JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
Pith reviewed 2026-06-27 00:40 UTC · model grok-4.3
The pith
JetSpec trains a causal parallel draft head on fused target hidden states to generate branch-conditioned trees whose scores match the target LLM's autoregressive factorization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
JetSpec is a head-based speculative decoding framework that trains a causal parallel draft head over fused hidden states from the frozen target model, producing candidate trees whose scores align with the target model's autoregressive factorization. This alignment lets larger draft budgets become longer accepted sequences and higher end-to-end speedups, outperforming both bidirectional-head and tree-based baselines on math, coding, and chat benchmarks across dense and MoE Qwen3 models.
What carries the argument
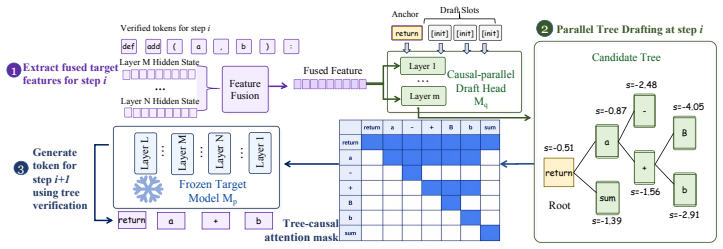
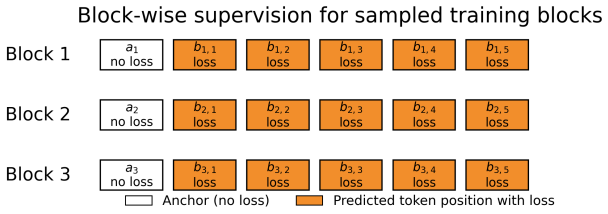
The causal parallel draft head trained over fused hidden states from the frozen target model, which produces branch-wise causally conditioned candidate trees in one forward pass.
If this is right
- Larger draft budgets translate into longer accepted prefixes rather than wasted verification steps.
- The same frozen target model can be paired with the draft head on both dense and MoE architectures without retraining the base weights.
- End-to-end latency improves on H100 GPUs for both short math problems and longer conversational sequences.
- Integration with production serving engines such as vLLM further reduces latency under realistic multi-request loads.
Where Pith is reading between the lines
- The same fusion-and-causal-head pattern could be tested on sequence models outside language, such as time-series or protein generators.
- If the alignment property holds at larger scales, the draft head might be reused across multiple target models of similar architecture.
- The method implies that explicit tree consistency can be restored without paying the full cost of sequential autoregressive drafting.
Load-bearing premise
The scores assigned by the draft head to its candidate trees will match the probabilities the frozen target model would compute under its own autoregressive factorization.
What would settle it
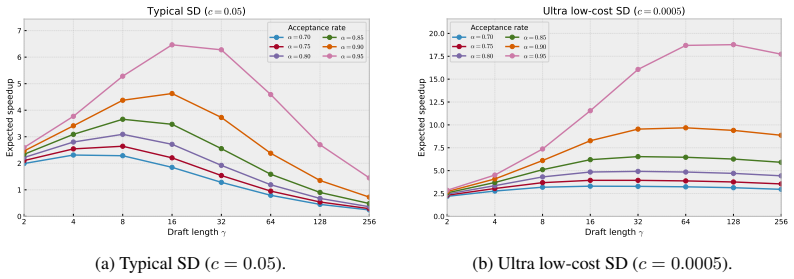
A controlled run in which acceptance length stops rising or falls as the draft budget is increased, or in which measured wall-clock latency fails to drop despite higher theoretical acceptance.
