Style or Content? Evaluating Style Classifiers with Controlled Content Overlap
Pith reviewed 2026-06-27 21:59 UTC · model grok-4.3
The pith
Controlled content overlap on parallel translations provides a diagnostic separating style learning from content shortcuts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
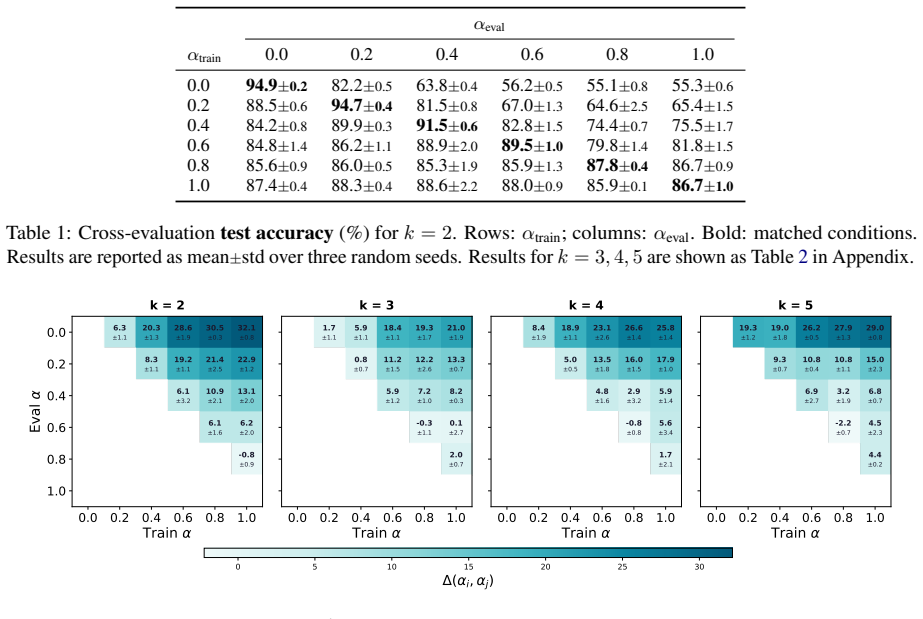
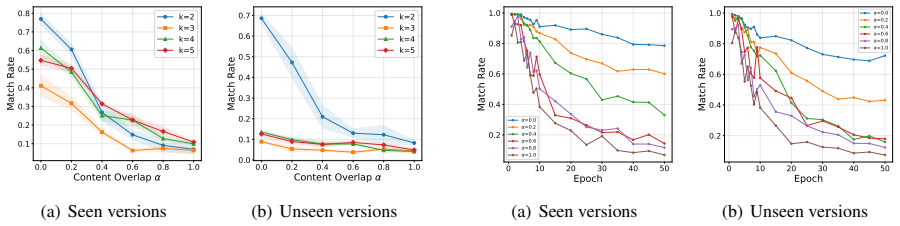
We define the overlap parameter α as the normalized residual of mutual information between content identity and style label, ranging from no shared content (α=0) to fully shared content (α=1). Cross-overlap evaluation of RoBERTa-based classifiers shows that low-overlap models degrade when content cues are removed, while high-overlap models transfer more robustly. A cross-style content retrieval probe further shows that content becomes less recoverable as α increases, with training dynamics showing this removal occurs gradually.
What carries the argument
the overlap parameter α defined as the normalized residual of mutual information between content identity and style label, which sets the degree of shared content across style classes
If this is right
- Low-overlap models will exhibit clear performance drops when tested in regimes that eliminate content shortcuts.
- High-overlap models will maintain accuracy across varying content conditions.
- Content recoverability from the model will decrease steadily as alpha is raised during training.
- The alpha-controlled setup can serve as a repeatable test for whether any given style classifier depends on content or style signals.
Where Pith is reading between the lines
- The same overlap-control technique could be applied to other parallel text collections to test whether the diagnostic generalizes past religious corpora.
- If the method works, it suggests training objectives that explicitly penalize content leakage could produce more style-specific classifiers.
- Analogous controlled-overlap constructions might help diagnose shortcut learning in related tasks such as authorship attribution or sentiment detection.
Load-bearing premise
Parallel Bible translations supply sufficiently clean style variation while allowing precise manipulation of content overlap via the alpha definition without introducing uncontrolled confounds.
What would settle it
If low-alpha trained classifiers show no greater degradation than high-alpha classifiers once content cues are removed, or if content retrieval accuracy stays constant across alpha levels.
Figures

read the original abstract
Style classifiers can use content cues that correlate with style labels in naturally collected data, yet we lack a systematic way to measure this reliance. We study this problem with a controlled content overlap setup built on parallel Bible translations. Specifically, we define the overlap parameter $\alpha$ as the normalized residual of mutual information between content identity and style label, so that it measures how much content is shared across style classes: from no shared content ($\alpha=0$) to fully shared content ($\alpha=1$). Cross-overlap evaluation of RoBERTa-based classifiers shows that low-overlap models degrade when content cues are removed, while high-overlap models transfer more robustly. A cross-style content retrieval probe further shows that content becomes less recoverable as $\alpha$ increases, with training dynamics showing this removal occurs gradually. Together, these results suggest that controlled overlap provides a simple diagnostic for separating style learning from content shortcuts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that style classifiers often exploit content cues correlated with style labels in natural data, and introduces a controlled content overlap setup using parallel Bible translations. It defines the overlap parameter α as the normalized residual mutual information between content identity (verse ID) and style label (translation version), ranging from no shared content (α=0) to fully shared content (α=1). Cross-overlap evaluation of RoBERTa classifiers shows low-α models degrade when content cues are removed while high-α models transfer robustly; a cross-style content retrieval probe shows content recoverability decreases with α, with training dynamics indicating gradual removal. The results position controlled overlap as a diagnostic for separating style learning from content shortcuts.
