Black-Box Assisted Regression: Phase Transitions and Minimax Optimality
Pith reviewed 2026-06-25 21:06 UTC · model grok-4.3
The pith
In nonparametric regression assisted by a fixed black-box predictor, the minimax risk transitions at a critical closeness radius from the black-box error to the standard rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
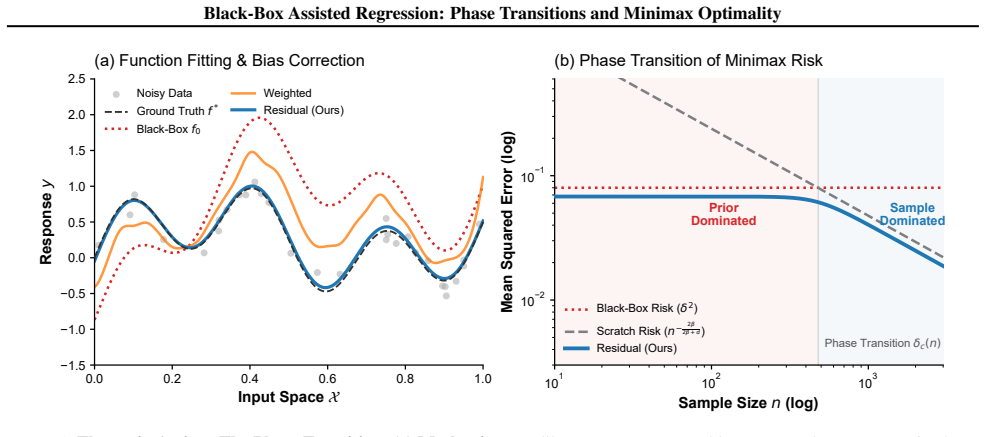
In the black-box assisted nonparametric regression setting, samples are observed along with access to a fixed predictor f0, and the target satisfies an L2 closeness bound of radius δ to f0. The minimax risk admits the finite-sample characterization with a phase transition at δ_c(n) ≍ n^{-β/(2β+d)}, where the leading risk term equals min{δ², n^{-2β/(2β+d)}}. The Safe Residual Estimator learns a residual correction initialized at zero (so it begins equal to f0) and applies holdout selection to revert to f0 when the correction lacks validation support, attaining the leading minimax term up to an additive validation-selection cost.
What carries the argument
The Safe Residual Estimator, which initializes its residual correction at zero and uses holdout selection to decide whether to apply the correction or revert to the black-box predictor alone.
If this is right
- When δ exceeds the critical radius the minimax risk equals δ², so the black-box alone is rate-optimal.
- When δ lies below the critical radius the minimax risk equals the standard nonparametric rate n^{-2β/(2β+d)}.
- The safe estimator matches the minimax leading term while guaranteeing it never exceeds the black-box risk.
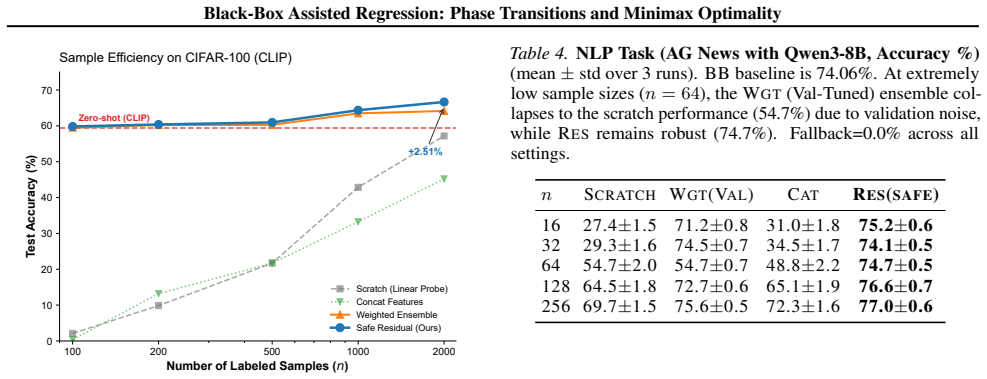
- The same residual-correction tradeoff appears in experiments on CIFAR-100 with CLIP and AG News with Qwen3-8B.
Where Pith is reading between the lines
- The phase-transition structure may extend to classification or other loss functions with analogous closeness assumptions.
- The validation-selection overhead could be reduced by alternative model-selection procedures not analyzed here.
