ACE-SQL: Adaptive Co-Optimization via Empirical Credit Assignment for Text-to-SQL
Pith reviewed 2026-06-28 01:10 UTC · model grok-4.3
The pith
ACE-SQL co-optimizes schema retrieval and SQL generation by deriving on-policy targets from execution-correct rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
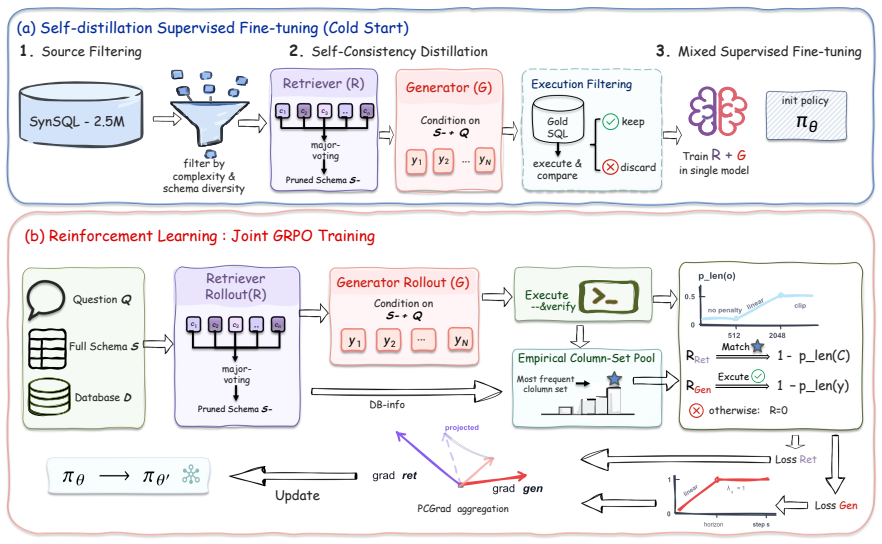
ACE-SQL constructs an online column-set pool from generator rollouts and derives adaptive on-policy retrieval targets from the column set most frequently associated with execution-correct rollouts. This induces bidirectional adaptation, where the retriever adapts toward column sets that the generator can execute correctly, while the generator adapts to the retriever's evolving schema selections under execution feedback.
What carries the argument
The empirical credit assignment that selects column sets by their frequency of appearance in execution-correct generator rollouts.
If this is right
- The retriever learns column sets that the generator can successfully turn into executable SQL.
- The generator improves by receiving execution signals tied to the retriever's current selections.
- Training converges with only about 3k synthetic question-database pairs.
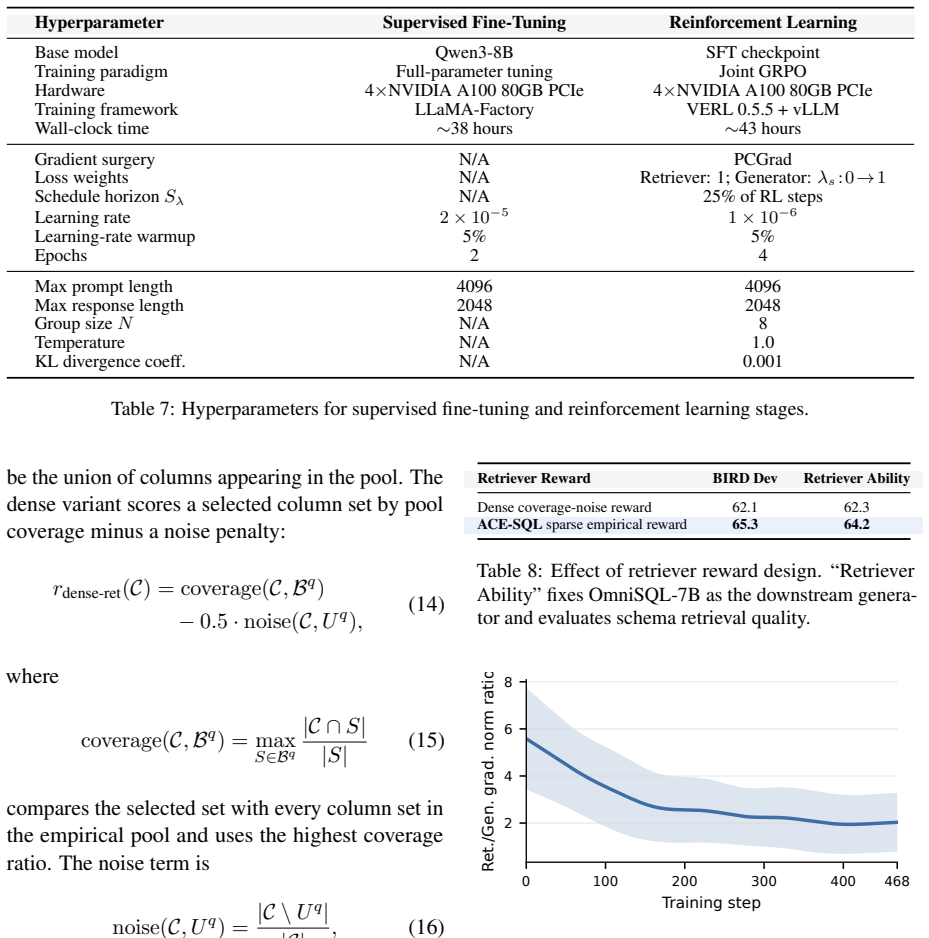
- Average output length stays at 0.93k tokens per query while reaching 65.3% greedy execution accuracy on BIRD Dev.