Figures


read the original abstract
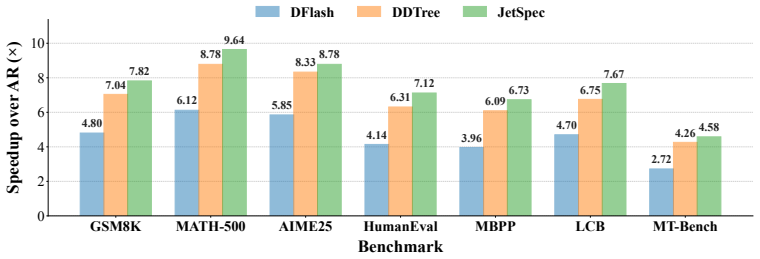
Speculative decoding (SD) accelerates autoregressive Large Language Models (LLMs) by drafting multiple tokens and verifying them in parallel, but it faces a scaling limitation: increasing the draft budget improves speed only when acceptance remains high and drafting overhead stays low. This ceiling has been difficult to break because prior head-based SD methods face a causality-efficiency dilemma. Autoregressive drafters produce path-conditioned candidates that are effective for tree speculative decoding with higher acceptance length, but their drafting cost grows with tree depth. Bidirectional block-diffusion drafters generate all positions in one pass, but their branch-agnostic marginals can form individually plausible yet mutually inconsistent trees, wasting budget and reducing acceptance. We propose JetSpec, a head-based SD framework that combines one-forward drafting efficiency with branch-wise causal conditioning. JetSpec trains a causal parallel draft head over fused hidden states from the frozen target model, producing candidate trees whose scores align with the target model's autoregressive factorization. This enables JetSpec to convert larger draft budgets into longer accepted prefixes and higher end-to-end speedup. Across math, coding, and chat benchmarks on dense and MoE Qwen3 models, JetSpec consistently outperforms bidirectional-head and tree-based SD baselines. On H100 GPUs, JetSpec achieves up to 9.64x speedup on MATH-500 and 4.58x on open-ended conversational workloads, with further latency gains demonstrated through vLLM integration under realistic serving loads. Our code and models are available at https://github.com/hao-ai-lab/JetSpec.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JetSpec, a speculative decoding framework that trains a single causal parallel draft head on fused hidden states from a frozen target LLM. This produces tree-structured candidate sequences whose per-token scores are intended to align with the target's autoregressive factorization, allowing larger draft budgets to translate into higher acceptance lengths without the inconsistency problems of bidirectional drafters or the depth-dependent cost of autoregressive drafters. Empirical results on Qwen3 dense and MoE models across math, coding, and chat benchmarks report consistent outperformance over bidirectional-head and tree-based baselines, with peak speedups of 9.64× on MATH-500 and 4.58× on conversational workloads on H100 GPUs, plus further gains when integrated with vLLM.
Significance. If the claimed alignment between the parallel draft head and the target factorization holds under verification and the reported speedups prove robust to implementation details, the work would meaningfully advance the scaling behavior of speculative decoding by removing a long-standing causality-efficiency trade-off. The open release of code and models strengthens the potential for follow-on work.
major comments (3)
- [Abstract, §3] Abstract and §3: The central claim that the trained causal parallel draft head 'produces candidate trees whose scores align with the target model's autoregressive factorization' is load-bearing for correct tree acceptance and the reported speedups, yet no loss term, auxiliary objective, or derivation is provided that enforces exact equivalence rather than approximate matching via standard training; any systematic mismatch would invalidate the verification step.
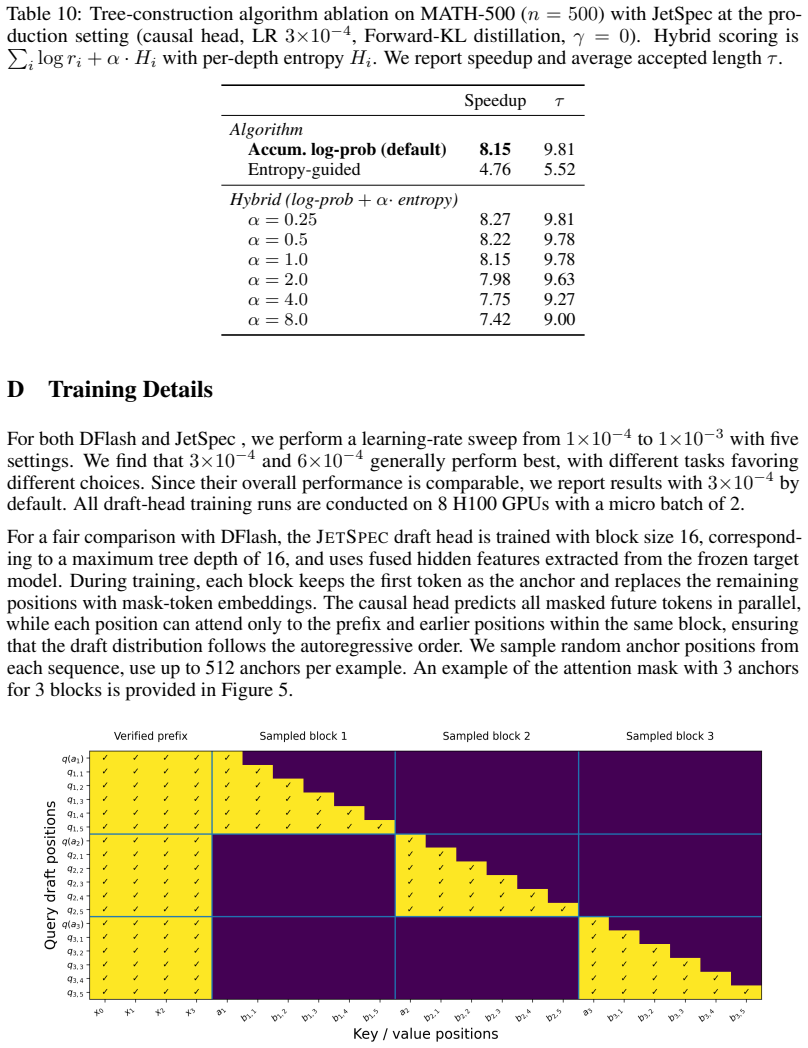
- [§4] §4 and experimental sections: The manuscript reports large speedups (e.g., 9.64× on MATH-500) but the provided text contains no error bars, statistical significance tests, or ablation studies isolating the contribution of the alignment property versus other implementation choices; without these, it is impossible to assess whether the scaling-ceiling claim is supported by the data.
