Beyond Additive Decompositions: Interpretability Through Separability
Pith reviewed 2026-06-28 23:19 UTC · model grok-4.3
The pith
A separable regression model can be fully reconstructed from its first-order partial dependence functions up to constant factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
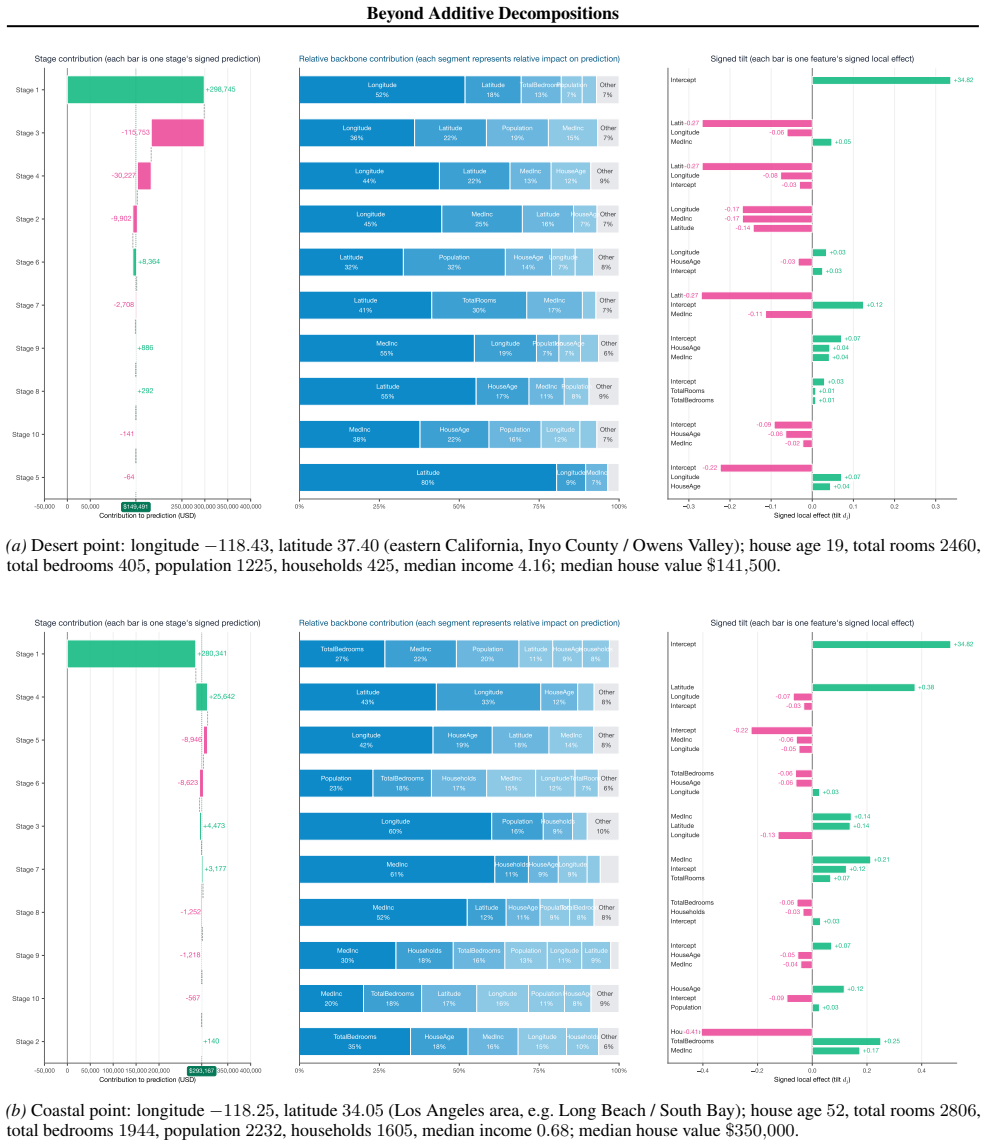
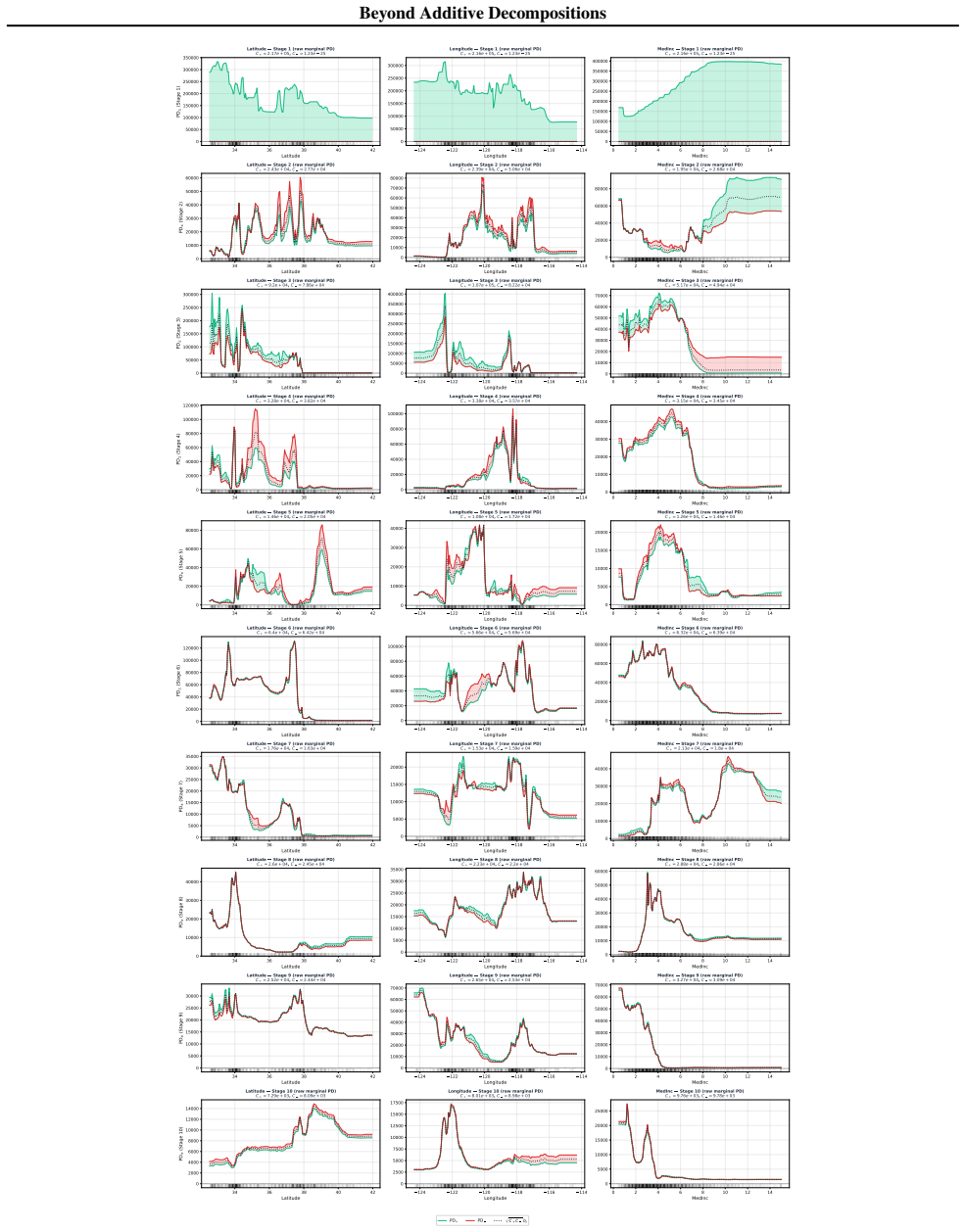
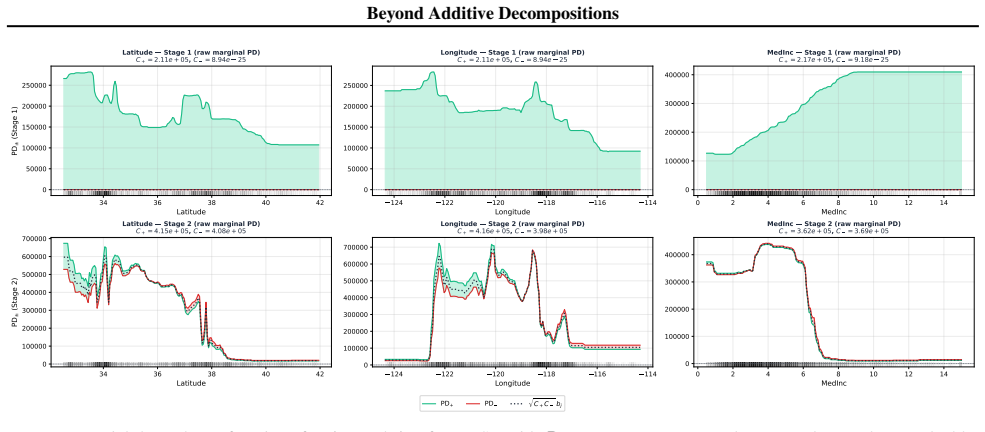
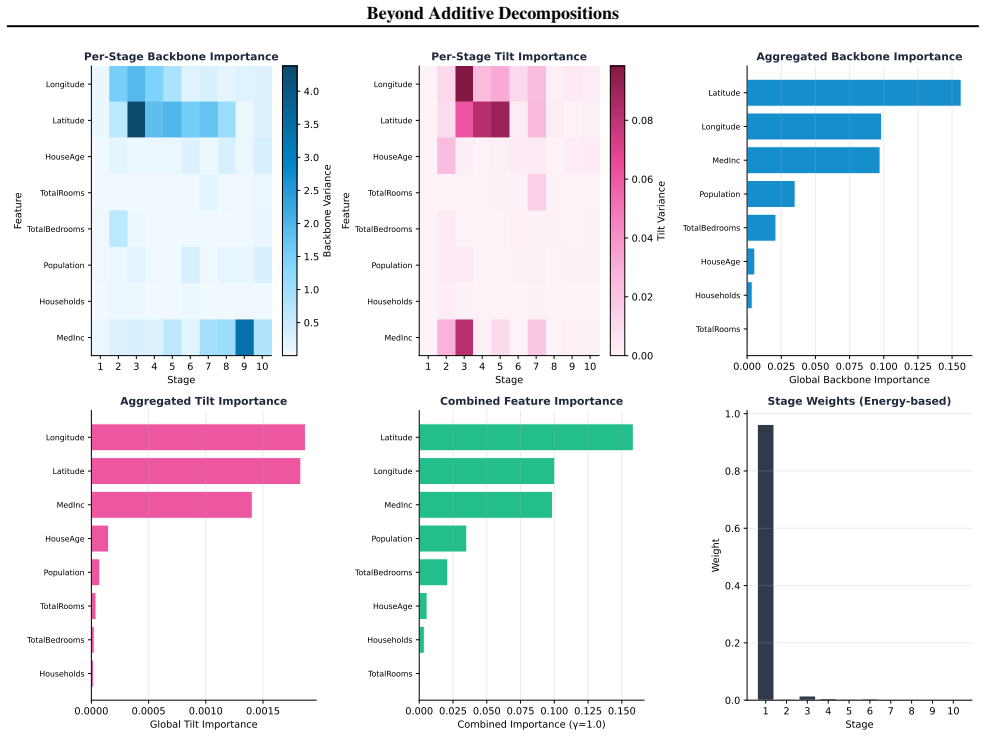
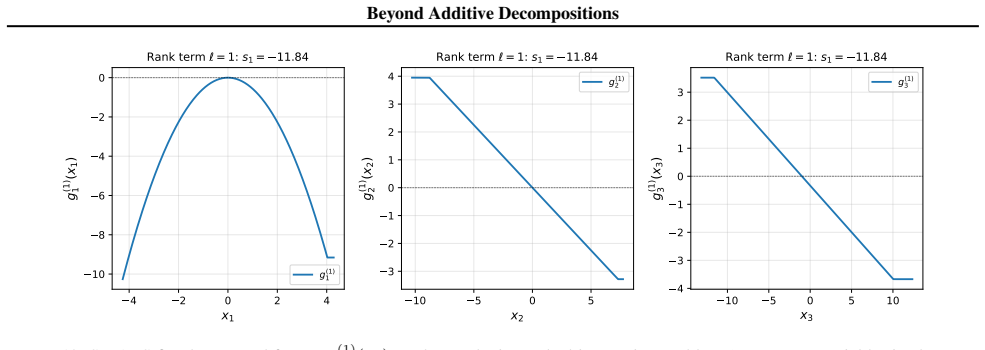
Tensor Separation Learning learns a sum of rank-1 products of univariate per-feature functions via a stagewise greedy procedure with orthogonal refitting. Because of the enforced separability, the learned model can be fully reconstructed from first-order partial dependence functions up to constant factors, and the resulting visualizations remain faithful to the fitted components without information loss from higher-order interactions.
