Natural Identifiers for Privacy and Data Audits in Large Language Models
Pith reviewed 2026-06-26 00:14 UTC · model grok-4.3
The pith
Natural identifiers in training data let auditors check LLM privacy and data use after training ends.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Natural identifiers are structured random strings that occur naturally in common LLM training datasets; their format allows unlimited generation of additional strings from the same distribution, which can replace specially inserted canaries for post-hoc differential privacy auditing and replace private non-member hold-out sets for dataset inference on any suspect collection that contains NIDs.
What carries the argument
Natural identifiers (NIDs): structured random strings naturally occurring in LLM training data whose format supports generating unlimited additional examples from the same distribution to serve as canaries or hold-outs.
If this is right
- Differential privacy audits can be performed on already-trained models without any retraining or canary insertion.
- Dataset inference becomes possible for any suspect dataset that contains NIDs without needing a private non-member hold-out set.
- Audits scale to real-world cases where held-out data from the identical distribution is unavailable or impractical to construct.
- Privacy verification no longer requires advance planning or modification of the training process.
Where Pith is reading between the lines
- Organizations could routinely scan public training corpora for NIDs before model release to prepare for future audits.
- The same generation trick might extend to other data types if analogous structured random elements exist in non-text modalities.
- Regulators might accept NID-based evidence as a lighter-weight alternative to full membership inference attacks in compliance reviews.
Load-bearing premise
NIDs appear naturally in common LLM training datasets at high enough density, and newly generated strings from the same format closely match the distribution of the original training data for auditing to work reliably.
What would settle it
A standard LLM training corpus is examined and found to contain zero or near-zero NIDs, or generated NIDs fail to produce statistically distinguishable audit signals between member and non-member examples.
Figures

read the original abstract
Assessing the privacy of large language models (LLMs) presents significant challenges. In particular, most existing methods for auditing differential privacy require the insertion of specially crafted canary data during training, making them impractical for auditing already-trained models without costly retraining. Additionally, dataset inference, which audits whether a suspect dataset was used to train a model, is infeasible without access to a private non-member held-out dataset. Yet, such held-out datasets are often unavailable or difficult to construct for real-world cases since they have to be from the same distribution (IID) as the suspect data. These limitations severely hinder the ability to conduct scalable, post-hoc audits. To enable such audits, this work introduces natural identifiers (NIDs) as a novel solution to the above-mentioned challenges. NIDs are structured random strings, such as cryptographic hashes and shortened URLs, naturally occurring in common LLM training datasets. Their format enables the generation of unlimited additional random strings from the same distribution, which can act as alternative canaries for audits and as same-distribution held-out data for dataset inference. Our evaluation highlights that indeed, using NIDs, we can facilitate post-hoc differential privacy auditing without any retraining and enable dataset inference for any suspect dataset containing NIDs without the need for a private non-member held-out dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes natural identifiers (NIDs)—structured random strings such as cryptographic hashes and shortened URLs that occur naturally in common LLM training corpora—as a mechanism for post-hoc differential privacy auditing of already-trained models without canary insertion or retraining, and for dataset inference on suspect datasets without requiring a private IID non-member held-out set. Additional strings are generated from the same syntactic formats to serve as canaries or same-distribution proxies.
Significance. If the distributional equivalence between real and synthetically generated NIDs can be established, the approach would remove two major practical barriers to auditing deployed LLMs, enabling scalable post-hoc privacy checks that current canary-based and held-out-set methods cannot support.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: the claim that 'evaluation highlights' effectiveness is unsupported because no quantitative results, error analysis, membership-inference AUC values, or experimental controls are reported, leaving the central empirical claims unverified.
- [Method and Evaluation] Method and Evaluation sections: the load-bearing assumption that strings generated from NID syntactic formats (e.g., hash regexes) are statistically interchangeable with real NIDs appearing in training corpora is not tested; no distributional-distance metrics (n-gram overlap, embedding statistics, or AUC gap between real and synthetic baselines) are provided, which directly affects validity of both the DP-auditing and dataset-inference claims.
minor comments (1)
- [Abstract] Abstract: the phrasing 'Our evaluation highlights that indeed' is informal and should be replaced with a direct statement of what was measured.
Simulated Author's Rebuttal
We thank the referee for these detailed comments on the empirical support for our claims. We agree that the current version of the manuscript does not provide sufficient quantitative evidence or distributional validation, and we will revise the Evaluation section to address both points directly.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: the claim that 'evaluation highlights' effectiveness is unsupported because no quantitative results, error analysis, membership-inference AUC values, or experimental controls are reported, leaving the central empirical claims unverified.