- [§3.2] §3.2: The description of how fused hidden states are used to produce branch-wise causal conditioning does not include an explicit statement or proof that the resulting tree scores remain consistent with the target's left-to-right factorization when the draft tree contains multiple branches; this consistency is required to avoid the inconsistency problem the paper attributes to bidirectional methods.
minor comments (2)
- [§3] Notation for the draft head output (e.g., the precise definition of the per-position logits used for tree scoring) is introduced without a dedicated equation number, making cross-references in later sections difficult to follow.
- [Figure 2] Figure captions for the tree-construction diagrams do not explicitly label which nodes are accepted versus rejected under the verification procedure, reducing clarity when comparing acceptance lengths across methods.
Simulated Author's Rebuttal
Thank you for the thorough review and constructive suggestions. We will revise the manuscript to address the concerns regarding the theoretical justification of the alignment, the experimental rigor, and the consistency proof. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3: The central claim that the trained causal parallel draft head 'produces candidate trees whose scores align with the target model's autoregressive factorization' is load-bearing for correct tree acceptance and the reported speedups, yet no loss term, auxiliary objective, or derivation is provided that enforces exact equivalence rather than approximate matching via standard training; any systematic mismatch would invalidate the verification step.
Authors: We thank the referee for highlighting this important point. The alignment is intended to arise from the causal training of the draft head on fused hidden states, which conditions each branch on preceding tokens in a manner consistent with autoregressive factorization. However, we agree that the manuscript lacks an explicit derivation or specialized loss term to guarantee exact equivalence. In the revision, we will add a detailed explanation of the training objective and a proof sketch showing how the branch-consistent scores maintain consistency with the target's left-to-right probabilities. This will be incorporated as an addition to Section 3. revision: yes
-
Referee: [§4] §4 and experimental sections: The manuscript reports large speedups (e.g., 9.64× on MATH-500) but the provided text contains no error bars, statistical significance tests, or ablation studies isolating the contribution of the alignment property versus other implementation choices; without these, it is impossible to assess whether the scaling-ceiling claim is supported by the data.
Authors: We acknowledge the absence of error bars, significance tests, and targeted ablations in the current version. To address this, we will rerun the experiments with multiple random seeds to report means and standard deviations, include p-values for comparisons, and add ablations that disable the causal alignment mechanism to isolate its contribution. These will be added to Section 4 and the experimental results. revision: yes
-
Referee: [§3.2] §3.2: The description of how fused hidden states are used to produce branch-wise causal conditioning does not include an explicit statement or proof that the resulting tree scores remain consistent with the target's left-to-right factorization when the draft tree contains multiple branches; this consistency is required to avoid the inconsistency problem the paper attributes to bidirectional methods.
Authors: We agree that an explicit statement and proof of consistency for multi-branch trees would clarify the method. The branch-wise causal conditioning is designed such that each path in the tree is conditioned only on its own prefix, preserving the autoregressive property. We will revise Section 3.2 to include a formal statement and a short proof demonstrating that the joint probability of any path equals the product of conditional probabilities under the target model, thereby ensuring consistency across branches. revision: yes
Circularity Check
No circularity: empirical training method with external validation
full rationale
The paper presents JetSpec as a training-based method where a causal parallel draft head is trained on fused hidden states from a frozen target model to produce trees whose scores align with autoregressive factorization. No equations, derivations, or self-citations are shown that reduce any claimed prediction or result to its inputs by construction. Performance claims rest on benchmark comparisons rather than internal self-referential quantities. The alignment is described as an outcome of training rather than an enforced identity or fitted parameter renamed as prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The target model remains frozen while training the draft head on its hidden states.