Where Pith is reading between the lines
- The same frequency-based credit signal could coordinate retrieval and generation in other retrieval-augmented tasks.
- Synthetic data paired with this loop might reduce dependence on large human-annotated schema links.
- The method's success would be tested by measuring whether the same targets improve accuracy on benchmarks other than BIRD.
Load-bearing premise
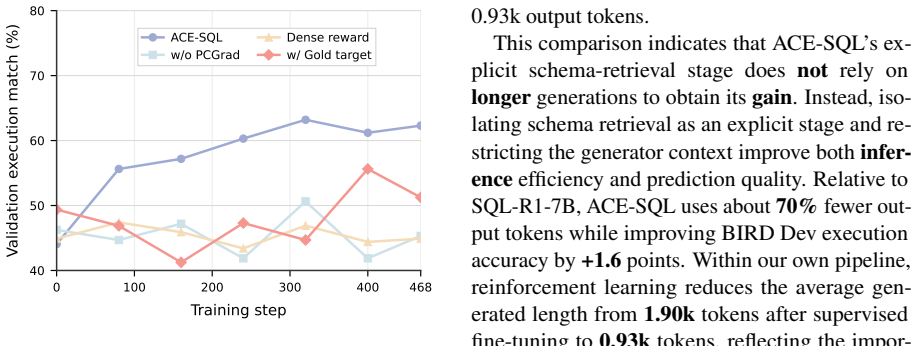
The column sets that occur most often with execution-correct rollouts supply suitable targets for the retriever without bias from the generator's current policy.
What would settle it
If replacing the frequency-derived targets with static gold columns produces higher execution accuracy after the same number of training steps, the adaptive credit assignment would not be delivering the claimed benefit.
Figures


read the original abstract
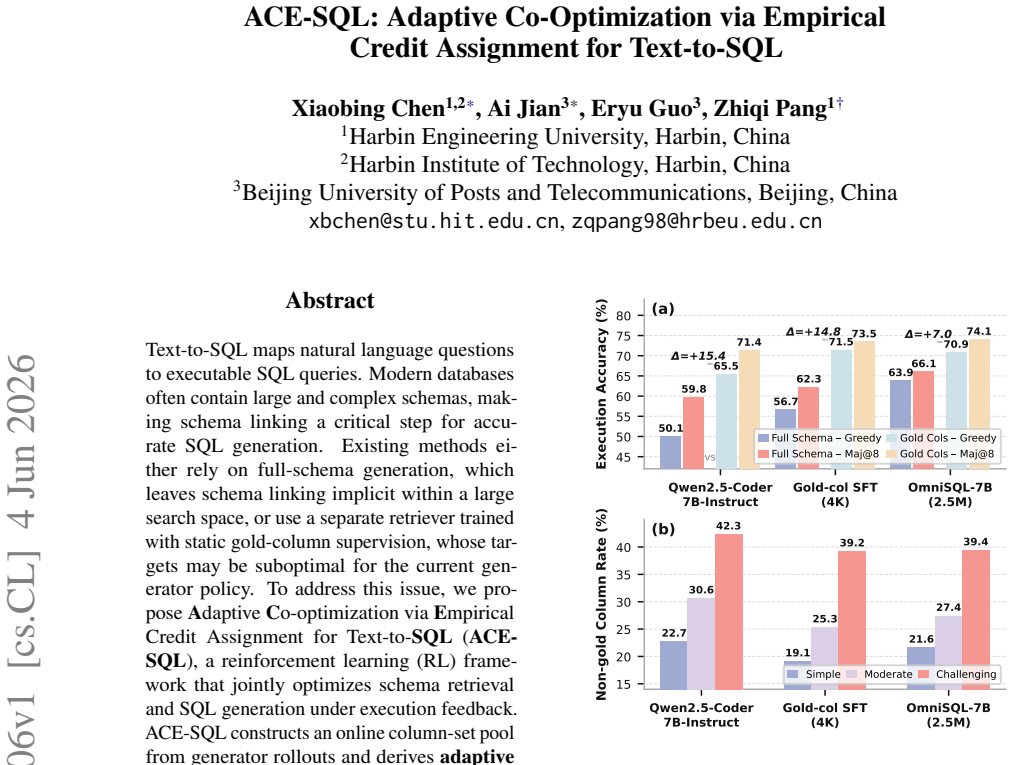
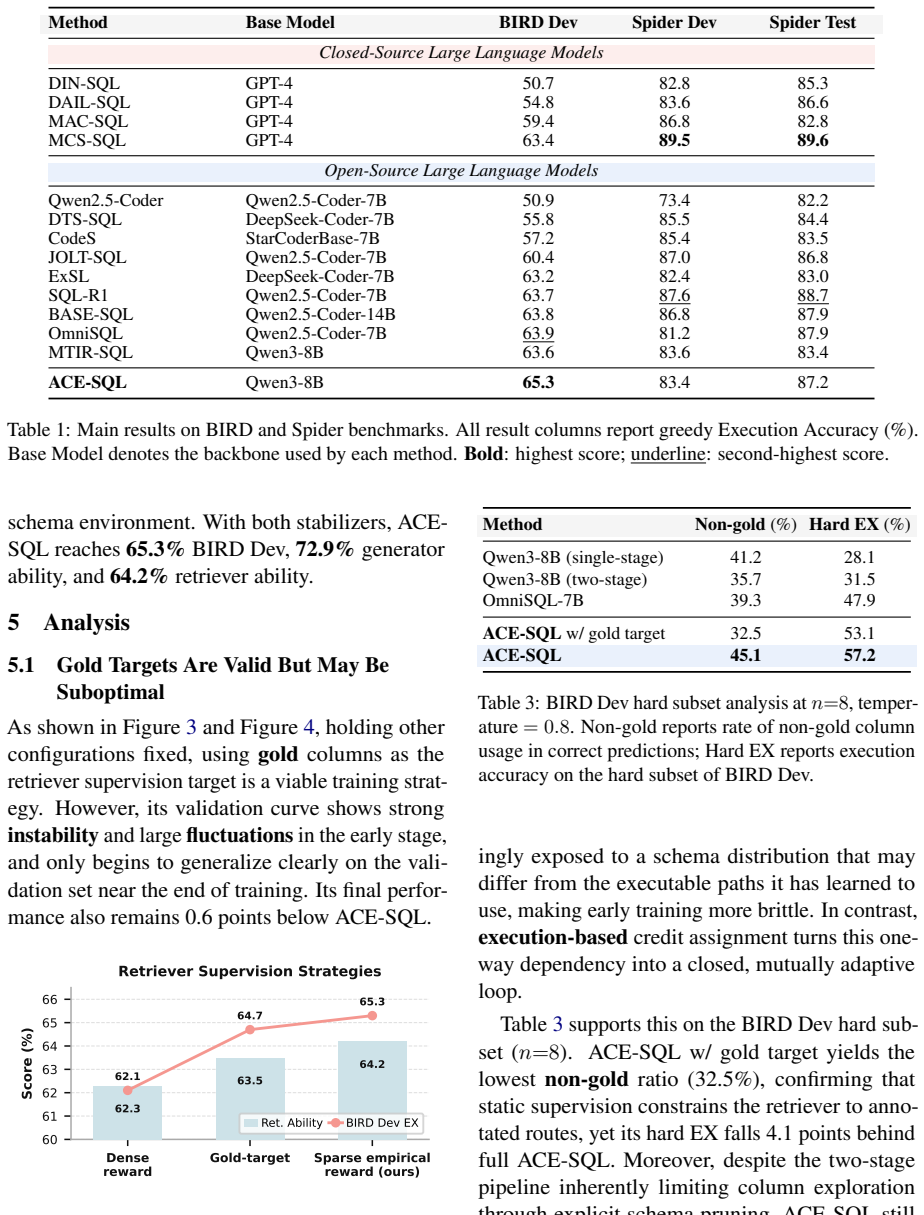
Text-to-SQL maps natural language questions to executable SQL queries. Modern databases often contain large and complex schemas, making schema linking a critical step for accurate SQL generation. Existing methods either rely on full-schema generation, which leaves schema linking implicit within a large search space, or use a separate retriever trained with static gold-column supervision, whose targets may be suboptimal for the current generator