What carries the argument
Tensor Separation Learning (TSL): a regression model expressed as a sum of rank-1 products of univariate functions, fitted by stagewise greedy selection with orthogonal refitting.
If this is right
- First-order partial dependence plots become faithful visualizations of the fitted components without marginalization loss.
- The model supplies approximation-rate guarantees for functions whose mixed partial derivatives of order p remain bounded.
- TSL avoids the signal cancellation and off-support extrapolation problems that arise in additive representations when interactions are strong.
- On regression benchmarks the method achieves accuracy comparable to black-box models while preserving the reconstruction property.
Where Pith is reading between the lines
- The reconstruction property may allow direct editing of model behavior by adjusting the partial dependence plots themselves.
- Datasets known to contain multiplicative feature effects could be modeled more naturally than with purely additive decompositions.
- The same stagewise fitting idea might be adapted to other base learners or combined with existing partial-dependence tools to improve their reliability.
- Extension to classification or survival tasks would require checking whether the rank-1 separability still yields exact recovery from first-order marginals.
Load-bearing premise
The stagewise greedy procedure with orthogonal refitting produces components whose first-order partial dependence plots recover the model without information loss from higher-order interactions.
What would settle it
Fit TSL to synthetic data generated from a known separable rank-1 structure with interactions, then verify whether the first-order partial dependence functions recover the original components up to constants.
