Denoising Tells When to Replan: Denoising-Variance Adaptive Chunking for Flow-Based Robot Policies
Pith reviewed 2026-06-28 09:24 UTC · model grok-4.3
The pith
Denoising variance in flow-based robot policies indicates when to replan chunks of actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
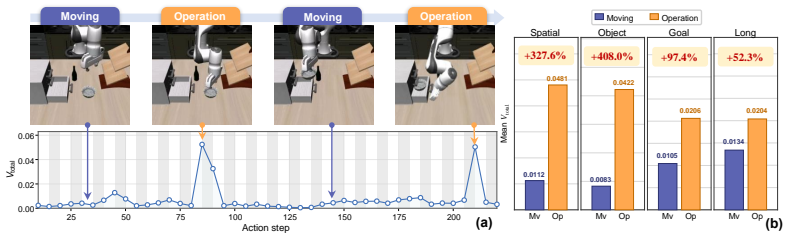
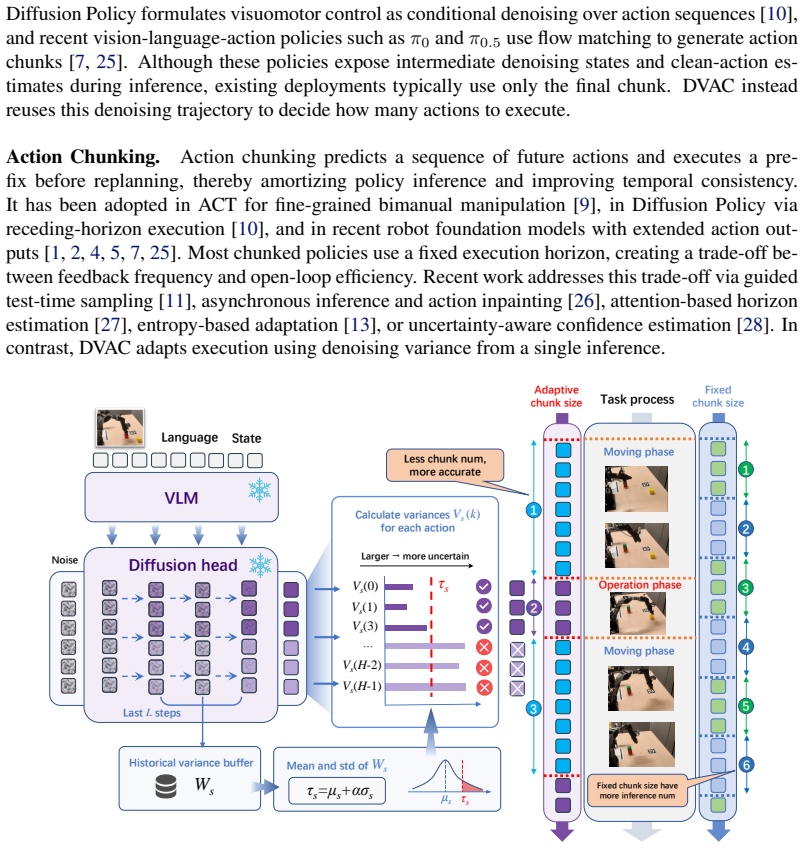
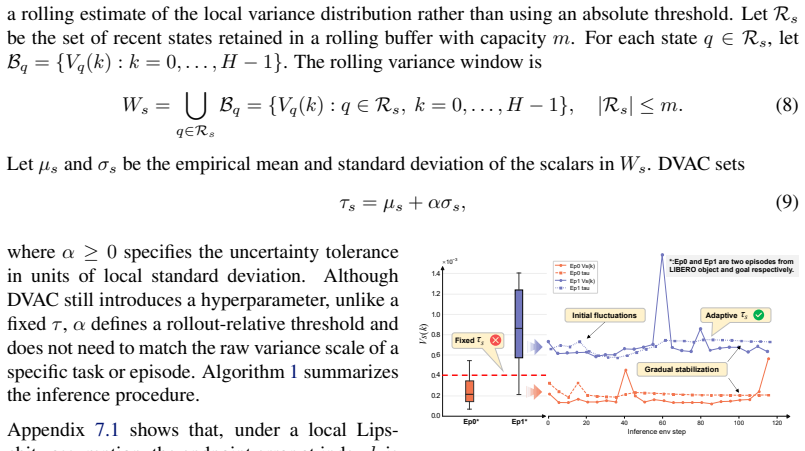
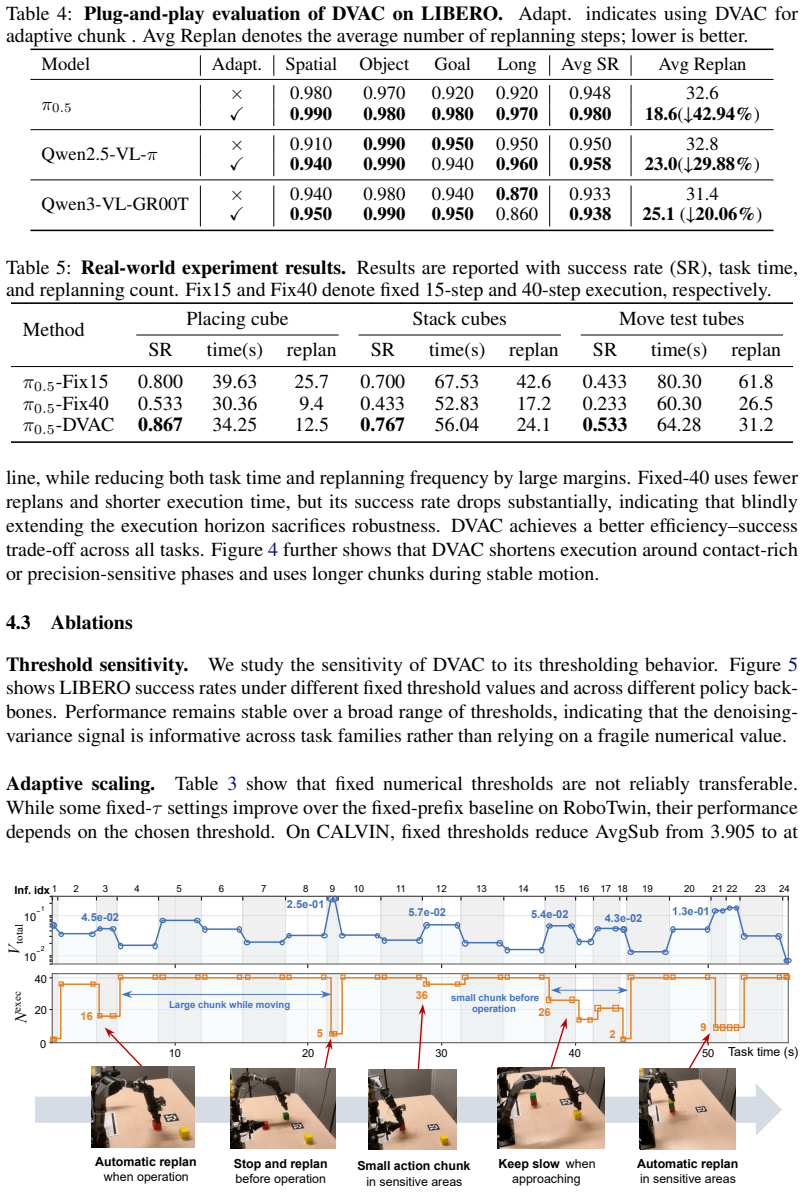
The denoising process of flow-based policies contains an intrinsic signal of task phases: clean-action estimates remain stable during predictable motion phases, but fluctuate more strongly around contact-rich or precision-sensitive operations. DVAC measures the variance of clean-action estimates over the final denoising steps, executes the stable low-variance prefix, and replans before high-variance future actions are committed. A rolling estimate of local variance scale transfers the method across tasks and rollouts.
What carries the argument
Denoising-Variance Adaptive Chunking (DVAC), which uses variance of clean-action estimates in the final denoising steps to set variable execution horizons instead of a fixed chunk length.
Load-bearing premise
The variance of clean-action estimates over the final denoising steps reliably indicates task phases requiring different replanning frequencies and generalizes across tasks when the threshold is calibrated via a rolling estimate of the local variance scale.
What would settle it
On a new set of manipulation tasks, the variance signal shows no consistent correlation with phase type, so that DVAC yields success rates and replan counts indistinguishable from fixed-length chunking.
