Towards Error-Free Long Video Generation
Pith reviewed 2026-06-26 10:47 UTC · model grok-4.3
The pith
Finetuning a diffusion model first on short videos then with causal attention across clips plus T-RFlow produces minute-long videos without error accumulation or attribute drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
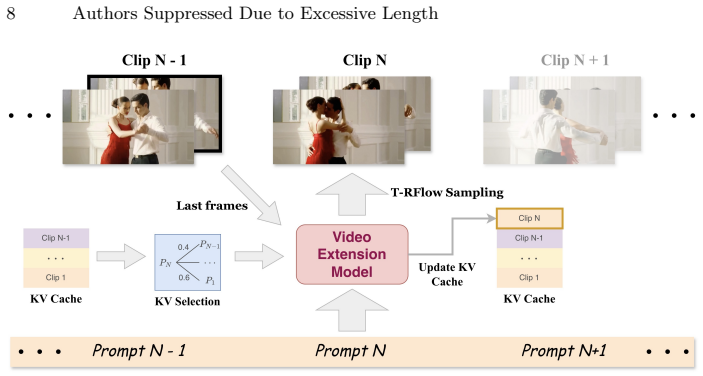
The framework first finetunes a diffusion model on large-scale short video data to serve as an autoregressive video extension model. It then continues finetuning with causal attention between clips on long video data so that tokens inside a clip receive bidirectional attention while tokens across clips receive only unidirectional attention. A KV cache keeps memory constant at inference time. The truncation-rectified flow technique is introduced to further reduce error accumulation, yielding high-quality, dynamic, identity-consistent videos at minute length.
What carries the argument
Causal attention computation between successive clips together with the truncation-rectified flow (T-RFlow) technique, which together preserve long-range context while retaining bidirectional modeling inside each short clip.
If this is right
- Causal attention lets the model exploit long-video data for training while keeping the strengths of modern diffusion models on short clips.
- KV caching makes inference memory independent of total video length.
- T-RFlow supplies an additional error-suppression mechanism beyond the attention change.
- The pipeline needs only short-video corpora for the first stage and modest long-video data for the second stage.
- Identity and motion consistency are maintained across minute-scale single-shot outputs.
Where Pith is reading between the lines
- The same causal-attention split might reduce drift in other autoregressive generators such as long audio or text sequences.
- Testing the method on multi-shot or variable-resolution videos would reveal whether the clip-boundary handling generalizes.
- An end-to-end training regime on mixed short and long data could be compared directly against the staged approach.
- Minute-scale coherent video opens direct use in simulation loops or narrative generation where current methods still require manual stitching.
Load-bearing premise
That the two-stage finetuning sequence with causal attention and T-RFlow will suppress error accumulation and attribute drift without introducing new inconsistencies that the model cannot correct.
What would settle it
Measure attribute consistency and perceptual quality on generated videos of steadily increasing length; if quality drops sharply after roughly 30-60 seconds the central claim is falsified.
Figures





read the original abstract
Recent advances in video generation have made minute-level synthesis possible; however, generating long videos remains challenging due to error accumulation, attribute drift, and the limited availability of long video data. In this paper, we introduce an infinite-length video generation framework that focusing on addressing these issues and produces high-quality, dynamic, and identity-consistent single-shot long videos. We first finetune a diffusion model as a video extension model on large-scale short video data to autoregressively generate temporally coherent clips. Inspired by the success of large language models (LLMs), we adopt causal attention computation between clips to further finetune this model on long video data. In this way, the tokens in one clip (short video) are computed by bidirectional attention while tokens among clips are computed by unidirectional attention. This design leverages the strengths of modern diffusion models while preserving long-term context information, effectively mitigating error accumulation and attribute drift. To achieve memory efficiency during inference, we adopt a key-value (KV) caching mechanism to maintain a constant KV memory. Furthermore, we introduce truncation-rectified flow (T-RFlow) technique to further suppress error accumulation. Experimental results demonstrate the effectiveness of our method. Our framework establishes a new benchmark for realistic and coherent minute-level video synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces an infinite-length video generation framework based on two-stage finetuning of a diffusion model: first on short-video data to enable autoregressive clip generation, then on long-video data using causal attention between clips (while retaining bidirectional attention within each clip). It adds KV caching for constant memory and a truncation-rectified flow (T-RFlow) technique, claiming these steps mitigate error accumulation and attribute drift to produce identity-consistent minute-scale videos and establish a new benchmark.
