Underspecification does not imply Incoherence: The Risks of Semantic Collapse in Coding Models
Pith reviewed 2026-07-03 08:59 UTC · model grok-4.3
The pith
Large language models often collapse to one incorrect interpretation of ambiguous coding tasks instead of showing uncertainty through multiple outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
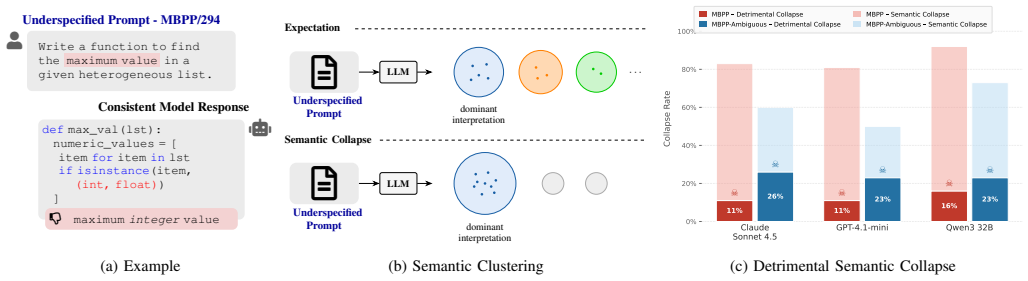
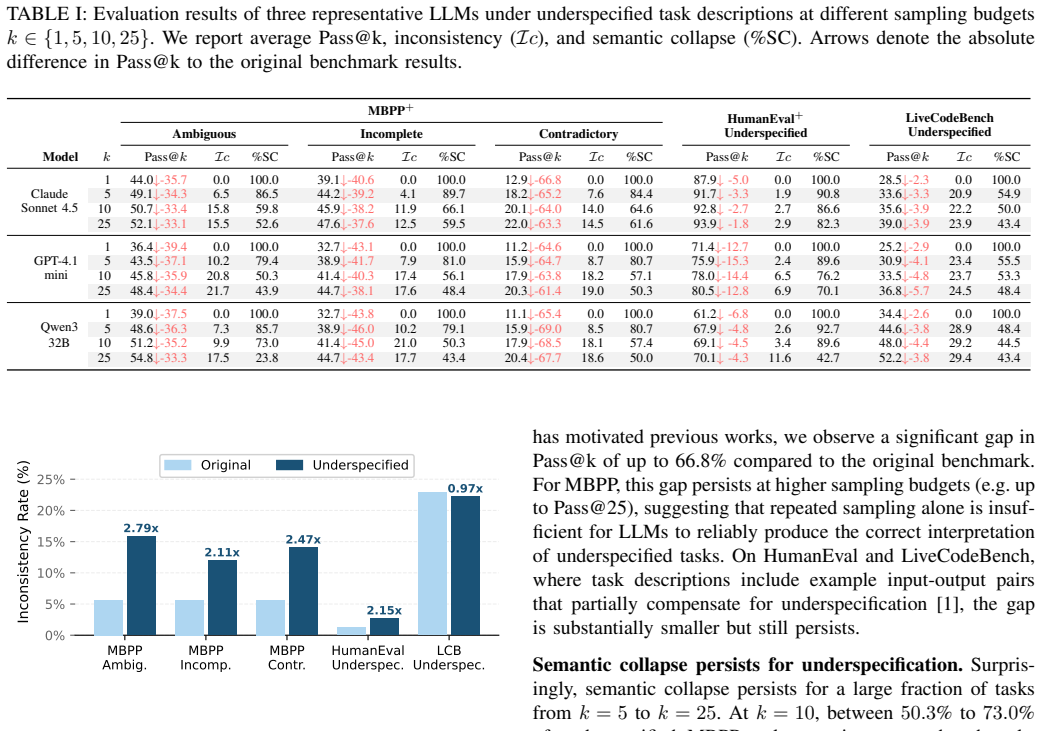
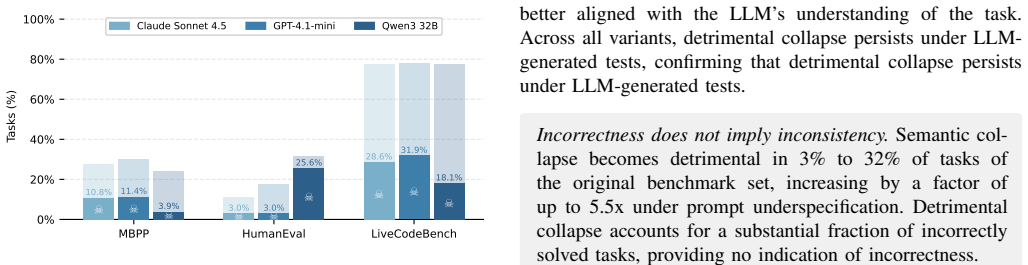
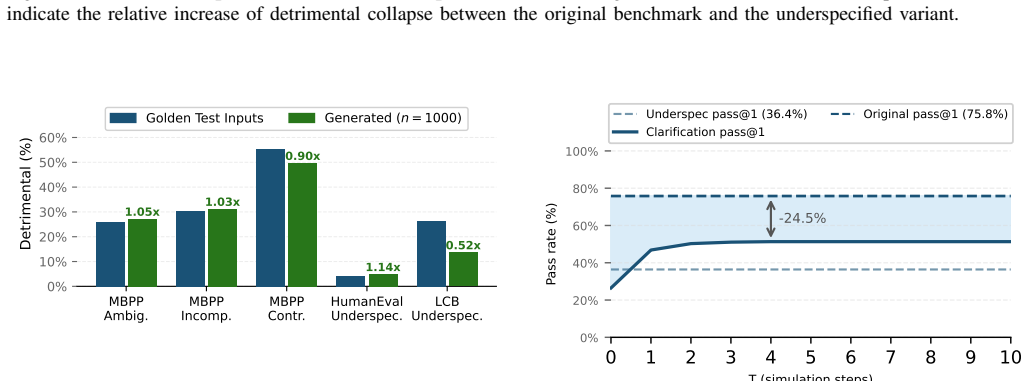
LLMs frequently collapse onto a single incorrect interpretation of the task description, consistently generating coherent but behaviorally misaligned code. We term this failure mode detrimental semantic collapse and find that it affects over 10% of tasks in MBPP, 3% in HumanEval, and 32% of LiveCodeBench, all benchmarks assumed to be well-specified. By deliberately injecting underspecification issues in the benchmark prompts, the rate rises to over 5 times, exposing a fundamental blind spot in disambiguation and correctness estimation techniques that rely on incoherence as a proxy for prompt underspecification.
What carries the argument
detrimental semantic collapse, where the model consistently selects and implements one incorrect interpretation of an underspecified prompt rather than producing varied outputs that reflect the ambiguity
If this is right
- Disambiguation techniques that rely on detecting incoherence in multiple model outputs will fail to catch many instances of underspecification.
- Correctness estimates for code generated from potentially ambiguous prompts may be inflated because the model does not reveal the ambiguity through variation.
- Existing benchmarks for code generation contain more underspecification than previously assumed, leading to hidden misalignment in reported performance.
- Methods for estimating model reliability based on output consistency need to account for this collapse behavior.
Where Pith is reading between the lines
- Real-world applications of coding assistants may produce unintended code behaviors without any signal of uncertainty from the model.
- New evaluation protocols could test for collapse by checking if models stick to one solution even when multiple interpretations are possible.
Load-bearing premise
The assumption that prompt underspecification will cause an LLM to produce multiple semantically distinct implementations when sampled multiple times.
What would settle it
If repeated sampling from the model on the identified tasks produces multiple distinct code implementations that align with different valid interpretations of the prompt, this would contradict the collapse finding.
