Universal Encoders for Modular Relational Deep Learning
Pith reviewed 2026-06-26 14:42 UTC · model grok-4.3
The pith
A pretrained universal row encoder decouples feature encoding from graph message-passing to serve as a reusable backend that transfers relational knowledge across databases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
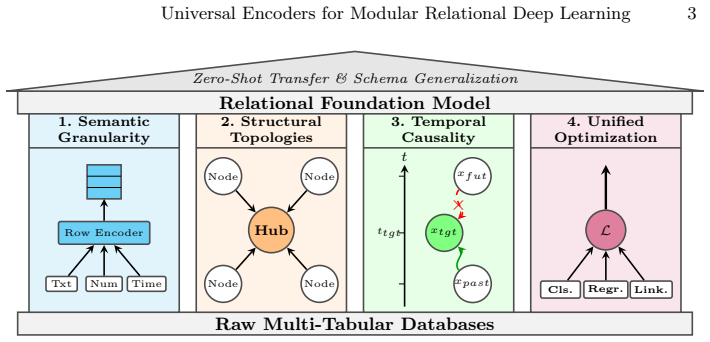
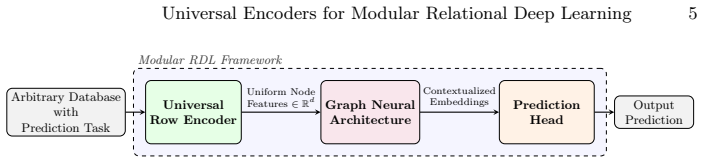
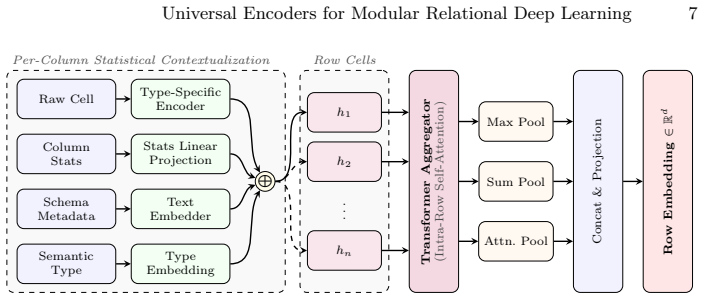
The central claim is that a Universal Row Encoder, built as a transformer that ingests raw cell values together with schema metadata and global distribution statistics, produces table-width invariant row embeddings through intra-row self-attention; when pretrained, this encoder functions as a modular backend for arbitrary graph message-passing layers, enabling native handling of unseen features and sparse data while delivering improved cross-database transfer on RelBench benchmarks along with faster convergence and reduced memory footprint.
What carries the argument
The Universal Row Encoder, a transformer module that feeds global distribution statistics into intra-row self-attention to produce table-width invariant embeddings from raw cells plus schema metadata.
If this is right
- The encoder can be pretrained once and reused as a backend for any relational graph architecture without retraining the encoding step.
- Cross-database knowledge transfer improves on established RelBench benchmarks.
- Learning convergence speeds up and memory footprint decreases compared with monolithic alternatives.
- Unseen features and sparse entries are handled natively inside the attention mechanism.
Where Pith is reading between the lines
- The modularity could let practitioners replace the encoder with a larger or domain-adapted version while keeping the same graph layers fixed.
- The same global-statistics approach might reduce data-preparation overhead in other multi-table settings such as time-series forecasting over joined tables.
- If the encoder generalizes, it could serve as a starting point for scaling laws experiments that vary encoder size independently of graph depth.
Load-bearing premise
That feeding global distribution statistics into intra-row self-attention lets the encoder handle unseen features and sparse data without schema-specific retraining or entanglement with message-passing.
What would settle it
A controlled test in which the pretrained universal encoder shows no improvement in accuracy or convergence over a schema-specific baseline when both are evaluated on a previously unseen database with different tables and feature distributions would falsify the transfer claim.