Significance. If the two-stage finetuning plus T-RFlow demonstrably keeps drift below coherence-destroying thresholds, the work would advance practical long-video synthesis by adapting LLM-style causal attention to diffusion models. The KV-caching mechanism for inference efficiency is a practical contribution. However, the absence of any quantitative metrics, baselines, or stability analysis in the provided text makes it impossible to evaluate whether the central claim holds.
major comments (3)
- [Abstract] Abstract: the claim that the method 'establishes a new benchmark for realistic and coherent minute-level video synthesis' rests on the assertion that 'experimental results demonstrate the effectiveness,' yet no quantitative metrics, baselines, datasets, error bars, or ablation results are supplied; this is load-bearing for the central claim of error-free generation.
- [Abstract] Abstract (method description): the architecture retains full bidirectional attention inside each clip while making only inter-clip attention causal; no derivation, contraction mapping, or empirical bound is given showing that intra-clip denoising steps cannot re-introduce attribute drift that compounds across autoregressive steps, leaving the weakest assumption unaddressed.
- [Abstract] Abstract: the T-RFlow technique is introduced to 'further suppress error accumulation,' but no equation, algorithm, or ablation quantifies its effect relative to standard rectified flow, making its contribution to the 'error-free' claim impossible to assess.
minor comments (2)
- [Abstract] Abstract contains a grammatical error: 'framework that focusing on' should be 'framework that focuses on.'
- [Title] The title uses 'Error-Free,' which is stronger than the body text's more qualified language about 'mitigating' drift; this mismatch should be reconciled.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of results and method details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'establishes a new benchmark for realistic and coherent minute-level video synthesis' rests on the assertion that 'experimental results demonstrate the effectiveness,' yet no quantitative metrics, baselines, datasets, error bars, or ablation results are supplied; this is load-bearing for the central claim of error-free generation.
Authors: We agree that the abstract would be strengthened by referencing specific results. The full manuscript includes quantitative evaluations (coherence metrics, baseline comparisons, and user studies) in the experiments section; we will revise the abstract to concisely cite key metrics and datasets while preserving length constraints. revision: yes
-
Referee: [Abstract] Abstract (method description): the architecture retains full bidirectional attention inside each clip while making only inter-clip attention causal; no derivation, contraction mapping, or empirical bound is given showing that intra-clip denoising steps cannot re-introduce attribute drift that compounds across autoregressive steps, leaving the weakest assumption unaddressed.
Authors: The hybrid attention design follows the LLM paradigm to preserve per-clip generation quality while limiting error propagation across clips. We acknowledge the absence of a formal bound; the revised manuscript will add a dedicated discussion paragraph explaining the empirical stability observed during two-stage finetuning and the role of causal inter-clip conditioning in containing drift. revision: partial
-
Referee: [Abstract] Abstract: the T-RFlow technique is introduced to 'further suppress error accumulation,' but no equation, algorithm, or ablation quantifies its effect relative to standard rectified flow, making its contribution to the 'error-free' claim impossible to assess.
