Atomic Task Graph: A Unified Framework for Agentic Planning and Execution
Pith reviewed 2026-07-03 13:57 UTC · model grok-4.3
The pith
Atomic Task Graph makes task dependencies explicit so LLM agents can reuse verified steps, run branches in parallel, and repair only failed regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
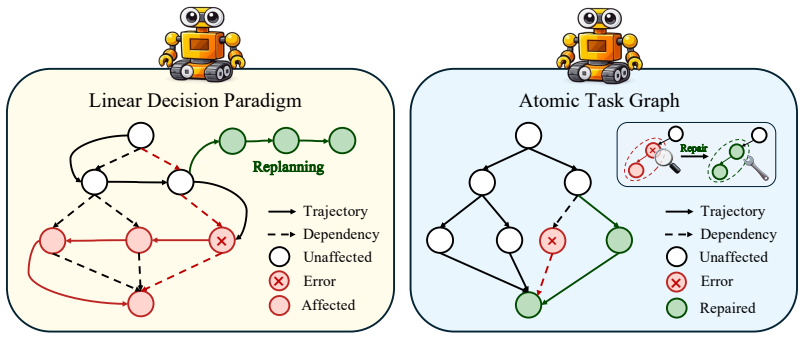
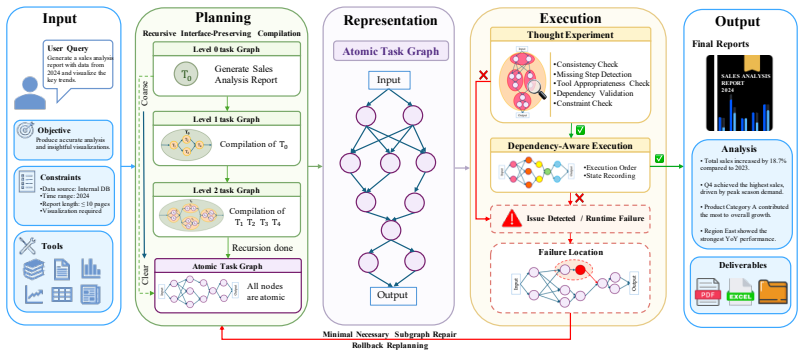
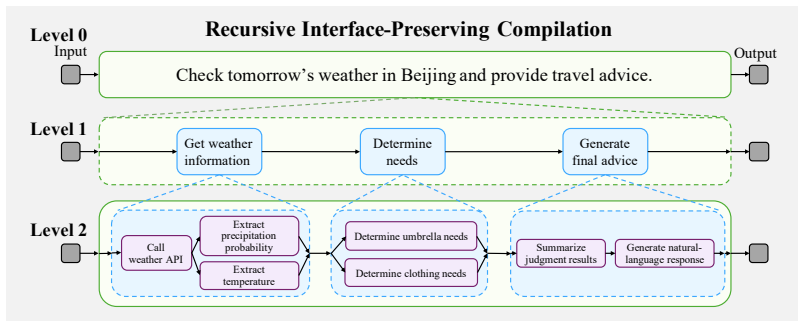
ATG is a unified framework that maintains an explicit graph of subtask dependencies, formed as evolving sequences of DAGs during recursive planning, and that uses the same graph during execution to enable parallel branch processing and history-guided localization of errors so that only the affected subgraph needs repair.
What carries the argument
Atomic Task Graph, an explicit directed acyclic graph that records subtask dependencies and evolution history to support reuse, parallelism, and localized repair.
If this is right
- Independent subtask branches can execute concurrently, shortening total runtime.
- Only the subgraph downstream of a detected failure needs re-planning or re-execution.
- Verified intermediate results become reusable across different high-level tasks.
