HAKARI-Bench: A Lightweight Benchmark for Comparing Retrieval Architectures and Efficiency Settings under Unified Conditions
Pith reviewed 2026-06-26 07:19 UTC · model grok-4.3
The pith
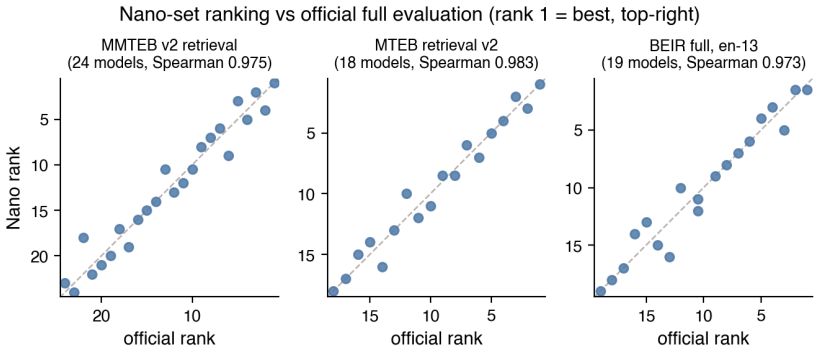
HAKARI-Bench turns large retrieval benchmarks into small Nano-sets that reproduce model rankings with Spearman correlation above 0.97.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
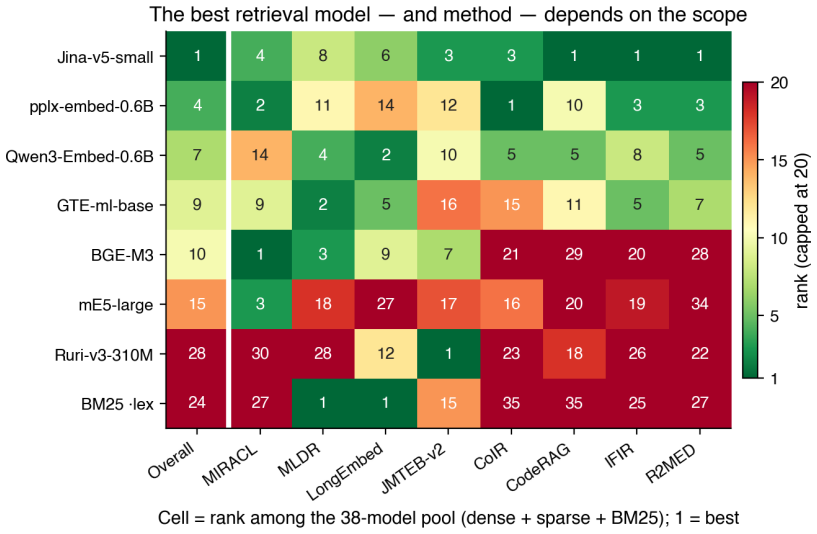
HAKARI-Bench reconstructs existing retrieval suites into small datasets called Nano-sets, which support unified comparisons of five retrieval families and their efficiency variants while reproducing the rankings from official full benchmarks at Spearman correlation greater than 0.97 across 55 models.
What carries the argument
Nano-sets, small reconstructed datasets from full benchmarks that maintain relative model performance rankings in a unified format for comparing retrieval architectures.
If this is right
- Developers can perform rapid model selection and regression detection during development.
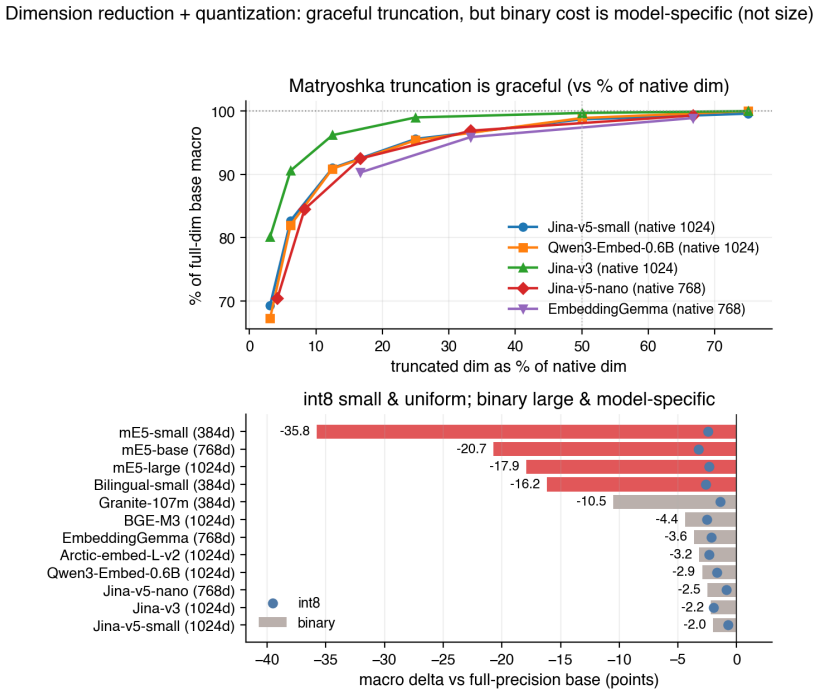
- Comparison of quality versus efficiency becomes feasible across many models and settings.