Authors: We will add the full mathematical definition of truncation-rectified flow, the corresponding algorithm, and ablation results quantifying its reduction in error accumulation versus standard rectified flow in the revised methods and experiments sections. revision: yes
Circularity Check
No circularity: empirical finetuning procedure with no self-referential derivations or load-bearing self-citations
full rationale
The paper presents an empirical framework consisting of two-stage finetuning of a diffusion model (first on short videos with bidirectional attention, then on long videos with causal inter-clip attention) plus KV caching and the T-RFlow technique. No equations, uniqueness theorems, or derivations appear that reduce the claimed mitigation of error accumulation to a fitted quantity or self-citation by construction. The central claims rest on experimental results rather than any mathematical reduction to inputs. No self-citations are invoked as load-bearing premises, and the method does not rename known results or smuggle ansatzes via prior work. The derivation chain is self-contained as a description of architectural and training choices whose effectiveness is asserted via evaluation, not by definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: SIGGRAPH Asia 2024 Conference Papers
Bar-Tal, O., Chefer, H., Tov, O., Herrmann, C., Paiss, R., Zada, S., Ephrat, A., Hur, J., Liu, G., Raj, A., et al.: Lumiere: A space-time diffusion model for video generation. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[2]
arXiv preprint arXiv:2311.15127 (2023)
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
Pith/arXiv arXiv 2023
-
[3]
arXiv preprint arXiv:2508.21058 (2025)
Cai, S., Yang, C., Zhang, L., Guo, Y., Xiao, J., Yang, Z., Xu, Y., Yang, Z., Yuille, A., Guibas, L., et al.: Mixture of contexts for long video generation. arXiv preprint arXiv:2508.21058 (2025)
arXiv 2025
-
[4]
Advances in Neural Information Processing Systems38, 91456–91483 (2026)
Chang, S., Wang, P., Tang, J., Wang, F., Yang, Y.: Sparsedit: Token sparsifica- tion for efficient diffusion transformer. Advances in Neural Information Processing Systems38, 91456–91483 (2026)
2026
-
[5]
arXiv preprint arXiv:2504.13074 (2025)
Chen, G., Lin, D., Yang, J., Lin, C., Zhu, J., Fan, M., Zhang, H., Chen, S., Chen, Z., Ma, C., et al.: Skyreels-v2: Infinite-length film generative model. arXiv preprint arXiv:2504.13074 (2025)
Pith/arXiv arXiv 2025
-
[6]
arXiv preprint arXiv:2310.19512 (2023)
Chen, H., Xia, M., He, Y., Zhang, Y., Cun, X., Yang, S., Xing, J., Liu, Y., Chen, Q., Wang, X., et al.: Videocrafter1: Open diffusion models for high-quality video generation. arXiv preprint arXiv:2310.19512 (2023)
Pith/arXiv arXiv 2023
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, H., Zhang, Y., Cun, X., Xia, M., Wang, X., Weng, C., Shan, Y.: Videocrafter2: Overcoming data limitations for high-quality video diffusion mod- els. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7310–7320 (2024) 14 Authors Suppressed Due to Excessive Length
2024
-
[8]
In: The Twelfth International Conference on Learning Representations (2023)
Chen, X., Wang, Y., Zhang, L., Zhuang, S., Ma, X., Yu, J., Wang, Y., Lin, D., Qiao, Y., Liu, Z.: Seine: Short-to-long video diffusion model for generative transition and prediction. In: The Twelfth International Conference on Learning Representations (2023)
2023
-
[9]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Dalal, K., Koceja, D., Xu, J., Zhao, Y., Han, S., Cheung, K.C., Kautz, J., Choi, Y., Sun, Y., Wang, X.: One-minute video generation with test-time training. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 17702– 17711 (2025)
2025
-
[10]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[11]
arXiv preprint arXiv:2503.19325 (2025)
Gu, Y., Mao, W., Shou, M.Z.: Long-context autoregressive video modeling with next-frame prediction. arXiv preprint arXiv:2503.19325 (2025)
Pith/arXiv arXiv 2025
-
[12]
arXiv preprint arXiv:2307.04725 (2023)
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725 (2023)
Pith/arXiv arXiv 2023
-
[13]