Figures
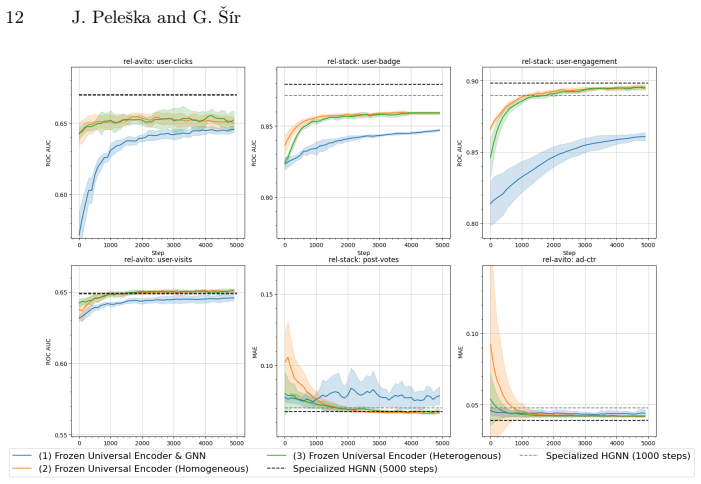
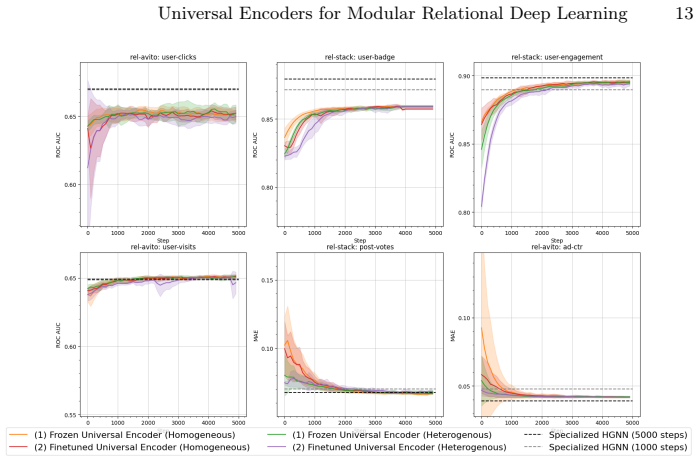
read the original abstract
Relational Deep Learning (RDL) models multi-tabular databases as temporal heterogeneous graphs for end-to-end representation learning. While RDL is evolving rapidly, existing approaches face significant generalization obstacles. They are either schema-specific, requiring training from scratch for every new database, or they rely on monolithic architectures that entangle feature encoding with graph message-passing. Analyzing these limitations, we establish four core pillars for building foundational relational models: semantic granularity, structural topology, temporal causality, and unified optimization. Addressing these pillars, we propose a modular approach that decouples row encoding from graph message-passing. We introduce the Universal Row Encoder, a transformer-based module that integrates raw cell data with schema metadata$-$including column semantics, table names, and global distribution statistics$-$to produce table-width invariant row embeddings. By explicitly feeding global statistics to an intra-row self-attention mechanism, the encoder natively contextualizes unseen features and handles sparse data. Serving as a flexible "backend" for any downstream graph architecture, our pretrained encoder enhances cross-database knowledge transfer on the established RelBench benchmarks while improving learning convergence and memory footprint.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a modular architecture for Relational Deep Learning (RDL) that decouples row encoding from graph message-passing. It introduces a transformer-based Universal Row Encoder that integrates raw cell data with schema metadata (column semantics, table names, global distribution statistics) to produce table-width invariant row embeddings. By feeding global statistics into intra-row self-attention, the encoder is claimed to natively handle unseen features and sparse data. Pretrained as a backend for downstream graph architectures, it is asserted to improve cross-database knowledge transfer on RelBench benchmarks along with convergence and memory footprint. The approach is motivated by four pillars: semantic granularity, structural topology, temporal causality, and unified optimization.
