A Markov Chain Approach to Preference Alignment
Pith reviewed 2026-06-26 10:32 UTC · model grok-4.3
The pith
MCHF defines a Markov kernel from pairwise utilities that converges geometrically to a stationary alignment distribution at a rate set by the non-transitive component of U.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
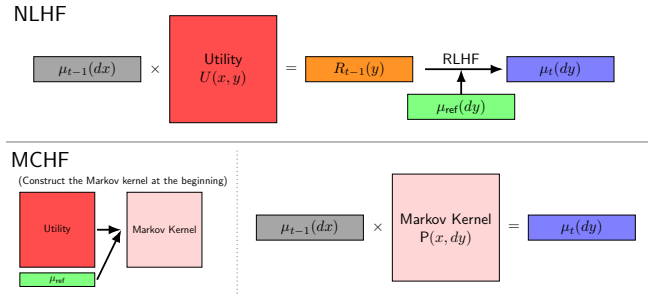
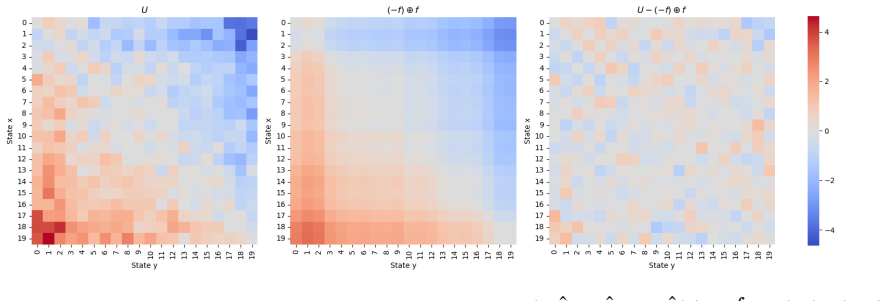
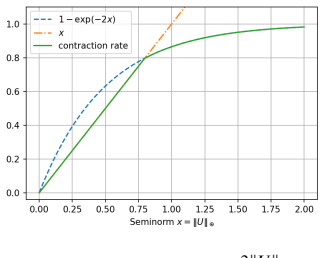
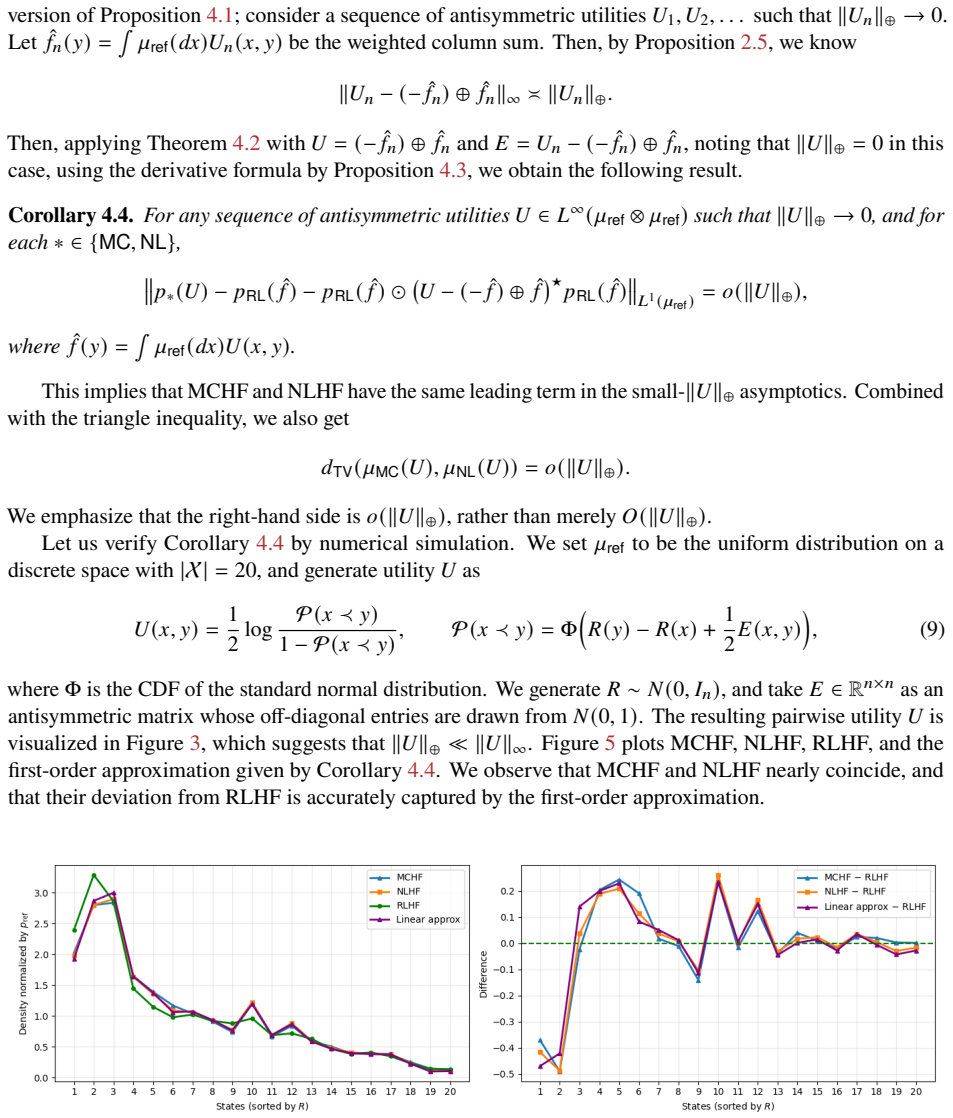
Given a pairwise utility U(x,y) and reference measure μ_ref, the kernel P(x,dy) ∝ exp(U(x,y)) μ_ref(dy) is a well-defined Markov transition. The chain started at μ_ref converges geometrically to its unique stationary distribution, with rate governed by the seminorm ||U||_⊕ = inf ||U − g ⊕ f||_∞ that extracts the non-transitive structure of U. A mirror-descent algorithm for NLHF obeys an analogous bound. When ||U||_⊕ is small, MCHF and NLHF coincide to first order around the RLHF solution given by the column-sum reward, and both algorithms recover that reward in their first step before incorporating the identical linear functional of the residual U − (−f̂) ⊕ f̂.
What carries the argument
The seminorm ||U||_⊕ that isolates the non-transitive part of the pairwise utility and directly sets the geometric convergence rate of the MCHF Markov kernel.
If this is right
- MCHF converges geometrically with rate controlled by the non-transitive seminorm of U.
- When the seminorm is small, MCHF and NLHF agree to first order around an RLHF solution.
- The first iteration of both MCHF and NLHF recovers the column-sum reward RLHF solution.
- From the second iteration onward both methods add the same linear functional of the residual non-transitive utility.
Where Pith is reading between the lines
- The framework suggests that alignment difficulty scales with measured non-transitivity rather than with raw preference noise.
- One could construct synthetic utilities with known cycle structure and verify whether empirical convergence rates track the seminorm exactly.
- The same seminorm might serve as a diagnostic for when reward-based methods are sufficient versus when a full game or chain formulation is required.
Load-bearing premise
The pairwise utility U is bounded and measurable, so that the kernel is a valid Markov transition and the induced chain possesses a unique stationary distribution.
What would settle it
For a concrete bounded utility U, compute the numerical value of ||U||_⊕ and run the iterated kernel; the observed contraction factor in total variation or KL distance should match the predicted geometric rate controlled by that seminorm value.
