A Stationary (and Therefore Compatible) Representation is All You Need
Pith reviewed 2026-06-27 10:31 UTC · model grok-4.3
The pith
Stationary representations learned with d-Simplex fixed classifiers are formally compatible.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
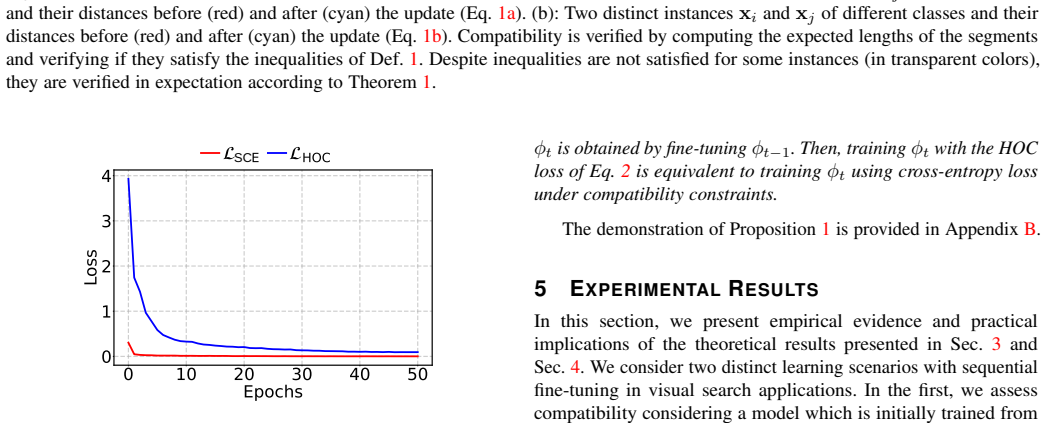
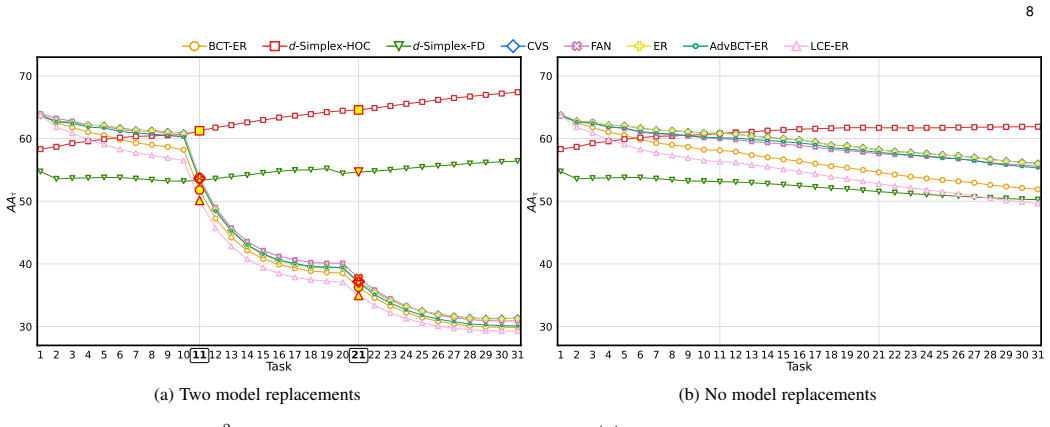
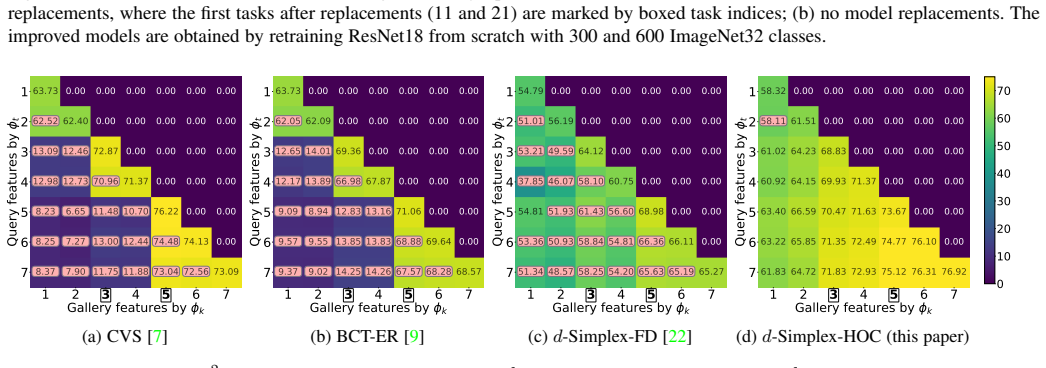
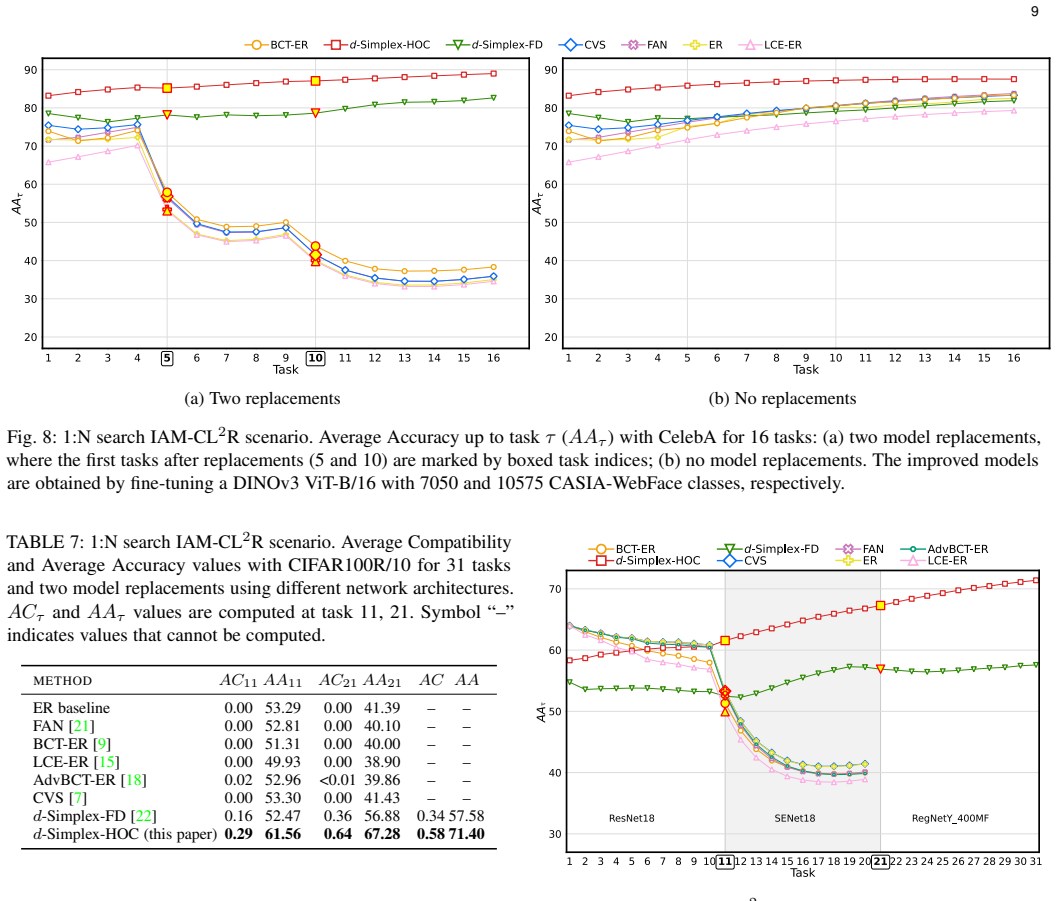
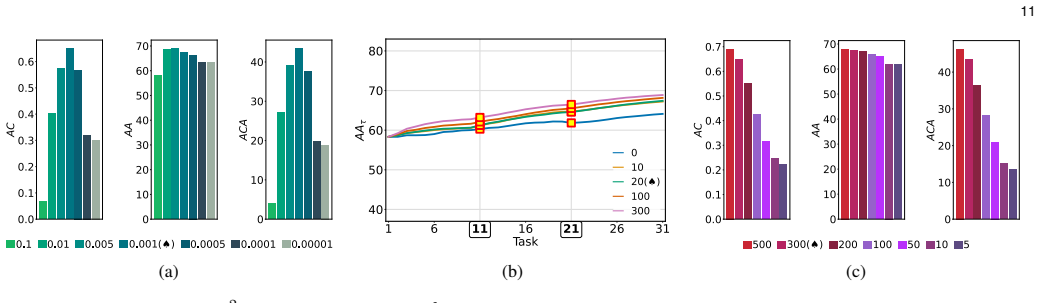
Stationary representations learned by d-Simplex fixed classifiers imply compatibility as in its formal definition. This establishes a foundation for learning compatibility in sequential model fine-tuning. Training with the cross-entropy loss aligns first-order statistics, while adding a contrastive loss captures higher-order dependencies and remains equivalent to constrained cross-entropy training. Experiments in retrieval tasks confirm uninterrupted services and state-of-the-art performance during updates and replacements.
What carries the argument
The d-Simplex fixed classifier, which fixes classifier weights to simplex vertices to enforce stationary representations that satisfy compatibility constraints.
If this is right
- Sequential fine-tuning maintains compatibility without re-encoding galleries.