arXiv preprint arXiv:2503.10589 (2025)
Guo, Y., Yang, C., Yang, Z., Ma, Z., Lin, Z., Yang, Z., Lin, D., Jiang, L.: Long context tuning for video generation. arXiv preprint arXiv:2503.10589 (2025)
arXiv 2025
-
[14]
Advances in Neural Information Processing Systems 35, 27953–27965 (2022)
Harvey, W., Naderiparizi, S., Masrani, V., Weilbach, C., Wood, F.: Flexible diffu- sion modeling of long videos. Advances in Neural Information Processing Systems 35, 27953–27965 (2022)
2022
-
[15]
arXiv preprint arXiv:2211.13221 (2022)
He, Y., Yang, T., Zhang, Y., Shan, Y., Chen, Q.: Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:2211.13221 (2022)
Pith/arXiv arXiv 2022
-
[16]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[17]
arXiv preprint arXiv:2205.15868 (2022)
Hong, W., Ding, M., Zheng, W., Liu, X., Tang, J.: Cogvideo: Large-scale pretrain- ing for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868 (2022)
Pith/arXiv arXiv 2022
-
[18]
arXiv preprint arXiv:2410.23277 (2024)
Hong, Y., Liu, B., Wu, M., Zhai, Y., Chang, K.W., Li, L., Lin, K., Lin, C.C., Wang, J., Yang, Z., et al.: Slowfast-vgen: Slow-fast learning for action-driven long video generation. arXiv preprint arXiv:2410.23277 (2024)
arXiv 2024
-
[19]
ICLR1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022)
2022
-
[20]
arXiv preprint arXiv:2506.08009 (2025)
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025)
Pith/arXiv arXiv 2025
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024)
2024
-
[22]
arXiv preprint arXiv:2412.03603 (2024)
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
Pith/arXiv arXiv 2024
-
[23]
kuaishou.com(2024)
Kuaishou: Kling ai: Next-generation ai creative studio.https : / / klingai . kuaishou.com(2024)
2024
-
[24]
arXiv preprint arXiv:2412.00131 (2024)
Lin, B., Ge, Y., Cheng, X., Li, Z., Zhu, B., Wang, S., He, X., Ye, Y., Yuan, S., Chen, L., et al.: Open-sora plan: Open-source large video generation model. arXiv preprint arXiv:2412.00131 (2024)
Pith/arXiv arXiv 2024
-
[25]
arXiv preprint arXiv:2210.02747 (2022) Abbreviated paper title 15
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) Abbreviated paper title 15
Pith/arXiv arXiv 2022
-
[26]
arXiv preprint arXiv:2209.03003 (2022)
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
Pith/arXiv arXiv 2022
-
[27]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[28]
arXiv preprint arXiv:2503.09642 (2025)
Peng, X., Zheng, Z., Shen, C., Young, T., Guo, X., Wang, B., Xu, H., Liu, H., Jiang, M., Li, W., Wang, Y., Ye, A., Ren, G., Ma, Q., Liang, W., Lian, X., Wu, X., Zhong, Y., Li, Z., Gong, C., Lei, G., Cheng, L., Zhang, L., Li, M., Zhang, R., Hu, S., Huang, S., Wang, X., Zhao, Y., Wang, Y., Wei, Z., You, Y.: Open-sora 2.0: Training a commercial-level video g...
Pith/arXiv arXiv 2025
-
[29]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[30]
arXiv preprint arXiv:1908.10084 (2019)
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. arXiv preprint arXiv:1908.10084 (2019)
Pith/arXiv arXiv 1908
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[32]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
2024
-
[33]
Team, G.: Mochi 1.https://github.com/genmoai/models(2024)
2024
-
[34]
arXiv preprint arXiv:2505.13211 (2025)
Teng, H., Jia, H., Sun, L., Li, L., Li, M., Tang, M., Han, S., Zhang, T., Zhang, W., Luo, W., et al.: Magi-1: Autoregressive video generation at scale. arXiv preprint arXiv:2505.13211 (2025)
Pith/arXiv arXiv 2025
-
[35]
Advances in neural information processing systems35, 23371–23385 (2022)
Voleti, V., Jolicoeur-Martineau, A., Pal, C.: Mcvd-masked conditional video diffu- sion for prediction, generation, and interpolation. Advances in neural information processing systems35, 23371–23385 (2022)
2022
-
[36]
arXiv preprint arXiv:2503.20314 (2025)
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
Pith/arXiv arXiv 2025
-
[37]
arXiv preprint arXiv:2410.02757 (2024)
Wang, Y., Xiong, T., Zhou, D., Lin, Z., Zhao, Y., Kang, B., Feng, J., Liu, X.: Loong: Generating minute-level long videos with autoregressive language models. arXiv preprint arXiv:2410.02757 (2024)
arXiv 2024
-