policy. To address this issue, we propose Adaptive Co-optimization via Empirical Credit Assignment for Text-to-SQL (ACE-SQL), a reinforcement learning (RL) framework that jointly optimizes schema retrieval and SQL generation under execution feedback. ACE-SQL constructs an online column-set pool from generator rollouts and derives adaptive on-policy retrieval targets from the column set most frequently associated with execution-correct rollouts. This induces bidirectional adaptation, where the retriever adapts toward column sets that the generator can execute correctly, while the generator adapts to the retriever's evolving schema selections under execution feedback. With approximately 3k synthetic Text-to-SQL question-database pairs for RL training, ACE-SQL achieves 65.3% greedy execution accuracy on BIRD Dev while using 0.93k output tokens per query. The repository is available at https://github.com/xbchen1/ACE-SQL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ACE-SQL, a reinforcement learning framework for Text-to-SQL that jointly optimizes schema retrieval and SQL generation. It builds an online column-set pool from generator rollouts under execution feedback and derives adaptive retrieval targets as the column set most frequently appearing in execution-correct rollouts. Trained on approximately 3k synthetic question-database pairs, the method reports 65.3% greedy execution accuracy on BIRD Dev while consuming 0.93k output tokens per query.
Significance. If the empirical credit assignment produces targets that improve retrieval without embedding policy bias, the approach could reduce dependence on static gold supervision and enable more efficient co-adaptation of retriever and generator in schema-linking tasks.
major comments (1)
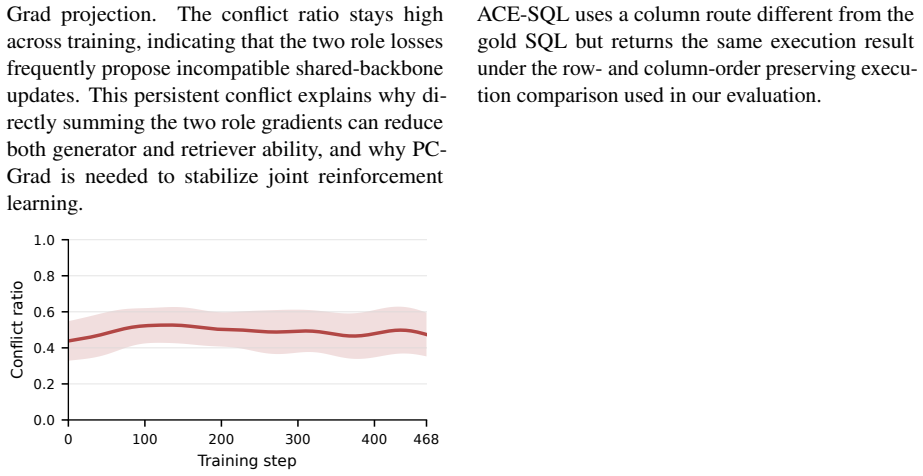
- [Abstract] Abstract (mechanism description): the adaptive on-policy retrieval targets are defined as the column set most frequently associated with execution-correct rollouts produced by the generator under its current policy. This construction conditions the targets on the very distribution the retriever is intended to improve, creating a risk that early policy errors (omitted columns or spurious ones that happen to execute) become reinforced targets. The bidirectional adaptation claim rests on the untested assumption that these frequencies supply policy-independent, improving signals; a direct comparison to static or off-policy targets is required to establish that the mechanism is load-bearing rather than circular.
minor comments (1)
- [Abstract] The abstract states performance numbers but supplies no variance estimates, ablation results, training curves, or implementation details on how the column-set pool is maintained or how credit is assigned, limiting immediate verifiability of the reported 65.3% accuracy.