Figures

read the original abstract
Large Language Models (LLMs) have become increasingly effective at generating code when task descriptions are clear and precise. Yet, in practice, user-provided task descriptions are often ambiguous, incomplete, or contradictory, leaving critical aspects of the intended program behavior underspecified. In such cases, multiple behaviorally distinct interpretations may satisfy the description equally well, yet semantically differ in ways that matter/affect the user intent. A natural expectation, often assumed by researchers, is that prompt underspecification manifests as incoherence: When asked multiple times, an LLM produces multiple semantically distinct implementations reflecting the ambiguity of the task description. In this paper, we challenge this assumption. We find that LLMs frequently collapse onto a single incorrect interpretation of the task description, consistently generating coherent but behaviorally misaligned code. We term this failure mode detrimental semantic collapse and find that it affects over 10% of tasks in MBPP, 3% in HumanEval, and 32% of LiveCodeBench, all benchmarks assumed to be well-specified. By deliberately injecting underspecification issues in the benchmark prompts, the rate rises to over 5 times, exposing a fundamental blind spot in disambiguation and correctness estimation techniques that rely on incoherence as a proxy for prompt underspecification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs do not respond to underspecified code-generation prompts by producing incoherent outputs (multiple semantically distinct implementations across samples), but instead exhibit 'detrimental semantic collapse': consistent generation of a single incorrect but coherent implementation. It reports this affects >10% of MBPP tasks, 3% of HumanEval, and 32% of LiveCodeBench (benchmarks presumed well-specified), with rates rising >5x after deliberate injection of underspecification, exposing limitations in incoherence-based disambiguation methods.
Significance. If the empirical distinction between semantic collapse and other consistent errors holds, the result identifies a previously under-appreciated failure mode that undermines variance-based proxies for prompt quality in code LLMs, with direct implications for correctness estimation and user-facing reliability.
major comments (2)
- [Abstract] Abstract: the central claim that observed consistent failures constitute 'collapse onto a single incorrect interpretation of the task description' requires evidence that the generated code implements one of the semantically valid readings licensed by the underspecified prompt; consistency plus benchmark failure alone does not establish this semantic grounding versus other systematic biases.
- [Abstract] Abstract: no information is provided on the number of samples drawn per task, the procedure used to distinguish detrimental semantic collapse from correct consistency or from non-semantic errors, or any statistical controls; these details are load-bearing for the reported rates and the injection experiment.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important points for clarification in the abstract. We address each major comment below and will make revisions to strengthen the presentation of our claims and methods.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that observed consistent failures constitute 'collapse onto a single incorrect interpretation of the task description' requires evidence that the generated code implements one of the semantically valid readings licensed by the underspecified prompt; consistency plus benchmark failure alone does not establish this semantic grounding versus other systematic biases.
Authors: We agree that consistency combined with benchmark failure is insufficient on its own to establish semantic grounding. The full manuscript includes qualitative analysis and examples demonstrating that the collapsed outputs align with specific, plausible misreadings of the underspecified prompts (e.g., default parameter assumptions or omitted constraints that are consistent with the prompt text but incorrect per the benchmark). To address the concern directly, we will add a new subsection with quantitative validation on a sample of tasks, enumerating alternative valid interpretations and showing alignment rates. revision: yes
-
Referee: [Abstract] Abstract: no information is provided on the number of samples drawn per task, the procedure used to distinguish detrimental semantic collapse from correct consistency or from non-semantic errors, or any statistical controls; these details are load-bearing for the reported rates and the injection experiment.
Authors: The full manuscript details the procedure (20 samples per task, collapse defined as ≥90% identical incorrect outputs distinct from the reference, with bootstrap CIs and controls for temperature and random seed). These were omitted from the abstract for brevity. We will revise the abstract to concisely include the sample count, collapse definition, and mention of statistical controls. revision: yes
Circularity Check
No circularity: purely empirical counts from benchmarks with no derivations or self-referential definitions
full rationale
The paper reports observed rates of consistent incorrect code generation on MBPP, HumanEval, and LiveCodeBench, plus increases after deliberate underspecification injection. These are direct empirical measurements against existing test suites. No equations, fitted parameters renamed as predictions, uniqueness theorems, or self-citation chains appear in the provided text. The central claim rests on observable output consistency and failure rates rather than any construction that reduces to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MBPP, HumanEval, and LiveCodeBench are assumed to be well-specified benchmarks.