Figures
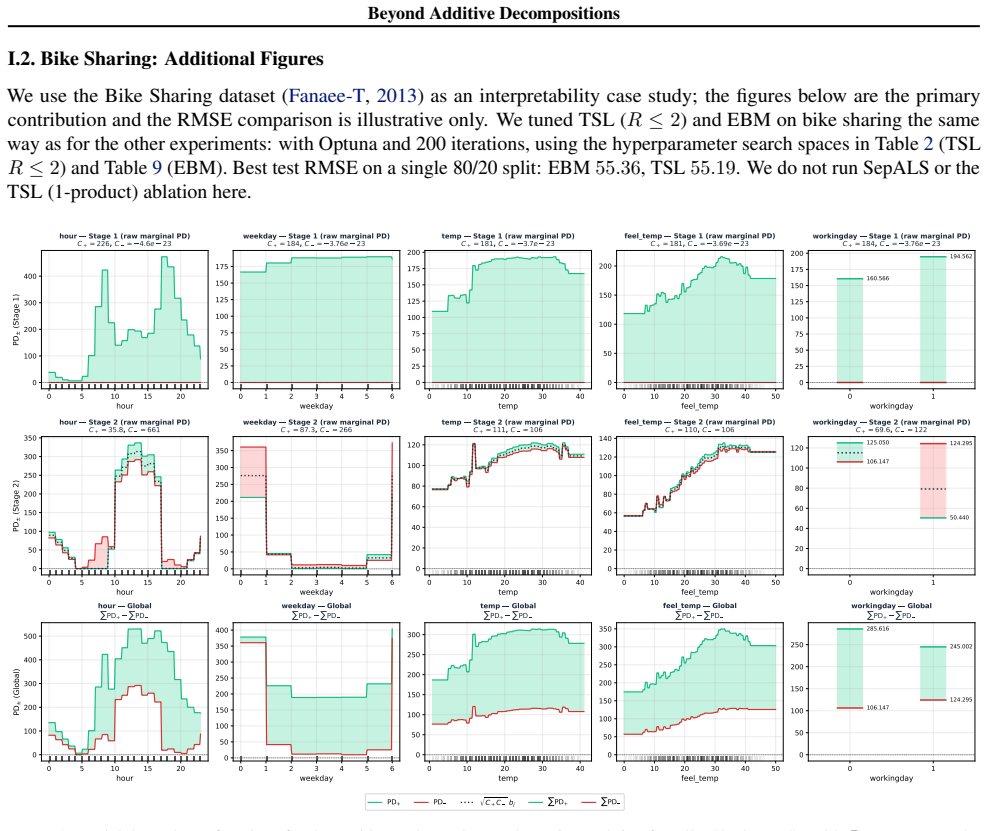
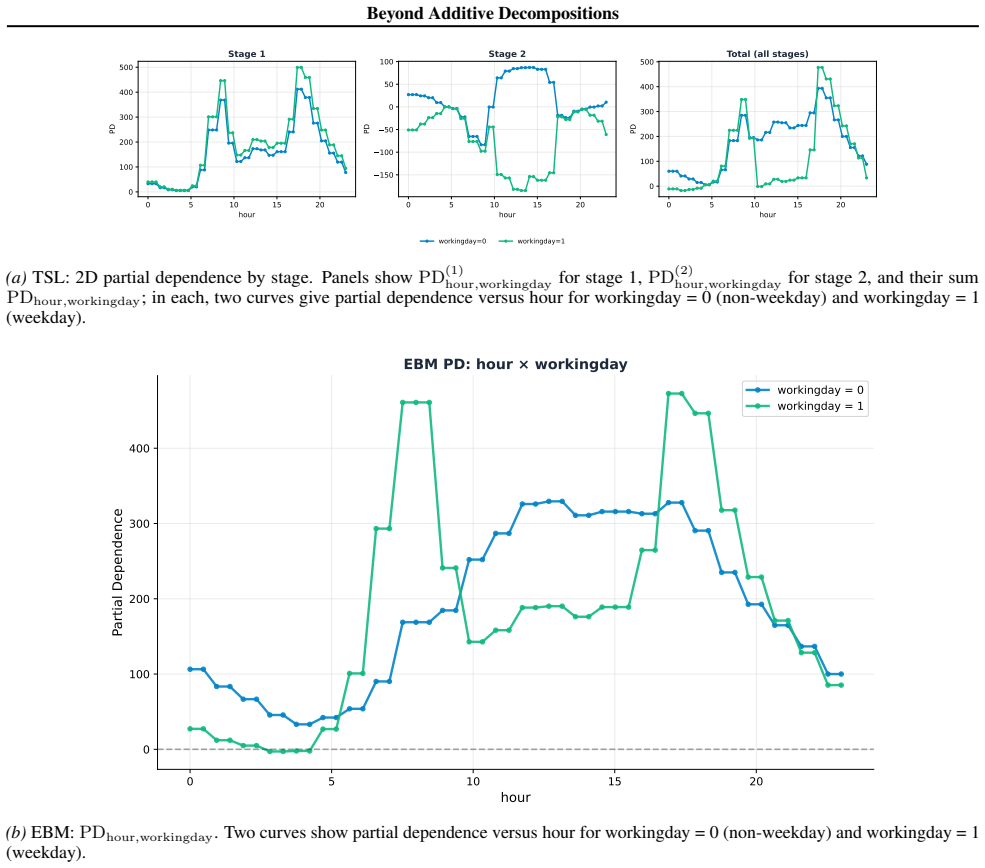
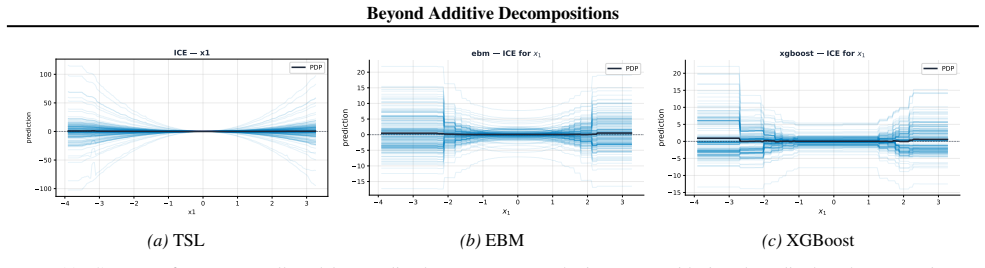
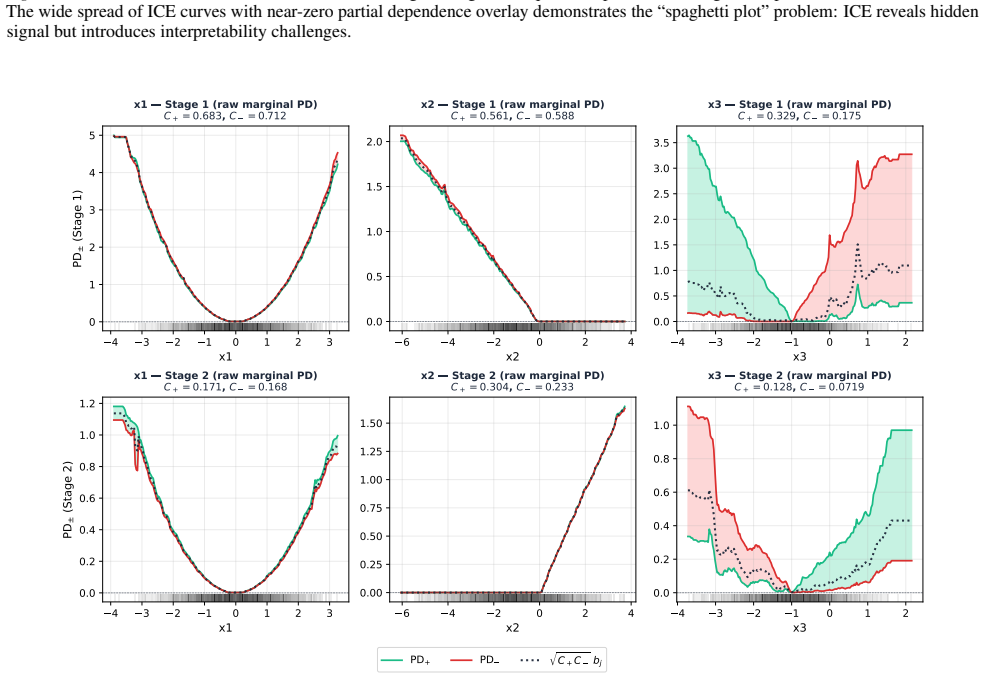
read the original abstract
Interpretable machine learning requires models that are accurate and structurally faithful to the data. Existing explainability methods rely heavily on additive representations (e.g., Generalized Additive Models (GAMs), SHapley Additive exPlanations (SHAP), functional ANOVA), which can suffer from signal cancellation and off-support extrapolation in the presence of strong interactions. We propose Tensor Separation Learning (TSL), a regression model that learns a sum of rank-1 products of univariate per-feature functions via a stagewise greedy procedure with orthogonal refitting. By enforcing separability, TSL avoids the information loss inherent in additive projections caused by marginalizing higher-order interactions. The learned TSL model can be fully reconstructed from first-order partial dependence functions, up to constant factors. This stage-wise correspondence ensures that the resulting visualizations are faithful to the fitted components. We establish approximation-rate guarantees for functions with bounded mixed $p$-th order partial derivatives and demonstrate that TSL competes with black-box models on regression benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Tensor Separation Learning (TSL), a regression model expressed as a sum of rank-1 products of univariate functions learned through a stagewise greedy procedure with orthogonal refitting. It claims that TSL models can be fully reconstructed from their first-order partial dependence functions up to constant factors, provides approximation rate guarantees for functions with bounded mixed p-th order partial derivatives, and demonstrates competitive performance with black-box models on regression benchmarks while offering improved interpretability by avoiding information loss from additive projections of interactions.