Figures
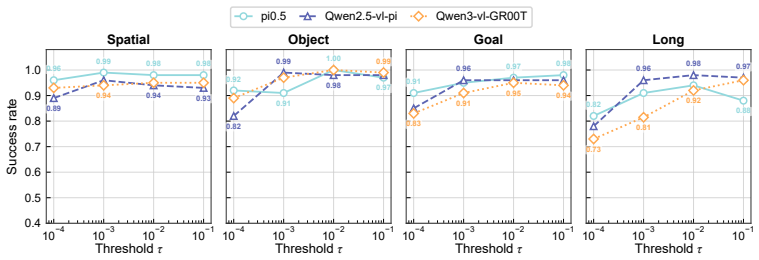
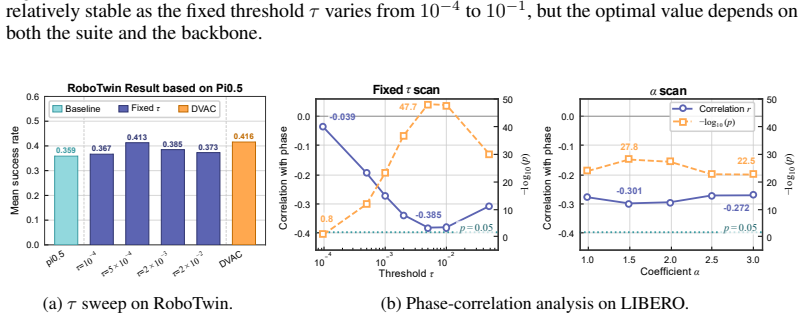
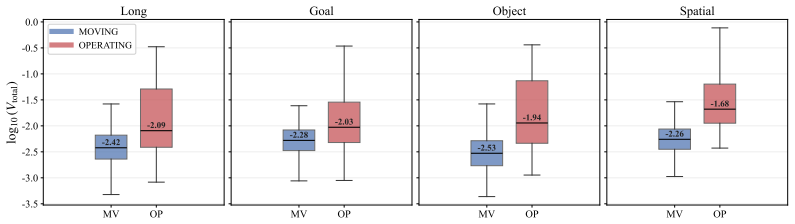
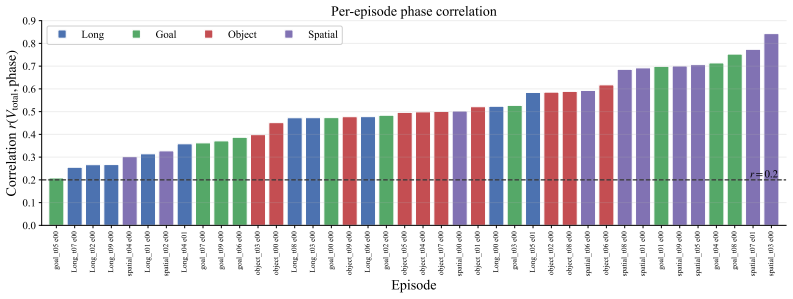
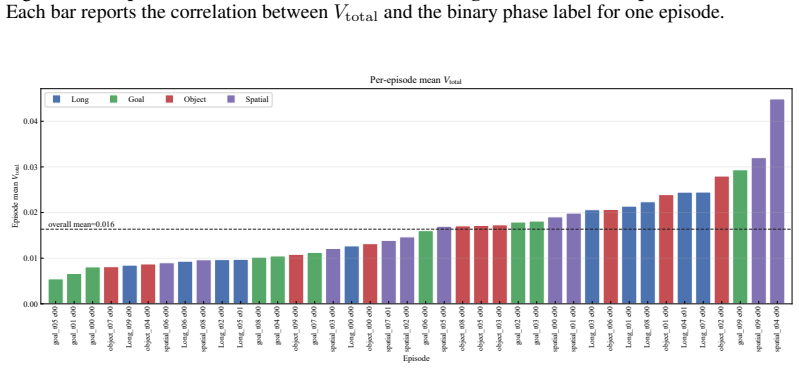
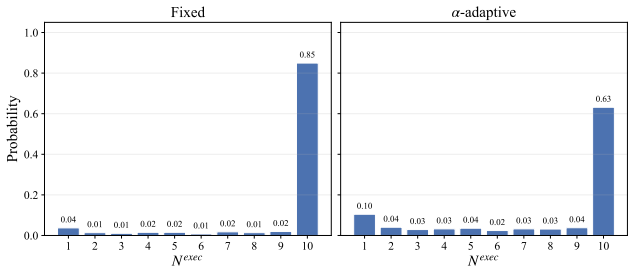
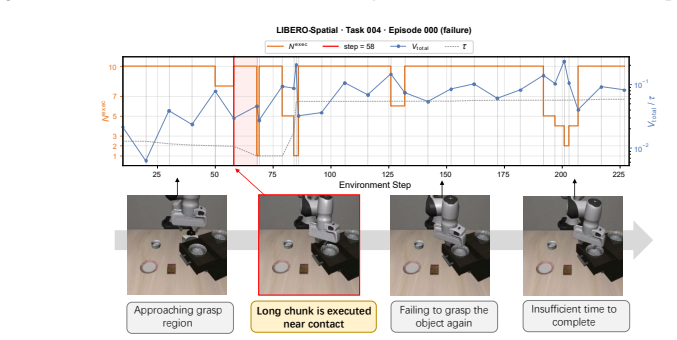
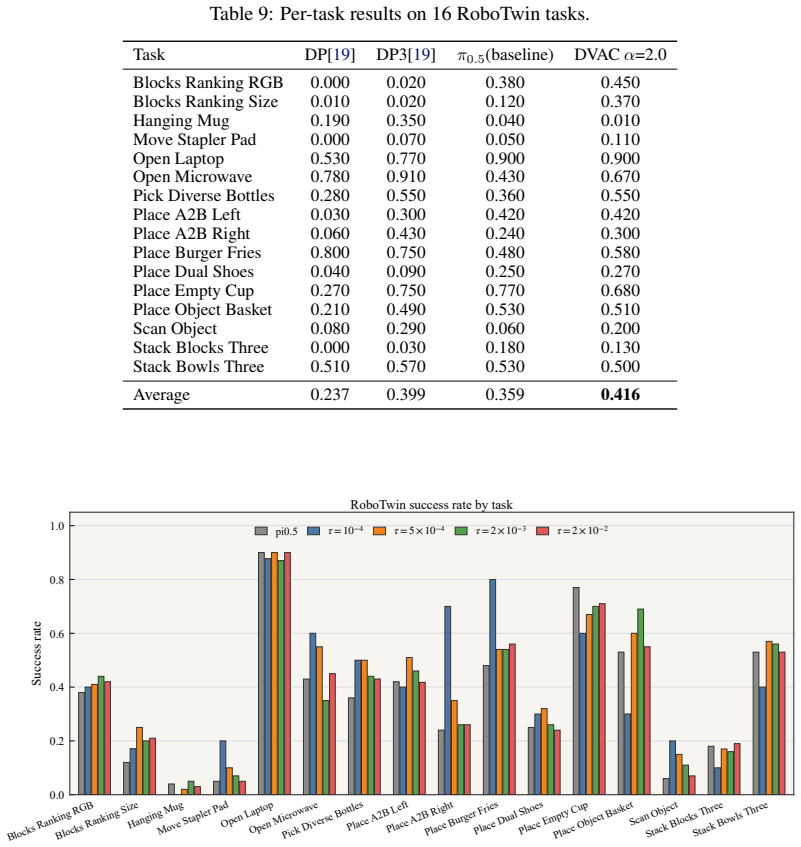
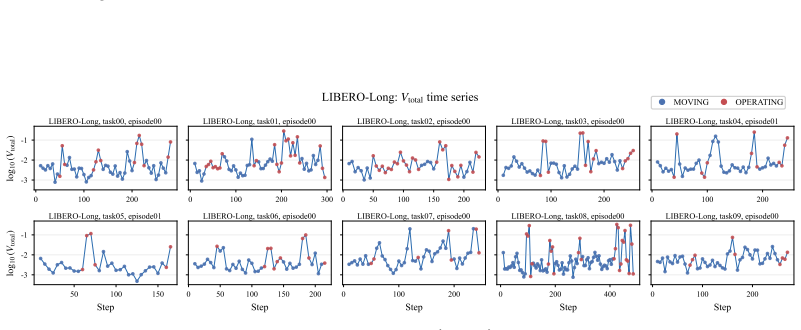
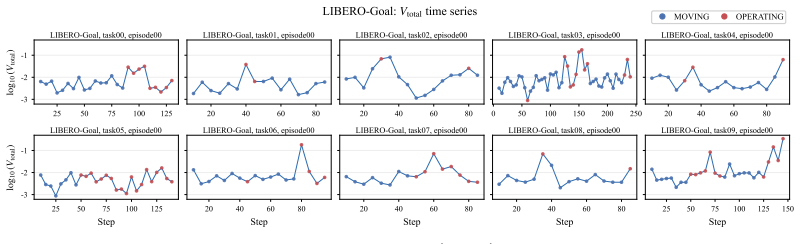
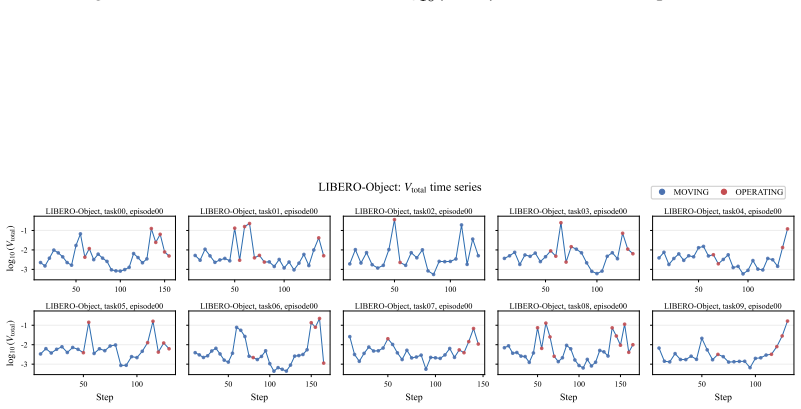
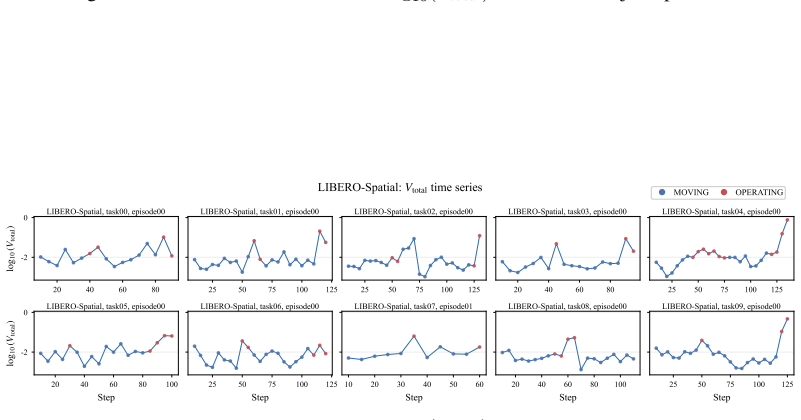
read the original abstract
Action chunking has become a common inference strategy for flow-based robot policies, improving action coherence by modeling multi-step temporal dependencies in demonstrations. However, the execution horizon is still typically set as an empirical fixed value, overlooking that predictable free-space motions and precision-critical interaction phases often require different replanning frequencies. In this