Significance. If the architectural claims hold with supporting evidence, the modular separation could enable reusable pretrained encoders across heterogeneous databases, reducing the need for schema-specific retraining and potentially improving efficiency in RDL pipelines. The absence of any quantitative results, ablations, or implementation details in the manuscript, however, prevents assessment of whether the proposed mechanism delivers the claimed generalization or efficiency gains.
major comments (2)
- [Abstract] Abstract: The central claim that 'explicitly feeding global statistics to an intra-row self-attention mechanism' enables native contextualization of unseen features and cross-database transfer provides no specification of (a) which distribution statistics are computed, (b) their exact encoding into the transformer (extra tokens, concatenated features, or positional encodings), or (c) how column-name or table-name metadata bridges semantic gaps when both identity and distribution are novel. This detail is load-bearing for the generalization argument.
- [Abstract] Abstract: The performance assertions ('enhances cross-database knowledge transfer on the established RelBench benchmarks while improving learning convergence and memory footprint') are stated without any quantitative results, error bars, ablation studies, or implementation details, so the central empirical claims cannot be evaluated.
Simulated Author's Rebuttal
Thank you for the detailed review. We address each of the major comments below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'explicitly feeding global statistics to an intra-row self-attention mechanism' enables native contextualization of unseen features and cross-database transfer provides no specification of (a) which distribution statistics are computed, (b) their exact encoding into the transformer (extra tokens, concatenated features, or positional encodings), or (c) how column-name or table-name metadata bridges semantic gaps when both identity and distribution are novel. This detail is load-bearing for the generalization argument.
Authors: The abstract is necessarily brief, but the full paper provides these specifications in Section 3.1. We compute the following distribution statistics for each column: mean, standard deviation, minimum, maximum, and quartiles. These are incorporated as additional input tokens to the transformer, each with a type embedding indicating the statistic. Column and table names are embedded using a shared vocabulary and concatenated to the cell value embeddings before the self-attention layers. This allows the model to use semantic information from names even for unseen columns, with global stats providing distributional context. We will update the abstract to include a high-level mention of these mechanisms. revision: yes
-
Referee: [Abstract] Abstract: The performance assertions ('enhances cross-database knowledge transfer on the established RelBench benchmarks while improving learning convergence and memory footprint') are stated without any quantitative results, error bars, ablation studies, or implementation details, so the central empirical claims cannot be evaluated.
Authors: We acknowledge that the current version of the manuscript does not include the quantitative results, ablations, or implementation details supporting the performance claims. This is a valid point, and we will revise the manuscript to include preliminary results from our RelBench experiments, including error bars and ablations, to substantiate the claims. revision: yes
Circularity Check
No circularity: architectural proposal with no equations or self-referential derivations
full rationale
The paper proposes a modular Universal Row Encoder architecture that integrates cell data with metadata and global statistics via intra-row self-attention. No equations, fitted parameters, or predictions are presented that reduce to the inputs by construction. The central claims rest on the described mechanism rather than any self-definition, fitted-input prediction, or load-bearing self-citation chain. The contribution is self-contained as an engineering design without mathematical reduction to its own assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic granularity, structural topology, temporal causality, and unified optimization are the four core pillars required for foundational relational models.
invented entities (1)
-
Universal Row Encoder
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems (2020)
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Win- ter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford...
