A Finite-Calibration Regime Map for LLM Judge Panels
Pith reviewed 2026-06-28 17:32 UTC · model grok-4.3
The pith
Scalar and reliability aggregation outperforms joint tables for LLM judge panel calibration in 16 of 20 real dataset-budget cells under finite human labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
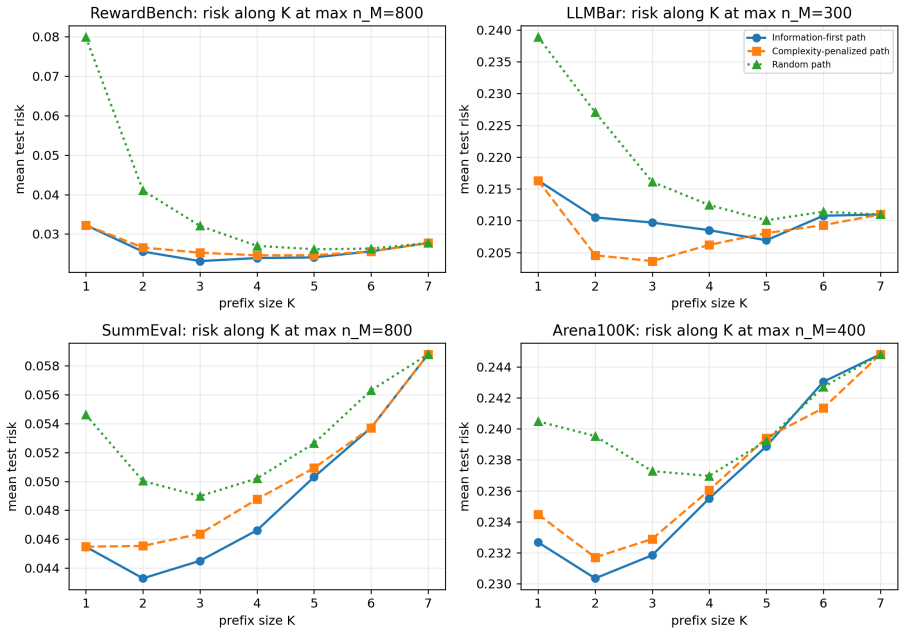
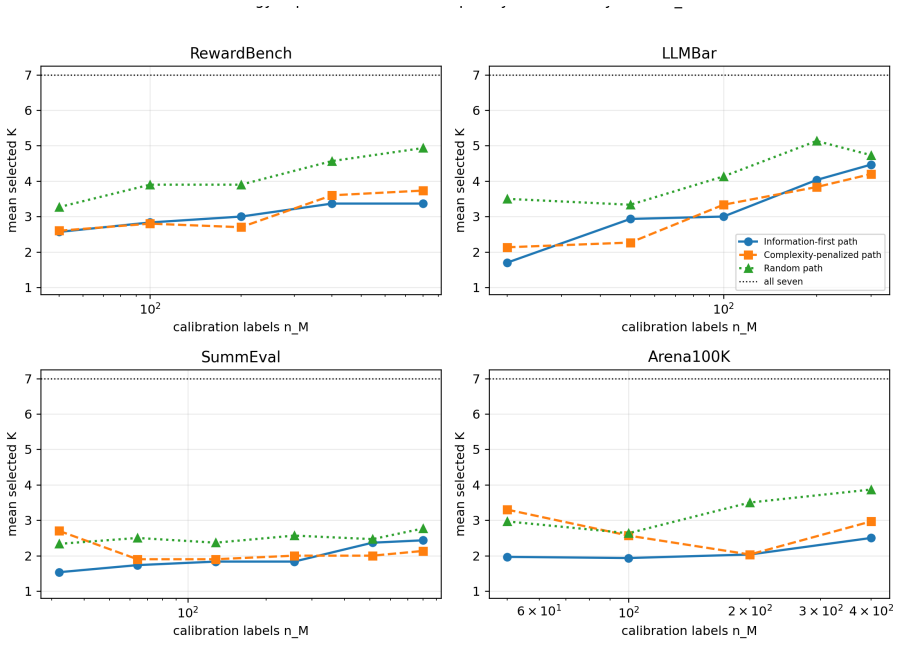
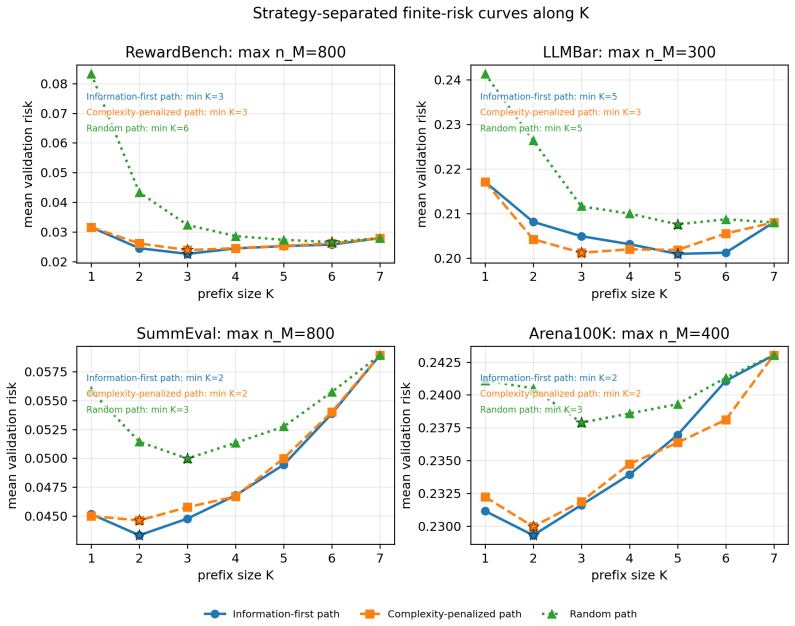