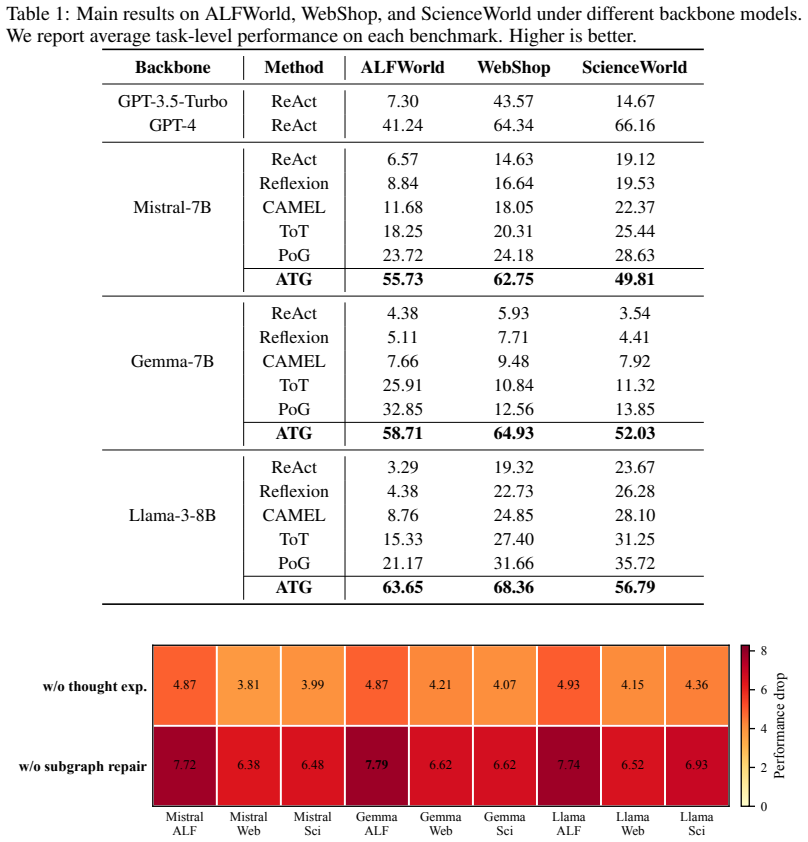
- Performance gains appear with 7B-8B models on interactive benchmarks without fine-tuning.
- The same graph structure serves both planning and execution phases in a single framework.
Where Pith is reading between the lines
- The approach could lower the compute budget required for reliable multi-step agents in resource-constrained settings.
- Graph history might supply training signals for future learned planners that predict likely failure points.
- Similar explicit dependency tracking could be applied to non-LLM agent architectures that already maintain internal state.
Load-bearing premise
That keeping an explicit dependency graph will let verified results be reused and will let errors be isolated to the right region without the graph structure itself creating new points of failure.
What would settle it
A controlled run on one of the three benchmarks in which ATG produces lower success rate or slower execution than the text-only baseline because graph maintenance introduces coordination errors.