invented entities (1)
-
detrimental semantic collapse
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Akli, M. Papadakis, M. Cordy, and Y . L. Traon, “When prompt under-specification improves code correctness: An exploratory study of prompt wording and structure effects on llm-based code generation,”CoRR, vol. abs/2604.24712, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2604.24712
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.24712 2026
-
[2]
Claude sonnet 4.5,
Anthropic, “Claude sonnet 4.5,” 2025, accessed: 2025. [Online]. Available: https://www.anthropic.com/news/claude-sonnet-4-5
2025
-
[4]
Program Synthesis with Large Language Models
[Online]. Available: https://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Codet: Code generation with generated tests,
B. Chen, F. Zhang, A. Nguyen, D. Zan, Z. Lin, J. Lou, and W. Chen, “Codet: Code generation with generated tests,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=ktrw68Cmu9c
2023
-
[6]
Divide-and-conquer meets consensus: Unleashing the power of func- tions in code generation,
J. Chen, H. Tang, Z. Chu, Q. Chen, Z. Wang, M. Liu, and B. Qin, “Divide-and-conquer meets consensus: Unleashing the power of func- tions in code generation,” inAdvances in Neural Information Processing Systems 37: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, A. Globersons, L....
2024
-
[7]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Oracle-guided program selection from large language models,
Z. Fan, H. Ruan, S. Mechtaev, and A. Roychoudhury, “Oracle-guided program selection from large language models,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, Vienna, Austria, September 16-20, 2024, M. Christakis and M. Pradel, Eds. ACM, 2024, pp. 628–640. [Online]. Available: https://doi.org/1...
-
[9]
Ambiguity in requirements engineering: Towards a unifying framework,
V . Gervasi, A. Ferrari, D. Zowghi, and P. Spoletini, “Ambiguity in requirements engineering: Towards a unifying framework,” inFrom Software Engineering to Formal Methods and Tools, and Back - Essays Dedicated to Stefania Gnesi on the Occasion of Her 65th Birthday, ser. Lecture Notes in Computer Science, M. H. ter Beek, A. Fantechi, and L. Semini, Eds., v...
-
[10]
Enhancing large language models in coding through multi-perspective self-consistency,
B. Huang, S. Lu, X. Wan, and N. Duan, “Enhancing large language models in coding through multi-perspective self-consistency,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, L. Ku, A. Martins, and V . Srikumar, Eds. Association for Computati...
-
[11]
Livecodebench: Holistic and contamination free evaluation of large language models for code,
N. Jain, K. Han, A. Gu, W. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica, “Livecodebench: Holistic and contamination free evaluation of large language models for code,” in The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. [Online]. Available: https://...
2025
-
[12]
Why ai agents still need you: Findings from developer-agent collaborations in the wild
H. Jia, R. Morris, H. Ye, F. Sarro, and S. Mechtaev, “Automated repair of ambiguous problem descriptions for llm-based code generation,” in40th IEEE/ACM International Conference on Automated Software Engineering, ASE 2025, Seoul, Korea, Republic of, November 16-20, 2025. IEEE, 2025, pp. 367–379. [Online]. Available: https://doi.org/10.1109/ASE63991.2025.00038
-
[13]
M. Larbi, A. Akli, M. Papadakis, R. Bouyousfi, M. Cordy, F. Sarro, and Y . L. Traon, “When prompts go wrong: Evaluating code model robustness to ambiguous, contradictory, and incomplete task descriptions,”CoRR, vol. abs/2507.20439, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2507.20439
-
[14]
Majority Voting for Code Generation
T. Launer, J. H ¨ubotter, M. Bagatella, I. Hakimi, and A. Krause, “Majority voting for code generation,”CoRR, vol. abs/2604.15618,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Majority Voting for Code Generation
[Online]. Available: https://doi.org/10.48550/arXiv.2604.15618
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.15618
-
[16]
DOCE: finding the sweet spot for execution-based code generation,
H. Li, P. Fernandes, I. Gurevych, and A. F. T. Martins, “DOCE: finding the sweet spot for execution-based code generation,”CoRR, vol. abs/2408.13745, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2408.13745
-
[17]
Competition-Level Code Generation with AlphaCode
Y . Li, D. H. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. D. Lago, T. Hubert, P. Choy, C. de Masson d’Autume, I. Babuschkin, X. Chen, P. Huang, J. Welbl, S. Gowal, A. Cherepanov, J. Molloy, D. J. Mankowitz, E. S. Robson, P. Kohli, N. de Freitas, K. Kavukcuoglu, and O. Vinyals, “Competition- level code gen...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Competition-Level Code Generation with AlphaCode
[Online]. Available: https://doi.org/10.48550/arXiv.2203.07814
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.07814
-
[19]
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,
J. Liu, C. S. Xia, Y . Wang, and L. Zhang, “Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,” inAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, A. Oh, T. Nauma...