Simulated Author's Rebuttal
We thank the referee for the careful analysis of the adaptive target mechanism. The concern about potential circular reinforcement is substantive and we address it directly below, including a commitment to the requested comparison experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract (mechanism description): the adaptive on-policy retrieval targets are defined as the column set most frequently associated with execution-correct rollouts produced by the generator under its current policy. This construction conditions the targets on the very distribution the retriever is intended to improve, creating a risk that early policy errors (omitted columns or spurious ones that happen to execute) become reinforced targets. The bidirectional adaptation claim rests on the untested assumption that these frequencies supply policy-independent, improving signals; a direct comparison to static or off-policy targets is required to establish that the mechanism is load-bearing rather than circular.
Authors: We agree that the on-policy construction merits explicit validation. Execution feedback is central to our design: only rollouts that produce fully correct SQL (verified by execution) contribute to the frequency counts, which excludes many early-policy errors that fail to execute. The frequency aggregation further requires consistent success across multiple samples, providing a form of empirical filtering. Nevertheless, we acknowledge that this does not constitute a formal proof of policy-independence. In the revision we will add a controlled ablation that (i) replaces the adaptive targets with static gold column sets and (ii) substitutes off-policy targets sampled from a frozen generator checkpoint. These comparisons will quantify whether the on-policy, execution-derived targets yield measurable gains in retrieval quality and end-to-end accuracy beyond what static or off-policy supervision provides. revision: yes
Circularity Check
No circularity: empirical RL uses external execution feedback; targets defined from rollouts but performance not reduced to input by construction
full rationale
The paper presents an RL framework that derives on-policy column-set targets from generator rollouts filtered by external execution correctness. This is a definitional choice of the method, not a derivation that equates the reported accuracy (65.3%) to any fitted parameter or self-citation. No equations are shown that perform a reduction, no self-citations are invoked as load-bearing uniqueness theorems, and the bidirectional adaptation claim is presented as an empirical outcome rather than a mathematical identity. The approach remains self-contained against external benchmarks (BIRD Dev execution accuracy) without internal circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Execution accuracy constitutes a reliable reward signal for credit assignment between schema retrieval and SQL generation.
invented entities (1)
-
online column-set pool
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Recent advances in
Deng, Naihao and Chen, Yulong and Zhang, Yue , booktitle=. Recent advances in
-
[2]
Next-generation database interfaces: A survey of
Hong, Zijin and Yuan, Zheng and Zhang, Qinggang and Chen, Hao and Dong, Junnan and Huang, Feiran and Huang, Xiao , journal=. Next-generation database interfaces: A survey of. 2025 , publisher=
2025
-
[3]
Pourreza, Mohammadreza and Rafiei, Davood , journal=
-
[5]
Wang, Bing and Ren, Changyu and Yang, Jian and Liang, Xinnian and Bai, Jiaqi and Chai, Linzheng and Yan, Zhao and Zhang, Qian-Wen and Yin, Di and Sun, Xing and others , booktitle=
-
[6]
2024 , publisher=
Li, Haoyang and Zhang, Jing and Liu, Hanbing and Fan, Ju and Zhang, Xiaokang and Zhu, Jun and Wei, Renjie and Pan, Hongyan and Li, Cuiping and Chen, Hong , journal=. 2024 , publisher=
2024
-
[8]
Ma, Peixian and Zhuang, Xialie and Xu, Chengjin and Jiang, Xuhui and Chen, Ran and Guo, Jian , journal=
-
[10]
Lee, Dongjun and Park, Choongwon and Kim, Jaehyuk and Park, Heesoo , booktitle=
-
[13]
2020 , eprint=
Gradient Surgery for Multi-Task Learning , author=. 2020 , eprint=
2020
-
[15]
Synthesizing
Yang, Jiaxi and Hui, Binyuan and Yang, Min and Yang, Jian and Lin, Junyang and Zhou, Chang , booktitle=. Synthesizing