- Retrieval performance improves during model updates and replacements.
- The combined loss aligns higher-order dependencies beyond first-order statistics.
- Pre-trained models can be replaced occasionally while keeping services uninterrupted.
Where Pith is reading between the lines
- Similar fixed classifiers might achieve stationarity in other architectures or domains.
- Reducing reprocessing could lower costs in large deployed retrieval systems.
- This equivalence might allow simpler training procedures in compatible learning setups.
Load-bearing premise
That the convex combination of cross-entropy and contrastive loss with a d-Simplex fixed classifier is equivalent to cross-entropy training under the compatibility constraints while also aligning higher-order feature dependencies.
What would settle it
An experiment in which swapping an updated model for a prior one produces retrieval accuracy below the level expected from compatible representations, showing that the learned features fail to remain interchangeable.
Figures

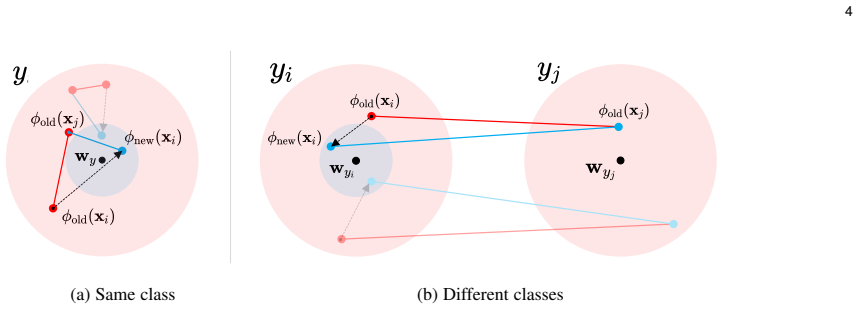
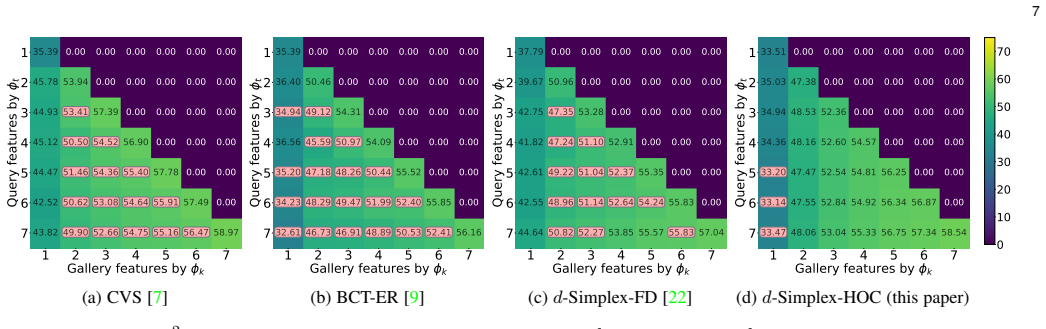
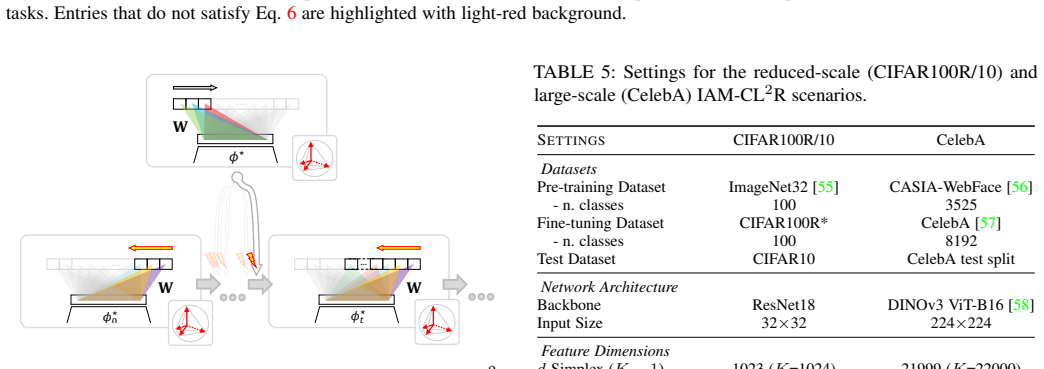
read the original abstract
Learning compatible representations aims to learn feature representations that can be used interchangeably over time whenever a model undergoes updates. In this paper, we demonstrate that stationary representations learned by d-Simplex fixed classifiers imply compatibility as in its formal definition. This result establishes a foundation for future works and can be directly exploited in practical learning scenarios. We address the challenge of learning compatibility using $d$-Simplex fixed classifiers when the model is sequentially fine-tuned. Learning according to a d-Simplex fixed classifier with the cross-entropy loss aligns feature distributions at the first-order statistics. Consequently, it may not fully capture higher-order dependencies in the representation between model updates. To address this issue, we demonstrate that training the model using a $d$-Simplex fixed classifier through a convex combination of the cross-entropy loss and a contrastive loss not only captures higher-order dependencies, but is also equivalent to learning with the cross-entropy under the compatibility constraints. We confirm our findings with extensive experiments also considering a new scenario where a pre-trained model is sequentially fine-tuned and occasionally replaced with an improved model. We show that stationary representations enable uninterrupted retrieval services (without reprocessing gallery images) while improving performance during model updates and replacements, achieving state-of-the-art. Code at https://github.com/miccunifi/iamcl2r.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that representations learned to be stationary via d-Simplex fixed classifiers are compatible by definition (i.e., interchangeable across model updates). It further claims that a convex combination of cross-entropy and contrastive loss with such a classifier both captures higher-order feature dependencies and is mathematically equivalent to plain cross-entropy training under the compatibility constraints. The authors validate the approach on sequential fine-tuning and model-replacement scenarios for image retrieval, reporting state-of-the-art performance with uninterrupted gallery services.