Figures
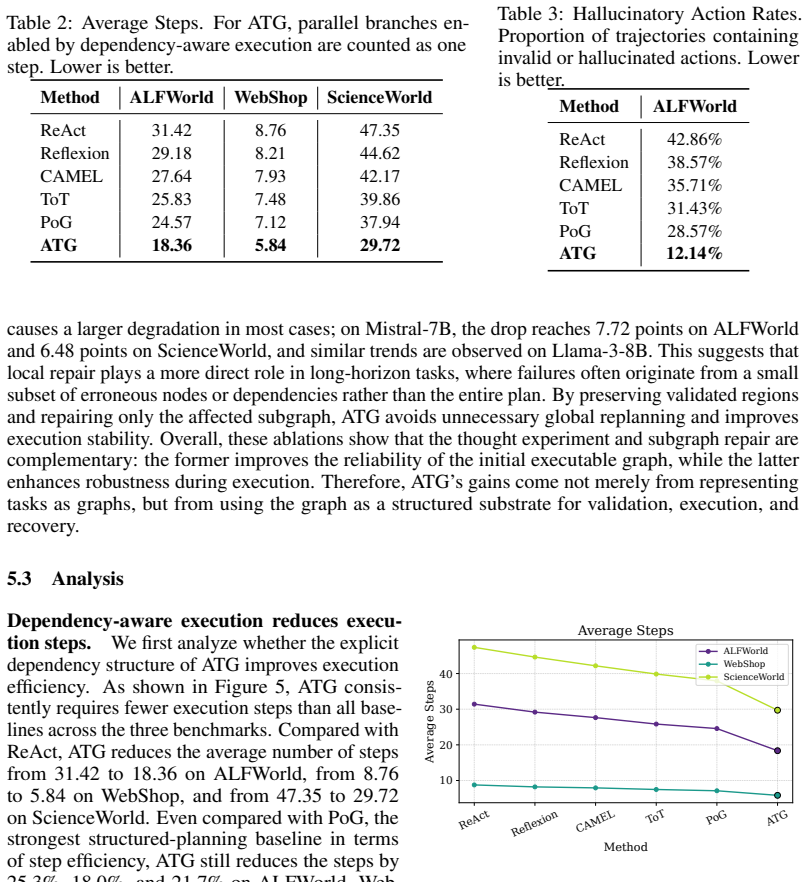
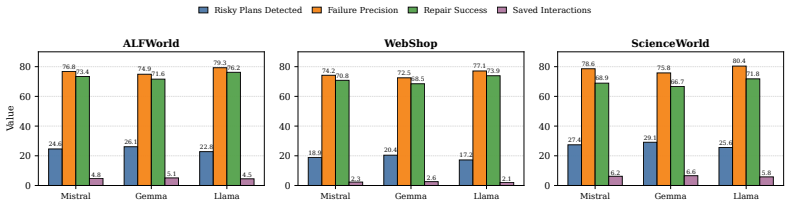

read the original abstract
LLM-based agents have shown strong potential for solving complex multi-step tasks, yet existing performance improvements often rely on either scaling to larger backbone models or task-specific fine-tuning. The former incurs substantial computational costs, while the latter typically generalizes poorly across different tasks. Although prompt-based control is training-free and broadly applicable, existing methods still leave input-output dependencies between subtasks implicit in textual trajectories, making verified intermediate results difficult to reuse. To address these limitations, we propose Atomic Task Graph (ATG), a unified control framework for planning and execution. Specifically, ATG maintains an explicit graph to expose dependencies and support reuse. During planning, it recursively decomposes a high-level task into subtasks, forming a sequence of directed acyclic graphs (DAGs) whose evolution can be traced. During execution, the dependencies exposed by ATG allow independent branches to be executed in parallel, thereby improving execution efficiency. When failures are detected, ATG leverages the graph evolution history to localize the error source and repair only the affected region, preserving validated regions unchanged. Experiments show that ATG consistently outperforms strong baselines in success rate and execution efficiency across three interactive benchmarks using only 7B-8B backbones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Atomic Task Graph (ATG), a unified control framework for LLM-based agents that maintains explicit directed acyclic graphs (DAGs) formed by recursive task decomposition. During planning, ATG exposes input-output dependencies; during execution, it enables parallel execution of independent branches and reuses verified intermediate results. On failure detection, the graph evolution history localizes errors for targeted repair while preserving validated regions. The central claim is that ATG consistently outperforms strong baselines in success rate and execution efficiency across three interactive benchmarks when using only 7B-8B backbone models.
Significance. If the empirical results hold, ATG provides a training-free mechanism to improve multi-step agent performance by making implicit textual dependencies explicit, reducing the need for model scaling or task-specific fine-tuning. The combination of DAG construction, parallel execution support, and history-based localized repair represents a concrete architectural contribution that could generalize across interactive tasks.
minor comments (3)
- [Abstract] Abstract: The three interactive benchmarks are not named and the strong baselines are not listed; adding these details would immediately clarify the scope and strength of the comparison.