-
[17]
2024 , url=
Cao Zhenbiao and Zheng Yuanlei and Fan Zhihao and Zhang Xiaojin and Chen Wei and Bai Xiang , journal=. 2024 , url=
2024
-
[20]
2024 , url=
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, YK and Wu, Yang and others , journal=. 2024 , url=
2024
-
[21]
2025 , doi=
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and others , journal=. 2025 , doi=
2025
-
[25]
2018 , eprint=
Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning , author=. 2018 , eprint=
2018
-
[27]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[29]
Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and others , booktitle=
-
[31]
Naihao Deng, Yulong Chen, and Yue Zhang. 2022. Recent advances in Text-to-SQL : A survey of what we have and what we expect. In Proceedings of the 29th International Conference on Computational Linguistics, pages 2166--2187
2022
-
[32]
Xuemei Dong, Chao Zhang, Yuhang Ge, Yuren Mao, Yunjun Gao, lu Chen, Jinshu Lin, and Dongfang Lou. 2023. https://arxiv.org/abs/2307.07306 C3 : Zero-shot Text-to-SQL with ChatGPT . Preprint, arXiv:2307.07306
arXiv 2023
-
[33]
Jakob Foerster, Nantas Nardelli, Gregory Farquhar, Triantafyllos Afouras, Philip H. S. Torr, Pushmeet Kohli, and Shimon Whiteson. 2018. https://arxiv.org/abs/1702.08887 Stabilising experience replay for deep multi-agent reinforcement learning . Preprint, arXiv:1702.08887
Pith/arXiv arXiv 2018
-
[34]
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2023. https://arxiv.org/abs/2308.15363 Text-to-SQL empowered by large language models: A benchmark evaluation . Preprint, arXiv:2308.15363
arXiv 2023
-
[35]
Michael Glass, Mustafa Eyceoz, Dharmashankar Subramanian, Gaetano Rossiello, Long Vu, and Alfio Gliozzo. 2025. https://arxiv.org/abs/2501.17174 Extractive schema linking for Text-to-SQL . Preprint, arXiv:2501.17174
arXiv 2025
-
[36]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. https://doi.org/10.1038/s41586-025-09422-z DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning . Nature, 645(8081):633--638
-
[37]
Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, and Xiao Huang. 2025. Next-generation database interfaces: A survey of LLM -based Text-to-SQL . IEEE Transactions on Knowledge and Data Engineering
2025
-
[38]
Harper Hua, Zhen Han, Zhengyuan Shen, Jeremy Lee, Patrick Guan, Qi Zhu, Sullam Jeoung, Yueyan Chen, Yunfei Bai, Shuai Wang, Vassilis Ioannidis, and Huzefa Rangwala. 2026. https://arxiv.org/abs/2601.17699 SQL-Trail : Multi-turn reinforcement learning with interleaved feedback for Text-to-SQL . Preprint, arXiv:2601.17699
arXiv 2026
-
[39]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, and 5 others. 2024. https://arxiv.org/abs/2409.12186 Qwen2.5-Coder technical report . Preprint, arXiv:2409.12186
Pith/arXiv arXiv 2024
-
[40]
Ai Jian, Xiaoyun Zhang, Wanrou Du, Jingqing Ruan, Jiangbo Pei, Weipeng Zhang, Ke Zeng, and Xunliang Cai. 2026. https://arxiv.org/abs/2603.16448 TRUST-SQL : Tool-integrated multi-turn reinforcement learning for Text-to-SQL over unknown schemas . Preprint, arXiv:2603.16448
arXiv 2026
-
[41]
Dongjun Lee, Choongwon Park, Jaehyuk Kim, and Heesoo Park. 2025. MCS-SQL : Leveraging multiple prompts and multiple-choice selection for Text-to-SQL generation. In Proceedings of the 31st International Conference on Computational Linguistics, pages 337--353
2025
-
[42]
Haoyang Li, Shang Wu, Xiaokang Zhang, Xinmei Huang, Jing Zhang, Fuxin Jiang, Shuai Wang, Tieying Zhang, Jianjun Chen, Rui Shi, Hong Chen, and Cuiping Li. 2025. https://arxiv.org/abs/2503.02240 OmniSQL : Synthesizing high-quality Text-to-SQL data at scale . Preprint, arXiv:2503.02240
arXiv 2025
-
[43]
Haoyang Li, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, and Hong Chen. 2024. CodeS : Towards building open-source language models for Text-to-SQL . Proceedings of the ACM on Management of Data, 2(3):1--28
2024
-
[44]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Rongyu Cao, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin C. C. Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. https://arxiv.org/abs/2305.03111 Can LLM already serve as a database interface? a big bench for large-scale database grounded Te...