Significance. If the claimed equivalence is rigorously established, the result supplies a practical, constraint-free route to compatible representations that directly supports continual retrieval without re-indexing. The experimental protocol that includes occasional model replacement is a useful addition to the literature on lifelong representation learning.
major comments (2)
- [Abstract and §3] Abstract and §3 (loss formulation): the central assertion that the convex combination of cross-entropy and contrastive loss 'is also equivalent to learning with the cross-entropy under the compatibility constraints' while additionally aligning higher-order moments is stated without an explicit derivation showing that the contrastive term becomes redundant precisely when first-order stationarity holds. This equivalence is load-bearing for the claim that stationarity implies compatibility; its absence leaves open the possibility that the higher-order term perturbs the first-order condition.
- [§4] §4 (experiments): the reported gains in retrieval performance under model replacement are presented as evidence that stationary representations enable uninterrupted services, yet no ablation isolates whether the observed compatibility stems from the d-Simplex fixed classifier alone or from the specific convex-loss construction; without this control the causal link between the claimed equivalence and the empirical outcome remains unverified.
minor comments (2)
- The GitHub link is given but the repository contents (training scripts, exact hyper-parameters for the convex weight) are not referenced in the text; adding a pointer to the relevant files would improve reproducibility.
- Notation for the d-Simplex fixed classifier and the compatibility constraint should be introduced once with a single equation rather than re-defined in multiple places.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (loss formulation): the central assertion that the convex combination of cross-entropy and contrastive loss 'is also equivalent to learning with the cross-entropy under the compatibility constraints' while additionally aligning higher-order moments is stated without an explicit derivation showing that the contrastive term becomes redundant precisely when first-order stationarity holds. This equivalence is load-bearing for the claim that stationarity implies compatibility; its absence leaves open the possibility that the higher-order term perturbs the first-order condition.
Authors: We agree that the equivalence claim would be strengthened by an explicit derivation. While the manuscript states that the convex combination is equivalent to cross-entropy under the compatibility constraints, the step-by-step argument showing the contrastive term becomes redundant exactly when first-order stationarity holds is not expanded in full detail. In the revised manuscript we will insert a dedicated derivation subsection in §3 that formally shows: under the definition of compatibility (first-order moment alignment between successive models), the contrastive component evaluates to zero and the joint objective reduces to cross-entropy, while the contrastive term still enforces higher-order alignment during training. revision: yes
-
Referee: [§4] §4 (experiments): the reported gains in retrieval performance under model replacement are presented as evidence that stationary representations enable uninterrupted services, yet no ablation isolates whether the observed compatibility stems from the d-Simplex fixed classifier alone or from the specific convex-loss construction; without this control the causal link between the claimed equivalence and the empirical outcome remains unverified.
