SalsaAgent: A multimodal embodied language model for interactive dance generation
Pith reviewed 2026-06-29 08:47 UTC · model grok-4.3
The pith
A language model generates full-body salsa dance motions that react to a human leader and music.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
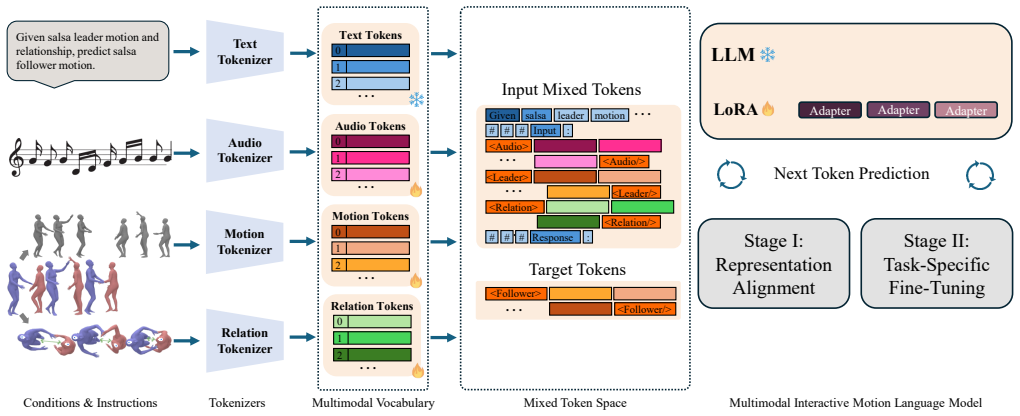
SalsaAgent formulates interaction as nonverbal motion token passing by extending an LLM vocabulary to include discrete motion tokens, pairwise relation tokens, and audio, then applies LLM fine-tuning on automatically derived text descriptions of skeleton dynamics followed by a two-stage token-to-diffusion pipeline to produce expressive, full-body salsa dance that reacts to a leader and music.
What carries the argument
Nonverbal motion token passing that extends the LLM to process motion tokens and pairwise relation tokens for generating coordinated two-person dance.
If this is right
- The generated motions exhibit consistent two-person spatial behavior across sequences.
- Coordination with both music and partner improves significantly compared with prior methods.
- The same token-passing structure supports bidirectional nonverbal reactivity suitable for robots or virtual agents.
- Full-body motion quality rises when the LLM processes the combined motion, relation, and audio tokens.
Where Pith is reading between the lines
- The token vocabulary could be reused for other partnered physical tasks such as object passing or collaborative assembly.
- Adding real-time sensor feedback loops might allow the model to adjust dance on the fly during live performance.
- Scaling the approach to larger groups would require new relation tokens that track multiple simultaneous partners.
Load-bearing premise
Automatically derived text descriptions of skeleton dynamics give enough grounding for the added motion and relation tokens to yield coherent interactive dance.
What would settle it
An experiment in which human raters score the generated dances on partner coordination and spatial consistency and find no measurable gain over the baselines would falsify the effectiveness claim.
Figures
read the original abstract
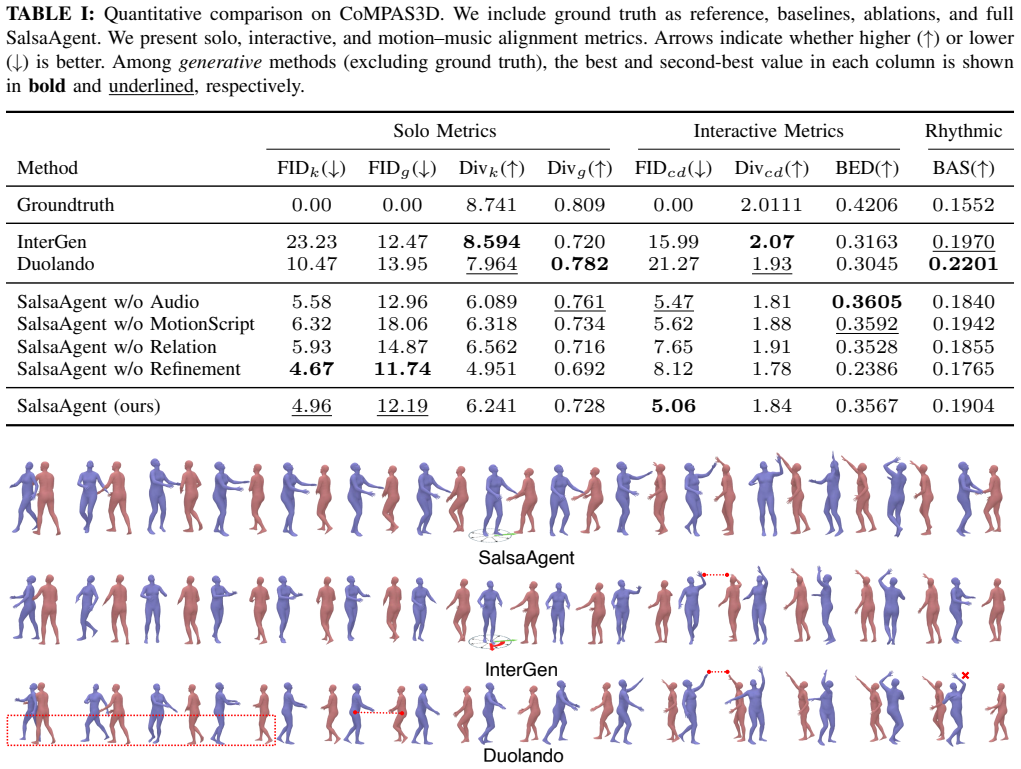
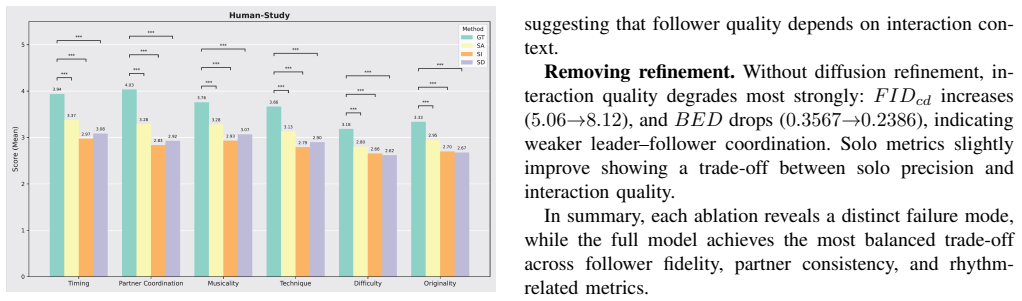