Significance. If the reconstruction property holds rigorously and the approximation guarantees are valid, TSL would offer a structurally faithful alternative to additive models for capturing interactions. The stagewise procedure with orthogonal refitting represents a potential technical contribution for ensuring PDP faithfulness without marginalization loss.
major comments (2)
- [Abstract] Abstract: The central reconstruction claim (that the learned TSL model can be fully reconstructed from first-order PDPs up to constant factors) is load-bearing for the faithfulness guarantee, yet the text provides no derivation showing that the stagewise orthogonal refitting ensures the coefficient matrix across terms is invertible, allowing unique separation of PDP_j(x_j) = ∑_k c_{k,j} g_{k,j}(x_j) for K>1 (as opposed to the K=1 case where PDP_j(x_j) = c_j ⋅ g_j(x_j)).
- [Abstract] Abstract: Approximation-rate guarantees are asserted for functions with bounded mixed p-th order partial derivatives, but the abstract states these without visible error analysis, explicit rates, or derivation, leaving the support for this theoretical claim unverified in the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We will revise the manuscript to improve clarity on the theoretical claims while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central reconstruction claim (that the learned TSL model can be fully reconstructed from first-order PDPs up to constant factors) is load-bearing for the faithfulness guarantee, yet the text provides no derivation showing that the stagewise orthogonal refitting ensures the coefficient matrix across terms is invertible, allowing unique separation of PDP_j(x_j) = ∑_k c_{k,j} g_{k,j}(x_j) for K>1 (as opposed to the K=1 case where PDP_j(x_j) = c_j ⋅ g_j(x_j)).
Authors: The manuscript's theoretical section establishes that orthogonal refitting produces components whose inner products yield a diagonal Gram matrix, ensuring invertibility for any K. This follows from the least-squares projection onto the orthogonal complement of previously fitted terms. The abstract omits the full derivation due to length constraints, but the result holds rigorously under the algorithm's construction. We will add an explicit pointer to the relevant theorem in the revised abstract and introduction. revision: yes
-
Referee: [Abstract] Abstract: Approximation-rate guarantees are asserted for functions with bounded mixed p-th order partial derivatives, but the abstract states these without visible error analysis, explicit rates, or derivation, leaving the support for this theoretical claim unverified in the provided text.
Authors: The rates appear in the approximation theory section, derived via tensor-product spline arguments for mixed smoothness classes, yielding explicit rates of the form O(N^{-p/m}) where m is the number of features and N the sample size. The abstract summarizes the result without the full analysis. We will revise the abstract to include the explicit rate and a reference to the theorem establishing the bound. revision: yes
Circularity Check
No circularity: reconstruction property stated as model consequence without reduction to inputs by construction
full rationale
The abstract asserts that the TSL model (sum of rank-1 products) can be reconstructed from first-order PDPs up to constants, and that the stagewise procedure ensures faithfulness. No quoted equation or step in the provided text reduces this reconstruction to a fitted parameter or self-citation by definition; the claim is presented as following from the separability structure and fitting procedure rather than being tautological. Approximation-rate guarantees are mentioned separately as independent content. This is the common case of a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.2307/2530946. Bungartz, H.-J. and Griebel, M. Sparse grids.Acta Numer- ica, 13:147–269, 2004. doi: 10.1017/S0962492904000 182. Carroll, J. D. and Chang, J.-J. Analysis of individual differ- ences in multidimensional scaling via an N-way gener- alization of “Eckart–Young” decomposition.Psychome- trika, 35(3):283–319, 1970. doi: 10.1007/BF02310791. ...
-
[2]
URL https:// papers.nips.cc/paper/2017/hash/6449f 44a102fde848669bdd9eb6b76fa-Abstract
Curran Associates, Inc., 2017. URL https:// papers.nips.cc/paper/2017/hash/6449f 44a102fde848669bdd9eb6b76fa-Abstract. html. Kolda, T. G. and Bader, B. W. Tensor decompositions and applications.SIAM Review, 51(3):455–500, 2009. doi: 10.1137/07070111X. Kruskal, J. B. Three-way arrays: rank and uniqueness of trilinear decompositions, with application to ari...
-
[3]
Park, S., Kong, I., Choi, Y ., Park, C., and Kim, Y
arXiv:1909.09223 [cs.LG]. Park, S., Kong, I., Choi, Y ., Park, C., and Kim, Y . Tensor product neural networks for functional ANOV A model. In Proceedings of the 42nd International Conference on Ma- chine Learning, volume 267 ofProceedings of Machine Learning Research, pp. 48041–48085. PMLR, 2025. Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V ., T...
-
[4]
URL https://proceedings.neurips.cc /paper_files/paper/2022/hash/37b00fb 39d966fcafa14068b2bd0c44a-Abstract-C onference.html. Rota, G.-C. On the foundations of combinatorial theory: I. theory of m¨obius functions. InClassic Papers in Combi- natorics, pp. 332–360. Springer, 1964. Rudin, C. Stop explaining black box machine learning models for high stakes de...