- Similar safe-correction mechanisms might apply when multiple black-box predictors are available rather than one fixed f0.
Load-bearing premise
The unknown target function lies within some fixed but unknown L2 distance δ of the given black-box predictor.
What would settle it
Empirical risk measurements across a grid of δ values and sample sizes n that fail to exhibit the predicted switch in leading term from δ² to n^{-2β/(2β+d)} at the stated critical radius, or instances where the safe estimator performs worse than the black-box alone.
Figures
read the original abstract
Foundation models are often used as fixed black-box predictors for downstream tasks with limited labeled data, but their predictions may be biased and unsafe to trust blindly. We study this setting through black-box assisted nonparametric regression: a learner observes labeled samples and can query a fixed predictor $f_0$, while the target $f^*$ is close to $f_0$ in $L_2(P_X)$ up to an unknown radius $\delta$. We give a finite-sample minimax characterization showing a phase transition at $\delta_c(n) \asymp n^{-\beta/(2\beta+d)}$, with leading risk $\min\{\delta^2, n^{-2\beta/(2\beta+d)}\}$. We then analyze a Safe Residual Estimator: it learns a correction around $f_0$, initializes the residual head at zero so the initial predictor equals $f_0$, and uses holdout selection to revert to $f_0$ when the learned correction is not supported by validation data. Here, "safe" means avoiding negative transfer, i.e., performing worse than the black-box predictor alone. The estimator matches the leading minimax term up to an additive validation-selection cost. Synthetic regression experiments verify the predicted phase transition, while CIFAR-100 with CLIP and AG News with Qwen3-8B provide practice-facing evidence that the same residual-correction tradeoff is useful beyond the formal squared-loss regression setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes black-box assisted nonparametric regression, where labeled samples are available and a fixed predictor f0 can be queried, under the model that the target f* satisfies ||f* - f0||_{L2(P_X)} ≤ δ for unknown δ. It derives a finite-sample minimax characterization with a phase transition at δ_c(n) ≍ n^{-β/(2β+d)} and leading risk min{δ², n^{-2β/(2β+d)}}. A Safe Residual Estimator is introduced that learns a correction to f0 (initialized at zero residual), uses holdout validation to select whether to apply the correction or revert to f0, and is shown to match the minimax leading term up to an additive validation cost. Synthetic experiments confirm the phase transition, and real-data examples (CIFAR-100 with CLIP, AG News with Qwen3-8B) illustrate utility beyond squared loss.
Significance. If the finite-sample minimax bounds and matching upper bound for the Safe Residual Estimator hold, the work supplies a precise theoretical account of when and how much a fixed black-box predictor can safely assist nonparametric regression. The explicit phase transition and the guarantee against negative transfer are directly relevant to foundation-model-assisted learning with limited labels. The matching of the leading minimax term (up to validation cost) and the provision of both synthetic verification and practice-facing experiments strengthen the contribution.
minor comments (3)
- The abstract refers to 'finite-sample minimax characterization' and 'matching the leading minimax term'; the precise statements of the lower and upper bounds (including dependence on β, d, n, and δ) should be stated explicitly in the introduction or theorem statements for immediate readability.
