HumanMoveVQA: Can Video MLLMs reason about human movement in videos?
Pith reviewed 2026-06-29 04:50 UTC · model grok-4.3
The pith
Video MLLMs fail at global human trajectory and orientation reasoning but improve markedly when fine-tuned on world-consistent 3D motion data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
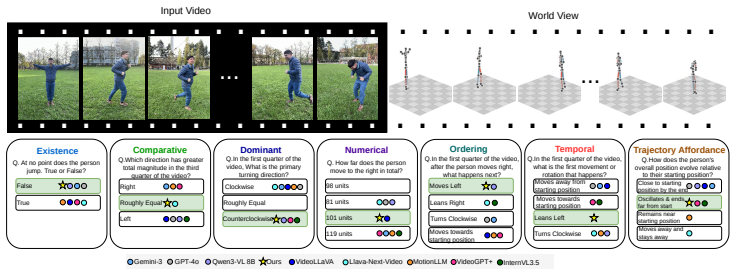
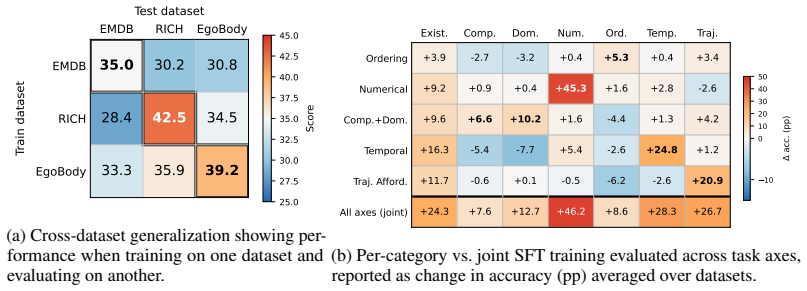
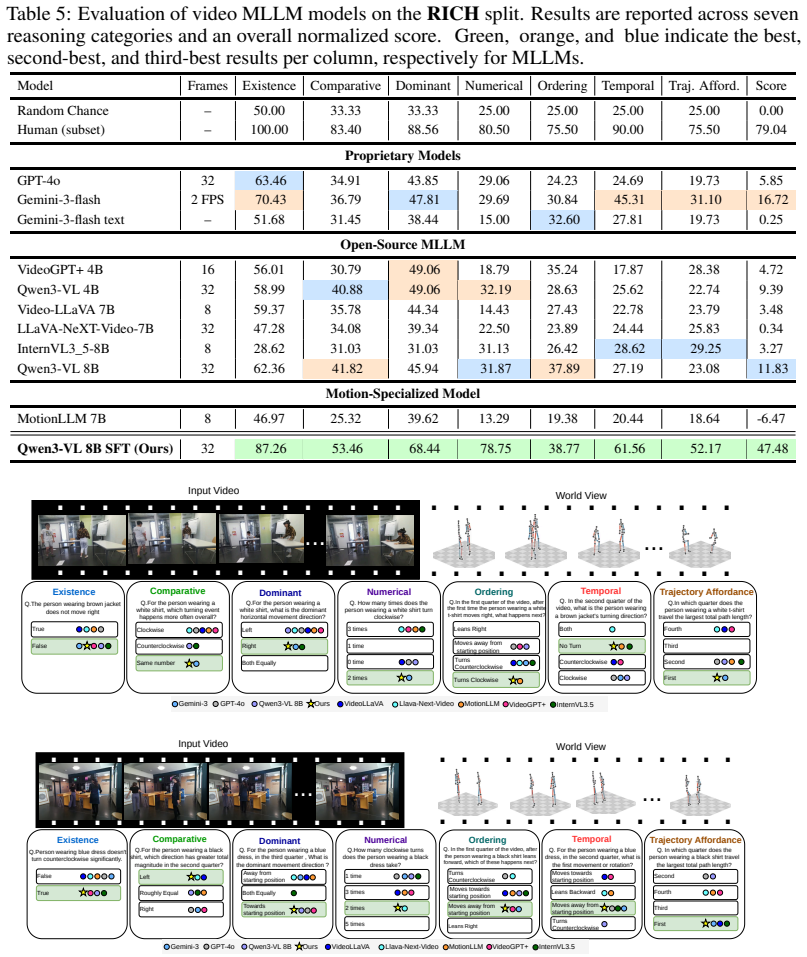
