Legal Domain Adaptation of Modern BERT Models
Pith reviewed 2026-06-30 01:21 UTC · model grok-4.3
The pith
Further pre-training ModernBERT on US court opinions yields significant gains on legal tasks even after its initial large-scale training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
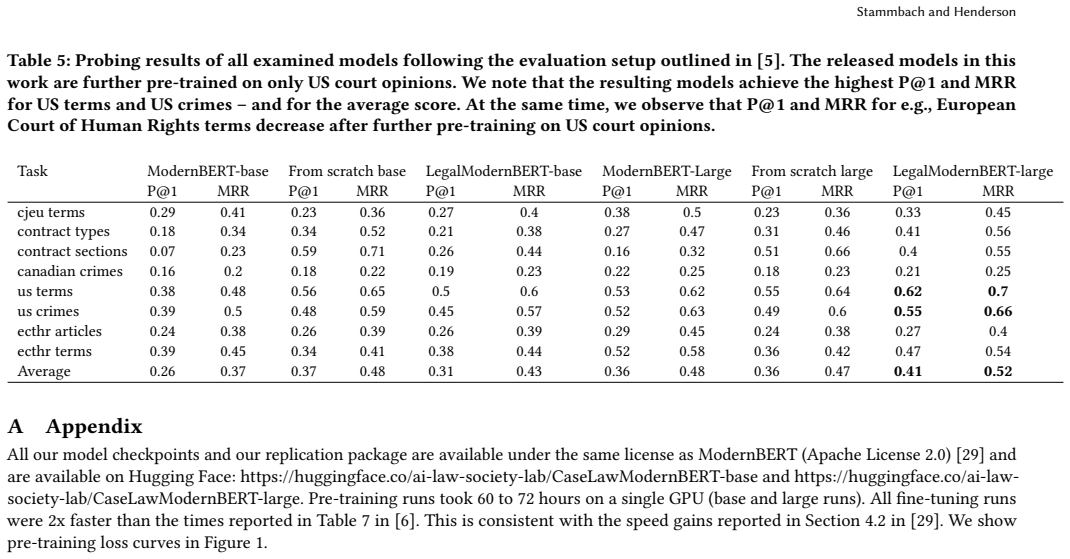
Although ModernBERT has been trained on roughly 500x more data than original BERT, further pre-training on all US court opinions using the masked language modeling objective produces significant improvements compared to vanilla ModernBERT on all datasets connected to US court opinions, with gains similar to those reported in early work on domain adaptation of BERT-like models; from-scratch pre-training does not match the performance of further pre-training an existing checkpoint.
What carries the argument
Continued pre-training via the masked language modeling objective on the full set of US court opinions, which adapts representations for legal content while preserving the model's native capacity for sequences up to 8,192 tokens.
If this is right
- Significant improvements over vanilla ModernBERT on every tested dataset tied to US court opinions.
- Gains of the same magnitude as those found in early domain-adaptation experiments with BERT-like models.
- From-scratch pre-training on the same legal corpus underperforms adaptation of an existing ModernBERT checkpoint.
- The adapted models support computation of embeddings for legal passages and rapid reranking of hundreds of passages per query.
- All resulting checkpoints are released for public use.
Where Pith is reading between the lines
- The same continued-pre-training recipe could be tested on other narrow domains such as medicine or finance.
- The 8k-token context length opens the possibility of processing entire long legal documents in a single pass rather than chunking.
- Efficiency comparisons between adapting existing large models versus training new ones from scratch become relevant for resource planning.
- Downstream legal applications may now incorporate these embeddings for retrieval or classification without additional fine-tuning data.
Load-bearing premise
That masked language modeling on court opinions will produce better representations for downstream legal tasks.
What would settle it
No measurable improvement on the US court opinion datasets, or equivalent results from a from-scratch model, would falsify the benefit of further pre-training.
Figures
read the original abstract
We investigate domain adaptation of modern BERT models in the legal domain. We further pre-train ModernBERT on all US court opinions using the masked language modeling objective. Although ModernBERT has been trained on roughly 500x more data than original BERT, we still find that this model benefits from further pre-training and domain adaptation in the legal domain: we report significant improvements compared to vanilla ModernBERT on all datasets connected to US court opinions. We find gains similar to those reported in early work on domain adaptation of BERT-like models. However, from scratch pre-training does not match the performance of further pre-training an existing ModernBERT checkpoint in our experiments. The resulting models are capable of processing sequences up to 8,192 tokens, and can be used to compute meaningful embeddings of legal passages, or could quickly rerank hundreds of legal passages for a given search query. We release all model checkpoints publicly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that further pre-training ModernBERT on US court opinions via masked language modeling produces significant gains over the vanilla checkpoint on legal downstream tasks, with gains comparable to early BERT domain-adaptation results; from-scratch pre-training underperforms continued pre-training; the resulting models support 8192-token sequences and are released publicly for embedding and reranking use cases.