Authors: We accept this criticism. The manuscript currently states that the evaluation 'highlights' effectiveness without reporting the supporting numbers. In the revised version we will add membership-inference AUC values, error analysis, and explicit experimental controls (including baseline comparisons) for both the DP-auditing and dataset-inference tasks so that the empirical claims are verifiable. revision: yes
-
Referee: [Method and Evaluation] Method and Evaluation sections: the load-bearing assumption that strings generated from NID syntactic formats (e.g., hash regexes) are statistically interchangeable with real NIDs appearing in training corpora is not tested; no distributional-distance metrics (n-gram overlap, embedding statistics, or AUC gap between real and synthetic baselines) are provided, which directly affects validity of both the DP-auditing and dataset-inference claims.
Authors: We agree that the interchangeability assumption is central and currently untested. The revision will include explicit distributional comparisons: n-gram overlap statistics, embedding-space distances, and AUC gaps between real NIDs extracted from training corpora and the synthetically generated strings. These metrics will be reported for both the canary-based DP audit and the dataset-inference setting. revision: yes
Circularity Check
No circularity: method relies on empirical properties of NIDs rather than self-referential derivation or fitted predictions
full rationale
The paper introduces natural identifiers (NIDs) as an observed property of training corpora and proposes their use for post-hoc auditing via synthetic generation from the same syntactic format. No equations, parameter fitting, or derivation chain are described in the provided text that would reduce a claimed result to its own inputs by construction. The central claims rest on the premise that NIDs occur naturally and that format-matched strings can serve as proxies, which is presented as an empirical assumption rather than a mathematically derived necessity. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are evident. This is a standard non-finding for a proposal paper without internal predictive modeling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep learning with differential privacy
Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC conference on computer and communications security, pp. 308–318,
2016
-
[2]
Membership inference attacks from first principles
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership inference attacks from first principles. In2022 IEEE Symposium on Security and Privacy (SP), pp. 1897–1914. IEEE,
1914
-
[3]
Hongyan Chang, Ali Shahin Shamsabadi, Kleomenis Katevas, Hamed Haddadi, and Reza Shokri. Context-aware membership inference attacks against pre-trained large language models.arXiv preprint arXiv:2409.13745,
-
[4]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
-
[5]
11 Published as a conference paper at ICLR 2026 Debeshee Das, Jie Zhang, and Florian Tramèr. Blind baselines beat membership inference attacks for foundation models.arXiv preprint arXiv:2406.16201,
arXiv 2026
-
[6]
Calibrating noise to sensitivity in private data analysis
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in private data analysis. InTheory of Cryptography: Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, March 4-7,
2006
-
[7]
The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027,
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027,
-
[8]
A Survey on In-context Learning
Association for Computational Linguistics. doi: 10.18653/v1/ 2024.acl-long.841. URLhttps://aclanthology.org/2024.acl-long.841/. Vincent Hanke, Tom Blanchard, Franziska Boenisch, Iyiola Emmanuel Olatunji, Michael Backes, and Adam Dziedzic. Open llms are necessary for current private adaptations and outperform their closed alternatives. InThirty-Eighth Conf...
-
[9]
Robert Hönig, Javier Rando, Nicholas Carlini, and Florian Tramèr. Adversarial perturbations cannot reliably protect artists from generative ai.arXiv preprint arXiv:2406.12027,
-
[10]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186,
-
[11]
PANORAMIA: Privacy auditing of machine learning models without retraining
12 Published as a conference paper at ICLR 2026 Mishaal Kazmi, Hadrien Lautraite, Alireza Akbari, Qiaoyue Tang, Mauricio Soroco, Tao Wang, Sébastien Gambs, and Mathias Lécuyer. PANORAMIA: Privacy auditing of machine learning models without retraining. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
2026
-
[12]
Najoung Kim, Sebastian Schuster, and Shubham Toshniwal
URLhttps://openreview.net/forum?id=5atraF1tbg. Najoung Kim, Sebastian Schuster, and Shubham Toshniwal. Code pretraining improves entity tracking abilities of language models.arXiv preprint arXiv:2405.21068,
-
[13]
Terrance Liu, Matteo Boglioni, Yiwei Fu, Shengyuan Hu, Pratiksha Thaker, and Zhiwei Steven Wu. Enhancing one-run privacy auditing with quantile regression-based membership inference.arXiv preprint arXiv:2506.15349,
-
[14]
Dataset inference: Ownership resolution in machine learning.arXiv preprint arXiv:2104.10706,
Pratyush Maini, Mohammad Yaghini, and Nicolas Papernot. Dataset inference: Ownership resolution in machine learning.arXiv preprint arXiv:2104.10706,
-
[15]
Justus Mattern, Fatemehsadat Mireshghallah, Zhijing Jin, Bernhard Schoelkopf, Mrinmaya Sachan, and Taylor Berg-Kirkpatrick
URL https://openreview.net/forum?id=jY7fAo9rfK. Justus Mattern, Fatemehsadat Mireshghallah, Zhijing Jin, Bernhard Schoelkopf, Mrinmaya Sachan, and Taylor Berg-Kirkpatrick. Membership inference attacks against language models via neigh- bourhood comparison. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.),Findings of the Association for Comput...
