Source-Grounded Data Generation for Text-to-JSON Learning
Pith reviewed 2026-06-26 17:30 UTC · model grok-4.3
The pith
A spreadsheet-grounded pipeline produces stronger training data for text-to-JSON extraction than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
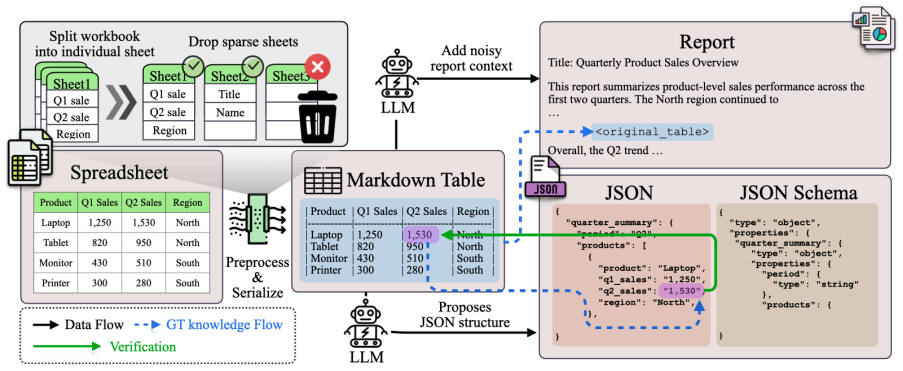
STAGE constructs reports and JSON schema by using LLMs for scalable synthesis while validating ground-truth values against the underlying spreadsheet, and evaluations on STAGE-Eval show that this produces stronger training data than existing approaches, lifting Qwen3-4B exact match from 31.37% to 74.27% and value accuracy from 45.46% to 90.69%.
What carries the argument
The STAGE pipeline, which pairs LLM synthesis of text and JSON with direct validation of values against a source spreadsheet.
If this is right
- Models trained on STAGE data achieve substantially higher exact-match rates on source-grounded text-to-JSON tasks.
- Value-level accuracy in JSON extraction rises sharply compared with models trained on existing synthetic datasets.
- The validation step allows scalable generation while preserving fidelity to the original source data.
- The method targets extraction needs in domains that store information in both documents and tabular records.
Where Pith is reading between the lines
- The same grounding principle could be applied to other output formats such as tables or XML when a comparable source of truth exists.
- Industries that already maintain both documents and spreadsheets could generate custom training sets without relying solely on public data.
- If the validation catches only value mismatches and not structural or semantic biases, additional checks may still be needed for full reliability.
Load-bearing premise
Validating the generated JSON values against the spreadsheet is enough to ensure the training pairs are high-quality and free of systematic errors introduced by the LLM step.
What would settle it
Training models on STAGE data and then measuring performance on a held-out collection of real documents paired with independently verified JSON extractions; if accuracy shows no improvement over baselines trained on unvalidated synthetic data, the claim would be falsified.
Figures

read the original abstract
From financial filings to clinical records, legacy industries rely heavily on long, unstructured documents to store high-value information. Reliably extracting this information into structured, machine-readable representations is a key prerequisite to making the contents accessible to automated systems. JSON is a natural target for such structured extraction, yet constructing reliable and scalable text-to-JSON training data remains challenging. To address this gap, we propose STAGE (Spreadsheet-grounded Text-to-JSON Artifact GEneration), a source-grounded data generation pipeline that constructs reports and JSON schema by using LLMs for scalable synthesis while validating ground-truth values against the underlying spreadsheet. Evaluations on STAGE-Eval, our source-grounded benchmark with an 851-example test set, show that STAGE produces stronger training data than existing approaches. This improves Qwen3-4B exact match from 31.37% to 74.27% and value accuracy from 45.46% to 90.69%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STAGE (Spreadsheet-grounded Text-to-JSON Artifact GEneration), a pipeline that uses LLMs to synthesize reports and JSON schemas from spreadsheets while validating extracted values against the source spreadsheet. It introduces the STAGE-Eval benchmark (851-example test set) and reports that training on STAGE-generated data improves Qwen3-4B exact match from 31.37% to 74.27% and value accuracy from 45.46% to 90.69% over existing approaches.
