Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
Pith reviewed 2026-06-28 06:28 UTC · model grok-4.3
The pith
Base language models already predict how external judges would score their open-ended responses when given few-shot prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
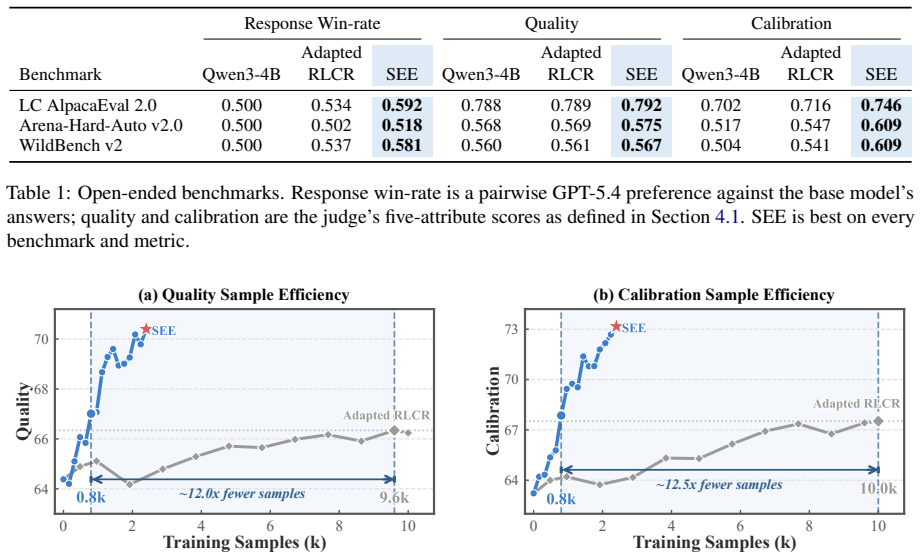
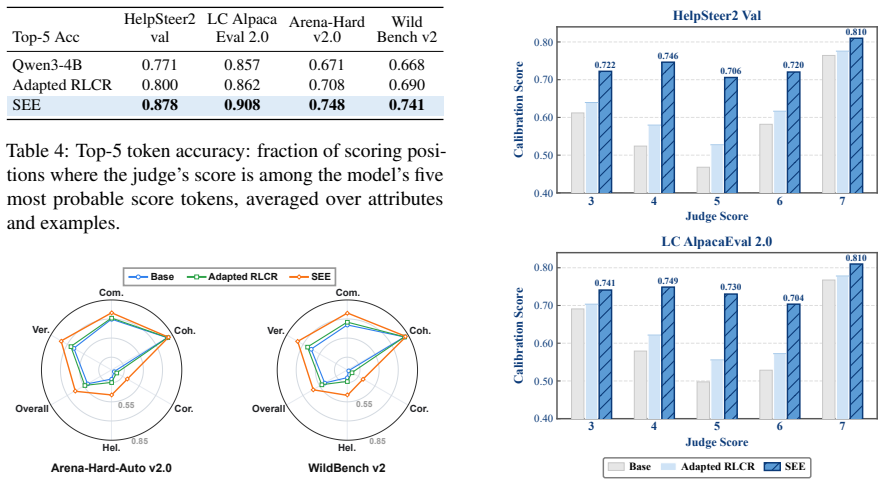
A base model prompted with few-shot examples can already predict how an external judge will assign multi-attribute quality scores to its open-ended responses, performing well above chance on three benchmarks. Self-Evaluation Elicitation elicits this latent ability through a calibration-coupled reinforcement learning phase followed by masked distillation, achieving better held-out calibration from 160 examples while preserving answer quality. The elicited capability is localized in the model's token distribution and transfers to unseen judges.
What carries the argument
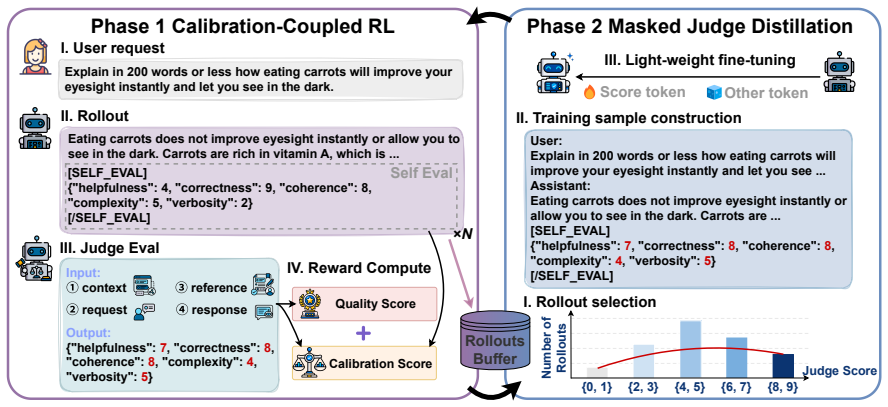
Self-Evaluation Elicitation (SEE), a short cycle consisting of a calibration-coupled reinforcement learning phase that jointly refines answers and judge-score predictions, followed by a masked distillation phase that sharpens only the predictions.