2023
-
[16]
Membership Inference Attacks against Language Models via Neighbourhood Comparison
Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.719. URLhttps://aclanthology.org/2023.findings-acl.719. Milad Nasr, Jamie Hayes, Thomas Steinke, Borja Balle, Florian Tramèr, Matthew Jagielski, Nicholas Carlini, and Andreas Terzis. Tight auditing of differentially private machine learning. In32nd USENIX Security Symposium (USE...
-
[17]
URLhttps://openreview.net/forum?id=pxxmUKKgel
ISSN 2835-8856. URLhttps://openreview.net/forum?id=pxxmUKKgel. Evani Radiya-Dixit, Sanghyun Hong, Nicholas Carlini, and Florian Tramer. Data poisoning won’t save you from facial recognition. InInternational Conference on Learning Representations. Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu...
-
[18]
net/forum?id=zWqr3MQuNs
URL https://openreview. net/forum?id=zWqr3MQuNs. 13 Published as a conference paper at ICLR 2026 R. Shokri, M. Stronati, C. Song, and V . Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE Symposium on Security and Privacy (SP), pp. 3–18, Los Alamitos, CA, USA, may
2026
-
[19]
Membership inference attacks against machine learning models
IEEE Computer Society. doi: 10.1109/SP.2017.41. URL https://doi. ieeecomputersociety.org/10.1109/SP.2017.41. Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Harsh Jha, Sachin Kumar, Li Lucy, Xinxi Lyu, Nathan Lambert, Ian Magnuss...
-
[20]
Florian Tramer, Andreas Terzis, Thomas Steinke, Shuang Song, Matthew Jagielski, and Nicholas Carlini
URL https: //openreview.net/forum?id=f38EY21lBw. Florian Tramer, Andreas Terzis, Thomas Steinke, Shuang Song, Matthew Jagielski, and Nicholas Carlini. Debugging differential privacy: A case study for privacy auditing.arXiv preprint arXiv:2202.12219,
-
[21]
Anqi Zhang and Chaofeng Wu. Adaptive pre-training data detection for large language models via surprising tokens.arXiv preprint arXiv:2407.21248,
-
[22]
Jie Zhang, Debeshee Das, Gautam Kamath, and Florian Tramèr. Membership inference attacks cannot prove that a model was trained on your data.arXiv preprint arXiv:2409.19798, 2024a. Jingyang Zhang, Jingwei Sun, Eric Yeats, Yang Ouyang, Martin Kuo, Jianyi Zhang, Hao Frank Yang, and Hai Li. Min-k%++: Improved baseline for detecting pre-training data from larg...
-
[23]
A STRUCTURE OFNIDS ANDGIDS To extract the MIA signal, we use NIDs and their corresponding GIDs together with the surrounding textual context
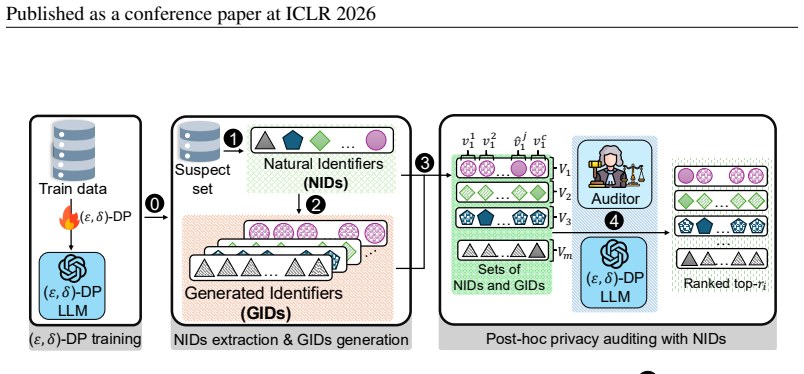
URLhttps://openreview.net/forum?id=a5Kgv47d2e. A STRUCTURE OFNIDS ANDGIDS To extract the MIA signal, we use NIDs and their corresponding GIDs together with the surrounding textual context. Examples are provided in Appendix B. For each NID and its context, we generate a GID by replacing the NID with a randomly generated string that matches the original for...
