Reinforcement Learning for Risk-Sensitive Investment Management: a Free Energy--Entropy Duality Approach
Pith reviewed 2026-06-26 14:24 UTC · model grok-4.3
The pith
Free energy-entropy duality reformulates risk-sensitive benchmarked asset allocation as an explicit linear-quadratic-Gaussian game that a continuous-time actor-critic method solves.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Free energy-entropy duality reformulates the benchmarked risk-sensitive allocation problem as a linear-quadratic-Gaussian stochastic differential game under an equivalent probability measure. This game possesses explicit saddle-point solutions for both finite and infinite horizons. The resulting quadratic value function and affine controls then determine the architecture of a continuous-time q-learning actor-critic method, with the portfolio allocation and adversarial control treated as deterministic actors. Implementation on U.S. equity data confirms that the actors recover the optimal policy to high accuracy and exhibits an asymmetry in which the portfolio actor receives a cleaner learning
What carries the argument
Free energy-entropy duality, which converts the original benchmarked control problem into an equivalent linear-quadratic-Gaussian stochastic differential game under a changed probability measure and supplies the explicit saddle-point solutions that shape the actor-critic architecture.
If this is right
- Explicit finite- and infinite-horizon saddle-point solutions exist for the reformulated LQG game.
- The quadratic value function motivates the critic and the affine controls motivate deterministic actors in the q-learning algorithm.
- The learned allocation policy admits an economic interpretation through fractional Kelly decompositions.
- The portfolio actor receives a cleaner learning signal than the auxiliary adversarial actor.
Where Pith is reading between the lines
- The same duality step could be tested on other risk-sensitive problems whose state process is exogenous but whose payoff includes controlled stochastic integrals.
- The observed asymmetry in learning signals suggests that training schedules could allocate more updates to the main allocation actor than to the adversary.
- Fractional Kelly interpretations of the learned policy could be checked against standard mean-variance or log-optimal benchmarks on the same data set.
Load-bearing premise
The benchmarked allocation problem, whose state is uncontrolled while the terminal reward contains a controlled Itô integral, admits an exact free energy-entropy duality reformulation into an equivalent LQG game.
What would settle it
Run the actor-critic algorithm on the same calibrated U.S. equity parameters and compare the learned controls against the known closed-form saddle-point solution of the equivalent LQG game; large persistent deviation would falsify the claim that the method learns the optimal policy with high accuracy.
Figures
read the original abstract
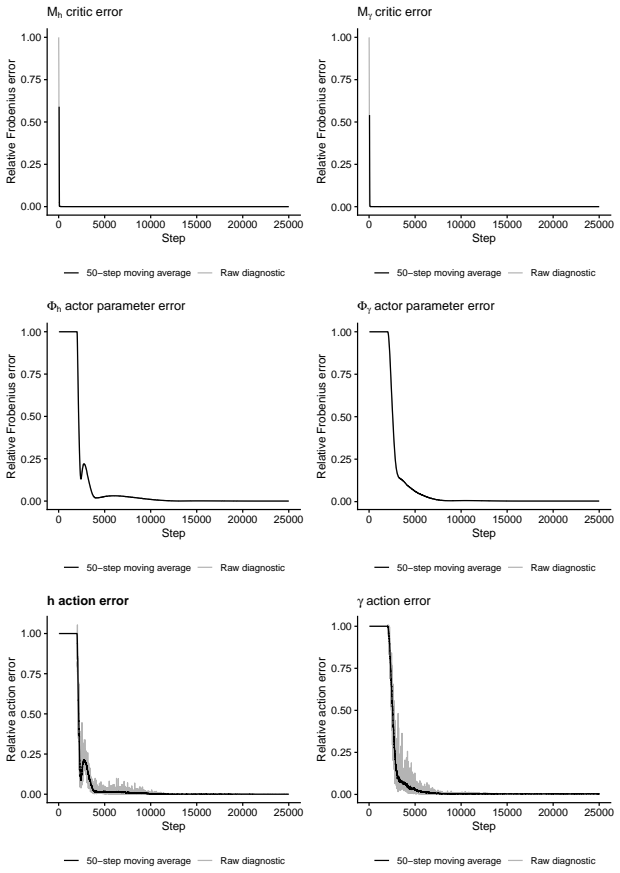
This paper develops a reinforcement-learning approach to continuous-time risk-sensitive benchmarked asset allocation in a partly model-based setting. The benchmarked problem does not directly fit the standard Markovian stochastic-control template: the state is uncontrolled, whereas the terminal reward contains a controlled It\^o integral. We use free energy-entropy duality to reformulate the problem as a linear-quadratic-Gaussian stochastic differential game under an equivalent probability measure, yielding explicit finite- and infinite-horizon saddle-point solutions. This structure guides a continuous-time $q$-learning actor-critic method: the quadratic value function motivates the critic, while the affine saddle-point controls motivate deterministic actors for the portfolio allocation and adversarial control. The learned allocation admits an economic interpretation through fractional Kelly decompositions. A proof-of-concept implementation calibrated to U.S. equity data shows that the actors learn the optimal policy with high accuracy and reveals a favorable asymmetry: the portfolio actor receives a cleaner learning signal than the auxiliary adversarial actor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a reinforcement-learning method for continuous-time risk-sensitive benchmarked asset allocation. It uses free energy-entropy duality to recast the problem (uncontrolled state dynamics, terminal reward with controlled Itô integral) as an equivalent linear-quadratic-Gaussian stochastic differential game under a changed measure. Explicit finite- and infinite-horizon saddle-point solutions are derived; these motivate a continuous-time q-learning actor-critic scheme whose critic is quadratic and whose actors are deterministic affine maps for portfolio and adversarial controls. The learned allocation is interpreted via fractional Kelly decompositions. A proof-of-concept calibration to U.S. equity data reports that the actors recover the optimal policy with high accuracy.
