MoRe: Modular Representations for Principled Continual Representation Learning on Sequential Data
Pith reviewed 2026-05-21 07:39 UTC · model grok-4.3
The pith
MoRe decomposes representations of sequential data into an identifiable hierarchy of fundamental and specific modules to support continual adaptation without forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MoRe decomposes knowledge into a hierarchy of fundamental and specific modules with identifiability guarantees. The decomposition is recovered from time-delayed dependencies in sequential data rather than from task boundaries. This structure permits principled module reuse, alignment, and expansion during adaptation while preserving old modules by construction. Experiments on synthetic benchmarks and real-world LLM activations confirm that the recovered hierarchy is interpretable and improves the plasticity-stability trade-off.
What carries the argument
Hierarchy of fundamental and specific modules recovered from time-delayed dependencies, equipped with identifiability guarantees.
Load-bearing premise
Time-delayed dependencies in sequential data naturally reveal an intrinsic modular organization of representations that can be identified with guarantees and used for selective updates without task-specific supervision.
What would settle it
A sequential dataset in which time-delayed dependencies produce no identifiable hierarchical modules, or in which following the module-update rules still produces measurable interference with previously learned representations.
Figures







read the original abstract
Continual learning requires models to adapt to new data while preserving previously acquired knowledge. At its core, this challenge can be viewed as principled one-step adaptation: incorporating new information with minimal interference to existing representations. Most existing approaches address this challenge by modifying model parameters or architectures in a supervised, task-specific manner. However, the underlying issue is representational: tasks require distinct yet structured representations that can be selectively updated without disrupting representations, while structure should reflect intrinsic organization in the data rather than task boundaries. In sequential data, time-delayed dependencies provide a natural signal for uncovering this organization, revealing how fundamental representations give rise to more specific ones. Inspired by the modular organization of the human brain, we propose MoRe, a framework that identifies modularity in the representation itself rather than allocating it at the architectural level. MoRe decomposes knowledge into a hierarchy of fundamental and specific modules with identifiability guarantees, enabling principled module reuse, alignment, and expansion during adaptation while preserving old modules by construction. Experiments on synthetic benchmarks and real-world LLM activations demonstrate interpretable hierarchical structure, improved plasticity-stability trade-offs, suggesting MoRe as a principled foundation for continual adaptation
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MoRe, a framework for continual representation learning on sequential data. It decomposes representations into a hierarchy of fundamental and specific modules identified via time-delayed dependencies, claiming formal identifiability guarantees that enable principled reuse, alignment, and expansion of modules during adaptation while preserving prior modules by construction. Experiments on synthetic benchmarks and LLM activations are said to show interpretable hierarchical structure and improved plasticity-stability trade-offs compared to existing approaches.
Significance. If the identifiability guarantees can be rigorously established under clearly stated conditions that hold for general sequential data, the work would provide a valuable representational foundation for continual learning that avoids task-specific supervision and architectural modifications. The emphasis on intrinsic data organization rather than task boundaries, combined with evaluation on real LLM activations, strengthens its potential relevance. However, the absence of explicit assumptions or derivations in the framing leaves the central contribution dependent on unverified conditions.
major comments (2)
- [§3] §3 (Theoretical Framework), identifiability claim: The assertion that time-delayed dependencies suffice to identify a unique hierarchy of fundamental and specific modules with guarantees is load-bearing for the 'principled' and 'by construction' aspects of the central claim, yet the manuscript provides no explicit statement of required conditions (e.g., source independence, non-Gaussianity, or sufficient variability in the mixing process) nor a derivation contrasting with standard results from temporal ICA or nonlinear ICA. This leaves open whether the guarantees are non-circular or reduce to modeling choices.
- [Experiments] Experiments section, real-world LLM activations: The reported improvements in plasticity-stability trade-offs are presented without controls or analysis for cases where activations exhibit entangled or non-stationary mixing that would violate the time-delayed dependency assumptions needed for identifiability. If these conditions do not hold, the empirical results do not substantiate the formal guarantees and undermine the claim of principled adaptation.
minor comments (2)
- [Abstract] Abstract: The final sentence is a run-on that combines multiple claims; splitting it would improve readability.