2020
-
[2]
Chen, T., Kanatsoulis, C., Leskovec, J.: RelGNN: Composite Message Passing for Relational Deep Learning (Feb 2025).https://doi.org/10.48550/arXiv.2502. 06784, arXiv:2502.06784 [cs]
-
[3]
arXiv preprint arXiv:2002.02046 (2020)
Cvitkovic, M.: Supervised learning on relational databases with graph neural net- works. arXiv preprint arXiv:2002.02046 (2020)
arXiv 2002
-
[4]
Dwivedi, V.P., Jaladi, S., Shen, Y., López, F., Kanatsoulis, C.I., Puri, R., Fey, M., Leskovec, J.: Relational Graph Transformer (May 2025).https://doi.org/ 10.48550/arXiv.2505.10960, arXiv:2505.10960 [cs]
-
[5]
In: Proceedings of the 41st Inter- national Conference on Machine Learning
Fey, M., Hu, W., Huang, K., Lenssen, J.E., Ranjan, R., Robinson, J., Ying, R., You, J., Leskovec, J.: Position: Relational Deep Learning - Graph Repre- sentation Learning on Relational Databases. In: Proceedings of the 41st Inter- national Conference on Machine Learning. pp. 13592–13607. PMLR (Jul 2024), https://proceedings.mlr.press/v235/fey24a.html, iSS...
2024
-
[6]
ACM Computing Surveys46(4), 44:1–44:37 (2014) Universal Encoders for Modular Relational Deep Learning 17
Gama, J., Žliobait¯ e, I., Bifet, A., Pechenizkiy, M., Bouchachia, A.: A survey on concept drift adaptation. ACM Computing Surveys46(4), 44:1–44:37 (2014) Universal Encoders for Modular Relational Deep Learning 17
2014
-
[7]
Gu, J., Ranjan, R., Kanatsoulis, C., Tang, H., Jurkovic, M., Hudovernik, V., Znidar, M., Chaturvedi, P., Shroff, P., Li, F., Leskovec, J.: RelBench v2: A Large-Scale Benchmark and Repository for Relational Data (Feb 2026).https: //doi.org/10.48550/arXiv.2602.12606, arXiv:2602.12606 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.12606 2026
-
[8]
In: Advances in Neural Information Processing Systems (2017)
Hamilton, W.L., Ying, R., Leskovec, J.: Inductive Representation Learning on Large Graphs. In: Advances in Neural Information Processing Systems (2017)
2017
-
[9]
Hollmann, N., Müller, S., Purucker, L., Krishnakumar, A., Körfer, M., Hoo, S.B., Schirrmeister, R.T., Hutter, F.: Accurate predictions on small data with a tabular foundation model. Nature637(8045), 319–326 (Jan 2025).https: //doi.org/10.1038/s41586-024-08328-6,https://www.nature.com/articles/ s41586-024-08328-6, publisher: Nature Publishing Group
-
[10]
In: Pro- ceedings of the web conference 2020
Hu, Z., Dong, Y., Wang, K., Sun, Y.: Heterogeneous graph transformer. In: Pro- ceedings of the web conference 2020. pp. 2704–2710 (2020)
2020
-
[11]
In: arXiv preprint arXiv:2012.06678 (2020)
Huang, X., Khetan, A., Cvitkovic, M., Karnin, Z.: Tabtransformer: Tabular data modeling using contextual embeddings. In: arXiv preprint arXiv:2012.06678 (2020)
Pith/arXiv arXiv 2012
-
[12]
thesis, Univerza v Ljubljani, Fakulteta za računalništvo in informatiko (2025)
Hudovernik, V.: Deep Learning Methods for Synthetic Relational Data Generation. thesis, Univerza v Ljubljani, Fakulteta za računalništvo in informatiko (2025)
2025
-
[13]
Kocijan, V., Sunil, J., Lenssen, J.E., Deb, V., Xe, X., Gomez, F.R., Fey, M., Leskovec, J.: Predictive Query Language: A Domain-Specific Language for Predic- tive Modeling on Relational Databases (Feb 2026).https://doi.org/10.48550/ arXiv.2602.09572, arXiv:2602.09572 [cs]
arXiv 2026
-
[14]
Kothapalli, V., Ranjan, R., Hudovernik, V., Dwivedi, V.P., Hoffart, J., Guestrin, C., Leskovec, J.: PluRel: Synthetic Data unlocks Scaling Laws for Relational Foundation Models (Feb 2026).https://doi.org/10.48550/arXiv.2602.04029, arXiv:2602.04029 [cs]
-
[15]