Interaction between humanoids involves bidirectional and nonverbal reactivity, coordination and synchrony. Toward socially aware robots and interactive virtual agents, we present SalsaAgent, a language model that generates expressive, full-body salsa dance motions in reaction to a human leader and against a contextual music backdrop. We formulate interaction as nonverbal motion token passing, extending the vocabulary of a large language model (LLM) to process discrete motion tokens, pairwise relation tokens, and audio. Our contributions include new tokens for full-body and motion relations, LLM fine-tuning using automatically derived text descriptions of skeleton dynamics for token grounding, and a two-stage token-to-diffusion pipeline. Subjective and objective evaluations demonstrate the effectiveness of our approach in terms of motion quality, music and partner coordination, and consistent two-person spatial behavior, with significant improvements over baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SalsaAgent, a multimodal embodied language model for generating expressive full-body salsa dance motions in reaction to a human leader and music backdrop. Interaction is formulated as nonverbal motion token passing by extending an LLM vocabulary to include discrete motion tokens, pairwise relation tokens, and audio. Contributions include new tokens for full-body and motion relations, LLM fine-tuning with automatically derived text descriptions of skeleton dynamics for token grounding, and a two-stage token-to-diffusion pipeline. Subjective and objective evaluations are reported to demonstrate effectiveness in motion quality, music and partner coordination, and consistent two-person spatial behavior, with significant improvements over baselines.
Significance. If the evaluations hold with proper quantitative support, the work could advance embodied AI for socially aware robots by showing how LLMs can handle bidirectional nonverbal reactivity in dance. The token extension and grounding via text descriptions of dynamics represent a potentially useful direction for interactive motion generation, though the assumption that such descriptions suffice for coherent two-person behavior requires verification through the reported results.
major comments (1)
- [Abstract] Abstract: the claim that 'subjective and objective evaluations demonstrate the effectiveness of our approach ... with significant improvements over baselines' supplies no quantitative results, baseline descriptions, or data details, so the support for the central claim cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'subjective and objective evaluations demonstrate the effectiveness of our approach ... with significant improvements over baselines' supplies no quantitative results, baseline descriptions, or data details, so the support for the central claim cannot be assessed.