Significance. If the empirical claims hold after details are supplied, the work would show that domain adaptation can still be useful even after 500x more pre-training data than original BERT, with direct utility for legal NLP. The public release of checkpoints is a clear strength for reproducibility.
major comments (3)
- [Abstract] Abstract: the central claim of 'significant improvements compared to vanilla ModernBERT on all datasets connected to US court opinions' is unsupported by any reported corpus size, token count, training steps, learning-rate schedule, batch size, statistical tests, or variance across runs, making it impossible to verify whether domain adaptation (rather than extra compute) is responsible.
- [Abstract] Abstract: the statement that 'from scratch pre-training does not match the performance of further pre-training' lacks confirmation that equivalent total training budget, optimizer settings, or data volume were used in the from-scratch run, which is load-bearing for the claim that continued pre-training of an existing checkpoint is preferable.
- [Abstract] Abstract: no ablation or control experiment is described that holds total compute fixed while varying only domain specificity, leaving open the possibility that observed gains are explained by optimization differences or additional steps rather than the legal corpus.
minor comments (2)
- The phrase 'all datasets connected to US court opinions' is vague; explicit dataset names, sizes, and task formulations would improve clarity.
- Consider adding a results table with exact metrics, baselines, and significance markers to replace the qualitative 'significant improvements' phrasing.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the need for greater experimental transparency. We will revise the manuscript to expand the abstract and add a methods section with the requested details on training configuration, corpus statistics, and controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'significant improvements compared to vanilla ModernBERT on all datasets connected to US court opinions' is unsupported by any reported corpus size, token count, training steps, learning-rate schedule, batch size, statistical tests, or variance across runs, making it impossible to verify whether domain adaptation (rather than extra compute) is responsible.
Authors: We agree that the abstract does not currently report these details. In the revision we will add the US court opinions corpus size in tokens, total training steps, learning-rate schedule, batch size, results with standard deviation across runs, and statistical significance tests. These additions will allow readers to assess whether the gains stem from domain adaptation rather than extra compute. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'from scratch pre-training does not match the performance of further pre-training' lacks confirmation that equivalent total training budget, optimizer settings, or data volume were used in the from-scratch run, which is load-bearing for the claim that continued pre-training of an existing checkpoint is preferable.
Authors: The referee is correct that the abstract omits explicit confirmation of matched budgets. We will revise the text to state that the from-scratch run used an equivalent total training budget, identical optimizer settings, and the same data volume as the continued pre-training run; full hyperparameter tables will be added to the methods section. revision: yes
-
Referee: [Abstract] Abstract: no ablation or control experiment is described that holds total compute fixed while varying only domain specificity, leaving open the possibility that observed gains are explained by optimization differences or additional steps rather than the legal corpus.
Authors: We acknowledge the value of an explicit ablation that isolates domain specificity while holding total compute constant. Our existing from-scratch versus continued-pretraining comparison already matches total compute and data volume; we will expand the discussion to clarify this control and explicitly note the remaining limitations. If space allows we will add a short additional control experiment. revision: partial
Circularity Check
No circularity: empirical domain-adaptation results rest on measured performance, not derivations or self-referential fits
full rationale
The paper is an empirical report of continued pre-training of ModernBERT on US court opinions via masked language modeling, followed by evaluation on legal datasets. No equations, uniqueness theorems, or first-principles derivations are present; performance gains are stated as direct experimental measurements. The central claim (further pre-training yields improvements) is not reduced to fitted parameters by construction, nor does it rely on self-citation chains for load-bearing premises. This matches the default case of a self-contained empirical study with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Masked language modeling pre-training on domain-specific text improves model representations for downstream tasks in that domain
Reference graph
Works this paper leans on
-
[1]
Abubakar Abid, Maheen Farooqi, and James Zou. 2021. Persistent anti-muslim bias in large language models. InProceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society. 298–306. https://dl.acm.org/doi/abs/10.1145/3461702. 3462624
-
[2]
Elliott Ash, Aniket Kesari, Suresh Naidu, Lena Song, and Dominik Stammbach
-
[3]
InProceedings of the Symposium on Computer Science and Law(Boston, MA, USA)(CSLA W ’24)
Translating Legalese: Enhancing Public Understanding of Court Opinions with Legal Summarizers. InProceedings of the Symposium on Computer Science and Law(Boston, MA, USA)(CSLA W ’24). Association for Computing Machinery, New York, NY, USA, 136–157. doi:10.1145/3614407.3643700
-
[4]
Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. SciBERT: A Pretrained Language Model for Scientific Text. InProceedings of the 2019 Conference on Empirical Meth- ods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (Eds.). Association ...