Relational data mining pp
Kramer, S., Lavrač, N., Flach, P.: Propositionalization approaches to relational data mining. Relational data mining pp. 262–291 (2001)
2001
-
[16]
Lachi, D., Mohammadi, M., Meyer, J., Arora, V., Palczewski, T., Dyer, E.L.: Integrating Temporal and Structural Context in Graph Transformers for Rela- tionalDeepLearning(Nov2025).https://doi.org/10.48550/arXiv.2511.04557, http://arxiv.org/abs/2511.04557, arXiv:2511.04557 [cs.LG]
-
[17]
Lachi, V., Longa, A., Bevilacqua, B., Lepri, B., Passerini, A., Ribeiro, B.: Boosting Relational Deep Learning with Pretrained Tabular Models (Apr 2025).https: //doi.org/10.48550/arXiv.2504.04934, arXiv:2504.04934 [cs]
-
[18]
In: Proceed- ings of the 36th International Conference on Machine Learning (2019)
Lee, J., Lee, Y., Kim, J., Kosiorek, A., Choi, S., Teh, Y.W.: Set transformer: A framework for attention-based permutation-invariant neural networks. In: Proceed- ings of the 36th International Conference on Machine Learning (2019)
2019
-
[19]
arXiv preprint arXiv:1511.03086 (2015)
Motl, J., Schulte, O.: The CTU Prague Relational Learning Repository. arXiv preprint arXiv:1511.03086 (2015)
arXiv 2015
-
[20]
In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases
Peleška, J., Šír, G.: Task-agnostic contrastive pretraining for relational deep learn- ing. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases. pp. 623–638. Springer (2025)
2025
-
[21]
In: Ribeiro, R.P., Pfahringer, B., Japkowicz, N., Larrañaga, P., Jorge, A.M., Soares, C., Abreu, P.H., Gama, J
Peleška, J., Šír, G.: ReDeLEx: A Framework for Relational Deep Learning Explo- ration. In: Ribeiro, R.P., Pfahringer, B., Japkowicz, N., Larrañaga, P., Jorge, A.M., Soares, C., Abreu, P.H., Gama, J. (eds.) Machine Learning and Knowledge Dis- covery in Databases. Research Track. pp. 438–456. Springer Nature Switzerland, Cham (Sep 2025)
2025
-
[22]
ACM Trans
Peleška, J., Šír, G.: Tabular Transformers Meet Relational Databases. ACM Trans. Intell. Syst. Technol.16(5), 115:1–115:24 (Sep 2025).https://doi.org/10.1145/ 3749991 18 J. Peleška and G. Šír
2025
-
[23]
In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (2014)
Pennington, J., Socher, R., Manning, C.D.: GloVe: Global Vectors for Word Repre- sentation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (2014)
2014
-
[24]
Re- lational transformer: Toward zero-shot foundation models for relational data, 2026
Ranjan, R., Hudovernik, V., Znidar, M., Kanatsoulis, C., Upendra, R., Moham- madi, M., Meyer, J., Palczewski, T., Guestrin, C., Leskovec, J.: Relational Trans- former: Toward Zero-Shot Foundation Models for Relational Data (Oct 2025). https://doi.org/10.48550/arXiv.2510.06377, arXiv:2510.06377 [cs]
-
[25]
In: The Thirty-eight Conference on Neural In- formation Processing Systems Datasets and Benchmarks Track (2024)
Robinson, J., Ranjan, R., Hu, W., Huang, K., Han, J., Dobles, A., Fey, M., Lenssen, J.E., Yuan, Y., Zhang, Z., He, X., Leskovec, J.: RelBench: A Benchmark for Deep Learning on Relational Databases. In: The Thirty-eight Conference on Neural In- formation Processing Systems Datasets and Benchmarks Track (2024)
2024
-
[26]
In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Vogel, L., Bodensohn, J.M., Binnig, C.: WikiDBs: A Large-Scale Corpus Of Relational Databases From Wikidata. In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (eds.) Advances in Neural Information Processing Systems. vol. 37, pp. 41186–41201. Curran Associates, Inc. (2024),https://proceedings.neurips.cc/paper_files/p...