Significance. If the central claim holds, the work supplies a practical, controllable diagnostic for a persistent issue in style classification and related NLP tasks. The empirical patterns on cross-overlap degradation and the retrieval probe, together with the observation of gradual removal during training, provide concrete evidence that the method can surface reliance on content shortcuts. The approach is simple enough to be reusable beyond Bible data if the core construction generalizes.
major comments (1)
- [Abstract and α definition] Abstract and the α definition (presumably §3): the construction normalizes residual MI between verse ID and version label so that α=1 is described as fully shared content, yet parallel translations of the same verse routinely differ in lexical choice, phrasing, and minor semantic shading that are systematic per version. These differences remain available as content cues correlated with the style label even when verse identity is held constant, so the reported cross-overlap degradation and retrieval-probe results may reflect removal of these residual cues rather than isolation of stylistic features. This directly affects the load-bearing claim that high-α models learn style robustly.
minor comments (2)
- The abstract reports directional results on degradation and retrieval without reference to error bars, confidence intervals, or statistical tests; these should be added to the results and figures for the cross-overlap and probe experiments.
- Notation for the normalized residual MI should be given explicitly as an equation (with the exact normalization formula) rather than described only in prose, to allow exact reproduction of the α construction.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a key subtlety in the α construction. We respond to the comment below and will revise the manuscript to address it.
read point-by-point responses
-
Referee: [Abstract and α definition] Abstract and the α definition (presumably §3): the construction normalizes residual MI between verse ID and version label so that α=1 is described as fully shared content, yet parallel translations of the same verse routinely differ in lexical choice, phrasing, and minor semantic shading that are systematic per version. These differences remain available as content cues correlated with the style label even when verse identity is held constant, so the reported cross-overlap degradation and retrieval-probe results may reflect removal of these residual cues rather than isolation of stylistic features. This directly affects the load-bearing claim that high-α models learn style robustly.
Authors: We agree that parallel translations of the same verse are not lexically identical and that version-specific lexical choices and minor semantic differences persist even at α=1. Our α parameter is defined strictly in terms of normalized residual mutual information between verse identity (content ID) and translation version; it therefore controls overlap at the level of verse identity but does not eliminate all possible lexical or phrasing cues that remain correlated with version. This is a genuine limitation of the construction. In the revised manuscript we will (1) clarify the precise scope of α in §3, (2) add an explicit limitations paragraph stating that residual lexical differences may still function as content shortcuts at high α, and (3) note that the observed robustness of high-α models should be interpreted as robustness to verse-level content overlap rather than to all possible content cues. We will also consider whether a follow-up probe isolating lexical residuals is feasible within the current experimental budget. revision: yes
Circularity Check
No circularity: empirical results on alpha-controlled datasets do not reduce to inputs by construction
full rationale
The paper defines the overlap parameter α explicitly from data statistics (normalized residual MI between verse ID and translation version) and then reports empirical classifier transfer accuracies and retrieval probe results across alpha levels. These outcomes are measured performance numbers that can vary with model training dynamics and are not forced to match the alpha definition or any fitted parameter. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify the central claim. The derivation chain consists of dataset construction followed by standard supervised training and evaluation, which remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mutual information between content identity and style label can be computed and normalized to produce a scalar overlap parameter alpha ranging from 0 to 1.
Reference graph
Works this paper leans on
-
[1]
Journal of the American Society for information Science and Technology , volume=
A survey of modern authorship attribution methods , author=. Journal of the American Society for information Science and Technology , volume=. 2009 , publisher=
2009
-
[2]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[3]
arXiv preprint arXiv:2104.08530 , year=
The topic confusion task: A novel scenario for authorship attribution , author=. arXiv preprint arXiv:2104.08530 , year=
-
[4]
Royal Society open science , volume=
Evaluating prose style transfer with the bible , author=. Royal Society open science , volume=. 2018 , publisher=
2018
-
[5]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Probing neural network comprehension of natural language arguments , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[6]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[7]
arXiv preprint arXiv:1907.11692 , year=
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
Pith/arXiv arXiv 1907
-
[8]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[9]
Computational Linguistics , volume=
Deep learning for text style transfer: A survey , author=. Computational Linguistics , volume=
-
[10]
Conneau, Alexis and Kruszewski, German and Lample, Guillaume and Barrault, Lo. What you can cram into a single \ & ! \# * vector: Probing sentence embeddings for linguistic properties. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1198
-
[11]
1999 , publisher=
Elements of information theory , author=. 1999 , publisher=
1999
-
[12]
2007 15th European signal processing conference , pages=
The effective rank: A measure of effective dimensionality , author=. 2007 15th European signal processing conference , pages=. 2007 , organization=
2007
-
[13]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Explore spurious correlations at the concept level in language models for text classification , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[14]
, author=
Investigating Topic Influence in Authorship Attribution. , author=. PAN , year=
-
[15]
Language resources and evaluation , volume=
A massively parallel corpus: the bible in 100 languages , author=. Language resources and evaluation , volume=. 2015 , publisher=
2015
-
[16]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Evaluating the evaluation metrics for style transfer: A case study in multilingual formality transfer , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.