There and Back Again: A Flexible-Frame Transformer for Multi-Exposure Fusion
Pith reviewed 2026-06-30 09:54 UTC · model grok-4.3
The pith
A new transformer fuses any number of exposure frames for high-dynamic-range imaging without retraining or model changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
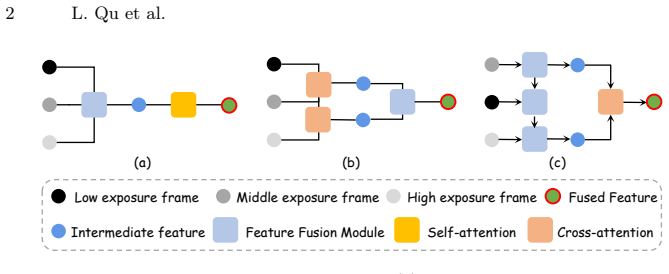
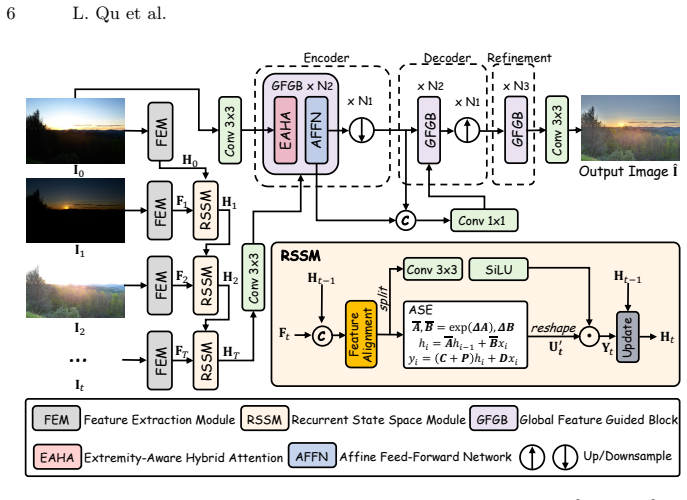
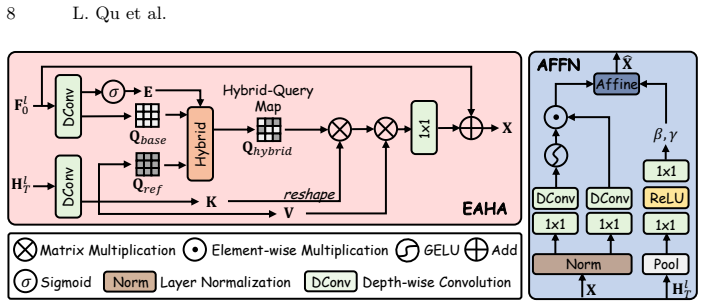
FreeMEF is the first flexible-frame transformer for multi-exposure fusion. It uses a recurrent state space module to fuse features from arbitrary-length exposure sequences via adaptive alignment and state-space recurrence, supplying global guidance, and a global feature guided block that combines extremity-aware hybrid attention with an affine-injection feed-forward network to resolve similarity paradoxes while regulating contrast and brightness.
What carries the argument
Recurrent state space module (RSSM) that sequentially fuses arbitrary-length feature sequences, paired with global feature guided block (GFGB) containing extremity-aware hybrid attention (EAHA) and affine-injection feed-forward network (AFFN).
If this is right
- Deployment systems no longer need to store and switch between multiple fixed-frame fusion models.
- A single trained network can process scenes captured with two, three, four, or more exposures.
- The same architecture works for both short and long exposure stacks without architectural modification.
- Global information guidance from the recurrent module improves fusion consistency across varying input counts.
Where Pith is reading between the lines
- The approach could extend to other variable-length multi-frame tasks such as burst denoising or video deblurring if the state-space recurrence generalizes.
- Real-time mobile HDR pipelines could adopt a single lightweight model instead of frame-count-specific variants.
- Training data collection can focus on diverse exposure combinations rather than balancing separate datasets per frame count.
Load-bearing premise
The recurrent state space module and extremity-aware hybrid attention maintain performance for any input sequence length without retraining or quality loss.
What would settle it
Quantitative results on the three benchmark datasets showing measurable drops in PSNR, SSIM, or perceptual scores when the number of input frames differs from the training distribution.