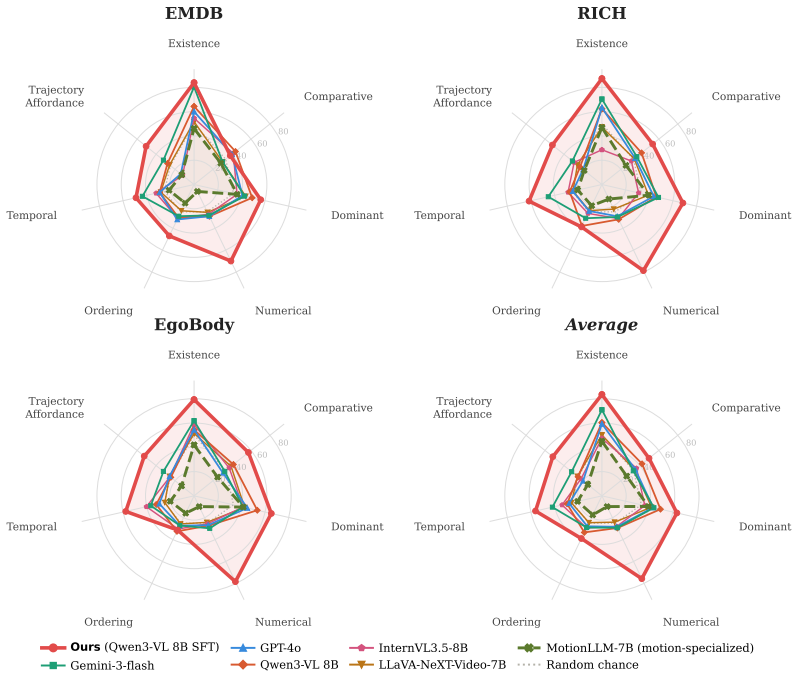
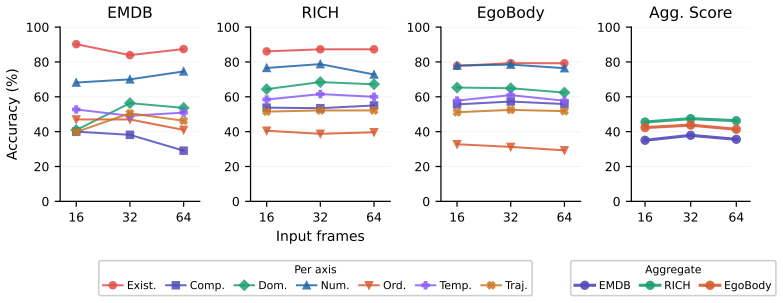
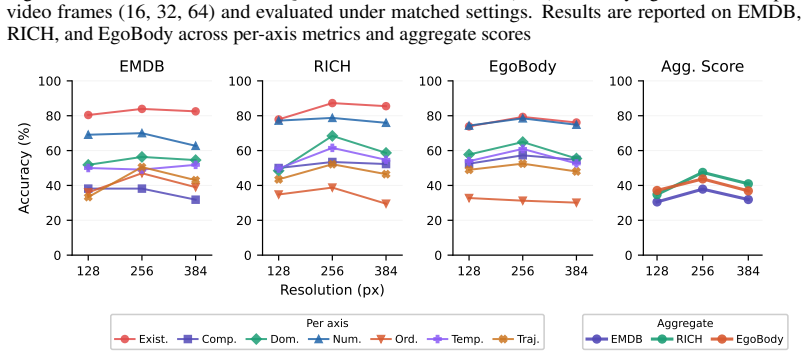
HumanMoveVQA shows that current video MLLMs reduce complex human motion to broad semantic labels and cannot reliably answer questions about global trajectories or orientation shifts, but fine-tuning an open-source model on the benchmark's world-consistent 3D supervision produces clear gains across the seven reasoning categories.