- [Introduction] Notation: The distinction between 'fundamental' and 'specific' modules is introduced without a clear mathematical definition or diagram in the early sections, making it difficult to follow the hierarchy construction.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We agree that clarifying the theoretical assumptions and providing robustness checks for the empirical results will strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§3] §3 (Theoretical Framework), identifiability claim: The assertion that time-delayed dependencies suffice to identify a unique hierarchy of fundamental and specific modules with guarantees is load-bearing for the 'principled' and 'by construction' aspects of the central claim, yet the manuscript provides no explicit statement of required conditions (e.g., source independence, non-Gaussianity, or sufficient variability in the mixing process) nor a derivation contrasting with standard results from temporal ICA or nonlinear ICA. This leaves open whether the guarantees are non-circular or reduce to modeling choices.
Authors: We appreciate this observation and agree that the identifiability result requires a more explicit foundation. In the revised manuscript we will expand §3 with a new subsection that (i) states the precise assumptions, including statistical independence of the fundamental modules, non-Gaussianity of the sources where needed, and sufficient temporal variability in the mixing process; (ii) provides a concise derivation that starts from the time-delayed dependency structure and shows how it yields a unique hierarchical factorization; and (iii) contrasts the approach with standard temporal ICA and nonlinear ICA results to demonstrate that the guarantees arise from the hierarchical organization induced by sequential dependencies rather than from modeling choices alone. This addition will make the non-circular nature of the argument transparent. revision: yes
-
Referee: [Experiments] Experiments section, real-world LLM activations: The reported improvements in plasticity-stability trade-offs are presented without controls or analysis for cases where activations exhibit entangled or non-stationary mixing that would violate the time-delayed dependency assumptions needed for identifiability. If these conditions do not hold, the empirical results do not substantiate the formal guarantees and undermine the claim of principled adaptation.
Authors: We concur that empirical validation must address potential violations of the identifiability assumptions. We will augment the Experiments section with (i) additional synthetic benchmarks that systematically vary the degree of entanglement and non-stationarity while measuring module recovery and plasticity-stability metrics; (ii) a diagnostic analysis of the LLM activation sequences (e.g., lagged cross-correlation statistics and stationarity tests) to quantify how well the time-delayed dependency assumption holds; and (iii) a limitations paragraph discussing performance degradation when the assumptions are only partially satisfied. These additions will clarify the scope of the formal guarantees and provide readers with a clearer picture of when the principled adaptation claim applies. revision: yes
Circularity Check
No significant circularity; derivation introduces new modular hierarchy without reducing to fitted inputs or self-citations by construction.
full rationale
The abstract frames MoRe as identifying a hierarchy of fundamental and specific modules from time-delayed dependencies in sequential data, with identifiability guarantees enabling reuse and preservation by construction. No equations, fitted parameters renamed as predictions, or load-bearing self-citations are visible in the provided text that would make the guarantees equivalent to modeling choices or prior author results. The approach appears self-contained as a proposed framework rather than a tautological renaming or fit. External benchmarks on synthetic and LLM data are referenced without indication that core claims collapse to inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Time-delayed dependencies provide a natural signal for uncovering intrinsic modular organization in sequential data.
- ad hoc to paper Modular decomposition admits identifiability guarantees that allow preservation of old modules by construction.