If this is right
- The elicited self-evaluation transfers to judges the model was never trained against.
- Calibration on held-out data improves across the three benchmarks tested.
- Answer quality stays the same after the elicitation cycle completes.
- The ability appears localized inside the model's own token distribution.
Where Pith is reading between the lines
- Minimal-data elicitation may generalize to other latent capabilities that current alignment methods treat as skills to be taught from scratch.
- If the quality notion is already inside the base model, targeted interventions could focus on localization rather than broad retraining.
- The transfer across unseen judges suggests the notion may connect to general response properties rather than judge-specific preferences.
Load-bearing premise
The observed few-shot performance reflects a stable, transferable notion of quality already present in the base model rather than an artifact of the specific prompt format or benchmark construction.
What would settle it
A base model given the same few-shot prompt fails to predict judge scores above chance on a fresh benchmark with different response formats, or the SEE cycle fails to raise held-out calibration while leaving answer quality unchanged.
Figures
read the original abstract
Large language models are increasingly evaluated by other models, raising a natural question: can a model predict how a judge will score its own output? We find that the ability is largely present before any targeted training: prompted few-shot, a base model already predicts an external judge's multi-attribute quality scores on open-ended responses well above chance across three benchmarks. We introduce Self-Evaluation Elicitation (SEE), a method that surfaces this latent ability through a short cycle comprising a calibration-coupled reinforcement learning phase that improves the answer and predicts the judge, followed by a masked distillation phase that sharpens the prediction while leaving the answer untouched. From 160 unique examples, roughly 31x fewer than a reinforcement learning baseline, SEE improves held-out calibration across three benchmarks while preserving answer quality. The elicited self-evaluation is sharply localized within the model's own token distribution and stable across judges it was never trained against, indicating a transferable notion of quality rather than a single judge's preference. These results reframe judge-aligned self-evaluation as a problem of elicitation rather than acquisition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that base LLMs already possess a latent ability to predict an external judge's multi-attribute quality scores on open-ended responses, which can be surfaced via few-shot prompting well above chance on three benchmarks. It introduces Self-Evaluation Elicitation (SEE), a two-phase procedure (calibration-coupled RL followed by masked distillation) that uses only 160 examples—roughly 31x fewer than a standard RL baseline—to improve held-out calibration while preserving answer quality. The resulting self-evaluation is localized in the model's token distribution and generalizes to judges not seen during training, supporting the interpretation that the model harbors a transferable internal notion of quality rather than acquiring one through targeted training.
Significance. If the central results are robust, the work reframes judge-aligned self-evaluation as primarily an elicitation problem, which could substantially lower the data requirements for alignment techniques. The reported localization of the self-evaluation signal and its stability across unseen judges are notable strengths that would, if confirmed, provide evidence for pre-existing quality representations in base models. The minimal-data regime (160 examples) and preservation of answer quality are also positive if the comparisons to the RL baseline hold under controlled conditions.
major comments (2)
- [Abstract and §3] Abstract and §3 (method overview): The claim that few-shot performance demonstrates a 'stable, transferable notion of quality latent in the base model' is load-bearing for the reframing of the problem as elicitation rather than acquisition. However, the manuscript provides no ablations on prompt phrasing, example ordering, or output format variations while holding judge scores fixed. If performance drops under modest rephrasing of the few-shot template, the result would be consistent with surface pattern matching rather than elicitation of an internal calibration.
- [§4] §4 (experimental results): The reported gains from SEE over the RL baseline are presented without error bars, dataset splits, or details on how the 160 examples were selected or whether they overlap with the held-out evaluation sets. This makes it difficult to assess whether the 31x data reduction and improved calibration are robust or sensitive to post-hoc choices in example construction.
minor comments (2)
- [Abstract] The abstract refers to 'three benchmarks' without naming them; the introduction should explicitly list the benchmarks and their characteristics to allow readers to assess domain coverage.
- [§3] Notation for the multi-attribute quality scores and the masking operation in the distillation phase should be defined more formally (e.g., with equations) rather than described only in prose, to improve reproducibility.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and indicate planned revisions to improve clarity and robustness.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method overview): The claim that few-shot performance demonstrates a 'stable, transferable notion of quality latent in the base model' is load-bearing for the reframing of the problem as elicitation rather than acquisition. However, the manuscript provides no ablations on prompt phrasing, example ordering, or output format variations while holding judge scores fixed. If performance drops under modest rephrasing of the few-shot template, the result would be consistent with surface pattern matching rather than elicitation of an internal calibration.
Authors: We agree that the absence of explicit ablations on prompt phrasing, ordering, and output format leaves the interpretation open to the alternative of surface-level pattern matching. While the reported generalization to entirely unseen judges offers some counter-evidence, it does not fully substitute for controlled prompt variations. We will therefore add a short ablation subsection reporting performance under two rephrased templates and one altered output format, using the same fixed judge scores. revision: yes
-
Referee: [§4] §4 (experimental results): The reported gains from SEE over the RL baseline are presented without error bars, dataset splits, or details on how the 160 examples were selected or whether they overlap with the held-out evaluation sets. This makes it difficult to assess whether the 31x data reduction and improved calibration are robust or sensitive to post-hoc choices in example construction.