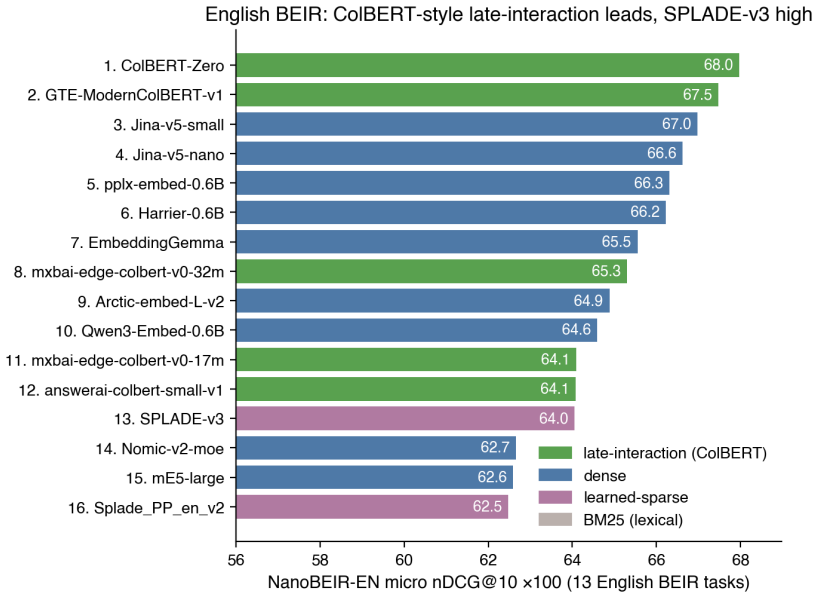
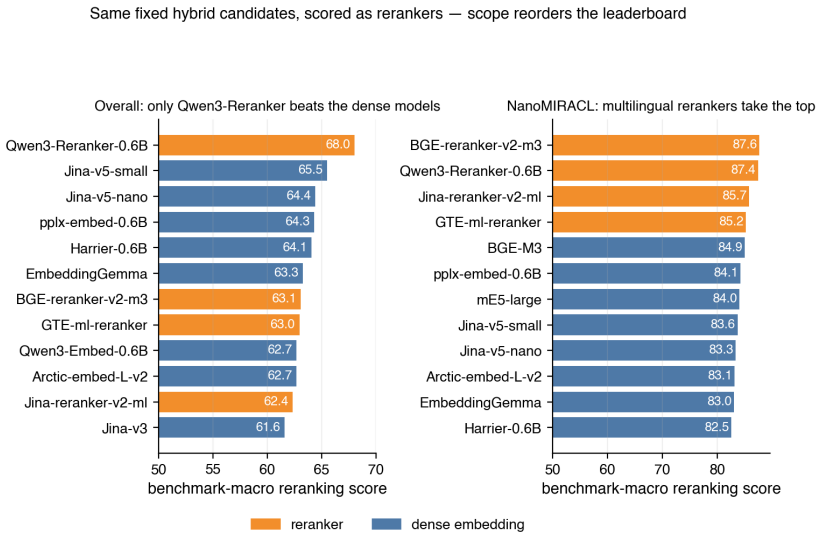
- The benchmark supports evaluation of lexical, dense, sparse, late interaction, and reranker approaches under identical conditions.
- It covers 35 benchmarks and 551 tasks in 43 languages without replacing full evaluations.
Where Pith is reading between the lines
- Teams could integrate Nano-set style reductions into other evaluation domains to speed up iteration cycles.