Figures






read the original abstract
Multi-exposure fusion (MEF) brings the dynamic range of conventional cameras closer to that of human vision, producing images with rich scene content. Given the large variability in scene luminance, exposure strategies often require different numbers of frames to capture the full radiance range faithfully. However, conventional MEF techniques are typically designed for a fixed number of inputs, forcing deployment systems to maintain separate models for different frame-count requirements, which undermines deployment efficiency. To address this limitation, we propose FreeMEF, the first flexible-frame transformer for MEF that seamlessly accommodates varying numbers of input exposures without retraining or architectural changes. The proposed approach consists of two key modules. First, we introduce a recurrent state space module (RSSM) that sequentially fuses features from arbitrary sequences via adaptive alignment and state-space recurrent modeling, thereby providing global information guidance for the subsequent restoration. Second, we devise a global feature guided block (GFGB) incorporating an extremity-aware hybrid attention (EAHA) and an affine-injection feed-forward network (AFFN), which effectively resolves the similarity paradox while simultaneously optimizing contrast and brightness regulation. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our method, which performs favorably against state-of-the-art methods both quantitatively and qualitatively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FreeMEF, the first flexible-frame transformer for multi-exposure fusion (MEF). It claims to handle arbitrary numbers of input exposures without retraining or architectural modification via a recurrent state space module (RSSM) for sequential fusion with adaptive alignment and a global feature guided block (GFGB) containing extremity-aware hybrid attention (EAHA) and affine-injection feed-forward network (AFFN). The method is evaluated on three benchmark datasets and reported to outperform state-of-the-art approaches both quantitatively and qualitatively.
Significance. If the flexibility claim is substantiated, the work would address a practical deployment limitation in MEF by removing the need for multiple fixed-frame models. The application of recurrent state-space modeling to sequential fusion in this domain is a timely direction given recent SSM advances, and the extremity-aware attention mechanism targets a known fusion challenge.
major comments (2)
- [Abstract] Abstract: the central claim that RSSM enables seamless accommodation of arbitrary input sequence lengths without retraining or degradation is load-bearing, yet the abstract supplies no quantitative results, ablation studies on frame-count variation, or details on whether training explicitly varied the number of exposures; this leaves the flexibility assertion unevaluated.
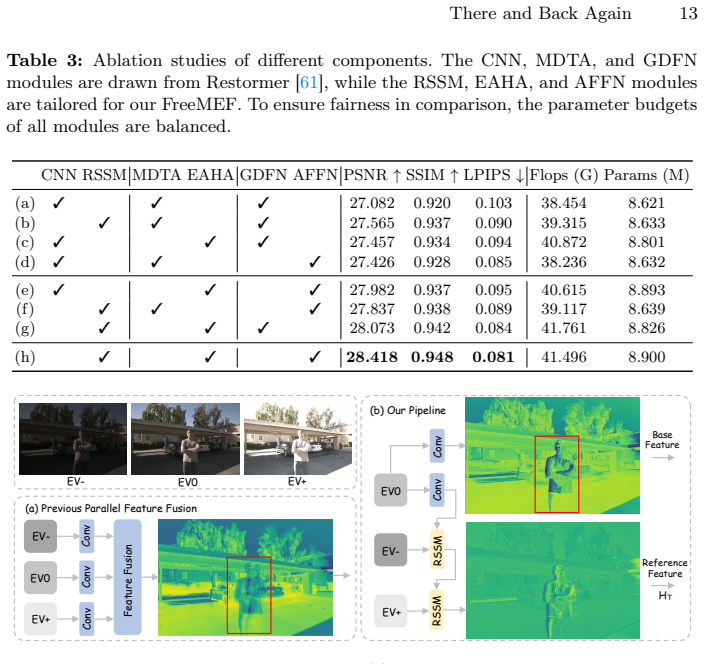
- [Method (RSSM module)] The description of RSSM sequential fusion via adaptive alignment and state-space recurrent modeling does not address potential progressive state dilution or misalignment for lengths far from the training distribution (e.g., 2 vs. 9+ frames), which directly undermines the 'arbitrary sequences' guarantee.
minor comments (1)
- [Abstract] The abstract states 'extensive experiments' but provides no metrics, tables, or implementation details; the full manuscript should include these to allow assessment of the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that RSSM enables seamless accommodation of arbitrary input sequence lengths without retraining or degradation is load-bearing, yet the abstract supplies no quantitative results, ablation studies on frame-count variation, or details on whether training explicitly varied the number of exposures; this leaves the flexibility assertion unevaluated.