Authors: The concern is valid; the current presentation omits error bars and precise selection details. The 160 examples were drawn uniformly at random from the training split of each benchmark with zero overlap to the held-out evaluation sets, and the RL baseline was trained on an identically sized random subset for direct comparison. In revision we will (i) report mean and standard deviation over five random seeds, (ii) state the exact random-selection procedure and non-overlap guarantee, and (iii) include a table of the train/validation/test splits used. revision: yes
Circularity Check
No significant circularity; empirical elicitation method is self-contained
full rationale
The paper introduces SEE as an empirical procedure (few-shot prompting plus a short RL+distillation cycle) whose performance is measured on held-out benchmarks against external judges. No equations, fitted parameters, or derivations appear that reduce the claimed latent calibration to quantities defined by the method itself. Claims rest on experimental deltas (31x fewer examples, stability across judges) rather than self-referential definitions or self-citation chains. The central premise that the ability is 'already there' is tested by ablation-style comparisons to baselines, not assumed by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Self-Evaluation Elicitation (SEE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[2]
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe, R...
2022
-
[3]
2022 , eprint=
Constitutional AI: Harmlessness from AI Feedback , author=. 2022 , eprint=
2022
-
[4]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Lee, Harrison and Phatale, Samrat and Mansoor, Hassan and Mesnard, Thomas and Ferret, Johan and Lu, Kellie and Bishop, Colton and Hall, Ethan and Carbune, Victor and Rastogi, Abhinav and Prakash, Sushant , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[5]
Beyond Binary Rewards: Training
Mehul Damani and Isha Puri and Stewart Slocum and Idan Shenfeld and Leshem Choshen and Yoon Kim and Jacob Andreas , booktitle=. Beyond Binary Rewards: Training. 2026 , url=
2026
-
[6]
The Fourteenth International Conference on Learning Representations , year=
LaSeR: Reinforcement Learning with Last-Token Self-Rewarding , author=. The Fourteenth International Conference on Learning Representations , year=
-
[7]
2025 , eprint=
Post-Completion Learning for Language Models , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[9]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
HelpSteer 2: Open-source dataset for training top-performing reward models , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[10]
2022 , eprint=
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
2022
-
[11]
2023 , url=
Chunting Zhou and Pengfei Liu and Puxin Xu and Srini Iyer and Jiao Sun and Yuning Mao and Xuezhe Ma and Avia Efrat and Ping Yu and LILI YU and Susan Zhang and Gargi Ghosh and Mike Lewis and Luke Zettlemoyer and Omer Levy , booktitle=. 2023 , url=
2023
-
[12]
Muennighoff, Niklas and Yang, Zitong and Shi, Weijia and Li, Xiang Lisa and Fei-Fei, Li and Hajishirzi, Hannaneh and Zettlemoyer, Luke and Liang, Percy and Cand \`e s, Emmanuel and Hashimoto, Tatsunori. s1: Simple test-time scaling. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1025
-
[13]
2025 , url=
Yixin Ye and Zhen Huang and Yang Xiao and Ethan Chern and Shijie Xia and Pengfei Liu , booktitle=. 2025 , url=
2025
-
[14]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in
Yang Yue and Zhiqi Chen and Rui Lu and Andrew Zhao and Zhaokai Wang and Yang Yue and Shiji Song and Gao Huang , booktitle=. Does Reinforcement Learning Really Incentivize Reasoning Capacity in. 2026 , url=
2026
-
[15]
2026 , eprint=
Spurious Rewards: Rethinking Training Signals in RLVR , author=. 2026 , eprint=
2026
-
[16]
The Fourteenth International Conference on Learning Representations , year=
AlphaAlign: Incentivizing Safety Alignment with Extremely Simplified Reinforcement Learning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[17]
The Twelfth International Conference on Learning Representations , year=
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author=. The Twelfth International Conference on Learning Representations , year=
-
[18]
2023 , eprint=
Reinforced Self-Training (ReST) for Language Modeling , author=. 2023 , eprint=
2023
-
[19]
Transactions on Machine Learning Research , issn=
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[20]
2023 , url=
Hanze Dong and Wei Xiong and Deepanshu Goyal and Yihan Zhang and Winnie Chow and Rui Pan and Shizhe Diao and Jipeng Zhang and KaShun SHUM and Tong Zhang , journal=. 2023 , url=
2023
-
[21]
2022 , url=
Eric Zelikman and Yuhuai Wu and Jesse Mu and Noah Goodman , booktitle=. 2022 , url=
2022
-
[22]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[23]
2025 , eprint=
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators , author=. 2025 , eprint=
2025
-
[24]
Forty-second International Conference on Machine Learning , year=
From Crowdsourced Data to High-quality Benchmarks: Arena-Hard and Benchbuilder Pipeline , author=. Forty-second International Conference on Machine Learning , year=
-
[25]
2024 , eprint=
WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.