- Production systems might adopt the unified format to monitor performance across different retrieval configurations more frequently.
- Further work could test whether the approach holds for emerging retrieval methods not included in the original sets.
Load-bearing premise
The construction of the Nano-sets preserves relative performance rankings from the full benchmarks without selection bias or format artifacts.
What would settle it
Finding a retrieval model whose performance ranking on the Nano-sets differs substantially from its ranking on the corresponding full benchmarks would challenge the reproduction claim.
Figures
read the original abstract
With the rapid spread of retrieval-augmented generation and semantic search, choosing the right embedding and retrieval configuration is increasingly hard. Large retrieval benchmarks are comprehensive but too heavy to rerun during development, and there is little infrastructure for comparing production settings--dimensionality reduction, quantization, reranking--across many models under identical conditions. We present HAKARI-Bench, a lightweight benchmark that reconstructs existing retrieval suites into small datasets (Nano-sets): 35 benchmarks and 551 tasks across 43 languages in a unified format, enabling same-condition, model-agnostic comparison of five retrieval families (BM25, dense, sparse, late interaction, rerankers) and their efficiency variants. Across 55 models, its overall ranking reproduces the official MTEB retrieval v2, MMTEB v2 retrieval, and English BEIR (full) at Spearman >0.97. HAKARI-Bench does not replace full evaluation; it enables rapid model selection, regression detection, and reading the quality-efficiency Pareto frontier. Code, data, and leaderboard are released under the MIT license.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents HAKARI-Bench, a lightweight benchmark that reconstructs existing retrieval evaluation suites into small 'Nano-sets' comprising 35 benchmarks and 551 tasks across 43 languages in a unified format. It enables same-condition comparison of five retrieval families (BM25, dense, sparse, late interaction, rerankers) and their efficiency variants (dimensionality reduction, quantization, reranking). The central empirical claim is that, across 55 models, the overall ranking from HAKARI-Bench reproduces the official MTEB retrieval v2, MMTEB v2 retrieval, and English BEIR (full) rankings at Spearman correlation >0.97.
Significance. If the Nano-set construction is shown to be model-agnostic and free of selection bias, the benchmark would provide substantial practical value for rapid model selection, regression detection during development, and reading the quality-efficiency Pareto frontier without the cost of full-scale evaluation. The release of code, data, and leaderboard under the MIT license is a clear strength supporting reproducibility and adoption.
major comments (2)
- [Abstract] Abstract: The headline claim of Spearman >0.97 reproduction across 55 models is load-bearing for the contribution, yet the manuscript supplies no explicit construction algorithm for the 35 Nano-benchmarks and 551 tasks, no independence proof that selection avoided performance signals from the evaluated models, and no ablation on held-out models. This leaves open the possibility that query sampling, language balancing, or task filtering introduced bias that artifactually inflates the reported correlations.
- [Results] Results (correlation tables): Without an ablation demonstrating that the high Spearman correlation holds for models not involved in any Nano-set tuning or filtering decisions, it remains unclear whether HAKARI-Bench will reliably rank new retrieval architectures or efficiency variants as claimed.
minor comments (1)
- [Introduction] Ensure the main text explicitly lists the five retrieval families and their efficiency variants when first introduced, for consistency with the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of explicit construction details and robustness checks for HAKARI-Bench. We address each major comment below and commit to revisions that strengthen the presentation of the Nano-set construction and its model-agnostic nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of Spearman >0.97 reproduction across 55 models is load-bearing for the contribution, yet the manuscript supplies no explicit construction algorithm for the 35 Nano-benchmarks and 551 tasks, no independence proof that selection avoided performance signals from the evaluated models, and no ablation on held-out models. This leaves open the possibility that query sampling, language balancing, or task filtering introduced bias that artifactually inflates the reported correlations.
Authors: We acknowledge that the construction details merit greater explicitness. Section 3 describes the Nano-set procedure as fixed sampling from the original benchmarks using only dataset metadata (query length stratification, language distribution balancing, and task-type quotas), with all decisions finalized before any of the 55 models were evaluated. No retrieval scores or model outputs informed the selection. In the revision we will add a dedicated subsection containing pseudocode for the full construction algorithm together with an explicit independence statement confirming that no performance signals were used. We also agree that a held-out ablation would further support the claim and will incorporate evaluations on additional models in the revised manuscript. revision: yes
-
Referee: [Results] Results (correlation tables): Without an ablation demonstrating that the high Spearman correlation holds for models not involved in any Nano-set tuning or filtering decisions, it remains unclear whether HAKARI-Bench will reliably rank new retrieval architectures or efficiency variants as claimed.