Significance. If the gains prove robust to the validation gap, the method offers a scalable route to source-grounded training data for text-to-JSON extraction, a practical need in finance, clinical records, and similar domains. The explicit grounding step is a methodological strength relative to purely synthetic generation.
major comments (2)
- [Pipeline description and evaluation] The validation step (described in the pipeline section) checks only that JSON values match the underlying spreadsheet; it does not verify that every JSON field is explicitly entailed by the generated report text, nor that the text avoids systematic omissions or stylistic artifacts introduced by the LLM. This leaves open the possibility that downstream gains reflect learning of generation-specific patterns rather than general extraction capability.
- [Evaluation and STAGE-Eval] The abstract and results section report large lifts on STAGE-Eval, but the exact construction of the held-out test set, data exclusion rules, and whether any STAGE-generated examples overlap with the test distribution are not visible; without these details the comparison baselines cannot be assessed for fairness.
minor comments (2)
- [Metrics] Define 'exact match' and 'value accuracy' precisely, including how partial matches or schema variations are handled.
- [Results] Add a small error analysis or qualitative examples showing cases where the generated text and JSON are misaligned despite value validation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below. Both points identify areas where additional clarity or detail is warranted, and we will revise the manuscript to incorporate the requested information.
read point-by-point responses
-
Referee: [Pipeline description and evaluation] The validation step (described in the pipeline section) checks only that JSON values match the underlying spreadsheet; it does not verify that every JSON field is explicitly entailed by the generated report text, nor that the text avoids systematic omissions or stylistic artifacts introduced by the LLM. This leaves open the possibility that downstream gains reflect learning of generation-specific patterns rather than general extraction capability.
Authors: We agree that the current validation enforces value grounding against the spreadsheet but does not perform explicit textual entailment checks between the generated report and each JSON field, nor does it systematically audit for LLM-induced stylistic artifacts or omissions. This is a deliberate design decision to prioritize scalable value accuracy from the source spreadsheet. However, the referee is correct that this leaves open the possibility that models trained on STAGE data may exploit generation-specific patterns. In the revision we will (a) explicitly state this limitation in the pipeline section, (b) add a short analysis of report-text coverage on a sample of generated examples, and (c) include an ablation that trains on STAGE data but evaluates on an external, non-STAGE test set to help separate pattern learning from general extraction gains. revision: yes
-
Referee: [Evaluation and STAGE-Eval] The abstract and results section report large lifts on STAGE-Eval, but the exact construction of the held-out test set, data exclusion rules, and whether any STAGE-generated examples overlap with the test distribution are not visible; without these details the comparison baselines cannot be assessed for fairness.
Authors: The referee correctly notes that the current manuscript does not provide sufficient detail on STAGE-Eval construction. We will add a dedicated subsection (likely in Section 4 or an appendix) that describes: (1) the source spreadsheets used, (2) the exact train/test split procedure and any exclusion rules applied to avoid leakage, (3) how the 851-example test set was sampled and annotated, and (4) explicit confirmation that no STAGE-generated training examples appear in the test distribution. These additions will allow readers to evaluate baseline fairness. revision: yes
Circularity Check
No circularity; empirical pipeline evaluated on held-out benchmark
full rationale
The paper describes a source-grounded data generation pipeline (STAGE) that synthesizes reports and JSON via LLMs, validates extracted values against spreadsheets, and measures downstream model improvements on the separate STAGE-Eval benchmark (851-example test set). No equations, derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. Claims rest on external empirical comparisons (e.g., Qwen3-4B exact match lift) rather than reducing to inputs by construction. This is a standard self-contained empirical result against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.04016 , volume=
Slot: Structuring the output of large language models , author=. arXiv preprint arXiv:2505.04016 , volume=. 2025 , publisher=
-
[2]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
2025 , eprint =
Qwen2.5 Technical Report , author =. 2025 , eprint =
2025
-
[4]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
2025 , month = dec, howpublished =
Gemini 3 Flash: frontier intelligence built for speed , author =. 2025 , month = dec, howpublished =
2025
-
[6]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Advances in Neural Information Processing Systems , volume=