invented entities (1)
-
Fundamental and specific modules
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
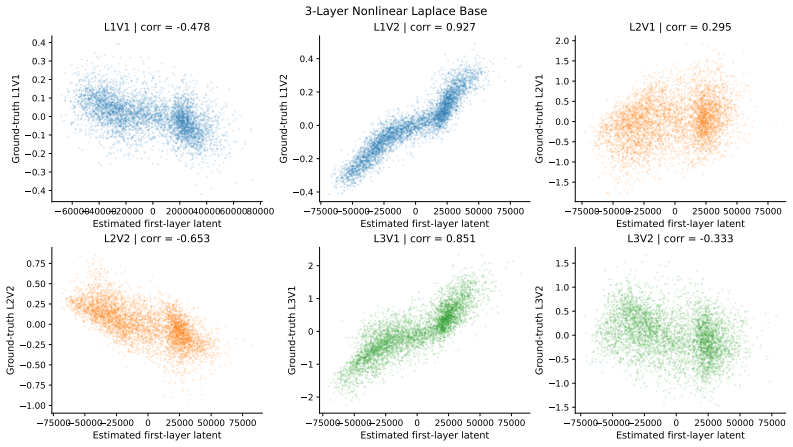
Theorem 1 (Identifiability of Latent Variables)... any mixture among Z can only happen within the same layer... under C3, Z are component-wise identifiable.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2 (Identifiability of Hierarchical Order)... any estimated hierarchical order... must be compatible with the true layer-level time-delayed graph.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
R. Aljundi, F. Babiloni, M. Elhoseiny, M. Rohrbach, and T. Tuytelaars. Memory aware synapses: Learning what (not) to forget. InProceedings of the European conference on computer vision (ECCV), pages 139–154, 2018
work page 2018
-
[2]
R. Aljundi, P. Chakravarty, and T. Tuytelaars. Expert gate: Lifelong learning with a network of experts. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3366–3375, 2017
work page 2017
-
[3]
S. Biderman, H. Schoelkopf, Q. G. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. InInternational conference on machine learning, pages 2397–2430. PMLR, 2023
work page 2023
-
[4]
W. Chen, Y . Zhou, N. Du, Y . Huang, J. Laudon, Z. Chen, and C. Cui. Lifelong language pretraining with distribution-specialized experts. InInternational Conference on Machine Learning, pages 5383–5395. PMLR, 2023
work page 2023
-
[5]
PathNet: Evolution Channels Gradient Descent in Super Neural Networks
C. Fernando, D. Banarse, C. Blundell, Y . Zwols, D. Ha, A. A. Rusu, A. Pritzel, and D. Wier- stra. Pathnet: Evolution channels gradient descent in super neural networks.arXiv preprint arXiv:1701.08734, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
E. Fini, V . G. T. Da Costa, X. Alameda-Pineda, E. Ricci, K. Alahari, and J. Mairal. Self- supervised models are continual learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9621–9630, 2022
work page 2022
-
[7]
A. Gomez-Villa, B. Twardowski, L. Yu, A. D. Bagdanov, and J. Van de Weijer. Continually learning self-supervised representations with projected functional regularization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3867–3877, 2022
work page 2022
-
[8]
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. At- tariyan, and S. Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
work page 2019
- [9]
-
[10]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[11]
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
work page 2017
- [12]
- [13]
-
[14]
Z. Li, Y . Shen, K. Zheng, R. Cai, X. Song, M. Gong, G. Chen, and K. Zhang. On the identi- fication of temporal causal representation with instantaneous dependence. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[15]
Y .-S. Liang and W.-J. Li. Inflora: Interference-free low-rank adaptation for continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23638–23647, 2024
work page 2024
-
[16]
W. Liu, F. Zhu, and C.-L. Liu. Branch-tuning: balancing stability and plasticity for continual self-supervised learning.IEEE Transactions on Neural Networks and Learning Systems, 2025. 10
work page 2025
-
[17]
Learning Sparse Neural Networks through $L_0$ Regularization
C. Louizos, M. Welling, and D. P. Kingma. Learning sparse neural networks through l_0 regularization.arXiv preprint arXiv:1712.01312, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [18]
-
[19]
A. Mallya and S. Lazebnik. Packnet: Adding multiple tasks to a single network by iterative pruning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 7765–7773, 2018
work page 2018
-
[20]
Modular deep learning.arXiv preprint arXiv:2302.11529, 2023
J. Pfeiffer, S. Ruder, I. Vuli ´c, and E. M. Ponti. Modular deep learning.arXiv preprint arXiv:2302.11529, 2023
-
[21]
E. M. Ponti, A. Sordoni, Y . Bengio, and S. Reddy. Combining parameter-efficient modules for task-level generalisation. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 687–702, 2023
work page 2023
-
[22]
D. Rao, F. Visin, A. Rusu, R. Pascanu, Y . W. Teh, and R. Hadsell. Continual unsupervised representation learning.Advances in neural information processing systems, 32, 2019
work page 2019
-
[23]
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
work page 2001
-
[24]
A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu, and R. Hadsell. Progressive neural networks.arXiv preprint arXiv:1606.04671, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [25]