Authors: The abstract provides a concise overview of the contribution and method. Quantitative evaluations and ablations on varying input frame counts are presented in the experimental section of the manuscript. To strengthen the abstract's support for the flexibility claim, we will revise it to include a brief reference to these results and the training procedure regarding exposure variation. revision: yes
-
Referee: [Method (RSSM module)] The description of RSSM sequential fusion via adaptive alignment and state-space recurrent modeling does not address potential progressive state dilution or misalignment for lengths far from the training distribution (e.g., 2 vs. 9+ frames), which directly undermines the 'arbitrary sequences' guarantee.
Authors: The RSSM employs state-space modeling specifically to support stable long-range dependencies with reduced dilution relative to standard recurrent architectures, combined with adaptive alignment for handling variable inputs. We agree that the current method description does not explicitly discuss or analyze edge cases of extreme sequence lengths. We will add a dedicated paragraph in the method section addressing these considerations along with supporting analysis or experiments on generalization. revision: yes
Circularity Check
No circularity: novel architecture with independent design choices
full rationale
The paper presents FreeMEF as a new transformer architecture consisting of explicitly introduced modules (RSSM for sequential fusion via adaptive alignment and state-space modeling; GFGB with EAHA and AFFN). No equations, fitted parameters, or predictions are shown that reduce by construction to inputs. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim of flexibility for arbitrary frame counts rests on the proposed design rather than renaming or re-deriving prior fitted results. This is a standard case of a self-contained architectural proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Afifi, M., Derpanis, K.G., Ommer, B., Brown, M.S.: Learning multi-scale photo exposure correction. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9157–9167 (2021)
2021
-
[2]
ACM Transactions on Graphics (TOG).26(3), 38–es (2007)
Akyüz, A.O., Fleming, R., Riecke, B.E., Reinhard, E., Bülthoff, H.H.: Do HDR displays support LDR content? A psychophysical evaluation. ACM Transactions on Graphics (TOG).26(3), 38–es (2007)
2007
-
[3]
Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint arXiv:1607.06450 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Bhat, G., Danelljan, M., Van Gool, L., Timofte, R.: Deep burst super-resolution. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9209–9218 (2021)
2021
-
[5]
IEEE Transactions on Image Processing (TIP).27(4), 2049–2062 (2018)
Cai, J., Gu, S., Zhang, L.: Learning a deep single image contrast enhancer from multi-exposure images. IEEE Transactions on Image Processing (TIP).27(4), 2049–2062 (2018)
2049
-
[6]
IEEE Transactions on Image Processing (TIP).31, 2661–2672 (2022)
Chen, J., Yang, Z., Chan, T.N., Li, H., Hou, J., Chau, L.P.: Attention-guided progressive neural texture fusion for high dynamic range image restoration. IEEE Transactions on Image Processing (TIP).31, 2661–2672 (2022)
2022
-
[7]
In: AAAI Conference on Artificial Intelligence (AAAI)
Chen, R., Zheng, B., Zhang, H., Chen, Q., Yan, C., Slabaugh, G., Yuan, S.: Im- proving dynamic hdr imaging with fusion transformer. In: AAAI Conference on Artificial Intelligence (AAAI). pp. 340–349 (2023)
2023
-
[8]
Chen, Z., Wang, Y., Cai, X., You, Z., Lu, Z., Zhang, F., Guo, S., Xue, T.: Ultrafu- sion:Ultrahighdynamicimagingusingexposurefusion.In:IEEE/CVFConference on Computer Vision and Pattern Recognition (CVPR). pp. 16111–16121 (2025)
2025
-
[9]
In: IEEE/CVF International Conference on Computer Vision (ICCV)
Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., Wei, Y.: Deformable convo- lutional networks. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 764–773 (2017)
2017
-
[10]
Towards In-Context Tone Style Transfer with A Large-Scale Triplet Dataset
Deng, Y., She, H., Shen, W., Li, M., Wu, R., Yuan, L., Li, X.: Towards in- context tone style transfer with a large-scale triplet dataset. arXiv preprint arXiv:2604.16114 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
