Generalizable Video Quality Assessment via Weak-to-Strong Learning
Pith reviewed 2026-05-22 16:06 UTC · model grok-4.3
The pith
Self-supervised learning on unlabeled videos achieves generalized video quality assessment matching supervised models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that training a large multimodal model with learning-to-rank on video pairs auto-labeled by existing VQA models' pseudo-labels and synthetic distortion-based relative rankings, plus an iterative self-improvement strategy, produces a model that matches or exceeds supervised VQA performance in zero-shot settings on standard benchmarks, shows better out-of-distribution generalization, and achieves new state-of-the-art after fine-tuning on human labels.
What carries the argument
A learning-to-rank framework on automatically labeled video pairs using pseudo-labels and synthetic simulations, enhanced by iterative self-improvement where the model improves its own annotations.
If this is right
- Zero-shot performance on existing VQA benchmarks reaches or exceeds that of supervised models.
- Superior generalization holds across diverse video content and different distortion types.
- State-of-the-art results are obtained after fine-tuning on human-labeled datasets.
- Training scales to datasets ten times larger than traditional VQA benchmarks using only unlabeled web videos.
Where Pith is reading between the lines
- Extending this ranking-based self-supervision to other media quality tasks could similarly reduce reliance on manual labels.
- The iterative annotation refinement might create a feedback loop that accelerates model improvement in low-data regimes.
- Public release of the large dataset and code could spur further research into scaling self-supervised perceptual models.
- Connections to ranking methods in other fields like recommendation systems might yield cross-domain insights.
Load-bearing premise
Existing VQA models can generate pseudo-labels and synthetic distortion simulations can provide relative rankings that are accurate enough for the learning-to-rank objective and iterative process to produce genuine gains in generalization.
What would settle it
Evaluating the trained model zero-shot on a benchmark featuring video distortions or content types absent from the web training data and finding performance significantly below supervised baselines would falsify the generalization claim.
Figures










read the original abstract
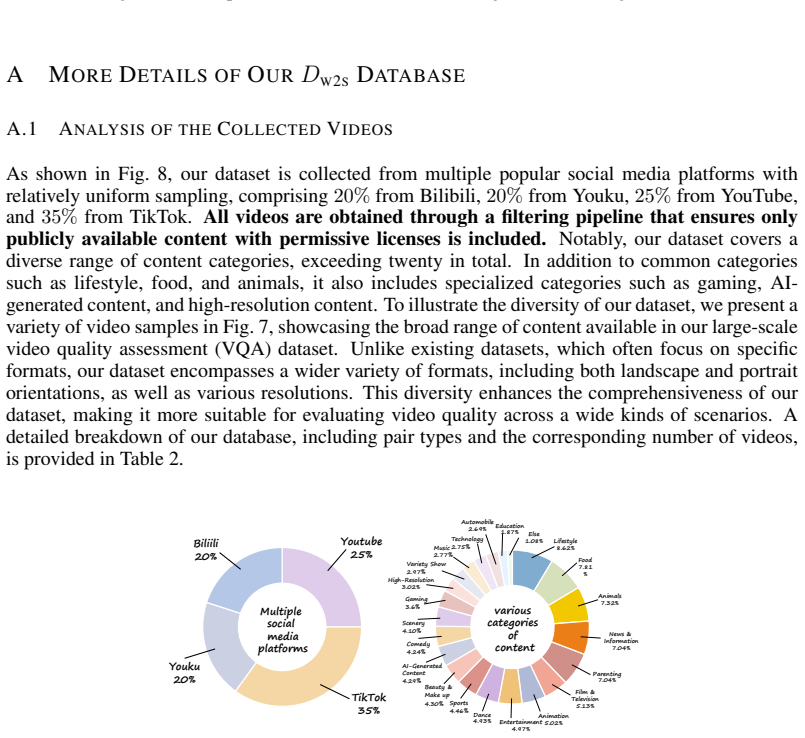
Video quality assessment (VQA) seeks to predict the perceptual quality of a video in alignment with human visual perception, serving as a fundamental tool for quantifying quality degradation across video processing workflows. The dominant VQA paradigm relies on supervised training with human-labeled datasets, which, despite substantial progress, still suffers from poor generalization to unseen video content. In this work, we explore weak-to-strong (W2S) learning as a new paradigm for advancing VQA without reliance on human-labeled datasets. We first provide empirical evidence that a straightforward W2S strategy allows a strong student model to not only match its weak teacher on in-domain benchmarks but also surpass it on out-of-distribution (OOD) benchmarks, revealing a distinct weak-to-strong effect in VQA. Building on this insight, we propose a novel framework that enhances W2S learning from two aspects: (1) integrating homogeneous and heterogeneous supervision signals from diverse VQA teachers -- including off-the-shelf VQA models and synthetic distortion simulators -- via a learn-to-rank formulation, and (2) iterative W2S training, where each strong student is recycled as the teacher in subsequent cycles, progressively focusing on challenging cases. Extensive experiments show that our method achieves state-of-the-art results across both in-domain and OOD benchmarks, with especially strong gains in OOD scenarios. Our findings highlight W2S learning as a principled route to break annotation barriers and achieve scalable generalization in video quality assessment. Our data and code will be available at https://github.com/clh124/W2S-VQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a self-supervised framework for generalized video quality assessment (VQA) that trains a large multimodal model via a learning-to-rank objective on video pairs drawn from a 10× larger unlabeled web-video corpus. Automatic labeling combines quality pseudo-labels generated by existing supervised VQA models with relative rankings obtained from synthetic distortion simulations; an iterative self-improvement loop then lets the trained model re-annotate the same pool to refine label quality. The resulting model is reported to reach zero-shot performance on in-domain VQA benchmarks that matches or exceeds fully supervised baselines, to exhibit stronger out-of-distribution generalization, and to set a new state-of-the-art after fine-tuning on human-labeled data.