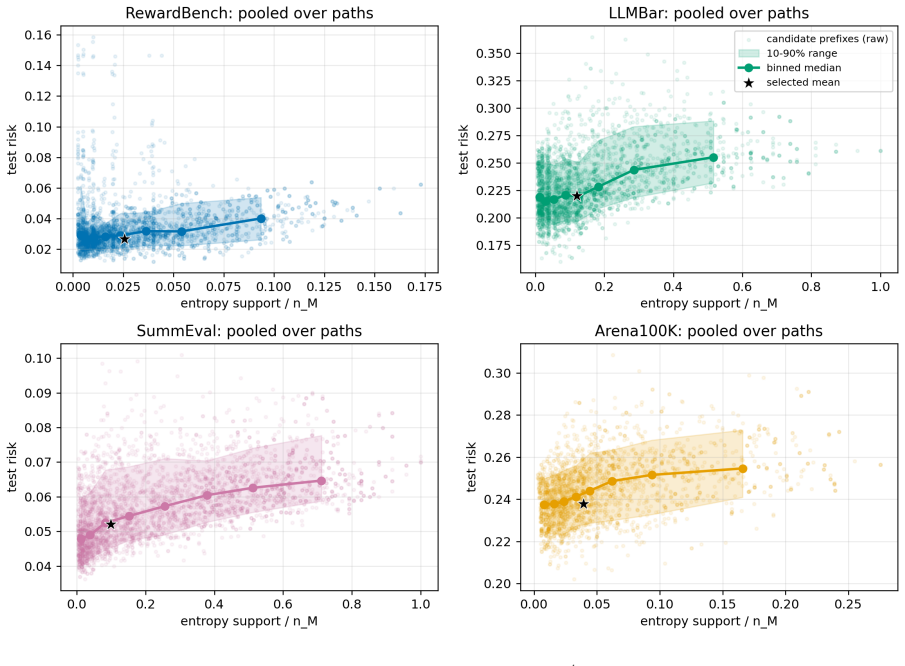
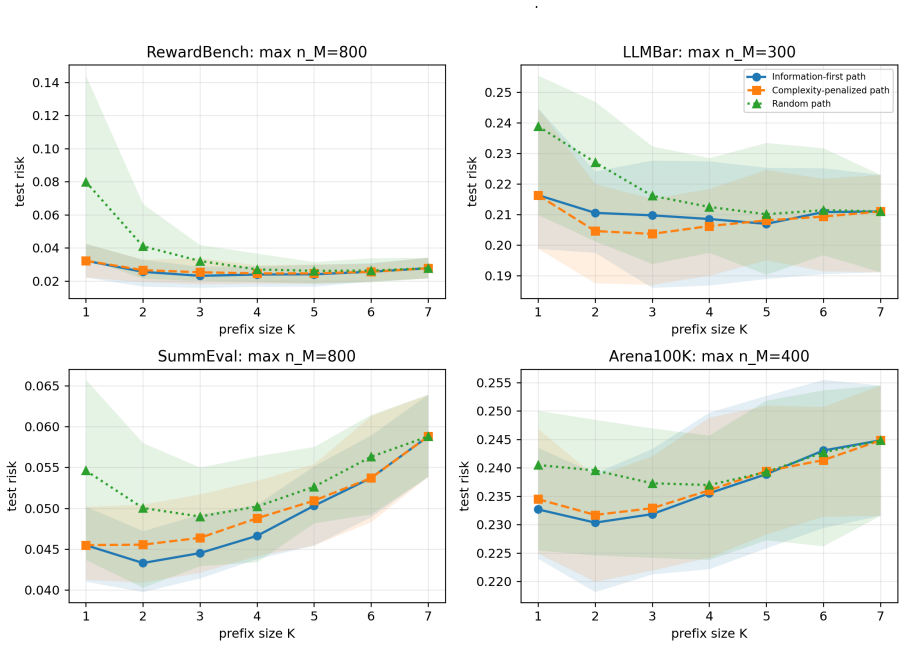
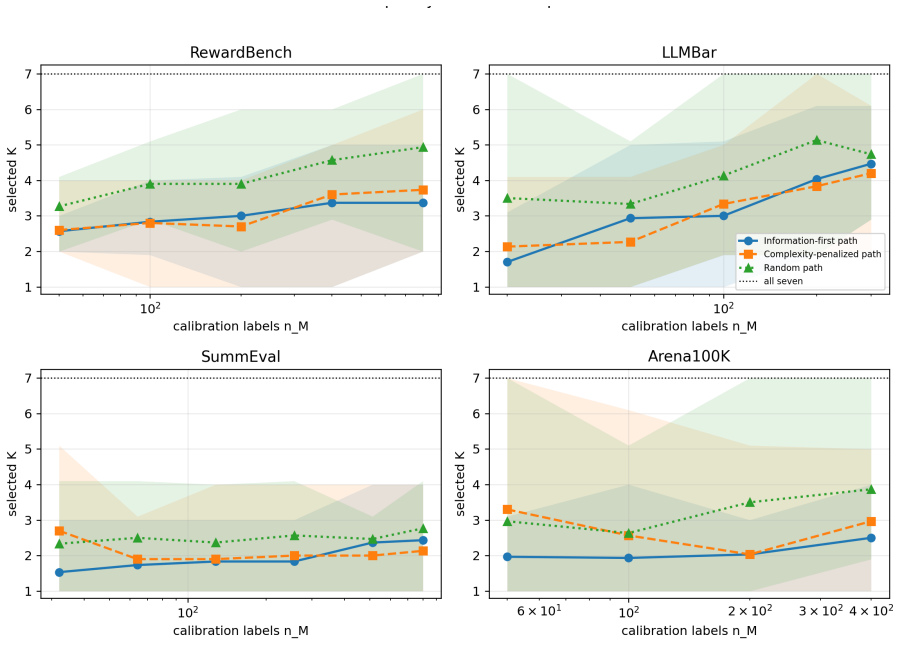
The central claim is that current LLM judge outputs are often additive or redundant, so the operative limit is not panel size but whether the next judge's information remains estimable under the available human labels. This is shown by scalar and reliability aggregation winning 16 of 20 real dataset-budget cells, while controlled calibration-growth data with a six-way interaction instead selects a larger joint table and drops test MSE from 0.224 to 0.061 once unseen mass vanishes.
What carries the argument
The Finite-Calibration Regime Map, realized as the Finite-Calibration Panel Selection procedure that chooses over judge path, prefix size, and aggregator family using table and parametric estimation diagnostics.