-
[5]
doi: 10.1109/TSP.2017.2690524. Stoudenmire, E. and Schwab, D. J. Supervised learn- ing with tensor networks. In Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., and Garnett, R. (eds.),Ad- vances in Neural Information Processing Systems, vol- ume 29. Curran Associates, Inc., 2016. URL https: //proceedings.neurips.cc/paper_files /paper/2016/file/5314b9674c86e...
-
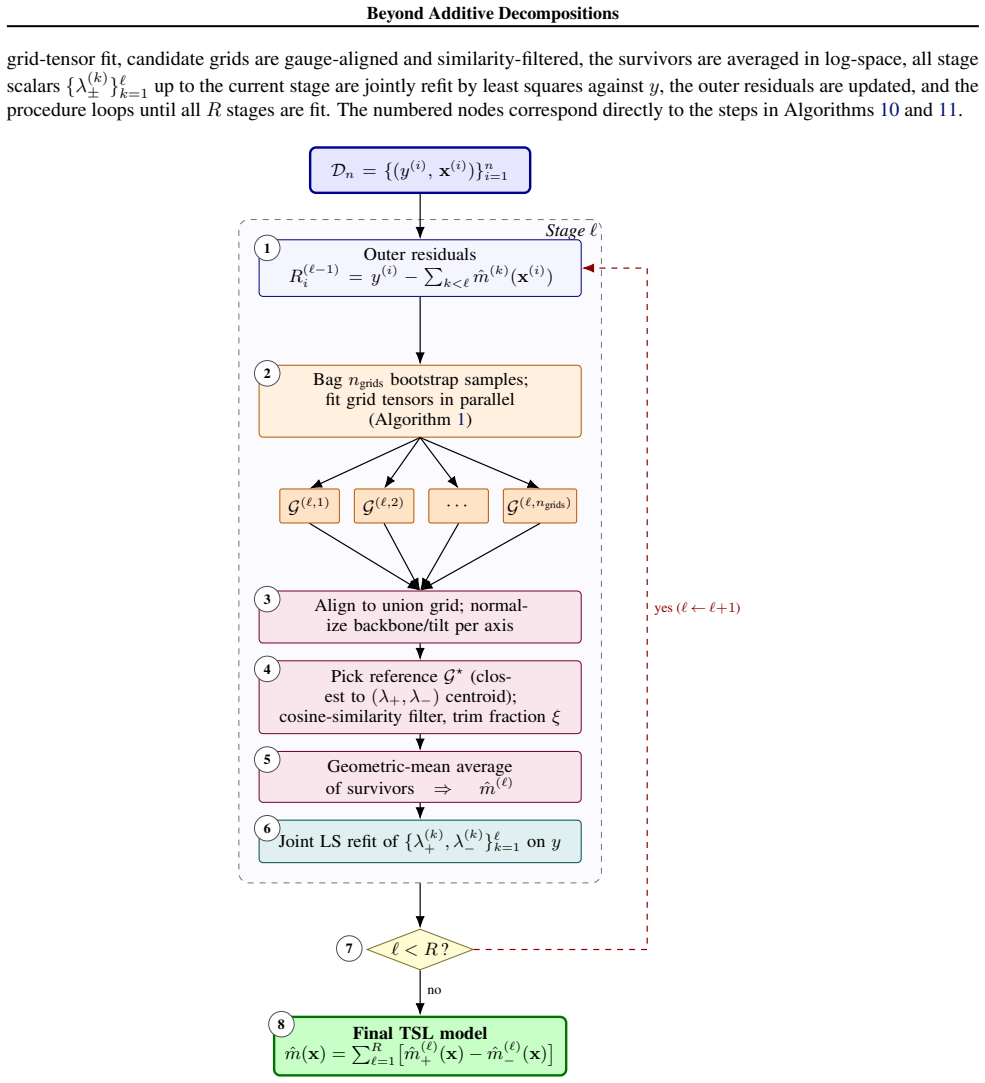
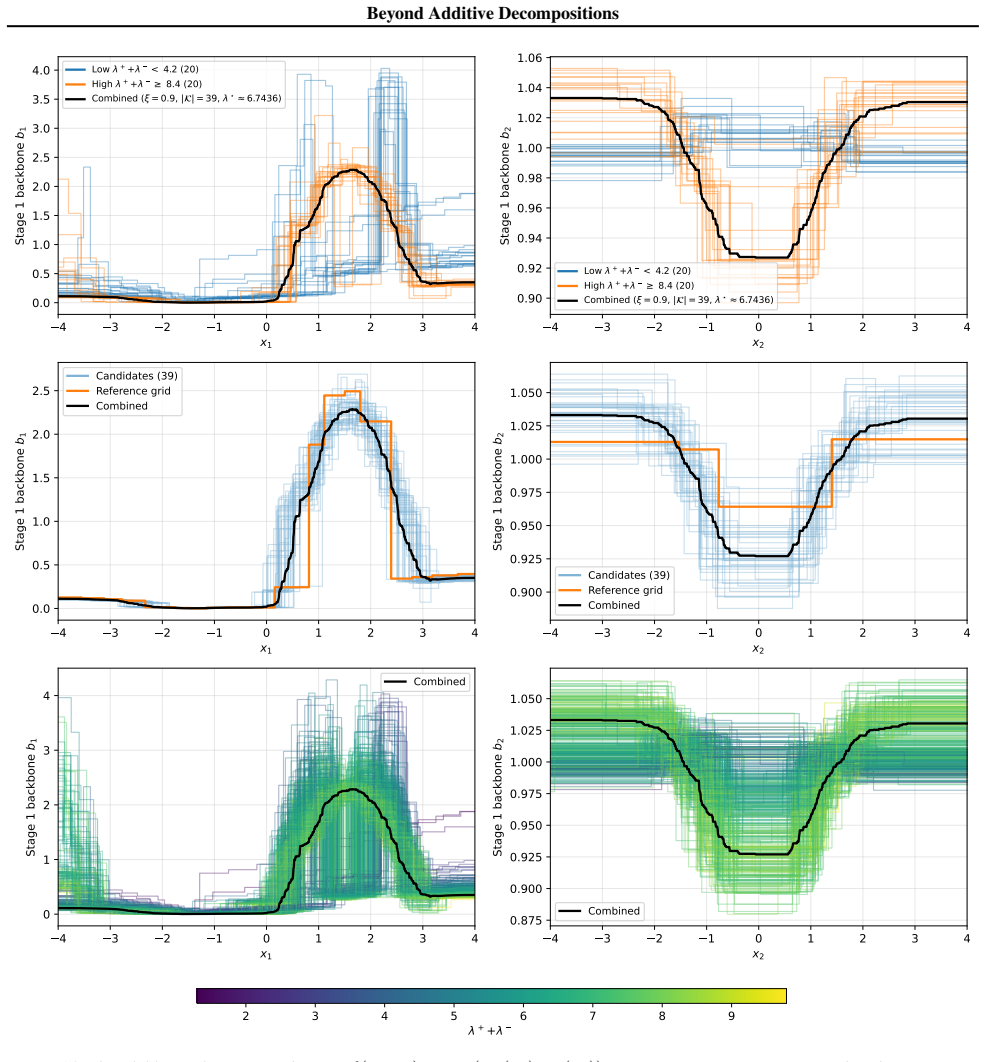
[6]
Align grids to a common union grid { ˜G(c)}ngrids c=1 ←REFINETOUNIONGRID({G (c)}ngrids c=1 )(union over all split points per axis)
-
[7]
Normalize each bag (gauge-fixing so similarities compareshapes) forc= 1ton grids do ˜G(c) ←NORMALIZEPERAXIS( ˜G(c);X){per axisj, subtract empirical mean oflogb j and ofd j overX} end for
-
[8]
Choose a reference grid (closest to the(λ +, λ−)centroid) G⋆ ←arg min c∈{1,...,ngrids} Pngrids c′=1 h (λ(c) + −λ (c′) + )2 + (λ(c) − −λ (c′) − )2 i
-
[9]