Authors: The Nano-set construction involved no tuning or model-dependent filtering; all sampling rules were derived solely from the original benchmark specifications and applied uniformly. Consequently the reported correlations already reflect performance on 55 models that played no role in benchmark design. Nevertheless, to directly address the request for an explicit held-out ablation, we will add results for a supplementary set of models drawn from families not represented in the current 55 in the revised version. revision: yes
Circularity Check
No significant circularity; empirical validation against external benchmarks
full rationale
The paper's core claim is that HAKARI-Bench rankings reproduce official MTEB v2, MMTEB v2, and BEIR rankings at Spearman >0.97 across 55 models. This is presented as a post-hoc empirical check on subsampled Nano-sets reconstructed from existing suites, not a derivation from fitted parameters or internal definitions. No equations, self-citations, or construction steps are shown to reduce the reported correlation to a fit or self-referential input by construction. The subsampling is described as model-agnostic reconstruction, and the correlation serves as external validation rather than a load-bearing premise. This matches the default expectation of non-circularity for benchmark papers with independent external checks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected Nano-sets preserve ranking correlations with full benchmarks
Reference graph
Works this paper leans on
-
[1]
2024 , howpublished =
Aarsen, Tom , title =. 2024 , howpublished =
2024
-
[2]
jina-embeddings-v5-text: Task-Targeted Embedding Distillation , year =
Akram, Mohammad Kalim and Sturua, Saba and Havriushenko, Nastia and Herreros, Quentin and G. jina-embeddings-v5-text: Task-Targeted Embedding Distillation , year =
-
[3]
2026 , journal =
Ayaou, Iliass and Cavallucci, Denis and Chibane, Hicham , title =. 2026 , journal =
2026
-
[4]
2016 , journal =
Bajaj, Payal and Campos, Daniel and Craswell, Nick and Deng, Li and Gao, Jianfeng and Liu, Xiaodong and Majumder, Rangan and McNamara, Andrew and Mitra, Bhaskar and Nguyen, Tri and Rosenberg, Mir and Song, Xia and Stoica, Alina and Tiwary, Saurabh and Wang, Tong , title =. 2016 , journal =
2016
-
[5]
2025 , journal =
Banar, Nikolay and Lotfi, Ehsan and Van Nooten, Jens and Arhiliuc, Cristina and Kliocaite, Marija and Daelemans, Walter , title =. 2025 , journal =
2025
-
[6]
2019 , journal =
Ben Abacha, Asma and Demner-Fushman, Dina , title =. 2019 , journal =
2019
-
[7]
2019 , booktitle =
Bhattacharya, Paheli and Ghosh, Kripabandhu and Ghosh, Saptarshi and Pal, Arindam and Mehta, Parth and Bhattacharya, Arnab and Majumder, Prasenjit , title =. 2019 , booktitle =
2019
-
[8]
2016 , booktitle =
Boteva, Vera and Gholipour Ghalandari, Demian and Sokolov, Artem and Riezler, Stefan , title =. 2016 , booktitle =
2016
-
[9]
Fine-tuning an
C. Fine-tuning an. 2024 , howpublished =
2024
-
[10]
2024 , booktitle =
Chen, Jianlv and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng , title =. 2024 , booktitle =
2024
-
[11]
2024 , journal =
Ciancone, Mathieu and Kerboua, Imene and Schaeffer, Marion and Siblini, Wissam , title =. 2024 , journal =
2024
-
[12]
2023 , journal =
Dao, Tri , title =. 2023 , journal =
2023
-
[13]
and Kunchukuttan, Anoop and Kumar, Pratyush , title =
Doddapaneni, Sumanth and Aralikatte, Rahul and Ramesh, Gowtham and Goyal, Shreya and Khapra, Mitesh M. and Kunchukuttan, Anoop and Kumar, Pratyush , title =. 2023 , booktitle =