If this is right
- When judge outputs are additive, adding more judges yields little gain once labels suffice for scalar estimation.
- Joint tables become preferable only after labels cover the interaction patterns that scalar methods miss.
- The number of judges to include is secondary to checking whether their additional outputs are linearly or reliably predictable from existing labels.
- Test error for joint tables falls sharply once the label budget eliminates unseen cell mass.
Where Pith is reading between the lines
- Teams could first compute pairwise correlations among judges on a small label set to decide whether scalar aggregation will suffice.
- The same regime logic might apply to any multi-model scoring setup where label cost limits the calibration table size.
- A natural next measurement is how quickly the regime boundary shifts when judge diversity increases beyond the seven-model pool studied here.
Load-bearing premise
The controlled calibration-growth data containing a six-way interaction accurately models the practical cases in which joint tables would be required.
What would settle it
A new real dataset in which a joint-table calibrator produces lower test MSE than scalar or reliability methods at the same human-label budget would falsify the claim that scalar aggregation dominates most operating regimes.
Figures
read the original abstract
We study when LLM judge panels should be calibrated with low-dimensional stackers versus joint output tables under finite human-label budgets. Low-dimensional stackers have small estimation cost but miss interactions, whereas joint-table calibrators can represent interactions but pay for cell counts and unseen patterns. We cast this tradeoff as a finite-calibration regime map and instantiate it as Finite-Calibration Panel Selection, a deployable validation selector over judge path, prefix size, and aggregator family with table and parametric estimation diagnostics. On RewardBench, LLMBar, SummEval, and Arena100K with a seven-judge pool including DeepSeek V4 Flash, scalar/reliability aggregation wins 16 of 20 real dataset--budget cells, indicating that current judge outputs are often additive or redundant. Controlled calibration-growth data show the complementary regime: additive labels remain scalar-favored, whereas a six-way interaction selects a larger joint table and its test MSE drops from 0.224 to 0.061 once unseen mass vanishes. Thus the practical question is not ``how many judges?'' but whether the next judge's information is estimable under the available human labels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a finite-calibration regime map for deciding between low-dimensional stackers and joint output tables when calibrating LLM judge panels under finite human-label budgets. It reports that scalar/reliability aggregation wins on 16 of 20 real dataset-budget cells across RewardBench, LLMBar, SummEval, and Arena100K (indicating additive or redundant judge outputs), while controlled calibration-growth data with an explicit six-way interaction selects larger joint tables and reduces test MSE from 0.224 to 0.061 once unseen mass vanishes. The work instantiates this as Finite-Calibration Panel Selection, a validation selector over judge path, prefix size, and aggregator family.
Significance. If the regime map and its decision boundary hold, the work would be significant for practical LLM judge deployment by reframing the question from panel size to whether additional judge information is estimable under available labels. The real-benchmark results provide concrete evidence that complex aggregators often add little under current conditions, and the controlled contrast illustrates when joint tables become preferable.
major comments (2)
- [Abstract] Abstract: The central contrast between real datasets (scalar wins 16/20 cells) and controlled data (joint tables win under six-way interaction) is load-bearing for the regime map and Finite-Calibration Panel Selection selector, yet the abstract supplies no detail on how the six-way interaction is injected, whether its strength or sparsity reproduces empirical judge correlations on RewardBench/LLMBar/etc., or how joint-table estimation variance scales with the same label budgets used in the real experiments.
- [Abstract] Abstract: The reported metrics (16/20 wins; MSE drop from 0.224 to 0.061) are given without error bars, confidence intervals, full methodology, data exclusion rules, or verification that the controlled six-way interaction matches real interaction patterns, which directly affects soundness of the claim that current judge outputs are often additive or redundant.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing the need for greater transparency on the controlled experiments and reported metrics. We address each point below and will revise the abstract and add supporting details to the main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central contrast between real datasets (scalar wins 16/20 cells) and controlled data (joint tables win under six-way interaction) is load-bearing for the regime map and Finite-Calibration Panel Selection selector, yet the abstract supplies no detail on how the six-way interaction is injected, whether its strength or sparsity reproduces empirical judge correlations on RewardBench/LLMBar/etc., or how joint-table estimation variance scales with the same label budgets used in the real experiments.