Authors: We concur that an ablation isolating the fixed classifier from the convex-loss construction would make the causal attribution clearer. The current experiments demonstrate end-to-end performance in the model-replacement setting but do not contain a direct control that trains the d-Simplex classifier with plain cross-entropy versus the convex combination. In the revision we will add such an ablation (plus a non-fixed-classifier baseline) to verify that compatibility is induced by the d-Simplex stationarity condition and that the equivalence result holds in practice. revision: yes
Circularity Check
No significant circularity; claims rest on internal derivations and experiments
full rationale
The abstract asserts that d-Simplex fixed classifiers yield stationary representations implying compatibility by formal definition, and that a convex CE+contrastive loss is equivalent to constrained CE while capturing higher-order statistics. No equations are provided showing that any prediction reduces to its inputs by construction, no self-citation is invoked as load-bearing justification for a uniqueness theorem or ansatz, and the equivalence is presented as a demonstrated result rather than a definitional renaming or fitted-input prediction. The paper's central chain therefore remains self-contained against external benchmarks and does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption d-Simplex fixed classifiers produce stationary representations that align first-order statistics under cross-entropy
Reference graph
Works this paper leans on
-
[1]
Representation learning: A review and new perspectives.IEEE transactions on pattern analysis and machine intelligence, 35(8):1798–1828, 2013
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives.IEEE transactions on pattern analysis and machine intelligence, 35(8):1798–1828, 2013
2013
-
[2]
Recent advances in open set recognition: A survey.IEEE transactions on pattern analysis and machine intelligence, 43(10):3614–3631, 2020
Chuanxing Geng, Sheng-jun Huang, and Songcan Chen. Recent advances in open set recognition: A survey.IEEE transactions on pattern analysis and machine intelligence, 43(10):3614–3631, 2020
2020
-
[3]
Deep learning for instance retrieval: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
Wei Chen, Yu Liu, Weiping Wang, Erwin M Bakker, Theodoros Georgiou, Paul Fieguth, Li Liu, and Michael S Lew. Deep learning for instance retrieval: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
2022
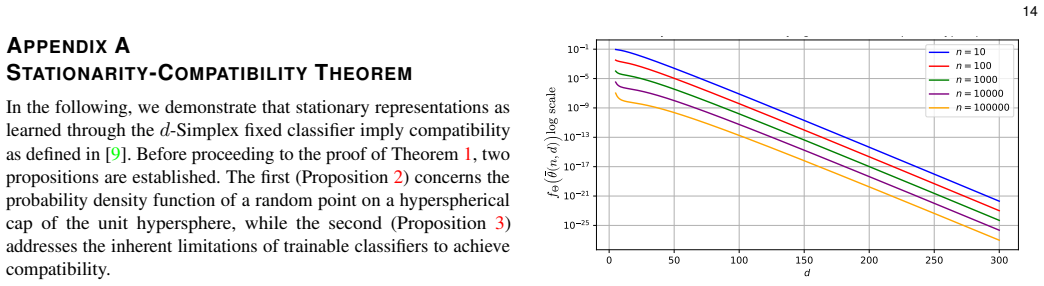
-
[4]
Lifelong person re-identification via adaptive knowledge accumulation
Nan Pu, Wei Chen, Yu Liu, Erwin M Bakker, and Michael S Lew. Lifelong person re-identification via adaptive knowledge accumulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7901–7910, 2021
2021
-
[5]
On the exploration of incremental learning for fine-grained image retrieval.Proceedings BMVC 2020, 2020
Wei Chen, Yu Liu, Weiping Wang, Tinne Tuytelaars, Erwin M Bakker, and Michael Lew. On the exploration of incremental learning for fine-grained image retrieval.Proceedings BMVC 2020, 2020
2020
-
[6]
Con- tinual representation learning for biometric identification
Bo Zhao, Shixiang Tang, Dapeng Chen, Hakan Bilen, and Rui Zhao. Con- tinual representation learning for biometric identification. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1198–1208, 2021
2021
-
[7]
Timmy S. T. Wan, Jun-Cheng Chen, Tzer-Yi Wu, and Chu-Song Chen. Continual learning for visual search with backward consistent feature embedding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16702–16711, June 2022
2022
-
[8]
Nan Pu, Zhun Zhong, Nicu Sebe, and Michael S. Lew. A memorizing and generalizing framework for lifelong person re-identification.IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–18, 2023
2023
-
[9]
Towards backward-compatible representation learning
Yantao Shen, Yuanjun Xiong, Wei Xia, and Stefano Soatto. Towards backward-compatible representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6368–6377, 2020
2020
-
[10]
Beyond neural scaling laws: beating power law scaling via data pruning
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari Morcos. Beyond neural scaling laws: beating power law scaling via data pruning. InNeurIPS, 2022
2022
-
[11]
Energy and policy considerations for deep learning in NLP
Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in NLP. InACL (1), pages 3645–3650. Association for Computational Linguistics, 2019
2019
-
[12]
Privacy in the age of medical big data.Nature medicine, 25(1):37–43, 2019
W Nicholson Price and I Glenn Cohen. Privacy in the age of medical big data.Nature medicine, 25(1):37–43, 2019
2019
-
[13]
Unified representation learning for cross model compatibility