2024
-
[24]
0123456789
has shown that longer input sequences can improve attack effectiveness. 14 Published as a conference paper at ICLR 2026 B EXAMPLES OFNIDS ANDGIDS In this section, we show a series of examples to represent common appearances of the NIDs. We bold the parts that differ between the NIDs and GIDs. As shown in these examples, to create a new held-out sample, we...
2026
-
[25]
(2023)] Let X, Y∈R be ran- dom variables
Definition 1 (Stochastic Dominance) [Definition 4.8, Steinke et al. (2023)] Let X, Y∈R be ran- dom variables. We say X is stochastically dominated by Y if P[X > t]≤P[Y > t] for all t∈R. Lemma 1 [Lemma 4.9, Steinke et al. (2023)] SupposeX1 is stochastically dominated byY1. Suppose that, for all x∈R , the conditional distributionX2|X1 =x is stochastically d...
2023
-
[26]
Proof:Our analysis is similar to Proposition 5.1 by Steinke et al. (2023). Fix some t∈Σ 1 × · · · ×Σ m, and i∈ {1, . . . , m} , a∈V i, and s<i ∈V 1 × · · · ×V i. Using Bayes’ 17 Published as a conference paper at ICLR 2026 Table 6:Natural Identifiers in Different Datasets.We present the number of variousnatural identifiers(here: SHA-1, MD5, SHA-256, Java ...
2023
-
[27]
(2023)] Let P and Q be probability distributions over Y
Lemma 2 [Lemma 5.6, Steinke et al. (2023)] Let P and Q be probability distributions over Y. Fix ε, δ≥0. Suppose that, for all measurableS⊆ Y, we have P(S)≤e ε ·Q(S) +δandQ(S)≤e ε ·P(S) +δ. Then there exists a randomized functionE P,Q :Y → {0,1}with the following properties. Fix p∈[0,1] and suppose X∼Bernoulli(p) . If X= 1 , sample Y∼P ; and, if X= 0 , sam...