work, we first show that the denoising process of flow-based policies contains an intrinsic signal of task phases: clean-action estimates remain stable during predictable motion phases, but fluctuate more strongly around contact-rich or precision-sensitive operations. Motivated by this observation, we propose DVAC (Denoising-Variance Adaptive Chunking), a test-time method that adaptively determines how many actions to execute from each predicted chunk. DVAC measures the variance of clean-action estimates over the final denoising steps, executes the stable low-variance prefix, and replans before high-variance future actions are committed. To transfer across tasks and rollouts, DVAC further calibrates the threshold with a rolling estimate of the local variance scale. Experiments on LIBERO, RoboTwin, CALVIN, and real-world manipulation show that DVAC improves task success while reducing replanning frequency. With a $\pi_{0.5}$-based policy, DVAC improves LIBERO success from 94.75% to 98.00% and reduces replanning by 43.0%, while also yielding aggregate gains on RoboTwin and CALVIN and improving real-world execution efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the denoising process in flow-based robot policies contains an intrinsic signal of task phases, with clean-action estimates showing higher variance during contact-rich or precision-sensitive operations than in predictable free-space motion. Motivated by this, it proposes DVAC, a test-time adaptive chunking method that measures variance over final denoising steps, executes stable low-variance prefixes, and uses rolling calibration of the local variance scale to decide replanning points. This yields higher task success and lower replanning frequency than fixed chunking on LIBERO (94.75% to 98.00% success, 43% replan reduction with a π0.5 policy), RoboTwin, CALVIN, and real hardware.