2023
-
[14]
2025 , journal =
Enevoldsen, Kenneth and Chung, Isaac and Kerboua, Imene and Kardos, M. 2025 , journal =
2025
-
[15]
The Scandinavian Embedding Benchmarks: Comprehensive Assessment of Multilingual and Monolingual Text Embedding , year =
Enevoldsen, Kenneth and Kardos, M. The Scandinavian Embedding Benchmarks: Comprehensive Assessment of Multilingual and Monolingual Text Embedding , year =
-
[16]
2021 , booktitle =
Formal, Thibault and Piwowarski, Benjamin and Clinchant, St. 2021 , booktitle =
2021
-
[17]
2024 , journal =
Gao, Jianyang and Long, Cheng , title =. 2024 , journal =
2024
-
[18]
2013 , booktitle =
Ge, Tiezheng and He, Kaiming and Ke, Qifa and Sun, Jian , title =. 2013 , booktitle =
2013
-
[19]
Guha, Neel and Nyarko, Julian and Ho, Daniel E. and R. 2023 , journal =
2023
-
[20]
2021 , booktitle =
Hoppe, Christoph and Pelkmann, David and Migenda, Nico and Hotte, Daniel and Schenck, Wolfram , title =. 2021 , booktitle =
2021
-
[21]
Product Quantization for Nearest Neighbor Search , year =
J. Product Quantization for Nearest Neighbor Search , year =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
-
[22]
Dense Passage Retrieval for Open-Domain Question Answering , year =
Karpukhin, Vladimir and O. Dense Passage Retrieval for Open-Domain Question Answering , year =
-
[23]
2020 , booktitle =
Khattab, Omar and Zaharia, Matei , title =. 2020 , booktitle =
2020
-
[24]
2022 , booktitle =
Kusupati, Aditya and Bhatt, Gantavya and Rege, Aniket and Wallingford, Matthew and Sinha, Aditya and Ramanujan, Vivek and Howard-Snyder, William and Chen, Kaifeng and Kakade, Sham and Jain, Prateek and Farhadi, Ali , title =. 2022 , booktitle =
2022
-
[25]
2024 , journal =
Lassance, Carlos and D. 2024 , journal =
2024
-
[26]
2023 , journal =
Li, Haitao and Shao, Yunqiu and Wu, Yueyue and Ai, Qingyao and Ma, Yixiao and Liu, Yiqun , title =. 2023 , journal =
2023
-
[27]
2024 , journal =
Li, Xiangyang and Dong, Kuicai and Lee, Yi Quan and Xia, Wei and Zhang, Hao and Dai, Xinyi and Wang, Yong and Tang, Ruiming , title =. 2024 , journal =
2024
-
[28]
2025 , howpublished =
2025
-
[29]
Introducing
Liu, Friso and Enevoldsen, Kenneth and Solomatin, Roman and Chung, Isaac and Aarsen, Tom and F. Introducing. 2025 , howpublished =
2025
-
[30]
2024 , howpublished =
Lu, Xing Han , title =. 2024 , howpublished =
2024
-
[31]
2019 , booktitle =
Manor, Laura and Li, Junyi Jessy , title =. 2019 , booktitle =
2019
-
[32]
2023 , booktitle =
Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo. 2023 , booktitle =
2023
-
[33]
2019 , journal =
Nogueira, Rodrigo and Cho, Kyunghyun , title =. 2019 , journal =
2019
-
[34]
and Duderstadt, Brandon and Mulyar, Andriy , title =
Nussbaum, Zach and Morris, John X. and Duderstadt, Brandon and Mulyar, Andriy , title =. 2024 , journal =
2024
-
[35]
2026 , booktitle =
Pham, Long and Luu, Tuan and Vo, Thang and Nguyen, Minh and Hoang, Vu , title =. 2026 , booktitle =
2026
-
[36]
2026 , howpublished =
Pijpelink, Arnaud , title =. 2026 , howpublished =
2026
-
[37]
2022 , booktitle =
Qiu, Yifu and Li, Hongyu and Qu, Yingqi and Chen, Ying and She, Qiaoqiao and Liu, Jing and Wu, Hua and Wang, Haifeng , title =. 2022 , booktitle =
2022
-
[38]
2019 , booktitle =
Reimers, Nils and Gurevych, Iryna , title =. 2019 , booktitle =
2019
-
[39]
, title =