2023
-
[20]
Easy approach to requirements syntax (EARS),
A. Mavin, P. Wilkinson, A. R. G. Harwood, and M. Novak, “Easy approach to requirements syntax (EARS),” inRE 2009, 17th IEEE International Requirements Engineering Conference, Atlanta, Georgia, USA, August 31 - September 4, 2009. IEEE Computer Society, 2009, pp. 317–322. [Online]. Available: https://doi.org/10.1109/RE.2009.9
-
[21]
Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification,
F. Mu, L. Shi, S. Wang, Z. Yu, B. Zhang, C. Wang, S. Liu, and Q. Wang, “Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification,”Proc. ACM Softw. Eng., vol. 1, no. FSE, pp. 2332–2354, 2024. [Online]. Available: https://doi.org/10.1145/3660810
-
[22]
OpenAI, “GPT-4 technical report,”CoRR, vol. abs/2303.08774, 2023. [Online]. Available: https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Eliminating hallucination- induced errors in LLM code generation with functional clustering,
C. Ravuri and S. Amarasinghe, “Eliminating hallucination- induced errors in LLM code generation with functional clustering,”CoRR, vol. abs/2506.11021, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2506.11021
-
[24]
Assessing correctness in llm-based code generation via uncertainty estimation,
A. Sharma and C. David, “Assessing correctness in llm-based code generation via uncertainty estimation,”CoRR, vol. abs/2502.11620,
-
[25]
Assessing correctness in llm-based code generation via uncertainty estimation,
[Online]. Available: https://doi.org/10.48550/arXiv.2502.11620
-
[26]
Natural language to code translation with execution,
F. Shi, D. Fried, M. Ghazvininejad, L. Zettlemoyer, and S. I. Wang, “Natural language to code translation with execution,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Y . Goldberg, Z. Kozareva, and Y . Zhang, Eds. Association for Computational ...
-
[27]
Q. Team, “Qwen3 technical report,”CoRR, vol. abs/2505.09388, 2025. [Online]. Available: https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Functional overlap reranking for neural code generation,
H. To, M. Nguyen, and N. Bui, “Functional overlap reranking for neural code generation,” inFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, ser. Findings of ACL, L. Ku, A. Martins, and V . Srikumar, Eds., vol. ACL 2024. Association for Computational Linguistics, 2024, pp. 3686–...
-
[29]
Incoherence as oracle-less measure of error in llm-based code generation,
T. J. Valentin, A. Madadi, G. Sapia, and M. B ¨ohme, “Incoherence as oracle-less measure of error in llm-based code generation,” inFortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Artificial Intelligence, Sixteenth Symposium on Educational Advances in Artificial Intelligence, AAAI 2026, Singapore,...
-
[30]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=1PL1NIMMrw
2023
-
[31]
Clarifycoder: Clarification-aware fine-tuning for programmatic problem solving,
J. J. Wu, M. Chaudhary, D. Abrahamyan, A. Khaku, A. Wei, and F. H. Fard, “Clarifycoder: Clarification-aware fine-tuning for programmatic problem solving,”CoRR, vol. abs/2504.16331, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2504.16331
-
[32]
Self-improving code generation via semantic entropy and behavioral consen- sus,
H. Zhang, W. Cheng, and W. Hu, “Self-improving code generation via semantic entropy and behavioral consen- sus,”CoRR, vol. abs/2603.29292, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2603.29292
-
[33]
Towards an understanding of large language models in software engineering tasks,
Z. Zheng, K. Ning, Q. Zhong, J. Chen, W. Chen, L. Guo, W. Wang, and Y . Wang, “Towards an understanding of large language models in software engineering tasks,”Empir. Softw. Eng., vol. 30, no. 2, p. 50,
-
[34]
Available: https://doi.org/10.1007/s10664-024-10602-0
[Online]. Available: https://doi.org/10.1007/s10664-024-10602-0
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.