Significance. If the empirical results hold, the work offers a practical, architecture-agnostic, training-free improvement to flow-based policies by exploiting a property of the existing denoising process. The test-time nature, evaluation across multiple simulation benchmarks plus real hardware, and direct comparison to fixed chunking are strengths that could make the heuristic immediately useful for deployment.
major comments (2)
- [Experiments / abstract results] The experimental results (abstract and implied Experiments section) report specific gains such as the LIBERO success improvement and 43% replanning reduction without error bars, number of trials, or statistical significance tests. This leaves open whether the gains are robust or could arise from unexamined experimental choices in threshold calibration or rollout selection.
- [Method (DVAC description) and Experiments] The weakest assumption—that the variance signal over final denoising steps reliably indicates phases and generalizes via rolling calibration—is presented as an observation but lacks an ablation on the calibration window size or sensitivity of performance to the variance threshold. Without this, it is unclear if the method's benefits are tied to post-hoc tuning on the evaluated tasks.
minor comments (2)
- [Abstract] The abstract introduces π0.5 without definition; the main text should clarify what this base policy is (e.g., a specific flow-matching model) on first use.
- [Method] Notation for the variance measure and rolling estimate could be formalized with an equation to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation. We address the two major comments below and will revise the manuscript accordingly to improve clarity and robustness of the reported results.
read point-by-point responses
-
Referee: [Experiments / abstract results] The experimental results (abstract and implied Experiments section) report specific gains such as the LIBERO success improvement and 43% replanning reduction without error bars, number of trials, or statistical significance tests. This leaves open whether the gains are robust or could arise from unexamined experimental choices in threshold calibration or rollout selection.
Authors: We agree that the current presentation lacks sufficient statistical detail. In the revised manuscript we will explicitly state the number of evaluation rollouts per task (50 on LIBERO, 30 on RoboTwin and CALVIN), report mean success rates with standard deviations across three random seeds where available, and include a statistical significance test (paired t-test) comparing DVAC against fixed chunking. If any benchmark was evaluated with a single seed, we will note this limitation and add multi-seed results for the camera-ready version. revision: yes
-
Referee: [Method (DVAC description) and Experiments] The weakest assumption—that the variance signal over final denoising steps reliably indicates phases and generalizes via rolling calibration—is presented as an observation but lacks an ablation on the calibration window size or sensitivity of performance to the variance threshold. Without this, it is unclear if the method's benefits are tied to post-hoc tuning on the evaluated tasks.
Authors: We accept that an explicit ablation would strengthen the claim of robustness. We will add a new subsection in Experiments that varies the rolling calibration window (5, 10, 20 steps) and the variance threshold multiplier (±10 % and ±20 % around the calibrated value) on LIBERO and RoboTwin. The results will show that performance remains above the fixed-chunking baseline across a reasonable range of these hyperparameters, confirming that the gains are not the result of narrow post-hoc tuning. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central contribution is an empirical observation (clean-action variance over final denoising steps is higher in contact/precision phases) followed by a purely test-time heuristic (DVAC) that uses a rolling variance-scale threshold to decide chunk execution length. No derivation chain reduces a claimed prediction or result to its own inputs by construction: there are no fitted parameters renamed as predictions, no self-definitional loops, and no load-bearing self-citations or uniqueness theorems. The method makes no architectural change to the underlying flow policy and is evaluated against a fixed-chunking baseline on multiple external benchmarks. The reported gains (e.g., LIBERO 94.75% → 98.00%) are therefore direct empirical outcomes of the heuristic rather than quantities forced by the paper's own equations or prior self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Variance of clean-action estimates over the final denoising steps indicates task phase predictability.
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. RT-1: Robotics transformer for real-world control at scale. In Robotics: Science and Systems, 2023. URLhttps://arxiv.org/abs/2212.06817
Pith/arXiv arXiv 2023
-
[2]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. In Proceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 2165–2183. PMLR, 2023. URLhttps://proceedings.mlr. press/v229...
2023
-
[3]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. PaLM-E: An embodied multimodal language model. InProceedings of the 40th International Confere...