Authors: We agree that the abstract would be strengthened by including explicit quantitative support for the central claim. The full manuscript reports detailed objective metrics (e.g., motion quality, coordination scores) and subjective user-study results with statistical significance against named baselines in Sections 4 and 5, but these are not summarized in the abstract. In the revised manuscript we will update the abstract to include one or two key quantitative highlights (e.g., percentage improvements and baseline names) while remaining within length limits. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an applied ML system for generating interactive dance motions via LLM token extensions, fine-tuning on skeleton-derived text, and a token-to-diffusion pipeline. No equations, first-principles derivations, or predictions are claimed that could reduce to inputs by construction. Contributions are empirical model-building steps (vocabulary extension, fine-tuning, evaluation) with no self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that collapse the central claim. The abstract and context contain no mathematical structure amenable to the enumerated circularity patterns, making this a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bartneck et al.Human-robot interaction: An introduction
C. Bartneck et al.Human-robot interaction: An introduction. Cam- bridge University Press, 2024
2024
-
[2]
J. L. Hanna.To dance is human: A theory of nonverbal communication. University of Chicago Press, 1987
1987
-
[3]
K. E. Raheb et al. Dance interactive learning systems: A study on interaction workflow and teaching approaches.ACM Comput. Surv., 2019
2019
-
[4]
J. McMains. Salsa steps toward intercultural education.J. Dance Educ., 2016
2016
-
[5]
Siyao et al
L. Siyao et al. Duolando: Follower gpt with off-policy reinforcement learning for dance accompaniment. InICLR, 2024
2024
-
[6]
Liang et al
H. Liang et al. InterGen: Diffusion-based multi-human motion generation under complex interactions.IJCV, 2024
2024
-
[7]
Li et al
R. Li et al. Interdance: Reactive 3d dance generation with realistic duet interactions. InICLR, 2025
2025
-
[8]
Jiang et al
B. Jiang et al. MotionGPT: Human motion as a foreign language. NeurIPS, 2023
2023
-
[9]
Yu et al
H. Yu et al. SocialGen: Modeling multi-human social interaction with language models. In3DV, 2026
2026
-
[10]
Burkanova et al
B. Burkanova et al. CoMPAS3D: A dataset and benchmark for interactive motion.arXiv, 2025
2025
-
[11]
P. J. Yazdian et al. MotionScript: Natural language descriptions for expressive 3D human motions. InIROS, 2025
2025
-
[12]
Zhang et al
C. Zhang et al. React to this! how humans challenge interactive agents using nonverbal behaviors. InIROS. IEEE, 2024
2024
-
[13]
Guo et al
C. Guo et al. Generating diverse and natural 3D human motions from text. InCVPR, June 2022
2022
-
[14]
Zhang et al
J. Zhang et al. T2M-GPT: Generating human motion from textual descriptions with discrete representations. InCVPR, 2023
2023
-
[15]
Dabral et al
R. Dabral et al. MoFusion: A framework for denoising-diffusion-based motion synthesis. InCVPR, 2023
2023
-
[16]
Zhou and B
Z. Zhou and B. Wang. UDE: A unified driving engine for human motion generation. InCVPR, 2023
2023
-
[17]
Siyao et al
L. Siyao et al. Bailando: 3d dance generation by actor-critic gpt with choreographic memory. InCVPR, 2022
2022
-
[18]
Tseng et al
J. Tseng et al. EDGE: Editable dance generation from music. In CVPR, 2023
2023
-
[19]
Le et al
N. Le et al. Music-driven group choreography. InCVPR, 2023
2023
-
[20]
Le et al
N. Le et al. Controllable group choreography using contrastive diffusion.TOG, 2023
2023
-
[21]
Petrovich et al
M. Petrovich et al. Action-conditioned 3D human motion synthesis with transformer V AE. InICCV, 2021
2021
-
[22]
Guo et al
C. Guo et al. Action2Motion: Conditioned generation of 3D human motions. InACM MM, 2020
2020
-
[23]
Tevet et al
G. Tevet et al. Human motion diffusion model. InICLR, 2023
2023
-
[24]
Shafir et al
Y . Shafir et al. Human motion diffusion as a generative prior. InICLR, 2024
2024
-
[25]
A. Q. Nichol and P. Dhariwal. Improved denoising diffusion proba- bilistic models. InICML. PMLR, 2021
2021
-
[26]
van den Oord et al
A. van den Oord et al. Neural discrete representation learning. NeurIPS, 2017
2017
-
[27]
Guo et al
C. Guo et al. MoMask: Generative masked modeling of 3D human motions. InCVPR, 2024
2024
-
[28]
Sui et al
K. Sui et al. A survey on human interaction motion generation.IJCV, 2026
2026
-
[29]
Liu et al
Y . Liu et al. Interactive humanoid: Online full-body motion reaction synthesis with social affordance canonicalization and forecasting. In 3DV, 2025
2025
-
[30]
Ghosh et al