Significance. If the duality mapping is exact and the equivalence is preserved, the work supplies a mathematically grounded route from a non-standard risk-sensitive control problem to an actor-critic architecture whose functional forms are dictated by the saddle-point solution rather than chosen heuristically. The explicit solutions, the economic Kelly interpretation, and the reproducible numerical demonstration on real data constitute clear strengths. The approach could influence the design of model-based RL methods for other finance problems whose state-reward structure deviates from the classical Markovian template.
major comments (2)
- [Abstract and duality-reformulation section] The central claim rests on an exact free energy-entropy duality that converts the benchmarked problem into an LQG game. The abstract states that the benchmarked problem 'does not directly fit the standard Markovian stochastic-control template' yet 'admits' the reformulation; the manuscript must supply the explicit change-of-measure construction and verify that the controlled Itô term in the terminal reward remains equivalent (i.e., does not introduce residual control dependence) after the duality is applied. Without this step-by-step verification, the subsequent derivation of the quadratic critic and affine actors cannot be regarded as load-bearing.
- [Numerical implementation and results section] The numerical claim that 'the actors learn the optimal policy with high accuracy' is presented without reported error bounds, sensitivity to the discretization of the continuous-time q-learning update, or ablation on the data-exclusion window used for calibration. Because the architecture is justified by the duality-derived saddle point, any discrepancy between the learned policy and the analytic saddle point must be quantified to support the accuracy statement.
minor comments (2)
- [Introduction] Notation for the free-energy functional and the entropy term should be introduced with explicit definitions before the duality statement is invoked.
- [Actor-critic method] The paper should state whether the continuous-time q-learning algorithm is derived from first principles or obtained by taking a formal limit of a discrete-time counterpart; the derivation path affects reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We will undertake a major revision to address the two points raised, adding the requested explicit derivations and quantitative numerical assessments.
read point-by-point responses
-
Referee: [Abstract and duality-reformulation section] The central claim rests on an exact free energy-entropy duality that converts the benchmarked problem into an LQG game. The abstract states that the benchmarked problem 'does not directly fit the standard Markovian stochastic-control template' yet 'admits' the reformulation; the manuscript must supply the explicit change-of-measure construction and verify that the controlled Itô term in the terminal reward remains equivalent (i.e., does not introduce residual control dependence) after the duality is applied. Without this step-by-step verification, the subsequent derivation of the quadratic critic and affine actors cannot be regarded as load-bearing.
Authors: We agree that the change-of-measure construction and verification of Itô-term equivalence require explicit, step-by-step presentation. The submitted manuscript sketches the duality but does not contain the full Girsanov construction or the direct check that the controlled integral remains equivalent under the new measure. In the revision we will insert a dedicated subsection that (i) states the Girsanov kernel, (ii) derives the Radon–Nikodym derivative, and (iii) verifies that the terminal reward’s controlled Itô term acquires no additional control dependence after the measure change. This will make the subsequent saddle-point derivations load-bearing. revision: yes
-
Referee: [Numerical implementation and results section] The numerical claim that 'the actors learn the optimal policy with high accuracy' is presented without reported error bounds, sensitivity to the discretization of the continuous-time q-learning update, or ablation on the data-exclusion window used for calibration. Because the architecture is justified by the duality-derived saddle point, any discrepancy between the learned policy and the analytic saddle point must be quantified to support the accuracy statement.