-
[4]
URLhttps://proceedings.mlr.press/v202/driess23a.html
PMLR, 2023. URLhttps://proceedings.mlr.press/v202/driess23a.html
2023
-
[5]
Open X-Embodiment Collaboration, A. Padalkar, A. Pooley, A. Jain, A. Bewley, A. Herzog, A. Irpan, A. Khazatsky, A. Rai, A. Singh, et al. Open x-embodiment: Robotic learning datasets and RT-X models.arXiv preprint arXiv:2310.08864, 2023. URLhttps://arxiv.org/abs/ 2310.08864
Pith/arXiv arXiv 2023
-
[6]
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024. URLhttps://arxiv.org/abs/2405.12213
Pith/arXiv arXiv 2024
-
[7]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. InProceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learni...
2025
- [8]
-
[9]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success. InRobotics: Science and Systems, 2025. URLhttps://arxiv.org/ abs/2502.19645
Pith/arXiv arXiv 2025
-
[10]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems, Daegu, Republic of Korea, July
-
[11]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
doi:10.15607/RSS.2023.XIX.016. URLhttps://arxiv.org/abs/2304.13705
work page internal anchor Pith review Pith/arXiv arXiv doi:10.15607/rss.2023.xix.016 2023
-
[12]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems,
-
[13]
URLhttps://arxiv.org/abs/2303.04137
-
[15]
D. Jing, G. Wang, J. Liu, W. Tang, Z. Sun, Y . Yao, Z. Wei, Y . Liu, Z. Lu, and M. Ding. Mixture of horizons in action chunking.arXiv preprint arXiv:2511.19433, 2025. URLhttps: //arxiv.org/abs/2511.19433. 10
Pith/arXiv arXiv 2025
-
[17]
Y . Liu, J. I. Hamid, A. Xie, Y . Lee, M. Du, and C. Finn. Bidirectional decoding: Improv- ing action chunking via guided test-time sampling. InInternational Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=qZmn2hkuzw
2025
-
[18]
J. So, C. Lee, S. Lee, J. Ok, and E. Park. Improving generative behavior cloning via self- guidance and adaptive chunking.arXiv preprint arXiv:2510.12392, 2025. URLhttps:// arxiv.org/abs/2510.12392
arXiv 2025
-
[19]
R. Gou. Learning temporal action chunking for motor control. Master’s thesis, Univer- sity of British Columbia, 2024. URLhttps://open.library.ubc.ca/soa/cIRcle/ collections/ubctheses/24/items/1.0445184. M.Sc. thesis
2024
-
[20]
Y . Liang, X. Wang, K. Wang, S. Wang, X. Peng, H. Chen, D. K. H. Chua, and P. Vadakkepat. Adaptive action chunking at inference-time for vision-language-action models. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026. URL https://arxiv.org/abs/2604.04161
Pith/arXiv arXiv 2026
-
[21]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowl- edge transfer for lifelong robot learning. InAdvances in Neural Information Processing Sys- tems Datasets and Benchmarks Track, 2023. URLhttps://arxiv.org/abs/2306.03310
Pith/arXiv arXiv 2023
-
[22]
Y . Mu, T. Chen, Z. Chen, S. Peng, Z. Lan, Z. Gao, Z. Liang, Q. Yu, Y . Zou, M. Xu, L. Lin, Z. Xie, M. Ding, and P. Luo. RoboTwin: Dual-arm robot benchmark with generative digital twins. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2025. URLhttps://arxiv.org/abs/2504.13059
arXiv 2025
-
[23]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. CALVIN: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022. doi:10.1109/LRA.2022.3180108. URLhttps: //arxiv.org/abs/2112.03227
-
[24]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840– 6851, 2020. URLhttps://proceedings.neurips.cc/paper/2020/hash/ 4c5bcfec8584af0d967f1ab10179ca4b-Abstract.html
2020
-
[25]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score- based generative modeling through stochastic differential equations. InInternational Con- ference on Learning Representations, 2021. URLhttps://openreview.net/forum?id= PxTIG12RRHS
2021
-
[26]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023. URLhttps: //openreview.net/forum?id=PqvMRDCJT9t
