Domination-Avoiding Learning Agents Cannot Collude
Pith reviewed 2026-06-28 16:21 UTC · model grok-4.3
The pith
Domination-avoiding agents provably cannot collude when selling in repeated pricing games.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
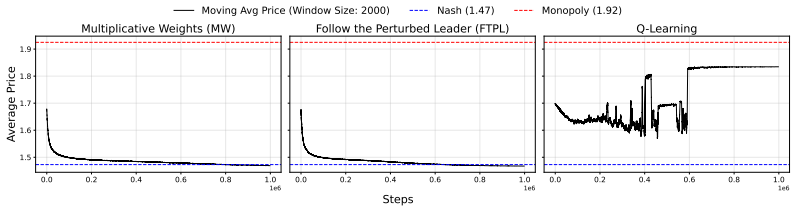
We identify a very general class of agents, which we term Domination-Avoiding agents, that provably do not collude in such markets. This class contains all Mean-Based agents and all internal-regret-minimizing agents, as well as others such as Multiplicative-Weight agents with variable learning rate and contextual variants thereof. More generally we show that, in any game, this class of agents is guaranteed to jointly learn to almost never play strategies that are eliminated by repeated elimination of purely dominated strategies.
What carries the argument
Domination-Avoiding agents: the property that an agent's sequence of play asymptotically places zero probability on any strategy eliminated by iterated strict dominance.
If this is right
- External-regret-minimizing agents can collude in the pricing market.
- Mean-based agents never collude.
- Internal-regret-minimizing agents never collude.
- Multiplicative-weights agents with variable learning rates never collude.
- In every finite game the agents jointly avoid all strategies removed by iterated elimination of strictly dominated strategies.
Where Pith is reading between the lines
- Market designers could require pricing algorithms to be internal-regret minimizers rather than external-regret minimizers to block collusion by construction.
- The separation between external and internal regret offers a concrete test for whether observed algorithmic collusion is driven by the regret notion rather than the market structure.
- The iterated-dominance guarantee may apply directly to other repeated games in which collusion is modeled as play of dominated joint strategies.
Load-bearing premise
The agent's update rule satisfies the domination-avoiding property that rules out play of iteratively dominated strategies.
What would settle it
An explicit construction or simulation in which a domination-avoiding agent places positive probability on an iteratively dominated strategy in the limit would falsify the central claim.
Figures
read the original abstract
An influential paper of Calvano et al. empirically demonstrated that Q-learning agents spontaneously collude when placed as sellers that compete on prices in a natural market model. More recent results of Fish et al. empirically demonstrated that similar collusion happens with commercial LLMs. We formally prove that such collusion can also happen with external-regret-minimizing agents. We identify a very general class of agents, which we term Domination-Avoiding agents, that provably do not collude in such markets. This class contains all Mean-Based agents and all internal-regret-minimizing agents, as well as others such as Multiplicative-Weight agents with variable learning rate and contextual variants thereof. More generally we show that, in any game, this class of agents is guaranteed to jointly learn to almost never play strategies that are eliminated by repeated elimination of purely dominated strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proves that external-regret-minimizing agents can collude in a Bertrand-style pricing market. It defines a broader class of Domination-Avoiding agents (containing all mean-based agents and all internal-regret minimizers, plus Multiplicative-Weights with variable rates and contextual variants) that provably do not collude in such markets. Separately, it shows that in any game these agents jointly play strategies eliminated by iterated elimination of strictly dominated strategies (IESDS) with probability approaching zero.
Significance. If the proofs hold, the result supplies a clean theoretical demarcation between classes of no-regret learners that can and cannot sustain collusion, directly addressing the empirical collusion observed with Q-learning and LLMs. The general game-theoretic guarantee on avoidance of IESDS strategies is a potentially useful contribution to the literature on learning in games.
major comments (1)
- [market non-collusion argument (following the general theorem)] The central non-collusion claim for the market model rests on the general IESDS-avoidance theorem. In standard discrete Bertrand pricing games the monopoly (collusive) price is typically rationalizable and survives IESDS. The manuscript must therefore contain an explicit additional step showing that any sustained collusive path requires positive probability on an IESDS-eliminated action; if the market result is obtained simply by invoking the general theorem, the implication is incomplete.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a point that requires clarification in the connection between our general result and the market application.
read point-by-point responses
-
Referee: [market non-collusion argument (following the general theorem)] The central non-collusion claim for the market model rests on the general IESDS-avoidance theorem. In standard discrete Bertrand pricing games the monopoly (collusive) price is typically rationalizable and survives IESDS. The manuscript must therefore contain an explicit additional step showing that any sustained collusive path requires positive probability on an IESDS-eliminated action; if the market result is obtained simply by invoking the general theorem, the implication is incomplete.