arXiv 2023
-
[45]
Peixian Ma, Xialie Zhuang, Chengjin Xu, Xuhui Jiang, Ran Chen, and Jian Guo. 2026. SQL-R1 : Training natural language to SQL reasoning model by reinforcement learning
2026
-
[46]
Mohammadreza Pourreza and Davood Rafiei. 2023. DIN-SQL : Decomposed in-context learning of Text-to-SQL with self-correction. Advances in Neural Information Processing Systems, 36:36339--36348
2023
-
[47]
Mohammadreza Pourreza and Davood Rafiei. 2024. https://arxiv.org/abs/2402.01117 DTS-SQL : Decomposed Text-to-SQL with small large language models . Preprint, arXiv:2402.01117
arXiv 2024
-
[48]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. https://arxiv.org/abs/1707.06347 Proximal policy optimization algorithms . Preprint, arXiv:1707.06347
Pith/arXiv arXiv 2017
-
[49]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. https://dblp.org/rec/journals/corr/abs-2402-03300 DeepSeekMath : Pushing the limits of mathematical reasoning in open language models
2024
-
[50]
Lei Sheng, Shuai-Shuai Xu, and Wei Xie. 2025. https://arxiv.org/abs/2502.10739 BASE-SQL : A powerful open source Text-to-SQL baseline approach . Preprint, arXiv:2502.10739
arXiv 2025
-
[51]
Jinwang Song, Hongying Zan, Kunli Zhang, Lingling Mu, Yingjie Han, Haobo Hua, and Min Peng. 2025. https://arxiv.org/abs/2505.14305 JOLT-SQL : Joint loss tuning of Text-to-SQL with confusion-aware noisy schema sampling . Preprint, arXiv:2505.14305
arXiv 2025
-
[52]
Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, Linzheng Chai, Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun, and 1 others. 2025. MAC-SQL : A multi-agent collaborative framework for Text-to-SQL . In Proceedings of the 31st International Conference on Computational Linguistics, pages 540--557
2025
-
[53]
Zekun Xu, Siyu Xia, Chuhuai Yue, Jiajun Chai, Mingxue Tian, Xiaohan Wang, Wei Lin, Haoxuan Li, and Guojun Yin. 2025. https://arxiv.org/abs/2510.25510 MTIR-SQL : Multi-turn tool-integrated reasoning reinforcement learning for Text-to-SQL . Preprint, arXiv:2510.25510
arXiv 2025
-
[54]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[55]
Jiaxi Yang, Binyuan Hui, Min Yang, Jian Yang, Junyang Lin, and Chang Zhou. 2024. Synthesizing Text-to-SQL data from weak and strong LLMs . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7864--7875
2024
-
[56]
Zhewei Yao, Guoheng Sun, Lukasz Borchmann, Gaurav Nuti, Zheyu Shen, Minghang Deng, Bohan Zhai, Hao Zhang, Ang Li, and Yuxiong He. 2026. https://arxiv.org/abs/2505.20315 Arctic-Text2SQL-R1 : Simple rewards, strong reasoning in Text-to-SQL . Preprint, arXiv:2505.20315
arXiv 2026
-
[57]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, and 1 others. 2018. Spider : A large-scale human-labeled dataset for complex and cross-domain semantic parsing and Text-to-SQL task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3911--3921
2018
-
[58]
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. 2020. https://arxiv.org/abs/2001.06782 Gradient surgery for multi-task learning . Preprint, arXiv:2001.06782
arXiv 2020
-
[59]
Cao Zhenbiao, Zheng Yuanlei, Fan Zhihao, Zhang Xiaojin, Chen Wei, and Bai Xiang. 2024. https://dblp.org/rec/journals/corr/abs-2411-00073 RSL-SQL : Robust schema linking in Text-to-SQL generation
2024
-
[60]
Victor Zhong, Caiming Xiong, and Richard Socher. 2017. https://arxiv.org/abs/1709.00103 Seq2SQL : Generating structured queries from natural language using reinforcement learning . Preprint, arXiv:1709.00103
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.