Sheetpedia: A 300K-Spreadsheet Corpus for Spreadsheet Intelligence and LLM Fine-Tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations) , pages=
Llamafactory: Unified efficient fine-tuning of 100+ language models , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations) , pages=
-
[9]
2025 , eprint=
LLMs Are Biased Towards Output Formats! Systematically Evaluating and Mitigating Output Format Bias of LLMs , author=. 2025 , eprint=
2025
-
[10]
2026 IEEE International Conference on AI Engineering and Innovations (AIEI) , pages=
AI-Driven Document Automation: A Gemini API Integrated System for Data Extraction , author=. 2026 IEEE International Conference on AI Engineering and Innovations (AIEI) , pages=. 2026 , organization=
2026
-
[11]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Layoutlm: Pre-training of text and layout for document image understanding , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[12]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Lmdx: Language model-based document information extraction and localization , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[13]
Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Unified structure generation for universal information extraction , author=. Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[14]
arXiv preprint arXiv:2501.10868 , year=
Jsonschemabench: A rigorous benchmark of structured outputs for language models , author=. arXiv preprint arXiv:2501.10868 , year=
-
[15]
Frontiers of Computer Science , volume=
A survey of large language models , author=. Frontiers of Computer Science , volume=. 2026 , publisher=
2026
-
[16]
arXiv preprint arXiv:2509.25922 , year=
DeepJSONEval: Benchmarking Complex Nested JSON Data Mining for Large Language Models , author=. arXiv preprint arXiv:2509.25922 , year=
-
[17]
Extractbench: A benchmark and evaluation methodology for complex structured extraction, 2026
ExtractBench: A Benchmark and Evaluation Methodology for Complex Structured Extraction , author=. arXiv preprint arXiv:2602.12247 , year=
-
[18]
The Structured Output Benchmark: A Multi-Source Benchmark for Evaluating Structured Output Quality in Large Language Models , author=. arXiv preprint arXiv:2604.25359 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
arXiv preprint arXiv:2602.14743 , year=
LLMStructBench: Benchmarking Large Language Model Structured Data Extraction , author=. arXiv preprint arXiv:2602.14743 , year=
-
[20]
Efficient Guided Generation for Large Language Models
Efficient guided generation for large language models , author=. arXiv preprint arXiv:2307.09702 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Learning to generate structured output with schema reinforcement learning , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[22]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
PICARD: Parsing incrementally for constrained auto-regressive decoding from language models , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[23]
Proceedings of Machine Learning and Systems , volume=
Xgrammar: Flexible and efficient structured generation engine for large language models , author=. Proceedings of Machine Learning and Systems , volume=
-
[24]
Advances in Neural Information Processing Systems , volume=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
International Conference on Learning Representations , volume=
Toolllm: Facilitating large language models to master 16000+ real-world apis , author=. International Conference on Learning Representations , volume=
-
[26]
2017 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC) , pages=
Spreadsheet practices and challenges in a large multinational conglomerate , author=. 2017 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC) , pages=. 2017 , organization=
2017
-
[27]
The American Statistician , volume=
Data organization in spreadsheets , author=. The American Statistician , volume=. 2018 , publisher=
2018
-
[28]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
DSQG-syn: Synthesizing high-quality data for text-to-SQL parsing by domain specific question generation , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[29]
arXiv preprint arXiv:2509.25672 , year=
Sing-sql: A synthetic data generation framework for in-domain text-to-sql translation , author=. arXiv preprint arXiv:2509.25672 , year=
-
[30]
arXiv preprint arXiv:2511.04473 , year=
Ground-Truth Subgraphs for Better Training and Evaluation of Knowledge Graph Augmented LLMs , author=. arXiv preprint arXiv:2511.04473 , year=
-
[31]
2023 IEEE international conference on big data (BigData) , pages=
Spider4SPARQL: a complex benchmark for evaluating knowledge graph question answering systems , author=. 2023 IEEE international conference on big data (BigData) , pages=. 2023 , organization=
2023
-
[32]
2024 , howpublished =
Glaive Function Calling v2 , author =. 2024 , howpublished =
2024
-
[33]
ScrapeGraphAI-100k: Dataset for Schema-Constrained LLM Generation
ScrapeGraphAI-100k: A Large-Scale Dataset for LLM-Based Web Information Extraction , author=. arXiv preprint arXiv:2602.15189 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[35]
International semantic web conference , pages=
Lc-quad 2.0: A large dataset for complex question answering over wikidata and dbpedia , author=. International semantic web conference , pages=. 2019 , organization=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.