2023
-
[27]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations, 2023. URL https://arxiv.org/abs/2209.03003
Pith/arXiv arXiv 2023
-
[28]
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: A vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025. URLhttps://arxiv.org/abs/ 2504.16054. 11
Pith/arXiv arXiv 2025
-
[29]
K. Black, M. Y . Galliker, and S. Levine. Real-time execution of action chunking flow policies. arXiv preprint arXiv:2506.07339, 2025. URLhttps://arxiv.org/abs/2506.07339
Pith/arXiv arXiv 2025
-
[31]
S.-W. Lee and Y .-L. Kuo. Diff-DAgger: Uncertainty estimation with diffusion policy for robotic manipulation.arXiv preprint arXiv:2410.14868, 2024. URLhttps://arxiv.org/ abs/2410.14868
arXiv 2024
-
[32]
S. Ye, J. Jang, B. Jeon, S. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, et al. Latent action pretraining from videos.arXiv preprint arXiv:2406.05173, 2024. URL https://arxiv.org/abs/2406.05173
arXiv 2024
-
[33]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, et al. CoT- VLA: Visual chain-of-thought reasoning for vision-language-action models.arXiv preprint arXiv:2505.15324, 2025. URLhttps://arxiv.org/abs/2505.15324
arXiv 2025
-
[35]
URLhttps://arxiv.org/abs/2506.02146
-
[36]
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. FAST: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2504.01227, 2025. URLhttps://arxiv.org/abs/2504.01227
arXiv 2025
-
[37]
X. Chen, H. Wei, P. Zhang, C. Zhang, K. Wang, Y . Guo, R. Yang, Y . Wang, X. Xiao, L. Zhao, et al. VILLA-X: Enhancing latent action modeling in vision-language-action models.arXiv preprint arXiv:2507.03867, 2025. URLhttps://arxiv.org/abs/2507.03867
arXiv 2025
-
[38]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2508.12268, 2025. URLhttps://arxiv.org/abs/2508.12268
Pith/arXiv arXiv 2025
-
[39]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. UniVLA: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2503.10474, 2025. URL https://arxiv.org/abs/2503.10474
arXiv 2025
-
[40]
K. Zhang, J. Zhang, R. Xu, Y . Sun, S. Xue, Y . Wen, X. Guo, M. Guo, W. Liufu, L. Zi- hou, K. Ji, Y . Zhang, J. Zhu, J. Liu, Z. Li, R. Chen, M. Cao, J. Zhang, S. Zhao, X. Chang, F. Zheng, I. Laptev, and X. Liang. A1: A fully transparent open-source, adaptive and effi- cient truncated vision-language-action model.arXiv preprint arXiv:2604.05672, 2026. URL ...
Pith/arXiv arXiv 2026
-
[41]
Y . Fu, Z. Zhang, Y . Zhang, Z. Wang, Z. Huang, and Y . Luo. MergeVLA: Cross-skill model merging toward a generalist vision-language-action agent. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026. URLhttps://arxiv.org/ abs/2511.18810
arXiv 2026
-
[42]
H. Wang, G. Zhang, Y . Yan, R. R. Kompella, and G. Liu. VLA knows its limits.arXiv preprint arXiv:2602.21445, 2026. URLhttps://arxiv.org/abs/2602.21445
Pith/arXiv arXiv 2026
-
[43]
T. A. Driscoll and R. J. Braun.Fundamentals of Numerical Computation. SIAM, 2017
2017
-
[44]
C. Yu, Y . Wang, Z. Guo, H. Lin, S. Xu, H. Zang, Q. Zhang, Y . Wu, C. Zhu, J. Hu, Z. Huang, M. Wei, Y . Xie, K. Yang, B. Dai, Z. Xu, J. Du, X. Wang, X. Fu, L. Shi, Z. Liu, K. Chen, W. Liu, G. Liu, B. Li, J. Yang, Z. Yang, G. Dai, and Y . Wang. RLinf: Flexible and efficient large-scale reinforcement learning via macro-to-micro flow transformation.arXiv pre...
arXiv 2025
-
[45]
StarVLA Community. StarVLA: A lego-like codebase for vision-language-action model de- veloping.arXiv preprint arXiv:2604.05014, 2026. URLhttps://arxiv.org/abs/2604. 05014. 7 Appendix 7.1 Proof of the Tail-Variance Error Bound This appendix expands the derivation summarized in Section 3. We work at one fixed input state sand one fixed future chunk indexk, ...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.