In: European Conference on Computer Vision (ECCV)
Dong, C., Loy, C.C., He, K., Tang, X.: Learning a deep convolutional network for image super-resolution. In: European Conference on Computer Vision (ECCV). pp. 184–199 (2014)
2014
-
[12]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Dudhane, A., Zamir, S.W., Khan, S., Khan, F.S., Yang, M.H.: Burstormer: Burst image restoration and enhancement transformer. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5703–5712 (2023)
2023
-
[13]
In: ACM SIGGRAPH Annual Conference (SIGGRAPH)
Durand, F., Dorsey, J.: Fast bilateral filtering for the display of high-dynamic- range images. In: ACM SIGGRAPH Annual Conference (SIGGRAPH). pp. 257– 266 (2002)
2002
-
[14]
IEEE Micro18(03), 8–15 (1998)
Fossum, E.R.: Digital camera system on a chip. IEEE Micro18(03), 8–15 (1998)
1998
-
[15]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Gao, T., Guo, L., Zhao, S., Xu, P., Yang, Y., Liu, X., Wang, S., Zhu, S., Zhou, D.: Quantnas: Quantization-aware neural architecture search for efficient deployment on mobile device. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1704–1713 (2024)
2024
-
[16]
In: Advances in Neural Information Processing Systems (NeurIPS)
Ghasemabadi, A., Janjua, M.K., Salameh, M., Niu, D.: Learning truncated causal history model for video restoration. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 27584–27615 (2024)
2024
-
[17]
In: IEEE/CVF International Conference on Computer Vision (ICCV)
Girshick, R.: Fast r-cnn. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 1440–1448 (2015) There and Back Again 17
2015
-
[18]
In: Conference on Language Modeling (COLM) (2024)
Gu, A., Dao, T.: Mamba: Linear-time sequence modeling with selective state spaces. In: Conference on Language Modeling (COLM) (2024)
2024
-
[19]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Guo, H.,Guo,Y.,Zha,Y.,Zhang,Y.,Li,W.,Dai,T., Xia,S.T.,Li,Y.:Mambairv2: Attentive state space restoration. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 28124–28133 (2025)
2025
-
[20]
In: European Conference on Computer Vision (ECCV)
Guo, H., Li, J., Dai, T., Ouyang, Z., Ren, X., Xia, S.T.: Mambair: A simple base- line for image restoration with state-space model. In: European Conference on Computer Vision (ECCV). pp. 222–241 (2024)
2024
-
[21]
ACM Transactions on Graphics (TOG).35(6), 1–12 (2016)
Hasinoff, S.W., Sharlet, D., Geiss, R., Adams, A., Barron, J.T., Kainz, F., Chen, J., Levoy, M.: Burst photography for high dynamic range and low-light imaging on mobile cameras. ACM Transactions on Graphics (TOG).35(6), 1–12 (2016)
2016
-
[22]
Hu, J., Gallo, O., Pulli, K., Sun, X.: HDR deghosting: How to deal with saturation? In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1163–1170 (2013)
2013
-
[23]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Huang, D.A., Ramanathan, V., Mahajan, D., Torresani, L., Paluri, M., Fei-Fei, L., Niebles, J.C.: What makes a video a video: Analyzing temporal information in video understanding models and datasets. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7366–7375 (2018)
2018
-
[24]
In: IEEE/CVF International Conference on Computer Vi- sion (ICCV)
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive in- stance normalization. In: IEEE/CVF International Conference on Computer Vi- sion (ICCV). pp. 1501–1510 (2017)
2017
-
[25]
The Visual Computer30(5), 507–517 (2014)
Huo, Y., Yang, F., Dong, L., Brost, V.: Physiological inverse tone mapping based on retina response. The Visual Computer30(5), 507–517 (2014)
2014
-
[26]
Categorical Reparameterization with Gumbel-Softmax
Jang, E., Gu, S., Poole, B.: Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
In: IEEE/CVF International Conference on Computer Vision (ICCV)
Jiang, T., Wang, C., Li, X., Li, R., Fan, H., Liu, S.: Meflut: Unsupervised 1d lookup tables for multi-exposure image fusion. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10542–10551 (2023)
2023
-
[28]
ACM Transactions on Graphics (TOG).36(4), 144–155 (2017)
Kalantari, N.K., Ramamoorthi, R., et al.: Deep high dynamic range imaging of dynamic scenes. ACM Transactions on Graphics (TOG).36(4), 144–155 (2017)
2017
-
[29]
In: European Conference on Computer Vision (ECCV)