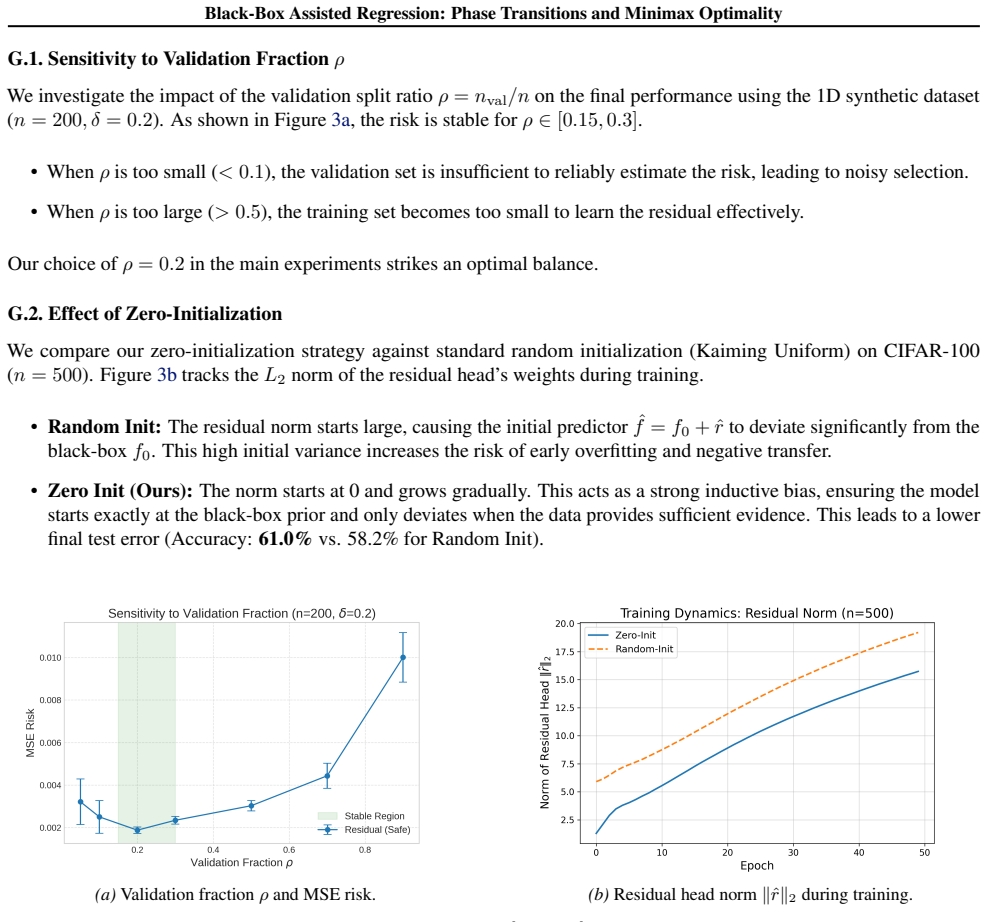
- Notation for the holdout selection procedure and the validation-selection cost should be introduced with a short display equation or algorithm box, as the current description leaves the exact form of the additive cost implicit.
- The real-data experiments are described only at high level; a brief table or paragraph clarifying the precise loss, the black-box model, and how δ is implicitly realized would help readers assess transfer beyond squared loss.
Simulated Author's Rebuttal
We thank the referee for their careful summary of our work and for the positive assessment of its significance in providing a finite-sample minimax characterization and safe estimator for black-box assisted regression. No major comments were listed in the report, so we have no specific points requiring response or revision at this time. We remain available to address any additional questions or to incorporate clarifications if the editor or referee requests them.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description present a standard finite-sample minimax analysis for nonparametric regression under an L2 closeness assumption to a fixed black-box predictor. The phase transition at δ_c(n) ≍ n^{-β/(2β+d)} and leading risk min{δ², n^{-2β/(2β+d)}} follow from conventional bias-variance and minimax lower-bound techniques in the field; the Safe Residual Estimator is defined explicitly via residual correction, zero initialization, and holdout selection, with performance guarantees stated relative to the minimax term plus an additive validation cost. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the given text. The derivation chain is self-contained against external nonparametric regression benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- δ
axioms (1)
- domain assumption Target belongs to a nonparametric function class (e.g., Holder with smoothness β in dimension d) for which the standard minimax rate is n^{-2β/(2β+d)}.