Figures
read the original abstract
We propose Markov Chain from Human Feedback (MCHF), an elementary approach for aligning generative models from pairwise human preferences. Unlike Reinforcement Learning from Human Feedback (RLHF), which reduces comparisons to a scalar reward, and Nash Learning from Human Feedback (NLHF), which preserves pairwise utilities through a KL-regularized minimax optimization, MCHF uses pairwise preferences directly to define a transition mechanism over model outputs. Given a pairwise utility $U(x,y)$, which quantifies human preference for $y$ over $x$, and a reference probability distribution $\mu_{\mathsf{ref}}$, we define a Markov kernel $\mathsf{P}(x, dy)\propto \exp(U(x,y))\mu_{\mathsf{ref}}(dy)$, and take the Markov chain starting from $\mu_{\mathsf{ref}}$ as an iterative alignment procedure. We show that MCHF converges geometrically fast to the stationary distribution, with a convergence rate governed by the seminorm $\|U\|_\oplus=\inf_{g,f\in L^\infty(\mu_{\mathsf{ref}})}\|U-g\oplus f\|_\infty$, which quantifies the non-transitive structure of the pairwise utility. We further show that a mirror-descent algorithm for NLHF satisfies an analogous structure-adaptive convergence guarantee. Finally, through a perturbation analysis, we prove that when $\|U\|_\oplus$ is small, MCHF and NLHF agree up to first order around an RLHF solution, which yields a unified view of reward-based, game-theoretic, and Markovian approaches to alignment. In particular, for two natural algorithms that converge to the MCHF/NLHF equilibria, we show that the first step of MCHF and NLHF recovers the RLHF solution based on the column-sum reward $\hat{f}(y)=\int \mu_{\mathsf{ref}}(dx) U(x, y)$, and starting from the second iteration, both algorithms incorporate the same linear functional of the residual $U-(-\hat f)\oplus \hat f$, which captures the non-transitive structure of the pairwise utility $U$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Markov Chain from Human Feedback (MCHF), which constructs a Markov kernel P(x, dy) ∝ exp(U(x,y)) μ_ref(dy) directly from a bounded measurable pairwise utility U and reference measure μ_ref, then iterates the chain starting at μ_ref as an alignment procedure. It claims geometric convergence to the stationary distribution at a rate controlled by the seminorm ||U||_⊕ = inf_{g,f} ||U - g ⊕ f||_∞ that quantifies deviation from additive separability; an analogous structure-adaptive guarantee for a mirror-descent NLHF algorithm; and a first-order perturbation result showing that MCHF and NLHF coincide with the RLHF solution based on the column-sum reward ilde f(y) = ∫ μ_ref(dx) U(x,y) when ||U||_⊕ is small, with subsequent steps incorporating the same linear functional of the residual U - (- ilde f) ⊕ ilde f.
Significance. If the stated convergence and perturbation results hold, the manuscript supplies an explicit, parameter-free unification of reward-based (RLHF), game-theoretic (NLHF), and Markovian alignment methods, together with convergence rates that adapt to the degree of non-transitivity in U. The column-sum reduction and the shared linear correction term for the non-additive residual are concrete strengths that make the relationships between the three approaches falsifiable and directly testable.
major comments (2)
- [Abstract] Abstract (geometric convergence paragraph): the claim that the seminorm ||U||_⊕ governs the mixing rate is asserted without the intermediate contraction-mapping or Dobrushin-coefficient steps that would verify how ||U||_⊕ controls the total-variation distance to stationarity; the manuscript must supply these steps for the central rate result to be load-bearing.
- [Abstract] Abstract (perturbation analysis paragraph): the first-order agreement between MCHF/NLHF and the column-sum RLHF solution is stated to follow from an expansion of the residual U - (- ilde f) ⊕ ilde f, yet no explicit expansion or remainder bound is provided; because this expansion underpins the claimed unification, the details are required.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for explicit intermediate steps in the central results. We address both major comments below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract (geometric convergence paragraph): the claim that the seminorm ||U||_⊕ governs the mixing rate is asserted without the intermediate contraction-mapping or Dobrushin-coefficient steps that would verify how ||U||_⊕ controls the total-variation distance to stationarity; the manuscript must supply these steps for the central rate result to be load-bearing.