Kim, T.H., Sajjadi, M.S., Hirsch, M., Scholkopf, B.: Spatio-temporal transformer network for video restoration. In: European Conference on Computer Vision (ECCV). pp. 106–122 (2018)
2018
-
[30]
In: European Conference on Computer Vision (ECCV)
Kong, L., Li, B., Xiong, Y., Zhang, H., Gu, H., Chen, J.: Safnet: Selective alignment fusion network for efficient hdr imaging. In: European Conference on Computer Vision (ECCV). pp. 256–273 (2024)
2024
-
[31]
In: Brazilian Symposium on Computer Graphics and Image Processing (SIBGRAPI)
Kovaleski, R.P., Oliveira, M.M.: High-quality reverse tone mapping for a wide range of exposures. In: Brazilian Symposium on Computer Graphics and Image Processing (SIBGRAPI). pp. 49–56 (2014)
2014
-
[32]
In: Advances in Neural Information Processing Systems (NeurIPS)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep con- volutional neural networks. In: Advances in Neural Information Processing Systems (NeurIPS). (2012)
2012
-
[33]
Nature.521(7553), 436–444 (2015)
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature.521(7553), 436–444 (2015)
2015
-
[34]
IEEE Transactions on Image Processing (TIP)
Li,H.,Ma,K.,Yong,H.,Zhang,L.:Fastmulti-scalestructuralpatchdecomposition for multi-exposure image fusion. IEEE Transactions on Image Processing (TIP). 29, 5805–5816 (2020)
2020
-
[35]
In: IEEE/CVF International Conference on Computer Vision (ICCV)
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Wang, L., Qiao, Y.: Uniformerv2: Unlocking the potential of image vits for video understanding. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 1632–1643 (2023) 18 L. Qu et al
2023
-
[36]
In: IEEE/CVF International Confer- ence on Computer Vision (ICCV)
Li, X., Ni, Z., Yang, W.: Afunet: Cross-iterative alignment-fusion synergy for hdr reconstruction via deep unfolding paradigm. In: IEEE/CVF International Confer- ence on Computer Vision (ICCV). pp. 10666–10675 (2025)
2025
-
[37]
In: Advances in Neural Information Processing Systems (NeurIPS)
Li, Y., Fang, C., Yang, J., Wang, Z., Lu, X., Yang, M.H.: Universal style transfer via feature transforms. In: Advances in Neural Information Processing Systems (NeurIPS). (2017)
2017
-
[38]
arXiv preprint arXiv:2410.12274 (2024)
Liang, P., Jiang, J., Ma, Q., Liu, X., Ma, J.: Fusion from decomposition: A self- supervised approach for image fusion and beyond. arXiv preprint arXiv:2410.12274 (2024)
-
[39]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Liu, S., Zhang, X., Sun, L., Liang, Z., Zeng, H., Zhang, L.: Joint hdr denoising and fusion: A real-world mobile hdr image dataset. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13966–13975 (2023)
2023
-
[40]
arXiv preprint arXiv:2403.10376 (2024)
Liu, X., Li, A., Wu, Z., Du, Y., Zhang, L., Zhang, Y., Timofte, R., Zhu, C.: Pasta: Towards flexible and efficient hdr imaging via progressively aggregated spatio- temporal alignment. arXiv preprint arXiv:2403.10376 (2024)
-
[41]
In: Advances in Neural Information Processing Systems (NeurIPS)
Liu, Y., Tian, Y., Zhao, Y., Yu, H., Xie, L., Wang, Y., Ye, Q., Jiao, J., Liu, Y.: Vmamba: Visual state space model. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 103031–103063 (2024)
2024
-
[42]
In: IEEE/CVF International Conference on Computer Vision (ICCV)
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10012–10022 (2021)
2021
-
[43]
In: European Conference on Computer Vision (ECCV)
Liu, Z., Wang, Y., Zeng, B., Liu, S.: Ghost-free high dynamic range imaging with context-aware transformer. In: European Conference on Computer Vision (ECCV). pp. 344–360 (2022)
2022
-
[44]
In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR). pp. 3431–3440 (2015)
2015
-
[45]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Luo, Z., Li, Y., Cheng, S., Yu, L., Wu, Q., Wen, Z., Fan, H., Sun, J., Liu, S.: Bsrt: Improving burst super-resolution with swin transformer and flow-guided de- formable alignment. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 998–1008 (2022)
2022
-
[46]
IEEE Transactions on Image Processing (TIP).26(5), 2519–2532 (2017)
Ma, K., Li, H., Yong, H., Wang, Z., Meng, D., Zhang, L.: Robust multi-exposure image fusion: a structural patch decomposition approach. IEEE Transactions on Image Processing (TIP).26(5), 2519–2532 (2017)
2017
-
[47]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).37(6), 1219–1232 (2014)