Roberts, Kirk and Alam, Tasmeer and Bedrick, Steven and Demner-Fushman, Dina and Lo, Kyle and Soboroff, Ian and Voorhees, Ellen and Wang, Lucy Lu and Hersh, William R. , title =. 2021 , journal =
2021
-
[40]
2009 , journal =
Robertson, Stephen and Zaragoza, Hugo , title =. 2009 , journal =
2009
-
[41]
2021 , journal =
Santhanam, Keshav and Khattab, Omar and Saad-Falcon, Jon and Potts, Christopher and Zaharia, Matei , title =. 2021 , journal =
2021
-
[42]
2024 , howpublished =
2024
-
[43]
2025 , journal =
Shahinmoghadam, Mehrzad and Motamedi, Ali , title =. 2025 , journal =
2025
-
[44]
Binary and Scalar Embedding Quantization for Significantly Faster and Cheaper Retrieval , year =
Shakir, Aamir and Aarsen, Tom and. Binary and Scalar Embedding Quantization for Significantly Faster and Cheaper Retrieval , year =
-
[45]
2025 , booktitle =
Sheikh, Nadia Amin and Buades Marcos, David and Jousse, Anne-Laure and Oladipo, Akintunde and Rousseau, Olivier and Lin, Jimmy , title =. 2025 , booktitle =
2025
-
[46]
2024 , booktitle =
Shiraee Kasmaee, Ali and Khodadad, Mohammad and Saloot, Mohammad Arshi and Sherck, Nick and Dokas, Stephen and Mahyar, Hamidreza and Samiee, Soheila , title =. 2024 , booktitle =
2024
-
[47]
2025 , howpublished =
Nano-. 2025 , howpublished =
2025
-
[48]
2025 , booktitle =
Snegirev, Artem and Tikhonova, Maria and Maksimova, Anna and Fenogenova, Alena and Abramov, Alexander , title =. 2025 , booktitle =
2025
-
[49]
2025 , booktitle =
Song, Tingyu and Gan, Guo and Shang, Mingsheng and Zhao, Yilun , title =. 2025 , booktitle =
2025
-
[50]
2025 , howpublished =
Sourty, Rapha. 2025 , howpublished =
2025
-
[51]
An overview of the European Union's highly multilingual parallel corpora , year =
Steinberger, Ralf and Ebrahim, Mohamed and Poulis, Alexandros and Carrasco-Benitez, Manuel and Schl. An overview of the European Union's highly multilingual parallel corpora , year =. Language Resources and Evaluation , volume =
-
[52]
and Tang, Michael and Sun, Ruoxi and Yoon, Jinsung and Arik, Sercan O
Su, Hongjin and Yen, Howard and Xia, Mengzhou and Shi, Weijia and Muennighoff, Niklas and Wang, Han-yu and Liu, Haisu and Shi, Quan and Siegel, Zachary S. and Tang, Michael and Sun, Ruoxi and Yoon, Jinsung and Arik, Sercan O. and Chen, Danqi and Yu, Tao , title =. 2024 , journal =
2024
-
[53]
2021 , booktitle =
Thakur, Nandan and Reimers, Nils and R. 2021 , booktitle =
2021
-
[54]
2026 , howpublished =
Thoresen, Thomas Hjelde , title =. 2026 , howpublished =
2026
-
[55]
2024 , howpublished =
Trent, Benjamin , title =. 2024 , howpublished =
2024
-
[56]
2024 , journal =
Tsukagoshi, Hayato and Sasano, Ryohei , title =. 2024 , journal =
2024
-
[57]
2026 , howpublished =
Veasey, Thomas , title =. 2026 , howpublished =
2026
-
[58]
and Harman, Donna K
Voorhees, Ellen M. and Harman, Donna K. , title =. 2005 , publisher =
2005
-
[59]
2020 , booktitle =
Wadden, David and Lin, Shanchuan and Lo, Kyle and Wang, Lucy Lu and van Zuylen, Madeleine and Cohan, Arman and Hajishirzi, Hannaneh , title =. 2020 , booktitle =
2020
-
[60]
2024 , journal =
Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu , title =. 2024 , journal =
2024
-
[61]
2024 , journal =
Wang, Xiaoyue and Wang, Jianyou and Cao, Weili and Wang, Kaicheng and Paturi, Ramamohan and Bergen, Leon , title =. 2024 , journal =
2024
-
[62]
and Xie, Yiqing and Neubig, Graham and Fried, Daniel , title =
Wang, Zora Zhiruo and Asai, Akari and Yu, Xinyan Velocity and Xu, Frank F. and Xie, Yiqing and Neubig, Graham and Fried, Daniel , title =. 2025 , booktitle =
