sentence with key metrics would better support the claim.
- The description of how the two settings (massively vs. non-massively distributed) are implemented could be expanded with more detail on data partitioning and model update frequency to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The acknowledgment of the practical value for fog-edge deployments and the explicit treatment of the two distribution regimes is appreciated. No specific major comments were provided in the report.
Circularity Check
No significant circularity; empirical evaluation stands alone
full rationale
The manuscript describes an empirical architecture that applies active learning at edge devices and federated learning at the fog node, then reports concrete accuracy and communication metrics on an image-classification task under massively and non-massively distributed regimes. No equations, parameter-fitting steps, uniqueness theorems, or self-citations appear in the provided text that would allow any claimed result to reduce to its own inputs by construction. The central claims are therefore supported by external experimental outcomes rather than definitional or self-referential loops.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bonomi, Flavio, et al. ”Fog computing and its role in the internet of things.” Proceedings of the first edition of the MCC workshop on Mobile cloud computing. ACM, 2012
work page 2012
-
[2]
Bonomi, Flavio, et al. ”Fog computing: A platform for internet of things and analytics.” Big data and internet of things: A roadmap for smart environments. Springer, Cham, 2014. 169-186
work page 2014
-
[3]
Dastjerdi, Amir Vahid, and Rajkumar Buyya. ”Fog computing: Helping the Internet of Things realize its potential.” Computer 49.8 (2016): 112- 116
work page 2016
-
[4]
”Active learning literature survey
Settles, Burr. ”Active learning literature survey. 2010.” Computer Sci- ences Technical Report 1648 (2014)
work page 2010
-
[5]
Gal, Yarin, and Zoubin Ghahramani. ”Dropout as a Bayesian approxi- mation: Representing model uncertainty in deep learning.” international conference on machine learning. 2016
work page 2016
-
[6]
Federated Learning: Strategies for Improving Communication Efficiency
Konen, Jakub, et al. ”Federated learning: Strategies for improving communication efficiency.” arXiv preprint arXiv:1610.05492 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
”Gaussian processes in machine learning.” Advanced lectures on machine learning
Rasmussen, Carl Edward. ”Gaussian processes in machine learning.” Advanced lectures on machine learning. Springer, Berlin, Heidelberg,
-
[8]
LeCun, Yann, Corinna Cortes, and C. J. Burges. ”MNIST handwritten digit database.” AT &T Labs [Online]. Available: http://yann. lecun. com/exdb/mnist 2 (2010)
work page 2010
-
[9]
”A mathematical theory of communication.” Bell system technical journal 27.3 (1948): 379-423
Shannon, Claude Elwood. ”A mathematical theory of communication.” Bell system technical journal 27.3 (1948): 379-423
work page 1948
-
[10]
Tong, Simon, and Daphne Koller. ”Support vector machine active learning with applications to text classification.” Journal of machine learning research 2.Nov (2001): 45-66
work page 2001
-
[11]
Bayesian Active Learning for Classification and Preference Learning
Houlsby, Neil, et al. ”Bayesian active learning for classification and preference learning.” arXiv preprint arXiv:1112.5745 (2011)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[12]
Elementary applied statistics: for students in behav- ioral science
Freeman, Linton C. Elementary applied statistics: for students in behav- ioral science. John Wiley and Sons, 1965
work page 1965
-
[13]
Deep Bayesian Active Learning with Image Data
Gal, Yarin, Riashat Islam, and Zoubin Ghahramani. ”Deep bayesian active learning with image data.” arXiv preprint arXiv:1703.02910 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Tong, S. and Chang, E., 2001, October. Support vector machine active learning for image retrieval. In Proceedings of the ninth ACM interna- tional conference on Multimedia (pp. 107-118). ACM
work page 2001
-
[15]
Diro, A.A. and Chilamkurti, N., 2018. Distributed attack detection scheme using deep learning approach for Internet of Things. Future Generation Computer Systems, 82, pp.761-768
work page 2018
-
[16]
Thompson, Cynthia A., Mary Elaine Califf, and Raymond J. Mooney. ”Active learning for natural language parsing and information extrac- tion.” ICML. 1999
work page 1999
-
[17]
Osugi, Thomas, Deng Kim, and Stephen Scott. ”Balancing exploration and exploitation: A new algorithm for active machine learning.” Data Mining, Fifth IEEE International Conference on. IEEE, 2005
work page 2005
-
[18]
Lakshminarayanan, B., Pritzel, A. and Blundell, C., 2017. Simple and scalable predictive uncertainty estimation using deep ensembles. In Advances in Neural Information Processing Systems (pp. 6402-6413)
work page 2017
-
[19]
Osband, I., Blundell, C., Pritzel, A. and Van Roy, B., 2016. Deep exploration via bootstrapped DQN. In Advances in neural information processing systems (pp. 4026-4034)
work page 2016
-
[20]
and Ghahramani, Z., 2016, June
Gal, Y . and Ghahramani, Z., 2016, June. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning (pp. 1050-1059)
work page 2016
-
[21]
LeCun, Y ., Haffner, P., Bottou, L. and Bengio, Y ., 1999. Object recog- nition with gradient-based learning. In Shape, contour and grouping in computer vision (pp. 319-345). Springer, Berlin, Heidelberg
work page 1999
-
[22]
Differential privacy: A survey of results
Dwork, C., 2008, April. Differential privacy: A survey of results. In International Conference on Theory and Applications of Models of Computation (pp. 1-19). Springer, Berlin, Heidelberg
work page 2008
-
[23]
Bayesian Convolutional Neural Networks with Bernoulli Approximate Variational Inference
Tang, B., Chen, Z., Hefferman, G., Wei, T., He, H. and Yang, Q., 2015, October. A hierarchical distributed fog computing architecture for big data analysis in smart cities. In Proceedings of the ASE BigData and SocialInformatics 2015 (p. 28). ACM.reprint arXiv:1506.02158
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
Federated Optimization: Distributed Machine Learning for On-Device Intelligence
Konecn, J., McMahan, H.B., Ramage, D. and Richtrik, P., 2016. Federated optimization: Distributed machine learning for on-device intelligence. arXiv preprint arXiv:1610.02527
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[25]
Hong, D. and Si, L., 2012, August. Mixture model with multiple centralized retrieval algorithms for result merging in federated search. In Proceedings of the 35th international ACM SIGIR conference on Research and development in information retrieval (pp. 821-830). ACM
work page 2012
-
[26]
Blei, D.M., Kucukelbir, A. and McAuliffe, J.D., 2017. Variational inference: A review for statisticians. Journal of the American Statistical Association, 112(518), pp.859-877
work page 2017
-
[27]
Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., Lin, Z., Desmaison, A., Antiga, L. and Lerer, A., 2017. Automatic differentiation in pytorch
work page 2017
-
[28]
LeCun, Y ., Bottou, L., Bengio, Y . and Haffner, P., 1998. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), pp.2278-2324
work page 1998
-
[29]
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I. and Salakhutdi- nov, R., 2014. Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1), pp.1929- 1958
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.