Significance. If the central claims hold, the work would meaningfully reduce dependence on costly human VQA annotations and demonstrate that scale plus ranking-based self-supervision can produce competitive or superior generalization. Public release of the dataset and code would further amplify its utility for the community. The combination of pseudo-labeling, synthetic distortions, and iteration is a plausible route to larger training corpora, but the significance is tempered by the absence of direct evidence that the generated training signals are sufficiently accurate and non-reinforcing.
major comments (2)
- [§3.3] §3.3 (Iterative Self-Improvement Training Strategy): the description states that the model 'acts as an improved annotator to iteratively refine the annotation quality,' yet no quantitative tracking of pseudo-label accuracy (e.g., Spearman or Pearson correlation with held-out human labels) across iterations is reported. Without such a diagnostic, it is impossible to verify that the loop corrects rather than amplifies systematic errors inherited from the base VQA models, which directly undermines the zero-shot and OOD claims in the abstract.
- [§4.1–4.2] §4.1–4.2 (Dataset Construction and Baselines): the 10× scale advantage is central to the performance claims, but the manuscript provides no ablation that isolates the contribution of the iterative step versus a single-pass pseudo-labeling regime, nor any analysis of domain mismatch between the web-video distribution and the base VQA models used for initial labeling. These omissions leave open the possibility that reported gains arise from dataset size or post-hoc selection rather than the proposed self-supervision mechanism.
minor comments (2)
- [Abstract] Abstract: the phrase 'matches or surpasses supervised models' should be accompanied by the precise metrics (SRCC, PLCC, etc.) and the exact competing methods for immediate clarity.
- [Figure 3 / Table 2] Figure 3 and Table 2: error bars or statistical significance tests are missing for the reported OOD improvements; adding them would strengthen the generalization claims.
Simulated Author's Rebuttal
We are grateful to the referee for the detailed and thoughtful review of our paper. The suggestions have allowed us to enhance the manuscript by providing additional diagnostics for the iterative training process and ablations for the dataset construction. Below, we respond to each major comment in turn, indicating the changes we will implement.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Iterative Self-Improvement Training Strategy): the description states that the model 'acts as an improved annotator to iteratively refine the annotation quality,' yet no quantitative tracking of pseudo-label accuracy (e.g., Spearman or Pearson correlation with held-out human labels) across iterations is reported. Without such a diagnostic, it is impossible to verify that the loop corrects rather than amplifies systematic errors inherited from the base VQA models, which directly undermines the zero-shot and OOD claims in the abstract.
Authors: We acknowledge the value of directly tracking pseudo-label accuracy across iterations to confirm the self-improvement effect. In the revised manuscript, we have added a new subsection in §3.3 along with a supplementary table that reports the Spearman and Pearson correlations between the generated pseudo-labels and a held-out human-labeled set at each iteration. The results show progressive improvement in correlation, supporting that the iterative process refines the annotations and mitigates error amplification from the initial base models. This addition directly addresses the concern regarding the validity of the zero-shot and OOD claims. revision: yes
-
Referee: [§4.1–4.2] §4.1–4.2 (Dataset Construction and Baselines): the 10× scale advantage is central to the performance claims, but the manuscript provides no ablation that isolates the contribution of the iterative step versus a single-pass pseudo-labeling regime, nor any analysis of domain mismatch between the web-video distribution and the base VQA models used for initial labeling. These omissions leave open the possibility that reported gains arise from dataset size or post-hoc selection rather than the proposed self-supervision mechanism.
Authors: We agree that isolating the iterative component and examining potential domain mismatches are important for attributing the performance gains correctly. We have performed an additional ablation study, now reported in §4.2, that compares the full iterative self-supervised training against a single-pass pseudo-labeling approach on the same 10× dataset. The iterative version outperforms the single-pass baseline, indicating the benefit of the refinement loop beyond mere scale. Additionally, we have included an analysis of domain characteristics in §4.1, comparing key statistics such as resolution, motion intensity, and content categories between our unlabeled web-video corpus and the source datasets of the base VQA models. We also provide OOD performance breakdowns to show robustness to any mismatches. These revisions help rule out alternative explanations based on size or selection alone. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's training pipeline begins with pseudo-labels generated by pre-existing VQA models plus synthetic distortion rankings, then applies an iterative self-improvement loop in which the trained model re-annotates the same pool. These steps are methodological choices whose outputs are subsequently evaluated on independent, human-labeled VQA benchmarks that were never part of the pseudo-label generation or iteration. Because the reported zero-shot and OOD metrics are measured against external ground truth rather than being algebraically or definitionally entailed by the input labels, no load-bearing claim reduces to its own inputs by construction. The scale-up to a 10× unlabeled corpus supplies an independent empirical signal that is tested rather than presupposed.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pseudo-labels from existing VQA models and relative rankings from synthetic distortion simulations provide sufficiently accurate signals for effective learning-to-rank training.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reformulate quality regression as a ranking problem... iterative W2S training... 200k videos... pseudo-labeling by existing VQA models and relative quality ranking based on synthetic distortion simulations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.