Chien-Yi Wang, Ya-Liang Chang, Shang-Ta Yang, Dong Chen, and Shang- Hong Lai. Unified representation learning for cross model compatibility. In31st British Machine Vision Conference 2020, BMVC 2020. BMV A Press, 2020
2020
-
[14]
Cores: Compatible representations via stationarity.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
Niccolo Biondi, Federico Pernici, Matteo Bruni, and Alberto Del Bimbo. Cores: Compatible representations via stationarity.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[15]
Learning compatible embeddings
Qiang Meng, Chixiang Zhang, Xiaoqiang Xu, and Feng Zhou. Learning compatible embeddings. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9939–9948, 2021
2021
-
[16]
Towards universal backward-compatible representation learning
Binjie Zhang, Yixiao Ge, Yantao Shen, Shupeng Su, Fanzi Wu, Chun Yuan, Xuyuan Xu, Yexin Wang, and Ying Shan. Towards universal backward-compatible representation learning. InIJCAI, pages 1615–1621. ijcai.org, 2022
2022
-
[17]
Compatibility-aware heterogeneous visual search
Rahul Duggal, Hao Zhou, Shuo Yang, Yuanjun Xiong, Wei Xia, Zhuowen Tu, and Stefano Soatto. Compatibility-aware heterogeneous visual search. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10723–10732, 2021
2021
-
[18]
Boundary-aware backward-compatible representation via adversarial learning in image retrieval
Tan Pan, Furong Xu, Xudong Yang, Sifeng He, Chen Jiang, Qingpei Guo, Feng Qian, Xiaobo Zhang, Yuan Cheng, Lei Yang, et al. Boundary-aware backward-compatible representation via adversarial learning in image retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15201–15210, 2023
2023
-
[19]
Hot-refresh model upgrades with regression-free compatible training in image retrieval
Binjie Zhang, Yixiao Ge, Yantao Shen, Yu Li, Chun Yuan, XUYUAN XU, Yexin Wang, and Ying Shan. Hot-refresh model upgrades with regression-free compatible training in image retrieval. InInternational Conference on Learning Representations, 2021
2021
-
[20]
Dual-tuning: Joint prototype transfer and structure regularization for compatible feature learning.IEEE Transactions on Multimedia, 25:7287–7298, 2023
Yan Bai, Jile Jiao, Yihang Lou, Shengsen Wu, Jun Liu, Xuetao Feng, and Ling-Yu Duan. Dual-tuning: Joint prototype transfer and structure regularization for compatible feature learning.IEEE Transactions on Multimedia, 25:7287–7298, 2023
2023
-
[21]
Memory-efficient incremental learning through feature adaptation
Ahmet Iscen, Jeffrey Zhang, Svetlana Lazebnik, and Cordelia Schmid. Memory-efficient incremental learning through feature adaptation. In European Conference on Computer Vision, pages 699–715. Springer, 2020
2020
-
[22]
Cl2r: Compatible lifelong learning representations
Niccolo Biondi, Federico Pernici, Matteo Bruni, Daniele Mugnai, and Alberto Del Bimbo. Cl2r: Compatible lifelong learning representations. ACM Transactions on Multimedia Computing, Communications and Applications, 18(2s):1–22, 2023
2023
-
[23]
Learning along the arrow of time: Hyperbolic geometry for backward-compatible representation learning
Ngoc Bui, Menglin Yang, Runjin Chen, Leonardo Neves, Mingxuan Ju, Rex Ying, Neil Shah, and Tong Zhao. Learning along the arrow of time: Hyperbolic geometry for backward-compatible representation learning. InICML, Proceedings of Machine Learning Research. PMLR / OpenReview.net, 2025
2025
-
[24]
Anti- forgetting adaptation for unsupervised person re-identification.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Hao Chen, Francois Bremond, Nicu Sebe, and Shiliang Zhang. Anti- forgetting adaptation for unsupervised person re-identification.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[25]
Query drift compensation: Enabling compatibility in continual learning of retrieval embedding models
Dipam Goswami, Liying Wang, Bartłomiej Twardowski, and Joost van de Weijer. Query drift compensation: Enabling compatibility in continual learning of retrieval embedding models. InConference on Lifelong Learning Agents, 2025
2025
-
[26]
Regular polytope networks.IEEE Transactions on Neural Networks and Learning Systems, 2021
Federico Pernici, Matteo Bruni, Claudio Baecchi, and Alberto Del Bimbo. Regular polytope networks.IEEE Transactions on Neural Networks and Learning Systems, 2021
2021
-
[27]
Neural collapse with unconstrained features.Sampling Theory, Signal Processing, and Data Analysis, 20(2):1–13, 2022
Dustin G Mixon, Hans Parshall, and Jianzong Pi. Neural collapse with unconstrained features.Sampling Theory, Signal Processing, and Data Analysis, 20(2):1–13, 2022
2022
-
[28]
A geometric analysis of neural collapse with unconstrained features.Advances in Neural Information Processing Systems, 34:29820–29834, 2021