2023
-
[28]
Proof:Our analysis follows Proposition 5.7 and Theorem 5.2 by Steinke et al. (2023). For i∈ {0, . . . , m} and s≤i ∈V 1 × · · · ×V i, let M(s ≤i) denote the distribution on Σ1 × · · · ×Σ m obtained by conditioningM(S)onS ≤i =s ≤i. We can express this as a convex combination: M(s ≤i) = X s>i∈Vi×···×Vm M(s ≤i, s>i)·P S>i←Vi×···×Vm[S>i =s >i]. 19 Published a...
2023
-
[29]
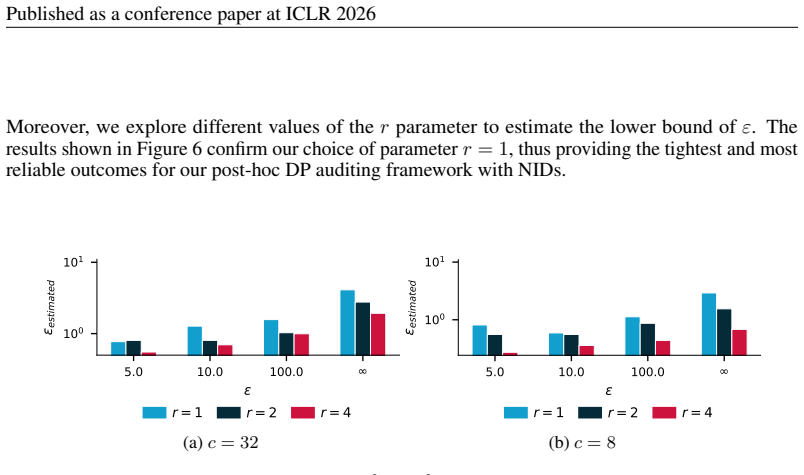
We highlight that our method is tight for rank threshold r= 1 , and the higher the ε, the larger the improvement given by a larger cardinalityc
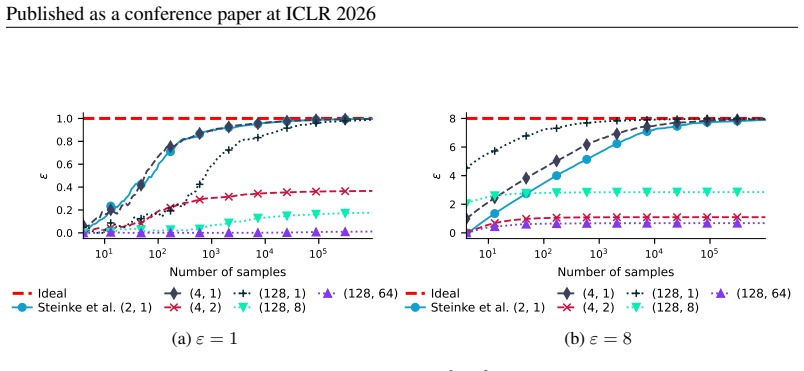
G.2 ADDITIONALRANDOMIZEDRESPONSEEXPERIMENTS FORr >1 Figure 4a and Figure 4b show additional results for the randomized response setting. We highlight that our method is tight for rank threshold r= 1 , and the higher the ε, the larger the improvement given by a larger cardinalityc. In the specific case of randomized response, r >1 is not tight, as there is...
2026
-
[30]
(b)ε= 8 Figure 4:Randomized responsemechanism with ε={1,8} . The red dashed line indicates the real ε of the mechanism, while other ones indicate the estimated lower bound of ε with 99% confidence for different choices of cardinality c, and rank threshold r. The (2,1) case corresponds to the method proposed by Steinke et al. (2023). Each label is written ...
2023
-
[31]