Authors: We agree that the abstract states the geometric convergence result without displaying the contraction-mapping or Dobrushin-coefficient arguments. In the revised manuscript we will add these intermediate steps explicitly in the main body (new subsection on the Dobrushin coefficient applied to the kernel P), showing the precise bound ||P^n(x,·) - π||_TV ≤ (1 - c(||U||_⊕))^n, and we will insert a one-sentence pointer in the abstract directing readers to that derivation. This makes the rate claim fully load-bearing. revision: yes
-
Referee: [Abstract] Abstract (perturbation analysis paragraph): the first-order agreement between MCHF/NLHF and the column-sum RLHF solution is stated to follow from an expansion of the residual U - (- ̃f) ⊕ ̃f, yet no explicit expansion or remainder bound is provided; because this expansion underpins the claimed unification, the details are required.
Authors: We acknowledge that the abstract invokes the first-order expansion without writing the explicit Taylor-type expansion or the O(||U||_⊕²) remainder. In the revision we will supply the full expansion of the fixed-point equations for both MCHF and the mirror-descent NLHF iterates around the column-sum RLHF solution, together with the explicit remainder bound controlled by ||U||_⊕, placed in the main perturbation-analysis section; a brief clause will be added to the abstract indicating that the expansion appears in the body. revision: yes
Circularity Check
No significant circularity
full rationale
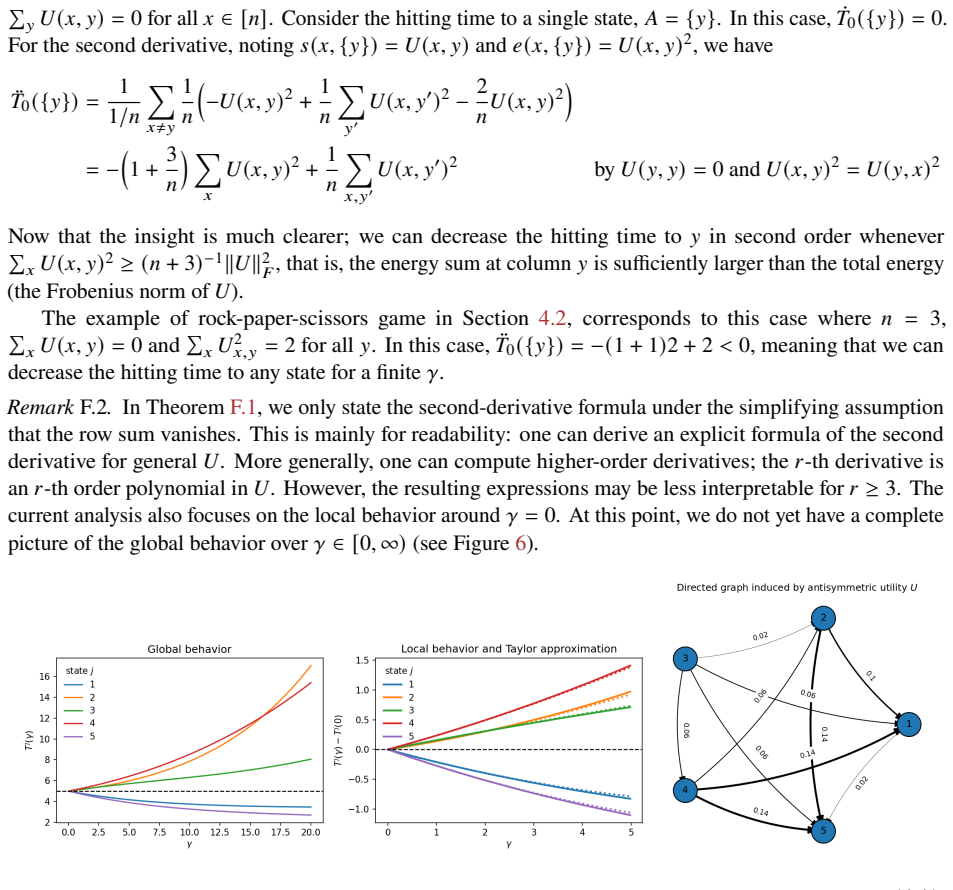
The derivation begins from the explicit definitions of the kernel P(x,dy)∝exp(U(x,y))μ_ref(dy) and the seminorm ||U||_⊕ as the infimum deviation from additive separability; the geometric convergence rate, the first-step recovery of the column-sum RLHF solution ˆf(y)=∫μ_ref(dx)U(x,y), and the first-order agreement with NLHF under small ||U||_⊕ are all obtained by direct mathematical expansion and perturbation analysis of these same objects. No parameter is fitted to data and then relabeled as a prediction, no load-bearing claim rests on a self-citation, and the stationary distribution is the standard fixed point of the kernel constructed from U, which is the usual non-circular property of Markov chains.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption U is a bounded measurable function on the output space so that the kernel P(x,dy)∝exp(U(x,y))μ_ref(dy) is a valid probability kernel.