What carries the argument
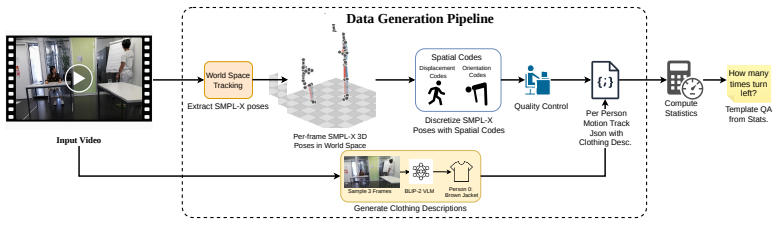
The multi-stage pipeline that converts 2D video frames into world-consistent 3D motion tracks anchored to the first frame, generating structured QA pairs that test trajectory-level and orientation reasoning.
If this is right
- Fine-tuned open-source models can outperform proprietary ones on global human motion tasks when given the same world-consistent supervision.
- Video understanding systems can move beyond local joint or scene labels to handle trajectory aggregation and sequential ordering questions.
- The seven reasoning categories supply a structured way to measure progress on movement-aware video models.
- A geometric, first-frame-anchored coordinate system provides a repeatable foundation for generating motion QA data at scale.
Where Pith is reading between the lines
- The same lifting pipeline could be applied to non-human moving objects such as vehicles or animals to create similar benchmarks.
- Models trained this way may transfer better to downstream tasks that require predicting future paths from observed motion.
- The gap between proprietary and fine-tuned performance suggests other video reasoning shortfalls could also close with targeted geometric data rather than scale alone.
Load-bearing premise
The pipeline that lifts 2D observations into 3D motion tracks keeps translation and rotation accurate relative to the fixed starting point without introducing errors that would invalidate the generated questions and answers.
What would settle it
A direct comparison of the pipeline's 3D tracks against ground-truth motion capture data on the same videos that reveals systematic drift in position or rotation, or a re-run of the fine-tuning experiment on a fresh set of real videos that shows no accuracy gain.
Figures






read the original abstract
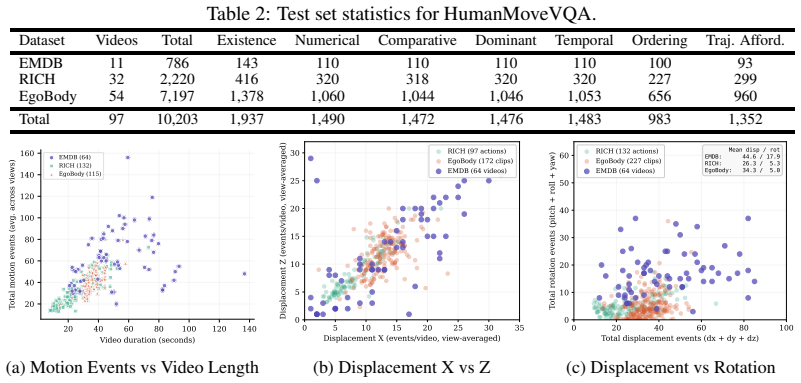
Despite the rapid advance of Multimodal Large Language Models (MLLMs) in high-level video understanding, a fundamental bottleneck remains: these models collapse complex human motion into coarse semantic labels. Existing benchmarks mostly focus on scene-centric events or local joint articulations, failing to probe global human motion in space over time (trajectory and orientation changes). We introduce HumanMoveVQA, the first comprehensive benchmark designed to evaluate global trajectory and orientation reasoning from an exocentric perspective. Our benchmark utilizes a first-frame anchored world coordinate system, preserving translation and rotation relative to a fixed starting point. We propose a scalable, multi-stage pipeline that lifts 2D video observations into world-consistent 3D motion tracks to generate over 10K structured question-answer pairs across seven reasoning categories, including motion aggregation, sequential ordering, and trajectory-level inference. Our extensive evaluation reveals a critical capability gap in state-of-the-art proprietary models on deep human motion understanding. However, we demonstrate that this is a learnable problem; by fine-tuning an open-source baseline with our targeted, world-consistent supervision, we achieve a significant improvement. HumanMoveVQA establishes a rigorous geometric foundation for developing next-generation, movement-aware video understanding models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HumanMoveVQA, the first benchmark targeting global human trajectory and orientation reasoning in videos from an exocentric perspective. It describes a first-frame-anchored world coordinate system and a multi-stage 2D-to-3D lifting pipeline used to generate over 10K QA pairs across seven categories (motion aggregation, sequential ordering, trajectory inference, etc.). Evaluations on the benchmark reveal capability gaps in state-of-the-art proprietary video MLLMs, while fine-tuning an open-source baseline with the generated world-consistent supervision yields significant gains.