, m} , we have |Vi|= 2 and ri = 1, the algorithm is equivalent to the fixed-length dataset case proposed by Steinke et al
We highlight that when for all i∈ {1, . . . , m} , we have |Vi|= 2 and ri = 1, the algorithm is equivalent to the fixed-length dataset case proposed by Steinke et al. (2023). 24 Published as a conference paper at ICLR 2026 Algorithm 1:Adapted version of the black-box DP-SGD Auditor algorithm proposed by Steinke et al. (2023) for fixed-length dataset with ...
2023
-
[32]
25 Published as a conference paper at ICLR 2026 Table 10:MIAs on NIDs for Pythia-6.9b.The AUC for MIAs between the NIDs and the corre- sponding GIDs on various subsets of the Pile dataset. Full Pile Github StackExchange UbuntuIRC Wikipediaen PubMedCentral HackerNews Pile-CC ArXiv Average MIATrain Test Train Test Train Test Train Train Train Train Train Tr...
2026
-
[33]
Natalia sold 48/2 = «48/2=24»24 clips in May. Natalia sold 48+24 = «48+24=72»72 clips altogether in April and May. #### 72
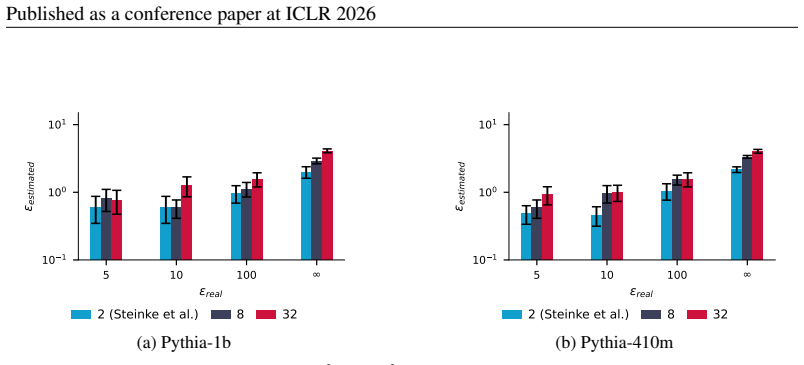
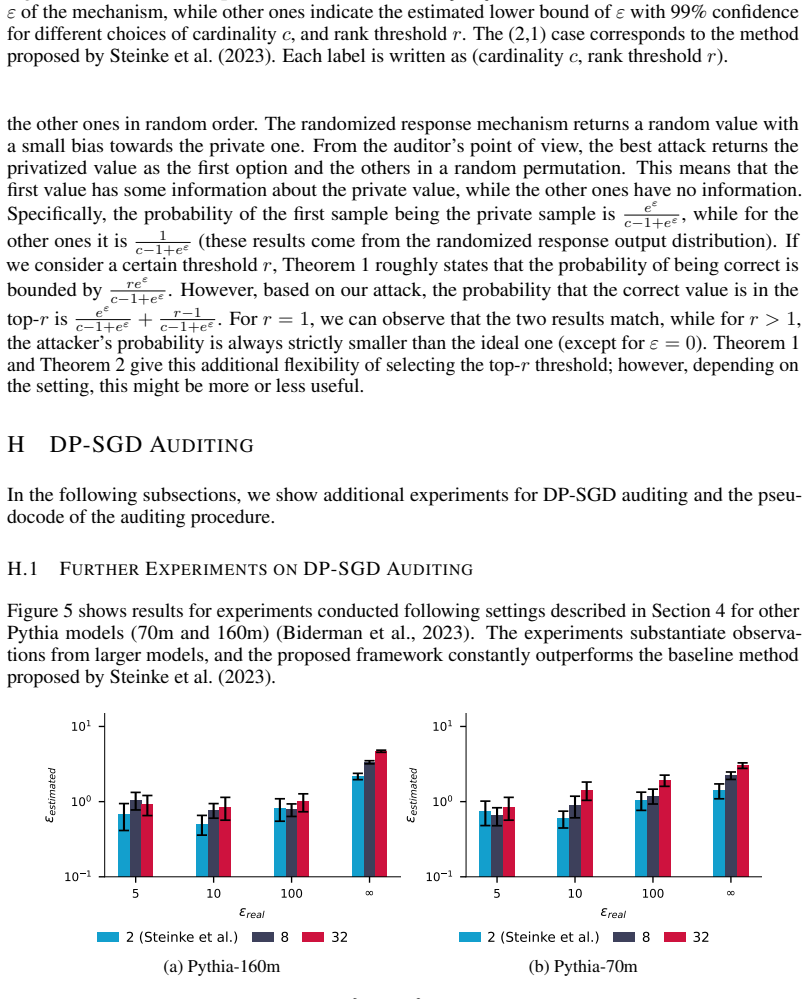
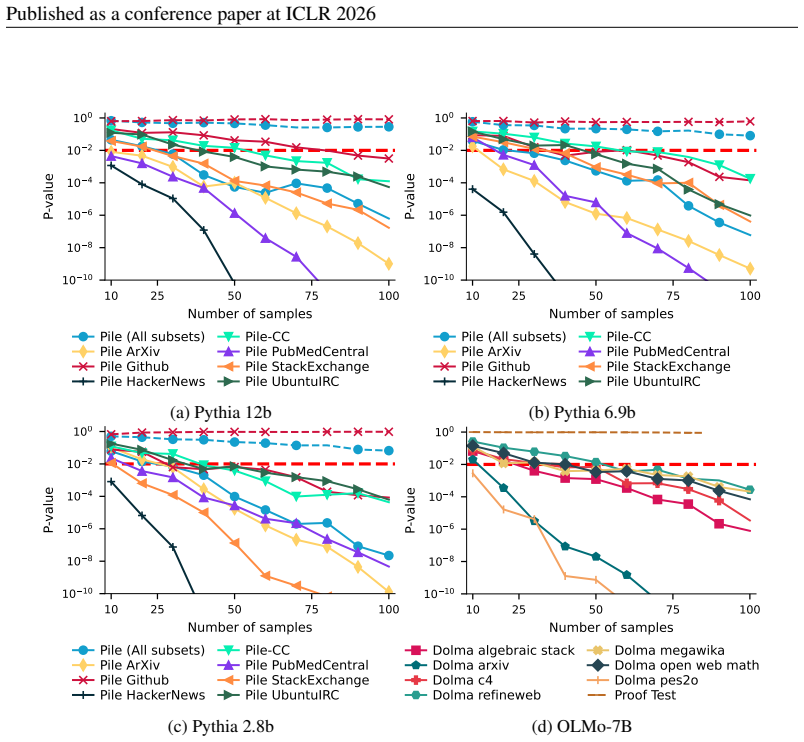
Overall, we find that NIDs perform competitively with other injected canaries. They capture privacy 26 Published as a conference paper at ICLR 2026 Table 14:MIAs on NIDs for Pythia-2.8b.The TPR @ 1% FPR for MIAs between the NIDs and the corresponding GIDs on various subsets of the Pile dataset. Full Pile Github StackExchange UbuntuIRC Wikipediaen PubMedCe...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.