Authors: We agree that the general IESDS-avoidance theorem by itself does not rule out collusion if collusive prices survive IESDS. The manuscript's market non-collusion claim therefore requires an explicit additional argument establishing that any sustained collusive path in the discrete Bertrand model places positive limiting probability on an IESDS-eliminated action. We will add this step as a dedicated lemma in the market section of the revised manuscript. revision: yes
Circularity Check
No significant circularity; formal definition and proof chain is self-contained
full rationale
The paper defines a new class (Domination-Avoiding agents) and states two theorems: (1) external-regret minimizers can collude and (2) the larger class provably avoids IESDS-eliminated strategies in any game (hence does not collude in the market model). These are presented as formal results derived from the definition rather than from any fitted parameter, self-referential renaming, or load-bearing self-citation chain. No equation or step reduces the claimed non-collusion result to the input definition by construction; the derivation remains a standard mathematical argument from stated assumptions to conclusions.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of repeated normal-form games and regret minimization from prior literature
invented entities (1)
-
Domination-Avoiding agents
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gagan Aggarwal, Ashwinkumar Badanidiyuru, Santiago R. Balseiro, Kshipra Bhawalkar, Yuan Deng, Zhe Feng, Gagan Goel, Christopher Liaw, Haihao Lu, Mohammad Mahdian, Jieming 9 Mao, Aranyak Mehta, Vahab Mirrokni, Renato Paes Leme, Andres Perlroth, Georgios Piliouras, Jon Schneider, Ariel Schvartzman, Balasubramanian Sivan, Kelly Spendlove, Yifeng Teng, Di Wan...
2024
-
[2]
Cambridge University Press, 2015
Álvaro Cartea, Sebastian Jaimungal, and José Penalva.Algorithmic and high-frequency trading. Cambridge University Press, 2015
2015
-
[3]
Algorithmic pricing and competition: Empirical evidence from the german retail gasoline market.Journal of Political Economy, 132(3):723–771, 2024
Stephanie Assad, Robert Clark, Daniel Ershov, and Lei Xu. Algorithmic pricing and competition: Empirical evidence from the german retail gasoline market.Journal of Political Economy, 132(3):723–771, 2024
2024
-
[4]
An empirical analysis of algorithmic pricing on amazon marketplace
Le Chen, Alan Mislove, and Christo Wilson. An empirical analysis of algorithmic pricing on amazon marketplace. InProceedings of the 25th international conference on World Wide Web, pages 1339–1349, 2016
2016
-
[5]
Chaos in auto- bidding auctions.arXiv preprint arXiv:2602.09118, 2026
Ioannis Anagnostides, Ian Gemp, Georgios Piliouras, and Kelly Spendlove. Chaos in auto- bidding auctions.arXiv preprint arXiv:2602.09118, 2026. https://arxiv.org/abs/2602. 09118
-
[6]
Natalie Shapira, Chris Wendler, Avery Yen, Gabriele Sarti, Koyena Pal, Olivia Floody, Adam Belfki, Alex Loftus, Aditya Ratan Jannali, Nikhil Prakash, Jasmine Cui, Giordano Rogers, Jannik Brinkmann, Can Rager, Amir Zur, Michael Ripa, Aruna Sankaranarayanan, David Atkinson, Rohit Gandikota, Jaden Fiotto-Kaufman, EunJeong Hwang, Hadas Orgad, P Sam Sahil, Neg...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Artificial intelligence, algorithmic pricing, and collusion.American Economic Review, 110(10):3267– 3297, 2020
Emilio Calvano, Giacomo Calzolari, Vincenzo Denicolò, and Sergio Pastorello. Artificial intelligence, algorithmic pricing, and collusion.American Economic Review, 110(10):3267– 3297, 2020
2020
-
[8]
Q-learning.Machine learning, 8(3-4):279–292, 1992
Christopher JCH Watkins and Peter Dayan. Q-learning.Machine learning, 8(3-4):279–292, 1992
1992
-
[9]
MIT press, second edition, 2018
Richard S Sutton and Andrew G Barto.Reinforcement learning: An introduction. MIT press, second edition, 2018
2018
-
[10]
MIT Press, Cambridge, MA, 1991
Drew Fudenberg and Jean Tirole.Game Theory. MIT Press, Cambridge, MA, 1991
1991
-
[11]
Osborne and Ariel Rubinstein.A Course in Game Theory
Martin J. Osborne and Ariel Rubinstein.A Course in Game Theory. MIT Press, Cambridge, MA, 1994
1994
-
[12]
Sara Fish, Yannai A. Gonczarowski, and Shohini Kundu. Algorithmic collusion by large language models.arXiv preprint arXiv:2404.00806, 2024. https://arxiv.org/abs/2404. 00806
-
[13]
Hartline, Sheng Long, and Chenhao Zhang
Jason D. Hartline, Sheng Long, and Chenhao Zhang. Regulation of algorithmic collusion. In Proceedings of the 4th ACM Symposium on Computer Science and Law (CSLaw). Association for Computing Machinery, 2024
2024
-
[14]
Cambridge university press, 2006