-
[5]
Ilias Chalkidis, Manos Fergadiotis, Prodromos Malakasiotis, Nikolaos Aletras, and Ion Androutsopoulos. 2020. LEGAL-BERT: The Muppets straight out of Law School. InFindings of the Association for Computational Linguistics: EMNLP 2020, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational Linguistics, Online, 2898–2904. doi:10.18653/v1/2...
-
[6]
Ilias Chalkidis, Nicolas Garneau, Catalina Goanta, Daniel Katz, and Anders Søgaard. 2023. LeXFiles and LegalLAMA: Facilitating English Multinational Legal Language Model Development. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Toronto, Canada,...
2023
-
[7]
Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion Androut- sopoulos, Daniel Katz, and Nikolaos Aletras. 2022. LexGLUE: A Benchmark Dataset for Legal Language Understanding in English. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Smaranda Muresan, Preslav Nakov, and Aline...
-
[8]
Inyoung Cheong, Patty Liu, Dominik Stammbach, and Peter Henderson. 2026. How Can AI Augment Access to Justice? Public Defenders’ Perspectives on AI Adoption. arXiv:2510.22933 [cs.CY] https://arxiv.org/abs/2510.22933
Pith/arXiv arXiv 2026
-
[9]
Inyoung Cheong, King Xia, KJ Kevin Feng, Quan Ze Chen, and Amy X Zhang
-
[10]
InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency
(A) I am not a lawyer, but...: engaging legal experts towards responsible LLM policies for legal advice. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency. 2454–2469
2024
-
[11]
Tri Dao. 2023. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. arXiv:2307.08691 [cs.LG] https://arxiv.org/abs/2307.08691
Pith/arXiv arXiv 2023
-
[12]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burstein, Christy...
2019
-
[13]
Ricardo Dominguez-Olmedo, Vedant Nanda, Rediet Abebe, Stefan Bechtold, Christoph Engel, Jens Frankenreiter, Krishna Gummadi, Moritz Hardt, and Michael Livermore. 2024. Lawma: The Power of Specialization for Legal Tasks. arXiv:2407.16615 [cs.CL] https://arxiv.org/abs/2407.16615
arXiv 2024
-
[14]
Aran Komatsuzaki Enrico Shippole. 2024. Cleaned Caselaw Access Project. https://huggingface.co/datasets/TeraflopAI/Caselaw_Access_Project
2024
-
[15]
Adam Feldman. 2018. Empirical SCOTUS: An opinion is worth at least a thousand words (Corrected). https://www.scotusblog.com/2018/04/empirical-scotus-an- opinion-is-worth-at-least-a-thousand-words/ SCOTUSblog, Accessed: 2025-02- 01
2018
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and et al. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[17]
Krass, Lucia Zheng, Neel Guha, Christopher D
Peter Henderson, Mark S. Krass, Lucia Zheng, Neel Guha, Christopher D. Man- ning, Dan Jurafsky, and Daniel E. Ho. 2022. Pile of Law: Learning Respon- sible Data Filtering from the Law and a 256GB Open-Source Legal Dataset. https://arxiv.org/abs/2207.00220
arXiv 2022
-
[18]
Harvard Library Innovation Lab. 2024. Cold Cases Dataset. https://huggingface. co/datasets/harvard-lil/cold-cases Accessed: 2025-02-01
2024
-
[19]
Li Lucy and David Bamman. 2021. Gender and representation bias in GPT-3 gen- erated stories. InProceedings of the Third Workshop on Narrative Understanding. 48–55. https://aclanthology.org/2021.nuse-1.5/
2021
-
[20]
Robert Mahari, Dominik Stammbach, Elliott Ash, and Alex Pentland. 2023. The Law and NLP: Bridging Disciplinary Disconnects. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 3445–
2023
-
[21]
doi:10.18653/v1/2023.findings-emnlp.224
-
[22]
Robert Mahari, Dominik Stammbach, Elliott Ash, and Alex Pentland. 2024. LePaRD: A Large-Scale Dataset of Judicial Citations to Precedent. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Ban...