Zhihui Zhu, Tianyu Ding, Jinxin Zhou, Xiao Li, Chong You, Jeremias Sulam, and Qing Qu. A geometric analysis of neural collapse with unconstrained features.Advances in Neural Information Processing Systems, 34:29820–29834, 2021
2021
-
[29]
Stationary representations: Optimally approximating compatibility and 12 implications for improved model replacements
Niccolò Biondi, Federico Pernici, Simone Ricci, and Alberto Del Bimbo. Stationary representations: Optimally approximating compatibility and 12 implications for improved model replacements. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[30]
R3 adversarial network for cross model face recognition
Ken Chen, Yichao Wu, Haoyu Qin, Ding Liang, Xuebo Liu, and Junjie Yan. R3 adversarial network for cross model face recognition. InCVPR, pages 9868–9876. Computer Vision Foundation / IEEE, 2019
2019
-
[31]
Forward compatible training for representa- tion learning.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
Vivek Ramanujan, Pavan Kumar Anasosalu Vasu, Ali Farhadi, Oncel Tuzel, and Hadi Pouransari. Forward compatible training for representa- tion learning.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[32]
λ-orthogonality regularization for compatible representation learning.Advances in Neural Information Processing Systems, 38:29036–29063, 2026
Simone Ricci, Niccolò Biondi, Federico Pernici, Ioannis Patras, and Alberto Del Bimbo. λ-orthogonality regularization for compatible representation learning.Advances in Neural Information Processing Systems, 38:29036–29063, 2026
2026
-
[33]
Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020
Vardan Papyan, XY Han, and David L Donoho. Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020
2020
-
[34]
Neural collapse: A review on modelling principles and generalization.Trans
Vignesh Kothapalli. Neural collapse: A review on modelling principles and generalization.Trans. Mach. Learn. Res., 2023, 2023
2023
-
[35]
Equiangular tight frames that contain regular simplices.Linear Algebra and its applications, 555:98–138, 2018
Matthew Fickus, John Jasper, Emily J King, and Dustin G Mixon. Equiangular tight frames that contain regular simplices.Linear Algebra and its applications, 555:98–138, 2018
2018
-
[36]
Exploring deep neural networks via layer-peeled model: Minority collapse in imbalanced training.Proceedings of the National Academy of Sciences, 118(43):e2103091118, 2021
Cong Fang, Hangfeng He, Qi Long, and Weijie J Su. Exploring deep neural networks via layer-peeled model: Minority collapse in imbalanced training.Proceedings of the National Academy of Sciences, 118(43):e2103091118, 2021
2021
-
[37]
Wenlong Ji, Yiping Lu, Yiliang Zhang, Zhun Deng, and Weijie J. Su. An unconstrained layer-peeled perspective on neural collapse. InICLR. OpenReview.net, 2022
2022
-
[38]
Inducing neural collapse in imbalanced learning: Do we really need a learnable classifier at the end of deep neural network? Advances in Neural Information Processing Systems, 2022
Yibo Yang, Liang Xie, Shixiang Chen, Xiangtai Li, Zhouchen Lin, and Dacheng Tao. Inducing neural collapse in imbalanced learning: Do we really need a learnable classifier at the end of deep neural network? Advances in Neural Information Processing Systems, 2022
2022
-
[39]
Neural collapse under mse loss: Proximity to and dynamics on the central path
XY Han, Vardan Papyan, and David L Donoho. Neural collapse under mse loss: Proximity to and dynamics on the central path. InInternational Conference on Learning Representations, 2022
2022
-
[40]
Maximally compact and separated features with regular polytope networks
Federico Pernici, Matteo Bruni, Claudio Baecchi, and Alberto Del Bimbo. Maximally compact and separated features with regular polytope networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2019
2019
-
[41]
Class-incremental learning with pre-allocated fixed classifiers
Federico Pernici, Matteo Bruni, Claudio Baecchi, Francesco Turchini, and Alberto Del Bimbo. Class-incremental learning with pre-allocated fixed classifiers. In2020 25th International Conference on Pattern Recognition (ICPR), pages 6259–6266. IEEE, 2021
2021
-
[42]
Yibo Yang, Haobo Yuan, Xiangtai Li, Zhouchen Lin, Philip H. S. Torr, and Dacheng Tao. Neural collapse inspired feature-classifier alignment for few-shot class-incremental learning. InICLR. OpenReview.net, 2023
2023
-
[43]
Forward compatible few-shot class-incremental learning
Da-Wei Zhou, Fu-Yun Wang, Han-Jia Ye, Liang Ma, Shiliang Pu, and De-Chuan Zhan. Forward compatible few-shot class-incremental learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9046–9056, 2022
2022
-
[44]
Scaling laws for the out-of-distribution generalization of image classifiers.ICML 2021 Workshop on Uncertainty and Robustness in Deep Learning., 2021