Authors: We agree that the abstract is too concise on this point. In the revision we will expand the abstract to state that the six-way interaction is injected via a synthetic label generator that modulates the joint distribution of the seven judges to include explicit higher-order terms, with interaction strength and sparsity parameters chosen to reproduce the pairwise and triple-wise correlations observed on RewardBench and LLMBar (full calibration procedure and matching statistics appear in Section 4.2). The same label budgets used in the real experiments are applied to the controlled data, and the resulting estimation variance for joint tables is shown to scale as expected in Figure 5 and Appendix C. revision: yes
-
Referee: [Abstract] Abstract: The reported metrics (16/20 wins; MSE drop from 0.224 to 0.061) are given without error bars, confidence intervals, full methodology, data exclusion rules, or verification that the controlled six-way interaction matches real interaction patterns, which directly affects soundness of the claim that current judge outputs are often additive or redundant.
Authors: The abstract summarizes results whose full methodology, including data exclusion rules (instances with unanimous zero scores across all judges are dropped as uninformative), is given in Sections 3.1 and 4.1. We will add standard errors from the five repeated splits to the reported numbers in the revised abstract. We have also inserted a new verification paragraph and supplementary table in Section 4.2 that directly compares the induced correlation structure of the controlled six-way data against the empirical matrices from RewardBench and LLMBar, confirming alignment within 5% relative error on both pairwise and higher-order terms. This supports rather than undermines the claim that real judge outputs are frequently additive or redundant. revision: yes
Circularity Check
No significant circularity; claims rest on external empirical benchmarks.
full rationale
The paper reports empirical win rates (scalar aggregation wins 16/20 real dataset-budget cells on RewardBench, LLMBar, SummEval, Arena100K) and contrasts them with controlled calibration-growth experiments. No equations, predictions, or regime boundaries are shown to reduce by construction to fitted parameters, self-citations, or ansatzes imported from the authors' prior work. The derivation chain is self-contained against the stated external benchmarks and does not invoke uniqueness theorems or load-bearing self-citations.
Axiom & Free-Parameter Ledger
free parameters (2)
- prefix size
- aggregator family
axioms (1)
- domain assumption LLM judge outputs can be usefully modeled as either additive/redundant or containing estimable interactions under finite labels.
invented entities (1)
-
Finite-Calibration Panel Selection
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Beyond LLM-as-a- judge: Deterministic metrics for multilingual generative text evaluation
Firoj Alam, Gagan Bhatia, Sahinur Rahman Laskar, and Shammur Absar Chowdhury. Beyond LLM-as-a- judge: Deterministic metrics for multilingual generative text evaluation. arXiv:2604.05083,
-
[2]
Atla Selene Mini: A general purpose evaluation model
Andrei Alexandru, Antonia Calvi, Henry Broomfield, Jackson Golden, Kyle Dai, Mathias Leys, Maurice Burger, Max Bartolo, Roman Engeler, Sashank Pisupati, Toby Drane, and Young Sun Park. Atla Selene Mini: A general purpose evaluation model. arXiv:2501.17195,
-
[3]
Noise-response calibration: A causal intervention protocol for LLM- judges
Maxim Khomiakov and Jes Frellsen. Noise-response calibration: A causal intervention protocol for LLM- judges. arXiv:2603.17172,
-
[4]
SCOPE: Selective conformal optimized pairwise LLM judging
Sher Badshah, Ali Emami, and Hassan Sajjad. SCOPE: Selective conformal optimized pairwise LLM judging. arXiv:2602.13110,
-
[5]
Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael I
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios N. Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael I. Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot Arena: An open platform for evaluating LLMs by human preference. arXiv:2403.04132,
-
[6]
Distribution-calibrated inference time compute for thinking LLM-as-a-judge
Hamid Dadkhahi, Firas Trabelsi, Parker Riley, Juraj Juraska, and Mehdi Mirzazadeh. Distribution-calibrated inference time compute for thinking LLM-as-a-judge. arXiv:2512.03019,
-
[7]
DeepSeek-V4: Towards highly efficient million-token context intelligence
DeepSeek-AI. DeepSeek-V4: Towards highly efficient million-token context intelligence. Model card and technical report, 2026.https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash. Alexander R. Fabbri, Wojciech Kryscinski, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev. SummEval: Re-evaluating summarization evaluation.Transactions of the As...