-
[23]
Joel Niklaus, Veton Matoshi, Matthias Stürmer, Ilias Chalkidis, and Daniel E. Ho. 2024. MultiLegalPile: A 689GB Multilingual Legal Corpus. arXiv:2306.02069 [cs.CL] https://arxiv.org/abs/2306.02069
arXiv 2024
-
[24]
McCarthy, Christopher Hahn, Brian M
Joel Niklaus, Lucia Zheng, Arya D. McCarthy, Christopher Hahn, Brian M. Rosen, Peter Henderson, Daniel E. Ho, Garrett Honke, Percy Liang, and Christopher Man- ning. 2025. LawInstruct: A Resource for Studying Language Model Adaptation to the Legal Domain. arXiv:2404.02127 [cs.CL] https://arxiv.org/abs/2404.02127
arXiv 2025
-
[25]
Travisano
Adam Paine and Robert M. Travisano. 2025. Discovery Pitfalls in the Age of AI. https://techcrunch.com/2025/07/25/sam-altman-warns-theres-no-legal- confidentiality-when-using-chatgpt-as-a-therapist/.Epstein Becker Green(Sep- tember 2025)
2025
-
[26]
Jacob Portes, Alex Trott, Sam Havens, Daniel King, Abhinav Venigalla, Moin Nadeem, Nikhil Sardana, Daya Khudia, and Jonathan Frankle. 2023. MosaicBERT: a bidirectional encoder optimized for fast pretraining. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., ...
2023
-
[27]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Em- pirical Methods in Natural Language Processing. Association for Computational Linguistics. https://arxiv.org/abs/1908.10084
Pith/arXiv arXiv 2019
-
[28]
Spaeth, Lee Epstein, Jeffrey A
Harold J. Spaeth, Lee Epstein, Jeffrey A. Segal, Andrew D. Martin, Theodore J. Ruger, and Sara C. Benesh. 2020. Supreme Court Database, Version 2020 Release
2020
-
[29]
Accessed: 2025-02-01
Washington University Law. Accessed: 2025-02-01
2025
-
[30]
Dominik Stammbach, Kylie Zhang, Patty Liu, Nimra Nadeem, Inyoung Cheong, Lucia Zheng, and Peter Henderson. 2026. Legal Retrieval for Public Defenders. arXiv:2601.14348 [cs.IR] https://arxiv.org/abs/2601.14348
Pith/arXiv arXiv 2026
-
[31]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. RoFormer: Enhanced transformer with Rotary Position Embedding. Neurocomputing568 (2024), 127063. doi:10.1016/j.neucom.2023.127063
-
[32]
Yi Tay, Vinh Q. Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, Tal Schuster, William W. Cohen, and Donald Metzler. 2022. Transformer Memory as a Differentiable Search Index. arXiv:2202.06991 [cs.CL] https://arxiv.org/abs/2202.06991
arXiv 2022
-
[33]
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hall- ström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Nathan Cooper, Griffin Adams, Jeremy Howard, and Iacopo Poli. 2024. Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Infer...
Pith/arXiv arXiv 2024
-
[34]
Nicolas Webersinke, Mathias Kraus, Julia Anna Bingler, and Markus Leippold
-
[35]
arXiv:2110.12010 [cs.CL] https://arxiv.org/abs/2110.12010
ClimateBert: A Pretrained Language Model for Climate-Related Text. arXiv:2110.12010 [cs.CL] https://arxiv.org/abs/2110.12010
-
[36]
Anderson, Peter Henderson, and Daniel E
Lucia Zheng, Neel Guha, Brandon R. Anderson, Peter Henderson, and Daniel E. Ho. 2021. When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset. arXiv:2104.08671 [cs.CL] https://arxiv.org/abs/ 2104.08671
arXiv 2021
-
[37]
Manning, Peter Henderson, and Daniel E
Lucia Zheng, Neel Guha, Javokhir Arifov, Sarah Zhang, Michal Skreta, Christo- pher D. Manning, Peter Henderson, and Daniel E. Ho. 2025. A Reasoning-Focused Legal Retrieval Benchmark. InProceedings of the 2025 Symposium on Computer Science and Law(Munich, Germany)(CSLA W ’25). Association for Computing Machinery, New York, NY, USA, 169–193. doi:10.1145/370...
-
[38]
Haoxi Zhong, Chaojun Xiao, Cunchao Tu, Tianyang Zhang, Zhiyuan Liu, and Maosong Sun. 2020. How Does NLP Benefit Legal System: A Summary of Legal Artificial Intelligence. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computati...
-
[39]
Liu Zhuang, Lin Wayne, Shi Ya, and Zhao Jun. 2021. A Robustly Optimized BERT Pre-training Approach with Post-training. InProceedings of the 20th Chinese National Conference on Computational Linguistics, Sheng Li, Maosong Sun, Yang Liu, Hua Wu, Kang Liu, Wanxiang Che, Shizhu He, and Gaoqi Rao (Eds.). Chinese Information Processing Society of China, Huhhot,...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.