Gabriele Prato, Simon Guiroy, Ethan Caballero, Irina Rish, and Sarath Chandar. Scaling laws for the out-of-distribution generalization of image classifiers.ICML 2021 Workshop on Uncertainty and Robustness in Deep Learning., 2021
2021
-
[45]
Broken neural scaling laws
Ethan Caballero, Kshitij Gupta, Irina Rish, and David Krueger. Broken neural scaling laws. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[46]
Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[47]
Contrastive representa- tion distillation
Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive representa- tion distillation. InInternational Conference on Learning Representations, 2020
2020
-
[48]
Contrastive multiview coding
Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XI 16, pages 776–
2020
-
[49]
John Wiley & Sons, 1999
Thomas M Cover.Elements of information theory. John Wiley & Sons, 1999
1999
-
[50]
A discriminative feature learning approach for deep face recognition
Yandong Wen, Kaipeng Zhang, Zhifeng Li, and Yu Qiao. A discriminative feature learning approach for deep face recognition. InEuropean Conference on Computer Vision, 2016
2016
-
[51]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[52]
Tiny imagenet visual recognition challenge.CS 231N, page 3, 2015
Ya Le and Xuan Yang. Tiny imagenet visual recognition challenge.CS 231N, page 3, 2015
2015
-
[53]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[54]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011
2011
-
[55]
Patryk Chrabaszcz, Ilya Loshchilov, and Frank Hutter. A downsampled variant of imagenet as an alternative to the cifar datasets.arXiv preprint arXiv:1707.08819, 2017
Pith/arXiv arXiv 2017
-
[56]
Learning face representation from scratch.arXiv preprint arXiv:1411.7923, 2014
Dong Yi, Zhen Lei, Shengcai Liao, and Stan Z Li. Learning face representation from scratch.arXiv preprint arXiv:1411.7923, 2014
Pith/arXiv arXiv 2014
-
[57]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of International Conference on Computer Vision (ICCV), December 2015
2015
-
[58]
Dinov3.arXiv preprint arXiv:2508.10104, 2025
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
-
[59]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020
2020
-
[60]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
2001
-
[61]
Random point sets on the sphere—hole radii, covering, and separation.Experimental Mathematics, 27(1):62–81, 2018
Johann S Brauchart, Alexander B Reznikov, Edward B Saff, Ian H Sloan, Yu Guang Wang, and Robert S Womersley. Random point sets on the sphere—hole radii, covering, and separation.Experimental Mathematics, 27(1):62–81, 2018
2018
-
[62]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4690–4699, 2019
2019
-
[63]
Generalized neural collapse for a large number of classes
Jiachen Jiang, Jinxin Zhou, Peng Wang, Qing Qu, Dustin G Mixon, Chong You, and Zhihui Zhu. Generalized neural collapse for a large number of classes. InInternational Conference on Machine Learning, pages 22010–22041. PMLR, 2024
2024
-
[64]
The distances between random points in two concentric circles.Biometrika, 51(1/2):275–277, 1964
David Fairthorne. The distances between random points in two concentric circles.Biometrika, 51(1/2):275–277, 1964
1964
-
[65]
and Murugesan Venkatapathi
Arun I. and Murugesan Venkatapathi. An O(n) algorithm for generating uniform random vectors in n-dimensional cones.Sankhya A, 2025
2025
-
[66]
Two-player games for efficient non-convex constrained optimization
Andrew Cotter, Heinrich Jiang, and Karthik Sridharan. Two-player games for efficient non-convex constrained optimization. In Aurélien Garivier and Satyen Kale, editors,Proceedings of the 30th International Conference on Algorithmic Learning Theory, volume 98 ofProceedings of Machine Learning Research, pages 300–332. PMLR, 22–24 Mar 2019
2019
-
[67]
Churn reduction via distillation
Heinrich Jiang, Harikrishna Narasimhan, Dara Bahri, Andrew Cotter, and Afshin Rostamizadeh. Churn reduction via distillation. InICLR. OpenReview.net, 2022
2022
-
[68]
Maximum separation as inductive bias in one matrix
Tejaswi Kasarla, , Gertjan J Burghouts, Max van Spengler, Elise van der Pol, Rita Cucchiara, and Pascal Mettes. Maximum separation as inductive bias in one matrix. InNeurIPS, 2022. 13 Niccolò BiondiNiccolò Biondi is an Assistant Professor with the Department of information engineering and computer science, University of Trento, Italy. He received the M.S....
2022
-
[69]
Both expression come directly from the n-ball volume Vn(R) =π n/2Rn/Γ(n/2 + 1): differentiating in R gives the sphere surface area, while settingn=d−1yields the(d−1)-ball volume used for the disc surface area. Fig. 11: The angle density fΘ evaluated at the expected nearest- neighbor angle, according to Eq. 8. Different curves (logarithmic scale) correspon...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.