Authors: We accept that the accuracy claim must be supported by quantitative diagnostics. The original proof-of-concept omitted error metrics, discretization sensitivity, and ablation studies. In the revised numerical section we will report (i) L² and sup-norm discrepancies between the learned and analytic saddle-point controls, (ii) results for a range of discretization step sizes in the continuous-time q-learning update, and (iii) an ablation over the data-exclusion window used for calibration. These additions will quantify any discrepancy and substantiate the accuracy statement. revision: yes
Circularity Check
No significant circularity; duality applied as external reformulation tool
full rationale
The derivation applies free energy-entropy duality as an external mathematical equivalence to convert the benchmarked allocation problem (uncontrolled state, controlled Itô term in reward) into an LQG stochastic differential game, from which explicit saddle-point solutions and the actor-critic architecture are obtained. No quoted step defines a quantity in terms of itself, renames a fitted input as a prediction, or reduces the central claim to a self-citation chain whose load-bearing premise is unverified. The paper presents the duality mapping and resulting explicit solutions as independent mathematical content that then guides the RL method; the subsequent calibration to U.S. equity data is a proof-of-concept implementation rather than a self-referential fit. This is the normal case of a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Carhart, M. (1997). On persistence in mutual fund performance. The Journal of Finance , 52(1), 57--82
1997
-
[2]
Cheng, Z., Guo, X., & Zhang, Y. (2026). Deterministic Policy Gradient for Reinforcement Learning with Continuous Time and State . arXiv:2509.23711 [cs.LG] version: 2
arXiv 2026
-
[3]
& Ziemba, W
Chopra, V. & Ziemba, W. (1993). The effect of errors in means, variances and covariances on optimal portfolio choice. Journal of Portfolio Management , 19(2), 6--11
1993
-
[4]
& Lleo, S
Davis, M. & Lleo, S. (2008). Risk-sensitive benchmarked asset management. Quantitative Finance , 8(4), 415--426
2008
-
[5]
& French, K
Fama, E. & French, K. R. (2015). A five-factor asset pricing model. Journal of Financial Economics , 116(1), 1--22
2015
-
[6]
N., & Ritter, G
Halperin, I., Kolm, P. N., & Ritter, G. (2025). Chapter 6: Reinforcement Learning and Inverse Reinforcement Learning : A Practitioner 's Guide for Investment Management . In j. Simonian (Ed.), AI in Asset Management: Tools, Applications, and Frontiers . CFA Institute Research Foundation
2025
-
[7]
Jia, Y. (2026). Continuous- Time Risk - Sensitive Reinforcement Learning via Quadratic Variation Penalty . Applied Mathematics & Optimization , 93(2), 58
2026
-
[8]
& Zhou, X
Jia, Y. & Zhou, X. (2022a). Policy Evaluation and Temporal - Difference Learning in Continuous Time and Space : A Martingale Approach . Journal of Machine Learning Research , 23(154), 1--55
-
[9]
& Zhou, X
Jia, Y. & Zhou, X. (2022b). Policy Gradient and Actor -- Critic Learning in Continuous Time and Space : Theory and Algorithms . Journal of Machine Learning Research , 23(275), 1--50
-
[10]
& Zhou, X
Jia, Y. & Zhou, X. Y. (2023). q- Learning in Continuous Time . Journal of Machine Learning Research , 24(161), 1--61
2023
-
[11]
Jiang, R., Saunders, D., & Weng, C. (2022). The reinforcement learning Kelly strategy. Quantitative Finance , 22(8), 1445--1464. Publisher: Routledge \_eprint: https://doi.org/10.1080/14697688.2022.2049356
-
[12]
& Ritter, G
Kolm, P. & Ritter, G. (2020). Modern Perspectives on Reinforcement Learning in Finance . The Journal of Machine Learning in Finance , 1(1)
2020
-
[13]
Kolm, P. N. & Ritter, G. (2025). Reinforcement Learning for Asset and Portfolio Management . Journal of Portfolio Management , 52(2), 81
2025
-
[14]
& Nagai, H
Kuroda, K. & Nagai, H. (2002). Risk-sensitive portfolio optimization on infinite time horizon. Stochastics and Stochastics Reports , 73, 309--331
2002
-
[15]
& Runggaldier, W
Lleo, S. & Runggaldier, W. (2024). On the separation of estimation and control in risk-sensitive investment problems under incomplete observation. European Journal of Operational Research , 316(1), 200--214
2024
-
[16]
& Runggaldier, W
Lleo, S. & Runggaldier, W. (2026a). Exploratory randomization for discrete-time risk-sensitive benchmarked investment management with reinforcement learning
-
[17]
& Runggaldier, W
Lleo, S. & Runggaldier, W. (2026b). Risk-sensitive investment management via free energy--entropy duality. Preprint
-
[18]
Silver, D., Lever, G., Heess, N., Degris, T., Wierstra, D., & Riedmiller, M. (2014). Deterministic Policy Gradient Algorithms . In Proceedings of the 31st International Conference on Machine Learning (pp.\ 387--395).: PMLR
2014
-
[19]
& Barto, A
Sutton, R. & Barto, A. (2018). Reinforcement Learning, second edition: An Introduction . Adaptive Computation and Machine Learning series. Bradford Books, 2 edition
2018
-
[20]
Wang, H., Zariphopoulou, T., & Zhou, X. Y. (2020). Reinforcement Learning in Continuous Time and Space : A Stochastic Control Approach . Journal of Machine Learning Research , 21(198), 1--34
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.