Reference graph
Works this paper leans on
-
[1]
Amini, M.-R., Feofanov, V., Pauletto, L., Hadjadj, L., Devijver, \'E ., and Maximov, Y. Self-training: A survey. Neurocomputing, 616: 0 128904, 2025. doi:10.1016/j.neucom.2024.128904
-
[2]
and Bates, Stephen and Fannjiang, Clara and Jordan, Michael I
Angelopoulos, A. N., Bates, S., Fannjiang, C., Jordan, M. I., and Zrnic, T. Prediction-powered inference. Science, 382 0 (6671): 0 669--674, 2023. doi:10.1126/science.adi6000
-
[3]
N., Duchi, J
Angelopoulos, A. N., Duchi, J. C., and Zrnic, T. Ppi++: Efficient prediction-powered inference, 2024
2024
-
[4]
A survey of cross-validation procedures for model selection , volume =
Arlot, S. and Celisse, A. A survey of cross-validation procedures for model selection. Statistics Surveys, 4: 0 40--79, 2010. doi:10.1214/09-SS054
-
[5]
Qwen technical report, 2023
Bai, J., Bai, S., Chu, Y., et al. Qwen technical report, 2023
2023
-
[6]
A theory of label propagation for subpopulation shift
Cai, T., Gao, R., Lee, J., and Lei, Q. A theory of label propagation for subpopulation shift. In Meila, M. and Zhang, T. (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp.\ 1170--1182. PMLR, 18--24 Jul 2021. URL https://proceedings.mlr.press/v139/cai21b.html
2021
-
[7]
Cai, T. T. and Pu, H. Transfer learning for nonparametric regression: Non-asymptotic minimax analysis and adaptive procedure, 2024
2024
-
[8]
URL https: //doi.org/10.1007/s10208-006-0196-8
Caponnetto, A. and De Vito, E. Optimal rates for the regularized least-squares algorithm. Foundations of Computational Mathematics, 7 0 (3): 0 331--368, 2007. doi:10.1007/s10208-006-0196-8
-
[9]
and Caron, F
Cortinovis, S. and Caron, F. Fab-ppi: Frequentist, assisted by bayes, prediction-powered inference, 2025
2025
-
[10]
Local Polynomial Modelling and Its Applications
Fan, J. Local Polynomial Modelling and Its Applications. Routledge, 1996. ISBN 9780203748725
1996
-
[11]
A., Dhingra, B., Globerson, A., and Cohen, W
Fisch, A., Maynez, J., Hofer, R. A., Dhingra, B., Globerson, A., and Cohen, W. W. Stratified prediction-powered inference for hybrid language model evaluation, 2024
2024
-
[12]
Deep learning, volume 1
Goodfellow, I., Bengio, Y., Courville, A., and Bengio, Y. Deep learning, volume 1. MIT press Cambridge, 2016
2016
-
[13]
URLhttps://doi.org/10.1109/ICCV51070.2023.00387
Gu, Z., Xu, C., Yang, J., and Cui, Z. Few-shot continual infomax learning. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp.\ 19167--19176, Paris, France, 2023. doi:10.1109/ICCV51070.2023.01761
-
[14]
The Elements of Statistical Learning
Hastie, T., Tibshirani, R., and Friedman, J. The Elements of Statistical Learning. Springer-Verlag, 2001
2001
-
[15]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[16]
A., Maynez, J., Dhingra, B., Fisch, A., Globerson, A., and Cohen, W
Hofer, R. A., Maynez, J., Dhingra, B., Fisch, A., Globerson, A., and Cohen, W. W. Bayesian prediction-powered inference, 2024
2024
-
[18]
C., Andreadis, P., and Diochnos, D
Kage, P., Rothenberger, J. C., Andreadis, P., and Diochnos, D. I. A review of pseudo-labeling for computer vision, 2025
2025
-
[19]
Transformers are minimax optimal nonparametric in-context learners
Kim, J., Nakamaki, T., and Suzuki, T. Transformers are minimax optimal nonparametric in-context learners. In Advances in Neural Information Processing Systems, volume 37, pp.\ 106667--106713, 2024
2024
-
[20]
M., Lu, K., Zrnic, T., Wang, S., and Bates, S
Kluger, D. M., Lu, K., Zrnic, T., Wang, S., and Bates, S. Prediction-powered inference with imputed covariates and nonuniform sampling, 2025
2025
-
[21]
and Hinton, G
Krizhevsky, A. and Hinton, G. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
2009
-
[22]
and Orabona, F
Kuzborskij, I. and Orabona, F. Stability and hypothesis transfer learning. In Proceedings of the 30th International Conference on Machine Learning, volume 28, pp.\ 942--950. PMLR, 2013
2013
-
[23]
Pseudo-label : The simple and efficient semi-supervised learning method for deep neural networks
Lee, D.-H. Pseudo-label : The simple and efficient semi-supervised learning method for deep neural networks. In ICML 2013 Workshop on Challenges in Representation Learning, 2013
2013
-
[24]
Tripartite weight-space ensemble for few-shot class-incremental learning
Lee, J., Hayat, M., and Yun, S. Tripartite weight-space ensemble for few-shot class-incremental learning. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 15329--15338, 2025