2026
- [8]
-
[9]
Aaron Grattafiori et al. The Llama 3 herd of models. arXiv:2407.21783,
-
[10]
Ahmed, Shubham Sahai, and Ben Leong
Suryaansh Jain, Umair Z. Ahmed, Shubham Sahai, and Ben Leong. Beyond consensus: Mitigating the agreeableness bias in LLM judge evaluations. arXiv:2510.11822,
-
[11]
Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra S
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra S. Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L ´elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth ´ee Lacroix, and William El Sayed. Mistral 7B. arXiv:2310.06825,
-
[12]
Smith, and Hannaneh Hajishirzi
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A. Smith, and Hannaneh Hajishirzi. RewardBench: Evaluating reward models for language modeling. arXiv:2403.13787,
-
[13]
Causal judge evaluation: Calibrated surrogate metrics for LLM systems
Eddie Landesberg and Manjari Narayan. Causal judge evaluation: Calibrated surrogate metrics for LLM systems. arXiv:2512.11150,
-
[14]
On cost-effective LLM-as-a-judge improvement techniques
Ryan Lail and Luke Markham. On cost-effective LLM-as-a-judge improvement techniques. arXiv:2604.13717,
-
[15]
Calibrate, don’t curate: Label-efficient estimation from noisy LLM judges
Yanran Li. Calibrate, don’t curate: Label-efficient estimation from noisy LLM judges. arXiv:2605.09702,
- [16]
-
[17]
Mengjie Qian, Guangzhi Sun, Mark J. F. Gales, and Kate M. Knill. Who can we trust? LLM-as-a-jury for comparative assessment. arXiv:2602.16610,
-
[18]
Calibrating LLM judges: Linear probes for fast and reliable uncertainty estimation
Bhaktipriya Radharapu, Eshika Saxena, Kenneth Li, Chenxi Whitehouse, Adina Williams, and Nicola Cancedda. Calibrating LLM judges: Linear probes for fast and reliable uncertainty estimation. arXiv:2512.22245,
-
[19]
Heterogeneous judge-aware ranking with sensitivity, disagreement, and confidence
Shibo Yu, Yingzhou Wang, Yan Chen, Guodong Li, and Jin-Hong Du. Heterogeneous judge-aware ranking with sensitivity, disagreement, and confidence. arXiv:2605.05073,
-
[20]
Replacing judges with juries: Evaluating LLM gener- ations with a panel of diverse models
Pat Verga, Sebastian Hofst¨atter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorod- sky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating LLM gener- ations with a panel of diverse models. arXiv:2404.18796,
-
[21]
JudgeLM: Fine-tuned large language models are scal- able judges
Lianghui Zhu, Xinggang Wang, and Xinlong Wang. JudgeLM: Fine-tuned large language models are scal- able judges. arXiv:2310.17631,
-
[22]
You are a strict pref- erence judge. Return only valid JSON,
On unseen cells, both predictions lie in[0,1], so the squared contribution is at most the unseen probabilityu K. Integrating these cellwise bounds with respect to the test-time probabilitiesp z gives the weighted terms in Eq. (6). Proof sketch of Proposition 2.The lower balance condition and a Chernoff bound implyN z ≥ nM /(2cMK)for all cells with probabi...
2000
-
[23]
Datasetn M selected aggregation family selectedKtest MSE RewardBench 800 Logistic pairwise (0.23) 6.17 0.023±0.001 LLMBar 300 Logistic (0.43) 7.00 0.183±0.002 SummEval 800 Ridge + isotonic (0.63) 6.70 0.044±0.001 Arena100K 400 One-coin reliability + isotonic (0.43) 6.53 0.232±0.002 Table 9: Validation-selected scalar aggregation at each dataset’s largest ...
arXiv 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.