- standard math The Markov chain induced by P admits a unique stationary distribution.
Reference graph
Works this paper leans on
-
[1]
The Thirteenth International Conference on Learning Representations , year=
Direct distributional optimization for provable alignment of diffusion models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[2]
arXiv preprint arXiv:2402.15194 , year=
Fine-tuning of continuous-time diffusion models as entropy-regularized control , author=. arXiv preprint arXiv:2402.15194 , year=
-
[3]
Deb, Nabarun and Liang, Tengyuan , journal=
-
[4]
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Manning, Christopher D and Ermon, Stefano and Finn, Chelsea , journal=
-
[5]
The Thirteenth International Conference on Learning Representations , year=
Rethinking Reward Modeling in Preference-based Large Language Model Alignment , author=. The Thirteenth International Conference on Learning Representations , year=
-
[6]
Advances in Neural Information Processing Systems , volume=
Preference alignment with flow matching , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Forty-first International Conference on Machine Learning , year=
Munos, R. Forty-first International Conference on Machine Learning , year=
-
[8]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Paul G. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[9]
Liu, Kaizhao and Long, Qi and Shi, Zhekun and Su, Weijie J and Xiao, Jiancong , journal=
-
[10]
Souradip Chakraborty and Jiahao Qiu and Hui Yuan and Alec Koppel and Dinesh Manocha and Furong Huang and Amrit Bedi and Mengdi Wang , booktitle=
-
[11]
Chenlu Ye and Wei Xiong and Yuheng Zhang and Hanze Dong and Nan Jiang and Tong Zhang , booktitle=
-
[12]
2017 , publisher=
Levin, David A and Peres, Yuval , volume=. 2017 , publisher=
2017
-
[13]
Shi, Zhekun and Liu, Kaizhao and Long, Qi and Su, Weijie J and Xiao, Jiancong , journal=
-
[14]
Conway, John B , year=
-
[15]
Rioux, Gabriel and Goldfeld, Ziv and Kato, Kengo , journal=
-
[16]
Tiapkin, Daniil and Calandriello, Daniele and Belomestny, Denis and Moulines, Eric and Naumov, Alexey and Rasul, Kashif and Valko, Michal and Menard, Pierre , journal=
-
[17]
Xiao, Jiancong and Shi, Zhekun and Liu, Kaizhao and Long, Qi and Su, Weijie J , journal=
-
[18]
Rosset, Corby and Cheng, Ching-An and Mitra, Arindam and Santacroce, Michael and Awadallah, Ahmed and Xie, Tengyang , journal=
-
[19]
Self-Play Preference Optimization for Language Model Alignment , volume =
Wu, Yue and Sun, Zhiqing and Hughes, Rina and Ji, Kaixuan and Yang, Yiming and Gu, Quanquan , booktitle =. Self-Play Preference Optimization for Language Model Alignment , volume =
-
[20]
Wang, Yuanhao and Liu, Qinghua and Jin, Chi , journal=
-
[21]
Terry , journal =
Ralph Allan Bradley and Milton E. Terry , journal =
-
[22]
Kazusato Oko and Annie S Ulichney and Nika Haghtalab and Han Bao , booktitle=
-
[23]
2024 , volume =
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe , booktitle =. 2024 , volume =
2024
-
[24]
Meng, Yu and Xia, Mengzhou and Chen, Danqi , booktitle =
-
[25]
2024 , editor =