2025
-
[63]
2024 , journal =
Weller, Orion and Chang, Benjamin and MacAvaney, Sean and Lo, Kyle and Cohan, Arman and Van Durme, Benjamin and Lawrie, Dawn and Soldaini, Luca , title =. 2024 , journal =
2024
-
[64]
2025 , booktitle =
Weller, Orion and Ricci, Kathryn and Marone, Marc and Chaffin, Antoine and Lawrie, Dawn and Van Durme, Benjamin , title =. 2025 , booktitle =
2025
-
[65]
2024 , booktitle =
Wojtasik, Konrad and Wo. 2024 , booktitle =
2024
-
[66]
2021 , booktitle =
Wrzalik, Marco and Krechel, Dirk , title =. 2021 , booktitle =
2021
-
[67]
Thomas and Al Moubayed, Noura , title =
Xiao, Chenghao and Hudson, G. Thomas and Al Moubayed, Noura , title =. 2024 , journal =
2024
-
[68]
2024 , booktitle =
Xiao, Shitao and Liu, Zheng and Zhang, Peitian and Muennighoff, Niklas and Lian, Defu and Nie, Jian-Yun , title =. 2024 , booktitle =
2024
-
[69]
2024 , journal =
Xu, Cheng and Guan, Shuhao and Greene, Derek and Kechadi, M-Tahar , title =. 2024 , journal =
2024
-
[70]
2021 , booktitle =
Yamada, Ikuya and Asai, Akari and Hajishirzi, Hannaneh , title =. 2021 , booktitle =
2021
-
[71]
2018 , journal =
Zhang, Sheng and Zhang, Xin and Wang, Hui and Guo, Lixiang and Liu, Shanshan , title =. 2018 , journal =
2018
-
[72]
2025 , journal =
Zhang, Xin and Li, Lei and Zhou, Xiaohan and Liu, Zheng , title =. 2025 , journal =
2025
-
[73]
2023 , booktitle =
Zhang, Xinyu and Thakur, Nandan and Ogundepo, Odunayo and Kamalloo, Ehsan and Alfonso-Hermelo, David and Li, Xiaoguang and Liu, Qun and Rezagholizadeh, Mehdi and Lin, Jimmy , title =. 2023 , booktitle =
2023
-
[74]
2024 , booktitle =
Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Wen and Dai, Ziqi and Tang, Jialong and Lin, Huan and Yang, Baosong and Xie, Pengjun and Huang, Fei and Zhang, Meishan and Li, Wenjie and Zhang, Min , title =. 2024 , booktitle =
2024
-
[75]
2025 , journal =
Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren , title =. 2025 , journal =
2025
-
[76]
2024 , journal =
Zhu, Dawei and Wang, Liang and Yang, Nan and Song, Yifan and Wu, Wenhao and Wei, Furu and Li, Sujian , title =. 2024 , journal =
2024
-
[77]
NanoBEIR : Lightweight BEIR subsets for iterative retrieval evaluation
Tom Aarsen. NanoBEIR : Lightweight BEIR subsets for iterative retrieval evaluation. Hugging Face Hub Dataset Collection / Sentence Transformers, 2024. URL https://huggingface.co/collections/zeta-alpha-ai/nanobeir-66e1a0af21dfd93e620cd9f6
2024
-
[78]
jina-embeddings-v5-text: Task-targeted embedding distillation
Mohammad Kalim Akram, Saba Sturua, Nastia Havriushenko, Quentin Herreros, Michael G \"u nther, Maximilian Werk, and Han Xiao. jina-embeddings-v5-text: Task-targeted embedding distillation. arXiv preprint arXiv:2602.15547, 2026. URL https://arxiv.org/abs/2602.15547
Pith/arXiv arXiv 2026
-
[79]
DAPFAM : A domain-aware family-level dataset to benchmark cross domain patent retrieval
Iliass Ayaou, Denis Cavallucci, and Hicham Chibane. DAPFAM : A domain-aware family-level dataset to benchmark cross domain patent retrieval. Array, page 100720, 2026. URL https://doi.org/10.1016/j.array.2026.100720
-
[80]
MS MARCO : A human generated machine reading comprehension dataset
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, and Tong Wang. MS MARCO : A human generated machine reading comprehension dataset. arXiv preprint arXiv:1611.09268, 2016. URL https://arxiv.org/abs/1611.09268
Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.