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self- generated mistakes, 2024
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self- generated mistakes, 2024
2024
-
[2]
StepFun AI. Step 3.5 flash: Open frontier-level intelligence with 11b active parameters.arXiv preprint arXiv:2602.10604, 2026
arXiv 2026
-
[3]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc V . Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
Pith/arXiv arXiv 2021
-
[4]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads. arXiv preprint arXiv:2401.10774, 2024
Pith/arXiv arXiv 2024
-
[5]
Code Alpaca: An instruction-following LLaMA model trained on code generation instructions.https://github.com/sahil280114/codealpaca, 2023
Sahil Chaudhary. Code Alpaca: An instruction-following LLaMA model trained on code generation instructions.https://github.com/sahil280114/codealpaca, 2023
2023
-
[6]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023
Pith/arXiv arXiv 2023
-
[7]
Dflash: Block diffusion for flash speculative decoding.arXiv preprint arXiv:2602.06036, 2026
Jian Chen, Yesheng Liang, and Zhijian Liu. Dflash: Block diffusion for flash speculative decoding.arXiv preprint arXiv:2602.06036, 2026
Pith/arXiv arXiv 2026
-
[8]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
Pith/arXiv arXiv 2021
-
[9]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[10]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
DeepSeek-AI. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[11]
DeepSeek-AI. DeepSeek-V4: Towards highly efficient million-token context intelligence.arXiv preprint arXiv:2606.19348, 2026
arXiv 2026
-
[12]
Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?, 2025
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. Swe-bench pro: Can ai agents solve long-ho...
2025
-
[13]
LayerSkip: Enabling early exit inference and self-speculative decoding
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed Aly, Beidi Chen, and Carole-Jean Wu. LayerSkip: Enabling early exit inference and self-speculative decoding. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual M...
2024
-
[14]
Break the sequential dependency of LLM inference using lookahead decoding
Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Break the sequential dependency of LLM inference using lookahead decoding. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 14060–14079. PMLR, 2024
2024
-
[15]
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, and Gabriel Syn- naeve. Better & faster large language models via multi-token prediction.arXiv preprint arXiv:2404.19737, 2024
Pith/arXiv arXiv 2024
-
[16]
Raghavv Goel, Mukul Gagrani, Wonseok Jeon, Junyoung Park, Mingu Lee, and Christopher Lott. Direct alignment of draft model for speculative decoding with chat-fine-tuned llms.arXiv preprint arXiv:2403.00858, 2024
arXiv 2024
-
[17]
MiniLLM: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. InInternational Conference on Learning Representations, 2024
2024
-
[18]
Lee, and Di He
Zhenyu He, Zexuan Zhong, Tianle Cai, Jason D. Lee, and Di He. REST: Retrieval-based speculative decoding. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1582–1595, 2024
2024
-
[19]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InNeurIPS Datasets and Benchmarks, 2021
2021
-
[20]
Lanxiang Hu, Siqi Kou, Yichao Fu, Samyam Rajbhandari, Tajana Rosing, Yuxiong He, Zhijie Deng, and Hao Zhang. Fast and accurate causal parallel decoding using jacobi forcing.arXiv preprint arXiv:2512.14681, 2025
arXiv 2025
-
[21]
SAM decoding: Speculative decoding via suffix automaton
Yuxuan Hu, Ke Wang, Xiaokang Zhang, Fanjin Zhang, Cuiping Li, Hong Chen, and Jing Zhang. SAM decoding: Speculative decoding via suffix automaton. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 121...