-
[26]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean. Outra- geously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
J. S. Smith, L. Karlinsky, V . Gutta, P. Cascante-Bonilla, D. Kim, A. Arbelle, R. Panda, R. Feris, and Z. Kira. Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11909–11919, 2023
work page 2023
-
[28]
X. Song, J. Sun, Z. Li, Y . Zheng, and K. Zhang. LLM interpretability with identifiable temporal- instantaneous representation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[29]
S. Tafazoli, F. M. Bouchacourt, A. Ardalan, N. T. Markov, M. Uchimura, M. G. Mattar, N. D. Daw, and T. J. Buschman. Building compositional tasks with shared neural subspaces.Nature, 650(8100):164–172, 2026
work page 2026
-
[30]
C. I. Tang, L. Qendro, D. Spathis, F. Kawsar, C. Mascolo, and A. Mathur. Kaizen: Practical self-supervised continual learning with continual fine-tuning. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2841–2850, 2024
work page 2024
-
[31]
G. Team, T. Mesnard, C. Hardin, R. Dadashi, S. Bhupatiraju, S. Pathak, L. Sifre, M. Rivière, M. S. Kale, J. Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
K. Tian, Z. Zhao, Y . Chen, N. Ge, S. Cao, X. Han, J. Gu, and S. Yu. Domain-specific schema reuse supports flexible learning to learn in the primate brain.Nature Communications, 2026
work page 2026
- [33]
-
[34]
L. Wang, X. Zhang, H. Su, and J. Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE transactions on pattern analysis and machine intelligence, 46(8):5362–5383, 2024
work page 2024
-
[35]
X. Wang, T. Chen, Q. Ge, H. Xia, R. Bao, R. Zheng, Q. Zhang, T. Gui, and X.-J. Huang. Orthogonal subspace learning for language model continual learning. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10658–10671, 2023
work page 2023
-
[36]
Z. Wang, Z. Zhang, S. Ebrahimi, R. Sun, H. Zhang, C.-Y . Lee, X. Ren, G. Su, V . Perot, J. Dy, et al. Dualprompt: Complementary prompting for rehearsal-free continual learning. InEuropean conference on computer vision, pages 631–648. Springer, 2022
work page 2022
-
[37]
Z. Wang, Z. Zhang, C.-Y . Lee, H. Zhang, R. Sun, X. Ren, G. Su, V . Perot, J. Dy, and T. Pfister. Learning to prompt for continual learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 139–149, 2022
work page 2022
-
[38]
W. Yao, G. Chen, and K. Zhang. Temporally disentangled representation learning.Advances in Neural Information Processing Systems, 35:26492–26503, 2022
work page 2022
-
[39]
J. Yu, Y . Zhuge, L. Zhang, P. Hu, D. Wang, H. Lu, and Y . He. Boosting continual learning of vision-language models via mixture-of-experts adapters. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23219–23230, 2024
work page 2024
-
[40]
Causal representation learning from multiple distributions: A general setting
K. Zhang, S. Xie, I. Ng, and Y . Zheng. Causal representation learning from multiple distributions: A general setting.arXiv preprint arXiv:2402.05052, 2024. 12 Appendices for“MoRe: Modular Representations for Principled Continual Learning on LLMs” Appendices Contents A Definitions and Proofs 13 A.1 Definitions . . . . . . . . . . . . . . . . . . . . . . ....
-
[41]
Second, with the density estimators fixed, we update fi using Eq. (25). In practice, we warm up the encoder with Lpred +L rec before enabling the CMI penalty. This warm-up prevents early density-estimation noise from collapsing the representation. After warm-up, the prediction loss can be hinge-thresholded at the warm-up value so that the CMI term shapes ...
work page 2048
-
[42]
expands and freezes distribution-specialized experts and gating dimensions for continual language pre-training, while MoE-Adapters [39] attach task-specific adapter experts to a frozen vision-language backbone with a distribution-discriminative auto-selector. With large pre-trained models, parameter- efficient fine-tuning (PEFT) methods adapt only small t...
-
[43]
reparameterizes pre-trained weights through an interference-eliminating subspace. Prompt-based continual learning extends the PEFT idea by learning small prompt memories or complementary prompts to manage task-specific and task-invariant knowledge without replay [37, 36, 27]. Despite their empirical strengths, these supervised CL methods predominantly tre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.