A. Ghosh et al. ReMoS: 3D motion-conditioned reaction synthesis for two-person interactions. InECCV. Springer, 2024
2024
-
[31]
Xu et al
L. Xu et al. ReGenNet: Towards human action-reaction synthesis. In CVPR, 2024
2024
-
[32]
M. G. Javed et al. InterMask: 3D human interaction generation via collaborative masked modelling. InICLR, 2025
2025
-
[33]
Fan et al
K. Fan et al. FreeMotion: A unified framework for number-free text- to-motion synthesis. InECCV. Springer, 2024
2024
-
[34]
Touvron et al
H. Touvron et al. LLaMA: Open and efficient foundation language models.arXiv, 2023
2023
-
[35]
W. L. Chiang et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. https://lmsys.org/blog/2023-03-30-vicuna/,
2023
-
[36]
Accessed: 2025-05-06
2025
-
[37]
Team et al
G. Team et al. Gemma 2: Improving open language models at a practical size.arXiv, 2024
2024
-
[38]
Brown et al
T. Brown et al. Language models are few-shot learners.NeurIPS, 2020
2020
-
[39]
Girdhar et al
R. Girdhar et al. ImageBind: One embedding space to bind them all. InCVPR, 2023
2023
-
[40]
Li et al
J. Li et al. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InICML, 2022
2022
-
[41]
Zhang et al
H. Zhang et al. Video-LLaMA: An instruction-tuned audio-visual language model for video understanding. InEMNLP Demo, 2023
2023
-
[42]
Wan: Open and advanced large-scale video generative models.arXiv, 2025
Wan Team. Wan: Open and advanced large-scale video generative models.arXiv, 2025
2025
-
[43]
Deshmukh et al
S. Deshmukh et al. Pengi: An audio language model for audio tasks. InNeurIPS, 2023
2023
-
[44]
Deng et al
Z. Deng et al. Musilingo: Bridging music and text with pre-trained language models for music captioning and query response. InNAACL Findings, 2024
2024
-
[45]
Han et al
J. Han et al. OneLLM: One framework to align all modalities with language. InCVPR, 2024
2024
-
[46]
Wu et al
S. Wu et al. NExT-GPT: Any-to-any multimodal LLM. InICML, 2024
2024
-
[47]
Zhang et al
Y . Zhang et al. MotionGPT: Finetuned LLMs are general-purpose motion generators. InAAAI, 2024
2024
-
[48]
Wu et al
Q. Wu et al. Motion-Agent: A conversational framework for human motion generation with LLMs. InICLR, 2025
2025
-
[49]
Luo et al
M. Luo et al. M 3GPT: An advanced multimodal, multitask framework for motion comprehension and generation. InNeurIPS, 2024
2024
-
[50]
Zhang et al
M. Zhang et al. FineMoGen: Fine-grained spatio-temporal motion generation and editing. InNeurIPS, 2023
2023
-
[51]
Zhang et al
Z. Zhang et al. Social agent: Mastering dyadic nonverbal behavior generation via conversational llm agents. InSIGGRAPH Asia, 2025
2025
-
[52]
Jiang et al
J. Jiang et al. Solami: Social vision-language-action modeling for immersive interaction with 3d autonomous characters. InCVPR, 2025
2025
-
[53]
Plappert et al
M. Plappert et al. The KIT motion-language dataset.Big Data, 2016
2016
-
[54]
Xu et al
L. Xu et al. Inter-x: Towards versatile human-human interaction analysis. InCVPR, 2024
2024
-
[55]
Li et al
R. Li et al. Ai choreographer: Music conditioned 3d dance generation with AIST++. InICCV, 2021
2021
-
[56]
Li et al
R. Li et al. Finedance: A fine-grained choreography dataset for 3d full body dance generation. InICCV, 2023
2023
-
[57]
P. J. Yazdian et al. Gesture2vec: Clustering gestures using represen- tation learning methods for co-speech gesture generation. InIROS. IEEE, 2022
2022
-
[58]
Razavi et al
A. Razavi et al. Generating diverse high-fidelity images with VQ- V AE-2. InNeurIPS, 2019
2019
-
[59]
Ji et al
S. Ji et al. Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling. InICLR, 2025
2025
-
[60]
E. J. Hu et al. Lora: Low-rank adaptation of large language models. InICLR, 2022
2022
-
[61]
Heusel et al
M. Heusel et al. Gans trained by a two time-scale update rule converge to a local nash equilibrium.NeurIPS, 2017
2017
-
[62]
Onuma et al
K. Onuma et al. FMDistance: A fast and effective distance function for motion capture data. InEurographics, 2008
2008
-
[63]
M ¨uller et al
M. M ¨uller et al. Efficient content-based retrieval of motion capture data. InSCA. 2005
2005
-
[64]
Rules, definitions and judging criteria 2024
Canada Salsa and Bachata Congress. Rules, definitions and judging criteria 2024. https://www.canadasalsacongress.com/rules, 2024. Accessed: 2025-05-06
2024
-
[65]
Radford et al
A. Radford et al. Learning transferable visual models from natural language supervision. InICML, 2021
2021
-
[66]
Song et al
J. Song et al. Denoising diffusion implicit models. InICLR, 2021
2021
-
[67]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InICLR, 2019
2019
-
[68]
M. F. Naeem et al. Reliable fidelity and diversity metrics for generative models. InICML. PMLR, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.