Oh, T.H., Lee, J.Y., Tai, Y.W., Kweon, I.S.: Robust high dynamic range imag- ing by rank minimization. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).37(6), 1219–1232 (2014)
2014
-
[48]
In: IEEE International Conference on Image Processing (ICIP)
Pourreza-Shahri,R.,Kehtarnavaz,N.:Exposurebracketingviaautomaticexposure selection. In: IEEE International Conference on Image Processing (ICIP). pp. 320– 323 (2015)
2015
-
[49]
IEEE Transactions on Information Theory (TIT).57(3), 1675–1691 (2011)
Rachlin, Y., Negi, R., Khosla, P.K.: The sensing capacity of sensor networks. IEEE Transactions on Information Theory (TIT).57(3), 1675–1691 (2011)
2011
-
[50]
ACM Transactions on Graphics (TOG).21(3), 267—-276 (2002)
Reinhard, E., Stark, M., Shirley, P., Ferwerda, J.: Photographic tone reproduction for digital images. ACM Transactions on Graphics (TOG).21(3), 267—-276 (2002)
2002
-
[51]
ACM Transactions on Graphics (TOG).31(6), 203–1 (2012)
Sen, P., Kalantari, N.K., Yaesoubi, M., Darabi, S., Goldman, D.B., Shechtman, E.: Robust patch-based hdr reconstruction of dynamic scenes. ACM Transactions on Graphics (TOG).31(6), 203–1 (2012)
2012
-
[52]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Shu, Y., Shen, L., Hu, X., Li, M., Zhou, Z.: Towards real-world hdr video recon- struction: A large-scale benchmark dataset and a two-stage alignment network. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2879–2888 (2024) There and Back Again 19
2024
-
[53]
In: European Conference on Computer Vision (ECCV)
Song, J.W., Park, Y.I., Kong, K., Kwak, J., Kang, S.J.: Selective transhdr: Transformer-based selective hdr imaging using ghost region mask. In: European Conference on Computer Vision (ECCV). pp. 288–304 (2022)
2022
-
[54]
In: IEEE/CVF International Conference on Computer Vision (ICCV)
Tel, S., Wu, Z., Zhang, Y., Heyrman, B., Demonceaux, C., Timofte, R., Gin- hac, D.: Alignment-free hdr deghosting with semantics consistent transformer. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 12836– 12845 (2023)
2023
-
[55]
In: Advances in Neural Information Processing Systems (NeurIPS)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS). (2017)
2017
-
[56]
In: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR)
Wang, J., Chen, D., Luo, C., He, B., Yuan, L., Wu, Z., Jiang, Y.G.: Omnivid: A generative framework for universal video understanding. In: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). pp. 18209–18220 (2024)
2024
-
[57]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Wang, X., Chan, K.C., Yu, K., Dong, C., Change Loy, C.: Edvr: Video restoration with enhanced deformable convolutional networks. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 1954–1963 (2019)
1954
-
[58]
In: European Conference on Computer Vision (ECCV)
Wu, S., Xu, J., Tai, Y.W., Tang, C.K.: Deep high dynamic range imaging with large foreground motions. In: European Conference on Computer Vision (ECCV). pp. 117–132 (2018)
2018
-
[59]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).44(1), 502–518 (2020)
Xu, H., Ma, J., Jiang, J., Guo, X., Ling, H.: U2fusion: A unified unsupervised image fusion network. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).44(1), 502–518 (2020)
2020
-
[60]
In: IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR)
Yan, Q., Gong, D., Shi, Q., Hengel, A.v.d., Shen, C., Reid, I., Zhang, Y.: Attention- guided network for ghost-free high dynamic range imaging. In: IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 1751–1760 (2019)
2019
-
[61]
In: IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR)
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H.: Restormer: Efficient transformer for high-resolution image restoration. In: IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 5728–5739 (2022)
2022
-
[62]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).47(11), 10344–10360 (2025)
Zhou,S.,Pan,J.,Yang,J.:Learninganadaptivesparsetransformerforefficientim- age restoration. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).47(11), 10344–10360 (2025)
2025
-
[63]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhu, P., Sun, Y., Cao, B., Hu, Q.: Task-customized mixture of adapters for gen- eral image fufsion. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7099–7108 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.