- [Methods] The description of how the DAG is constructed during recursive decomposition (e.g., node/edge representation, stopping criteria) is only sketched at a high level; a short pseudocode or explicit definition in the methods section would improve reproducibility.
- [Experiments] Figure captions and axis labels in the experimental plots should explicitly state the metric (success rate vs. efficiency) and backbone model size for each curve.
Simulated Author's Rebuttal
We thank the referee for the positive summary and recommendation of minor revision. The provided report contains no specific major comments to address point-by-point.
Circularity Check
No significant circularity
full rationale
The paper introduces the ATG framework as a control structure for LLM agents, describing recursive DAG construction, dependency exposure, parallel execution, and history-based repair. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The central claim is an empirical outperformance result on benchmarks, which is not shown to reduce to any input by construction. No self-citations, ansatzes, or uniqueness theorems are invoked in a load-bearing way. The derivation chain is therefore self-contained as a descriptive framework plus experimental validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey on large language model based autonomous agents.Frontiers Comput
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. A survey on large language model based autonomous agents.Frontiers Comput. Sci., 18(6): 186345, 2024. doi: 10.1007/S11704-024-40231-1. URL https://doi.org/10.1007/ s11704-024-40231-1
-
[2]
A review of prominent paradigms for llm-based agents: Tool use, planning (including rag), and feedback learning
Xinzhe Li. A review of prominent paradigms for llm-based agents: Tool use, planning (including rag), and feedback learning. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, COLING 2025, Abu Dhabi, UAE, January ...
2025
-
[3]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.arXiv preprint arXiv:2302.04761, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
PAL: program-aided language models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. PAL: program-aided language models. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, Pro...
2023
-
[5]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large lan- guage model connected with massive apis. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Ad- vances in Neural Information Processing Systems 38: Annual Conference on Neural In- formation Process...
2024
-
[6]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023
2023
-
[7]
Narasimhan, and Shunyu Yao
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R. Narasimhan, and Shunyu Yao. Re- flexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, volume 36, pages 8634–8652, 2023
2023
-
[8]
Webshop: Towards scal- able real-world web interaction with grounded language agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scal- able real-world web interaction with grounded language agents. In Sanmi Koyejo, S. Mo- hamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neu- ral Information Processing Systems 35: Annual Conference on Neural Information Pro- cessing Systems 2022,...
2022
-
[9]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2...
2024
-
[10]
Mind2web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samual Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. In Alice Oh, Tris- tan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Syst...
2023
-
[11]
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. ALFRED: A benchmark for interpreting grounded instructions for everyday tasks. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pages 10737–10746. Computer Vision ...
-
[12]
Hausknecht
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew J. Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URL https://openreview.net/ forum?id=0IOX0YcCdTn
2021
-
[13]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhut- dinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi- hop question answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Lan- guage P...
-
[14]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback.CoRR, abs/2112.093...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
MedCLIP: Contrastive learning from unpaired medical images and text
Ruoyao Wang, Peter A. Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu. Science- world: Is your agent smarter than a 5th grader? In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 1...
-
[16]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, volume 36, pages 11809–11822, 2023
2023
-
[17]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17682–17690, 2024
2024
-
[18]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/ forum?...
2023
-
[19]
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning, acting, and planning in language models.arXiv preprint arXiv:2310.04406, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradb...
2023
-
[21]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Lit...
2020
-
[22]
Zhao, Yanping Huang, Andrew M
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Y . Zhao, Yanpi...
2024
-
[23]
Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M
Jason Wei, Maarten Bosma, Vincent Y . Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V . Le. Finetuned language models are zero-shot learners. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29,
2022
-
[24]
URLhttps://openreview.net/forum?id=gEZrGCozdqR
OpenReview.net, 2022. URLhttps://openreview.net/forum?id=gEZrGCozdqR
2022
-
[25]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neura...