Nicolò Cesa-Bianchi and Gábor Lugosi.Prediction, learning, and games. Cambridge university press, 2006
2006
-
[15]
Jason Hartline. The economics of no-regret learning algorithms.arXiv preprint arXiv:2601.22079, 2026.https://arxiv.org/abs/2601.22079
-
[16]
No regret learning in oligopolies: Cournot vs
Uri Nadav and Georgios Piliouras. No regret learning in oligopolies: Cournot vs. Bertrand. In International Symposium on Algorithmic Game Theory, pages 300–311. Springer, 2010
2010
-
[17]
Auctions between regret-minimizing agents
Yoav Kolumbus and Noam Nisan. Auctions between regret-minimizing agents. InProceedings of the ACM Web Conference 2022, WWW ’22, page 100–111, New York, NY , USA, 2022. Association for Computing Machinery. 10
2022
-
[18]
Correlated and coarse equilibria of single- item auctions
Michal Feldman, Brendan Lucier, and Noam Nisan. Correlated and coarse equilibria of single- item auctions. In Yang Cai and Adrian Vetta, editors,Web and Internet Economics, pages 131–144, 2016
2016
-
[19]
Algorithmic collusion without threats.arXiv preprint arXiv:2409.03956, 2024
Eshwar Ram Arunachaleswaran, Natalie Collina, Sampath Kannan, Aaron Roth, and Juba Ziani. Algorithmic collusion without threats.arXiv preprint arXiv:2409.03956, 2024. https: //arxiv.org/abs/2409.03956
-
[20]
Matthew Weinberg
Mark Braverman, Jieming Mao, Jon Schneider, and S. Matthew Weinberg. Selling to a no-regret buyer. InProceedings of the 19th ACM Conference on Economics and Computation (EC), pages 523–538. Association for Computing Machinery, 2018
2018
-
[21]
Nash convergence of mean-based learning algorithms in first price auctions
Xiaotie Deng, Xinyan Hu, Tao Lin, and Weiqiang Zheng. Nash convergence of mean-based learning algorithms in first price auctions. InProceedings of the ACM Web Conference 2022, WWW ’22, page 141–150, New York, NY , USA, 2022. Association for Computing Machinery
2022
-
[22]
Conver- gence analysis of no-regret bidding algorithms in repeated auctions.Proceedings of the AAAI Conference on Artificial Intelligence, 35(6):5399–5406, May 2021
Zhe Feng, Guru Guruganesh, Christopher Liaw, Aranyak Mehta, and Abhishek Sethi. Conver- gence analysis of no-regret bidding algorithms in repeated auctions.Proceedings of the AAAI Conference on Artificial Intelligence, 35(6):5399–5406, May 2021
2021
-
[23]
Martin Bichler, Julius Durmann, and Matthias Oberlechner. Online optimization algorithms in repeated price competition: Equilibrium learning and algorithmic collusion.arXiv preprint arXiv:2412.15707, 2024.https://arxiv.org/abs/2412.15707
-
[24]
MIT press, 1997
Jörgen W Weibull.Evolutionary game theory. MIT press, 1997
1997
-
[25]
Strategizing against no-regret learners
Yuan Deng, Jon Schneider, and Balasubramanian Sivan. Strategizing against no-regret learners. Advances in neural information processing systems, 32, 2019
2019
-
[26]
Regret analysis of stochastic and nonstochastic multi-armed bandit problems.Foundations and Trends in Machine Learning, 5(1):1–122, 2012
Sébastien Bubeck and Nicolò Cesa-Bianchi. Regret analysis of stochastic and nonstochastic multi-armed bandit problems.Foundations and Trends in Machine Learning, 5(1):1–122, 2012
2012
-
[27]
Attention in delay of gratification.Journal of Personality and Social Psychology, 16(2):329–337, 1970
Walter Mischel and Ebbe B Ebbesen. Attention in delay of gratification.Journal of Personality and Social Psychology, 16(2):329–337, 1970
1970
-
[28]
Doubling Trick
Simon P Anderson, André De Palma, and Jacques-François Thisse.Discrete choice theory of product differentiation. MIT press, 1992. A Classes of Domination-Avoiding Algorithms We establish the DA property for four broad classes of algorithms: Mean-Based dynamics (in- cluding finite-horizon variants via the Doubling Trick), the standard infinite-horizon Mult...
1992
-
[29]
A.2 Multiplicative Weights with Variable Learning Rate The Multiplicative Weights (MW) algorithm (Algorithm 1) is a cornerstone of online learning
Thus: UTA({dt(δ)})≤ ϵ 4 + ϵ 4 = ϵ 2 < ϵ This satisfies the Domination-Avoiding condition. A.2 Multiplicative Weights with Variable Learning Rate The Multiplicative Weights (MW) algorithm (Algorithm 1) is a cornerstone of online learning. While MW with a constant learning rate is Mean-Based and regret-minimizing in finite-horizon settings, it fails to achi...
-
[30]
Because the threshold boundaries expand symmetrically, p∗ inherently approaches the exact midpoint of the surviving interval. Consequently, for sufficiently dense grids, the maximum distance from the equilibrium to any surviving price tightens to a single ϵ, asymptotically confining the IESPDS set to[p ∗ −ϵ, p ∗ +ϵ]. We now provide the deferred proofs for...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.