Gheshlaghi Azar, Mohammad and Daniel Guo, Zhaohan and Piot, Bilal and Munos, Remi and Rowland, Mark and Valko, Michal and Calandriello, Daniele , booktitle =. 2024 , editor =
2024
-
[26]
Huang, Audrey and Zhan, Wenhao and Xie, Tengyang and Lee, Jason and Sun, Wen and Krishnamurthy, Akshay and Foster, Dylan , booktitle =
-
[27]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Duncan , publisher=
Luce, R. Duncan , publisher=
-
[29]
Advances in Neural Information Processing Systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Fine-Tuning Language Models from Human Preferences
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[31]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[32]
2024 , volume =
Swamy, Gokul and Dann, Christoph and Kidambi, Rahul and Wu, Steven and Agarwal, Alekh , booktitle =. 2024 , volume =
2024
-
[33]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
1998 , note =
Computer Networks and ISDN Systems , volume =. 1998 , note =
1998
-
[36]
Negahban, Sahand and Oh, Sewoong and Shah, Devavrat , journal=
-
[37]
Proceedings of the 31st International Conference on Machine Learning , pages=
A statistical convergence perspective of algorithms for rank aggregation from pairwise data , author=. Proceedings of the 31st International Conference on Machine Learning , pages=
-
[38]
2011 , publisher=
Jiang, Xiaoye and Lim, Lek-Heng and Yao, Yuan and Ye, Yinyu , journal=. 2011 , publisher=
2011
-
[39]
GPT-4 Technical Report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Fang Wu and Xu Huang and Weihao Xuan and Zhiwei Zhang and Yijia Xiao and Guancheng Wan and Xiaomin Li and Bing Hu and Peng Xia and Jure Leskovec and Yejin Choi , booktitle=
-
[42]
The Fourteenth International Conference on Learning Representations , year=
Barna P. The Fourteenth International Conference on Learning Representations , year=
-
[43]
Xu Chu and Zhixin Zhang and Tianyu Jia and Yujie Jin , booktitle=
-
[44]
2024 , volume =
Sorensen, Taylor and Moore, Jared and Fisher, Jillian and Gordon, Mitchell L and Mireshghallah, Niloofar and Rytting, Christopher Michael and Ye, Andre and Jiang, Liwei and Lu, Ximing and Dziri, Nouha and Althoff, Tim and Choi, Yejin , booktitle =. 2024 , volume =
2024
-
[45]
Dobrushin, R. L. , title =. Theory of Probability & Its Applications , volume =
-
[46]
Rosenthal , title =
Jeffrey S. Rosenthal , title =. Journal of the American Statistical Association , volume =. 1995 , publisher =
1995
-
[47]
and Parks, Harold R
Krantz, Steven G. and Parks, Harold R. , series =. 2013 , doi =
2013
-
[48]
and Nesterov, Yurii , title =
Lu, Haihao and Freund, Robert M. and Nesterov, Yurii , title =. SIAM Journal on Optimization , volume =
-
[49]
2024 , url=
Tianqi Liu and Yao Zhao and Rishabh Joshi and Misha Khalman and Mohammad Saleh and Peter J Liu and Jialu Liu , booktitle=. 2024 , url=
2024
-
[50]
arXiv preprint arXiv:2407.13734 , year=
Understanding reinforcement learning-based fine-tuning of diffusion models: A tutorial and review , author=. arXiv preprint arXiv:2407.13734 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.