2024
-
[27]
arXiv preprint arXiv:2402.05672 (2024)
Wang, L., Yang, N., Huang, X., Yang, L., Majumder, R., Wei, F.: Multilingual e5 text embeddings: A technical report. arXiv preprint arXiv:2402.05672 (2024)
Pith/arXiv arXiv 2024
-
[28]
Advances in Neural Information Processing Systems 37, 27236–27273 (2024)
Wang, M., Gan, Q., Wipf, D., Cai, Z., Li, N., Tang, J., Zhang, Y., Zhang, Z., Mao, Z., Song, Y., et al.: 4dbinfer: A 4d benchmarking toolbox for graph-centric predictive modeling on rdbs. Advances in Neural Information Processing Systems 37, 27236–27273 (2024)
2024
-
[29]
Advances in neural information processing systems33, 5776–5788 (2020)
Wang, W., Wei, F., Dong, L., Bao, H., Yang, N., Zhou, M.: Minilm: Deep self- attention distillation for task-agnostic compression of pre-trained transformers. Advances in neural information processing systems33, 5776–5788 (2020)
2020
-
[30]
Griffin: Towards a graph-centric relational database foundation model, 2025
Wang, Y., Wang, X., Gan, Q., Wang, M., Yang, Q., Wipf, D., Zhang, M.: Grif- fin: Towards a Graph-Centric Relational Database Foundation Model (May 2025). https://doi.org/10.48550/arXiv.2505.05568, arXiv:2505.05568 [cs]
-
[31]
In: CIDR (2025)
Wehrstein, J., Binnig, C., Özcan, F., Vasudevan, S., Gan, Y., Wang, Y.: Towards foundation database models. In: CIDR (2025)
2025
-
[32]
In: Proceedings of the 63rd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers)
Wu, F., Dwivedi, V.P., Leskovec, J.: Large language models are good relational learners. In: Proceedings of the 63rd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers). pp. 7835–7854 (2025)
2025
-
[33]
In: Advances in Neural Information Processing Systems
Yun, S., Jeong, M., Kim, R., Kang, J., Kim, H.J.: Graph Transformer Net- works. In: Advances in Neural Information Processing Systems. vol. 32. Curran Associates, Inc. (2019),https://proceedings.neurips.cc/paper/2019/hash/ 9d63484abb477c97640154d40595a3bb-Abstract.html
2019
-
[34]
In: Advances in Neural Information Processing Systems (2017)
Zaheer, M., Kottur, S., Ravanbakhsh, S., Póczos, B., Salakhutdinov, R.R., Smola, A.J.: Deep sets. In: Advances in Neural Information Processing Systems (2017)
2017
-
[35]
In: NeurIPS 2023 Second Table Representation Learning Workshop (2023)
Zahradník, L., Neumann, J., Šír, G.: A Deep Learning Blueprint for Relational Databases. In: NeurIPS 2023 Second Table Representation Learning Workshop (2023)
2023
-
[36]
Zhang, C., Song, D., Huang, C., Swami, A., Chawla, N.V.: Heterogeneous Graph Neural Network. In: Proceedings of the 25th ACM SIGKDD International Con- ference on Knowledge Discovery & Data Mining. pp. 793–803. KDD ’19, As- sociation for Computing Machinery, New York, NY, USA (Jul 2019).https: //doi.org/10.1145/3292500.3330961
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.