Score candidates by similarity to the reference forc= 1ton grids do Compute per-point backbone and tilt summaries: bc ← hQp j=1 b(c),kj(i) j in i=1 andd c ← hPp j=1 d(c),kj(i) j in i=1 simb ← b⋆·bc ∥b⋆∥ ∥bc∥, sim d ← d⋆·dc ∥d⋆∥ ∥dc∥ score(c)← (simb+1)(simd+1) 4 ∈[0,1](as in Eq.(23)) end for
-
[10]
Trim and keep top candidates Keep the topK=⌈(1−ξ)n grids⌉indices by score(c); call this kept setK
-
[11]
¯bk j = q ¯ak +,j¯ak −,j, ¯dk j = 1 2 log(¯ak +,j/¯ak −,j))
Average normalized components (geometric mean in log-space ofa ±), reconstruct(b, d) ¯ak ±,j ←exp 1 |K| P c∈K loga (c),k ±,j wherea k ±,j =b k j e±dk j Reconstruct( ¯b, ¯d)from¯a+,¯a− (e.g. ¯bk j = q ¯ak +,j¯ak −,j, ¯dk j = 1 2 log(¯ak +,j/¯ak −,j))
-
[12]
Combined lambdas:λ combined ± ←exp 1 |K| P c∈K logλ (c) ± return ¯G:= ({ˆmcombined +,j }p j=1,{ˆmcombined −,j }p j=1, λcombined + , λcombined − ) 22 Beyond Additive Decompositions D.2. Candidate Selection via Similarity We select a reference grid G⋆ as the candidate closest to the (λ+, λ−) centroid, i.e. the one minimizing the sum of squared λ-distances t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.