2022
-
[26]
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee- Peng Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2609–2634, 2023
2023
-
[27]
Plan-over-graph: Towards parallelable LLM agent schedule.CoRR, abs/2502.14563, 2025
Shiqi Zhang, Xinbei Ma, Zouying Cao, Zhuosheng Zhang, and Hai Zhao. Plan-over-graph: Towards parallelable LLM agent schedule.CoRR, abs/2502.14563, 2025. doi: 10.48550/ ARXIV .2502.14563. URLhttps://doi.org/10.48550/arXiv.2502.14563
-
[28]
Hugginggpt: Solving AI tasks with chatgpt and its friends in hugging face
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving AI tasks with chatgpt and its friends in hugging face. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, edi- tors,Advances in Neural Information Processing Systems 36: Annual Conference on Neu- ral Information P...
2023
-
[29]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated 12 software engineering. In Amir Globersons, Lester Mackey, Danielle Belgrave, An- gela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing...
2024
-
[30]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum? id=VTF8yNQM66
2024
-
[31]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemi- cal research with large language models.Nat., 624(7992):570–578, 2023. doi: 10.1038/ S41586-023-06792-0. URLhttps://doi.org/10.1038/s41586-023-06792-0
-
[32]
Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D
Andres M. Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D. White, and Philippe Schwaller. Augmenting large language models with chemistry tools.Nat. Mac. Intell., 6 (5):525–535, 2024. doi: 10.1038/S42256-024-00832-8. URL https://doi.org/10.1038/ s42256-024-00832-8
-
[33]
CAMEL: Communicative agents for “mind” exploration of large language model society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for “mind” exploration of large language model society. InAdvances in Neural Information Processing Systems, volume 36, pages 51991–52008, 2023
2023
-
[34]
Kevin Yau, Zhouhan Lin, Jie Zhou, Yining Wang, et al
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiaosi Zheng, Yuheng Cheng, Chaoyi Zhang, Jian Wang, Zhonghao Zhang, S.-K. Kevin Yau, Zhouhan Lin, Jie Zhou, Yining Wang, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations, 2024
2024
-
[35]
White, and Doug Burger Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Chi Liu, Ahmed Hassan Awadallah, Ryen W. White, and Doug Burger Wang. Auto- gen: Enabling next-gen LLM applications via multi-agent conversation.Proceedings of the Conference on Language Modeling, 2024
2024
-
[36]
Junwei Yu, Yepeng Ding, and Hiroyuki Sato. Dyntaskmas: A dynamic task graph-driven framework for asynchronous and parallel llm-based multi-agent systems.arXiv preprint arXiv:2503.07675, 2025
-
[37]
Tenenbaum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Learning, IC...
2024
-
[38]
Zhenhailong Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, and Heng Ji. Unleashing the emergent cognitive synergy in large language models: A task-solving agent through multi- persona self-collaboration. In Kevin Duh, Helena Gómez-Adorno, and Steven Bethard, editors, Proceedings of the 2024 Conference of the North American Chapter of the Association f...
-
[39]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Agenttuning: Enabling generalized agent abilities for llms
Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. Agenttuning: Enabling generalized agent abilities for llms. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, Findings of ACL, pages 3053–3...
-
[41]
arXiv preprint arXiv:2310.05915 , year=
Baian Chen, Chang Shu, Ehsan Shareghi, Nigel Collier, Karthik Narasimhan, and Shunyu Yao. Fireact: Toward language agent fine-tuning.CoRR, abs/2310.05915, 2023. doi: 10.48550/ ARXIV .2310.05915. URLhttps://doi.org/10.48550/arXiv.2310.05915
-
[42]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chap- lot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.CoRR, abs/2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
OpenAI. GPT-4 technical report.CoRR, abs/2303.08774, 2023. doi: 10.48550/ARXIV .2303. 08774. URLhttps://doi.org/10.48550/arXiv.2303.08774. 14
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.