2025
-
[25]
Do we really need to access the source data? S ource hypothesis transfer for unsupervised domain adaptation
Liang, J., Hu, D., and Feng, J. Do we really need to access the source data? S ource hypothesis transfer for unsupervised domain adaptation. In Proceedings of the 37th International Conference on Machine Learning, volume 119, pp.\ 6028--6039. PMLR, 2020
2020
-
[26]
A comprehensive survey on test-time adaptation under distribution shifts
Liang, J., He, R., and Tan, T. A comprehensive survey on test-time adaptation under distribution shifts. International Journal of Computer Vision, 133 0 (1): 0 31--64, 2025
2025
-
[27]
and Reimherr, M
Lin, H. and Reimherr, M. Model-robust and adaptive-optimal transfer learning for tackling concept shifts in nonparametric regression, 2025
2025
-
[28]
C., and Oberst, M
Mani, P., Xu, P., Lipton, Z. C., and Oberst, M. No free lunch: Non-asymptotic analysis of prediction-powered inference, 2025
2025
-
[29]
Density Estimation via Model Selection, pp.\ 201--277
Massart, P. Density Estimation via Model Selection, pp.\ 201--277. Springer Berlin Heidelberg, 2007. doi:10.1007/978-3-540-48503-2_7
-
[30]
Pan, S. J. and Yang, Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 22 0 (10): 0 1345--1359, 2010. doi:10.1109/TKDE.2009.191
-
[31]
and Smola, A
Sch \"o lkopf, B. and Smola, A. J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. The MIT Press, 2001
2001
-
[32]
Siegel, J. W. Optimal approximation rates for deep ReLU neural networks on sobolev and besov spaces. Journal of Machine Learning Research, 24 0 (357): 0 1--52, 2023
2023
-
[33]
Fixmatch: Simplifying semi-supervised learning with consistency and confidence
Sohn, K., Berthelot, D., Carlini, N., et al. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. In Advances in Neural Information Processing Systems, volume 33, pp.\ 596--608, 2020
2020
-
[34]
Stone, C. J. Optimal global rates of convergence for nonparametric regression. The Annals of Statistics, 10 0 (4): 0 1040--1053, 1982
1982
-
[35]
Tsybakov, A. B. Introduction to Nonparametric Estimation. Springer, 2009
2009
-
[36]
Tent: Fully test-time adaptation by entropy minimization
Wang, D., Shelhamer, E., Liu, S., Olshausen, B., and Darrell, T. Tent: Fully test-time adaptation by entropy minimization. In International Conference on Learning Representations, 2021
2021
-
[37]
Continual test-time domain adaptation
Wang, Q., Fink, O., Van Gool, L., and Dai, D. Continual test-time domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 7201--7211, 2022
2022
-
[38]
Weiss, K., Khoshgoftaar, T. M., and Wang, D. A survey of transfer learning. Journal of Big Data, 3 0 (1): 0 9, 2016. doi:10.1186/s40537-016-0043-6
-
[39]
Xie, Q., Luong, M.-T., Hovy, E., and Le, Q. V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 10687--10698, 2020
2020
-
[40]
Qwen3 technical report, 2025
Yang, A., Li, A., Yang, B., et al. Qwen3 technical report, 2025
2025
-
[41]
On the optimal approximation of sobolev and besov functions using deep relu neural networks
Yang, Y. On the optimal approximation of sobolev and besov functions using deep relu neural networks. Applied and Computational Harmonic Analysis, 79: 0 101797, 2025. doi:10.1016/j.acha.2025.101797
-
[42]
Unsupervised word sense disambiguation rivaling supervised methods
Yarowsky, D. Unsupervised word sense disambiguation rivaling supervised methods. In 33rd Annual Meeting of the Association for Computational Linguistics, pp.\ 189--196, 1995
1995
-
[43]
N., and Ma, T
Zhang, H., Dauphin, Y. N., and Ma, T. Residual learning without normalization via better initialization. In International Conference on Learning Representations, 2019
2019
-
[44]
and Cand \`e s, E
Zrnic, T. and Cand \`e s, E. J. Cross-prediction-powered inference, 2024
2024
-
[45]
Science , year =
Prediction-powered inference , author =. Science , year =
-
[46]
2024 , eprint =
PPI++: Efficient Prediction-Powered Inference , author =. 2024 , eprint =
2024
-
[47]
2024 , eprint =
Cross-Prediction-Powered Inference , author =. 2024 , eprint =
2024
-
[48]
2024 , eprint =
Stratified Prediction-Powered Inference for Hybrid Language Model Evaluation , author =. 2024 , eprint =
2024
-
[49]
2024 , eprint =
Bayesian Prediction-Powered Inference , author =. 2024 , eprint =
2024
-
[50]
2025 , eprint =
FAB-PPI: Frequentist, Assisted by Bayes, Prediction-Powered Inference , author =. 2025 , eprint =
2025
-
[51]