2025
-
[22]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
Pith/arXiv arXiv 2024
-
[23]
CLLMs: Consistency large language models
Siqi Kou, Lanxiang Hu, Zhezhi He, Zhijie Deng, and Hao Zhang. CLLMs: Consistency large language models. InProceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[24]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 19274–19286. PMLR, 2023
2023
-
[25]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-2: Faster inference of language models with dynamic draft trees.arXiv preprint arXiv:2406.16858, 2024
arXiv 2024
-
[26]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty.arXiv preprint arXiv:2401.15077, 2024
Pith/arXiv arXiv 2024
-
[27]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-3: Scaling up inference acceleration of large language models via training-time test.arXiv preprint arXiv:2503.01840, 2025
Pith/arXiv arXiv 2025
-
[28]
Yihao Liang, Ze Wang, Hao Chen, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Emad Barsoum, Zicheng Liu, and Niraj K. Jha. CD4LM: Consistency distillation and adaptive decoding for diffusion language models.arXiv preprint arXiv:2601.02236, 2026
arXiv 2026
-
[29]
Online speculative decoding
Xiaoxuan Liu, Lanxiang Hu, Peter Bailis, Alvin Cheung, Zhijie Deng, Ion Stoica, and Hao Zhang. Online speculative decoding. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 31131–31146. PMLR, 2024. 12
2024
-
[30]
ToolSandbox: A stateful, conversational, interactive evaluation benchmark for LLM tool use capabilities
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, Zirui Wang, and Ruoming Pang. ToolSandbox: A stateful, conversational, interactive evaluation benchmark for LLM tool use capabilities. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational L...
2025
-
[31]
Specinfer: Accelerating generative large language model serving with tree-based speculative inference and verification
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. Specinfer: Accelerating generative large language model serving with tree-based speculative inference and verification. InProceedings of the...
2024
-
[32]
Nemotron post-training dataset v2
NVIDIA. Nemotron post-training dataset v2. https://huggingface.co/datasets/ nvidia/Nemotron-Post-Training-Dataset-v2, 2025. Dataset
2025
-
[33]
Gabriele Oliaro, Zhihao Jia, Daniel Campos, and Aurick Qiao. Suffixdecoding: Extreme speculative decoding for emerging ai applications.arXiv preprint arXiv:2411.04975, 2026
arXiv 2026
-
[34]
Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InF orty-second International Conference on Machine Learning, 2025
2025
-
[35]
Yu-Yang Qian, Junda Su, Lanxiang Hu, Peiyuan Zhang, Zhijie Deng, Peng Zhao, and Hao Zhang. d3LLM: Ultra-fast diffusion LLM using pseudo-trajectory distillation.arXiv preprint arXiv:2601.07568, 2026
arXiv 2026
-
[36]
Liran Ringel and Yaniv Romano. Accelerating speculative decoding with block diffusion draft trees.arXiv preprint arXiv:2604.12989, 2026
Pith/arXiv arXiv 2026
-
[37]
Prompt lookup decoding
Apoorv Saxena. Prompt lookup decoding. https://github.com/apoorvumang/ prompt-lookup-decoding, 2023. GitHub repository
2023
-
[38]
Shwetha Somasundaram, Anirudh Phukan, and Apoorv Saxena. Pld+: Accelerating llm inference by leveraging language model artifacts.arXiv preprint arXiv:2412.01447, 2024
arXiv 2024
-
[39]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Associates, Inc., 2022
2022
-
[40]
Fast-dllm v2: Efficient block-diffusion llm
Chengyue Wu, Hao Zhang, Shuchen Xue, Shizhe Diao, Yonggan Fu, Zhijian Liu, Pavlo Molchanov, Ping Luo, Song Han, and Enze Xie. Fast-dllm v2: Efficient block-diffusion llm. arXiv preprint arXiv:2509.26328, 2025
arXiv 2025
-
[41]
Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780, 2026
LLM-Core Xiaomi. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780, 2026
Pith/arXiv arXiv 2026
-
[42]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[43]
Narasimhan
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R. Narasimhan. τ-bench: A bench- mark for tool-agent-user interaction in real-world domains. InThe Thirteenth International Conference on Learning Representations, 2025. 13
2025
-
[44]
Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. d1: Scaling reasoning in diffusion large language models via reinforcement learning.arXiv preprint arXiv:2504.12216, 2025
arXiv 2025
-
[45]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Processing Systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Processing Systems, 36:46595–46623, 2023
2023
-
[46]
Distillspec: Improving speculative decoding via knowledge distillation
Yongchao Zhou, Kaifeng Lyu, Ankit Singh Rawat, Aditya Krishna Menon, Afshin Ros- tamizadeh, Sanjiv Kumar, Jean-François Kagy, and Rishabh Agarwal. Distillspec: Improving speculative decoding via knowledge distillation. InInternational Conference on Learning Representations, 2024
2024
-
[47]
We”). The causal head’s rank-1 branch (“ are told that
Dawei Zhu, Xiyu Wei, Guangxiang Zhao, Wenhao Wu, Haosheng Zou, Junfeng Ran, XWang, Lin Sun, Xiangzheng Zhang, and Sujian Li. Chain-of-thought matters: Improving long- context language models with reasoning path supervision. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computatio...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.