[38]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wu, W., Liu, M., Zhu, Z., Xia, X., Feng, H., Wang, W., Lin, K.Q., Shen, C., Shou, M.Z.: Moviebench: A hierarchical movie level dataset for long video generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 28984–28994 (2025)
2025
-
[39]
arXiv preprint arXiv:2507.18634 (2025)
Xiao, J., Yang, C., Zhang, L., Cai, S., Zhao, Y., Guo, Y., Wetzstein, G., Agrawala, M., Yuille, A., Jiang, L.: Captain cinema: Towards short movie generation. arXiv preprint arXiv:2507.18634 (2025)
arXiv 2025
-
[40]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xie, D., Xu, Z., Hong, Y., Tan, H., Liu, D., Liu, F., Kaufman, A., Zhou, Y.: Progressive autoregressive video diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6322–6332 (2025) 16 Authors Suppressed Due to Excessive Length
2025
-
[41]
In: European Conference on Computer Vision
Xing,J.,Xia,M.,Zhang,Y.,Chen,H.,Yu,W.,Liu,H.,Liu,G.,Wang,X.,Shan,Y., Wong, T.T.: Dynamicrafter: Animating open-domain images with video diffusion priors. In: European Conference on Computer Vision. pp. 399–417. Springer (2024)
2024
-
[42]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yan, X., Cai, Y., Wang, Q., Zhou, Y., Huang, W., Yang, H.: Long video diffusion generation with segmented cross-attention and content-rich video data curation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 3184–3194 (2025)
2025
-
[43]
arXiv preprint arXiv:2509.22622 (2025)
Yang, S., Huang, W., Chu, R., Xiao, Y., Zhao, Y., Wang, X., Li, M., Xie, E., Chen, Y., Lu, Y., et al.: Longlive: Real-time interactive long video generation. arXiv preprint arXiv:2509.22622 (2025)
Pith/arXiv arXiv 2025
-
[44]
arXiv preprint arXiv:2306.02562 (2023)
Yang, S., Zhang, L., Liu, Y., Jiang, Z., He, Y.: Video diffusion models with local- global context guidance. arXiv preprint arXiv:2306.02562 (2023)
arXiv 2023
-
[45]
arXiv preprint arXiv:2408.06072 (2024)
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
Pith/arXiv arXiv 2024
-
[46]
In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Yin, S., Wu, C., Yang, H., Wang, J., Wang, X., Ni, M., Yang, Z., Li, L., Liu, S., Yang, F., et al.: Nuwa-xl: Diffusion over diffusion for extremely long video generation. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 1309–1320 (2023)
2023
-
[47]
International Journal of Computer Vision133(4), 1879–1893 (2025)
Zhang, D.J., Wu, J.Z., Liu, J.W., Zhao, R., Ran, L., Gu, Y., Gao, D., Shou, M.Z.: Show-1: Marrying pixel and latent diffusion models for text-to-video generation. International Journal of Computer Vision133(4), 1879–1893 (2025)
2025
-
[48]
arXiv preprint arXiv:2504.12626 (2025)
Zhang, L., Agrawala, M.: Packing input frame context in next-frame prediction models for video generation. arXiv preprint arXiv:2504.12626 (2025)
arXiv 2025
-
[49]
arXiv preprint arXiv:2311.04145 (2023)
Zhang, S., Wang, J., Zhang, Y., Zhao, K., Yuan, H., Qin, Z., Wang, X., Zhao, D., Zhou, J.: I2vgen-xl: High-quality image-to-video synthesis via cascaded diffusion models. arXiv preprint arXiv:2311.04145 (2023)
Pith/arXiv arXiv 2023
-
[50]
Zhang, Z., Chang, S., He, Y., Han, Y., Tang, J., Wang, F., Zhuang, B.: Blockvid: Block diffusion for high-fidelity and coherent minute-long video generation (2025), https://openreview.net/forum?id=k8KIwW4f7P
2025
-
[51]
arXiv preprint arXiv:2407.16655 (2024)
Zhao, C., Liu, M., Wang, W., Chen, W., Wang, F., Chen, H., Zhang, B., Shen, C.: Moviedreamer: Hierarchical generation for coherent long visual sequence. arXiv preprint arXiv:2407.16655 (2024)
arXiv 2024
-
[52]
arXiv preprint arXiv:2502.15894 (2025)
Zhao, M., He, G., Chen, Y., Zhu, H., Li, C., Zhu, J.: Riflex: A free lunch for length extrapolation in video diffusion transformers. arXiv preprint arXiv:2502.15894 (2025)
arXiv 2025
-
[53]
Advances in Neural In- formation Processing Systems37, 110315–110340 (2024)
Zhou, Y., Zhou, D., Cheng, M.M., Feng, J., Hou, Q.: Storydiffusion: Consistent self-attention for long-range image and video generation. Advances in Neural In- formation Processing Systems37, 110315–110340 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.