2025 , eprint =
No Free Lunch: Non-Asymptotic Analysis of Prediction-Powered Inference , author =. 2025 , eprint =
2025
-
[52]
2025 , eprint =
Prediction-Powered Inference with Imputed Covariates and Nonuniform Sampling , author =. 2025 , eprint =
2025
-
[53]
Proceedings of the 38th International Conference on Machine Learning , year =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , year =
-
[54]
2025 , eprint =
Qwen3 Technical Report , author =. 2025 , eprint =
2025
-
[55]
2023 , eprint =
Qwen Technical Report , author =. 2023 , eprint =
2023
-
[56]
Introduction to Nonparametric Estimation , author =
-
[57]
High-Dimensional Statistics: A Non-Asymptotic Viewpoint , author =
-
[58]
All of nonparametric statistics , author =
-
[59]
The Annals of Statistics , year =
Optimal Global Rates of Convergence for Nonparametric Regression , author =. The Annals of Statistics , year =
-
[60]
Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond , author =
-
[61]
2001 , pages =
The Elements of Statistical Learning , author =. 2001 , pages =
2001
-
[62]
Deep learning , author =
-
[63]
, journal =
Siegel, Jonathan W. , journal =. Optimal Approximation Rates for Deep. 2023 , volume =
2023
-
[64]
Advances in Neural Information Processing Systems , volume =
Transformers are Minimax Optimal Nonparametric In-Context Learners , author =. Advances in Neural Information Processing Systems , volume =
-
[65]
Applied and Computational Harmonic Analysis , year =
On the optimal approximation of Sobolev and Besov functions using deep ReLU neural networks , author =. Applied and Computational Harmonic Analysis , year =
-
[66]
2024 , eprint =
Transfer Learning for Nonparametric Regression: Non-asymptotic Minimax Analysis and Adaptive Procedure , author =. 2024 , eprint =
2024
-
[67]
2025 , eprint =
Model-Robust and Adaptive-Optimal Transfer Learning for Tackling Concept Shifts in Nonparametric Regression , author =. 2025 , eprint =
2025
-
[68]
Proceedings of the 30th International Conference on Machine Learning , year =
Stability and Hypothesis Transfer Learning , author =. Proceedings of the 30th International Conference on Machine Learning , year =
-
[69]
Do We Really Need to Access the Source Data?
Liang, Jian and Hu, Dapeng and Feng, Jiashi , booktitle =. Do We Really Need to Access the Source Data?. 2020 , pages =
2020
-
[70]
ICML 2013 Workshop on Challenges in Representation Learning , year =
Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks , author =. ICML 2013 Workshop on Challenges in Representation Learning , year =
2013
-
[71]
33rd Annual Meeting of the Association for Computational Linguistics , year =
Unsupervised Word Sense Disambiguation Rivaling Supervised Methods , author =. 33rd Annual Meeting of the Association for Computational Linguistics , year =
-
[72]
Advances in Neural Information Processing Systems , volume =
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence , author =. Advances in Neural Information Processing Systems , volume =
-
[73]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Self-Training With Noisy Student Improves ImageNet Classification , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[74]
Neurocomputing , year =
Self-training: A survey , author =. Neurocomputing , year =
-
[75]
2025 , eprint =
A Review of Pseudo-Labeling for Computer Vision , author =. 2025 , eprint =
2025
-
[76]
International Journal of Computer Vision , year =
A comprehensive survey on test-time adaptation under distribution shifts , author =. International Journal of Computer Vision , year =
-
[77]
International Conference on Learning Representations , year =
Tent: Fully Test-Time Adaptation by Entropy Minimization , author =. International Conference on Learning Representations , year =
-
[78]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Continual Test-Time Domain Adaptation , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[79]
Statistics Surveys , year =
A survey of cross-validation procedures for model selection , author =. Statistics Surveys , year =
-
[80]
Concentration Inequalities and Model Selection , year =
Density Estimation via Model Selection , author =. Concentration Inequalities and Model Selection , year =
-
[81]
Foundations of Computational Mathematics , year =
Optimal Rates for the Regularized Least-Squares Algorithm , author =. Foundations of Computational Mathematics , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.