Significance. If the 3D lifting pipeline is shown to be accurate, the work supplies a geometrically grounded benchmark that addresses a clear gap in existing video-understanding evaluations, which largely emphasize semantic events or local joint motion rather than global trajectory and orientation changes over time. The explicit demonstration that the observed gap is learnable via targeted supervision is a constructive finding for the field.
major comments (1)
- [Method section describing the 2D-to-3D lifting pipeline] The multi-stage 2D-to-3D lifting pipeline (described in the method section) is load-bearing for the entire benchmark and all downstream claims, yet the manuscript reports no quantitative validation against ground-truth 3D data (e.g., position/orientation drift or mocap error on held-out sequences). Systematic biases in translation or rotation relative to the first-frame anchor would directly corrupt the seven reasoning categories and the fine-tuning supervision.
minor comments (1)
- [Abstract] The abstract states results at a high level but omits any reference to dataset statistics, error analysis, or validation of the generated QA pairs, making it difficult to assess reliability from the provided description alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the benchmark's significance. We address the single major comment point by point below.
read point-by-point responses
-
Referee: [Method section describing the 2D-to-3D lifting pipeline] The multi-stage 2D-to-3D lifting pipeline (described in the method section) is load-bearing for the entire benchmark and all downstream claims, yet the manuscript reports no quantitative validation against ground-truth 3D data (e.g., position/orientation drift or mocap error on held-out sequences). Systematic biases in translation or rotation relative to the first-frame anchor would directly corrupt the seven reasoning categories and the fine-tuning supervision.
Authors: We agree that the 2D-to-3D lifting pipeline is central to the benchmark and that the absence of quantitative validation against ground-truth 3D data is a limitation. The pipeline composes established off-the-shelf components (2D pose estimation, monocular depth, and camera pose estimation) with a first-frame anchoring step, but we did not report end-to-end error metrics on held-out mocap sequences. In the revised manuscript we will add a dedicated validation subsection that measures position and orientation drift on sequences with available 3D ground truth, thereby quantifying any systematic biases relative to the anchor frame. revision: yes
Circularity Check
No circularity; benchmark pipeline and evaluations are independent of each other
full rationale
The paper constructs HumanMoveVQA via a described multi-stage 2D-to-3D lifting pipeline to produce QA pairs, then separately evaluates proprietary and open-source MLLMs on those pairs and shows fine-tuning gains. No equations, fitted parameters, or self-citations are presented as load-bearing derivations. The pipeline is an input method for data generation, not a quantity derived from or equivalent to the model results. The central claims (capability gap + learnability) rest on external model evaluations rather than reducing to the pipeline definition itself. This matches the default expectation of a non-circular benchmark paper.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.