Regimes: An Auditable, Held-Out-Gated Improvement Loop Demonstrated on LongMemEval with ActiveGraph
Pith reviewed 2026-06-27 16:02 UTC · model grok-4.3
The pith
An event-sourced runtime makes controlled agent improvement a first-class auditable workflow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
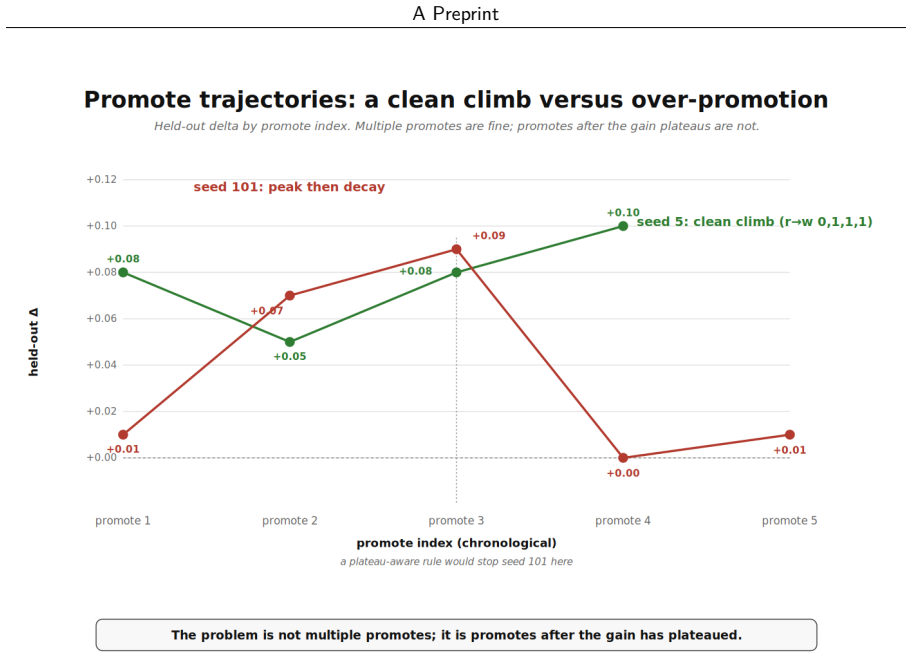
The central claim is that an event-sourced agent runtime removes the friction that usually makes autonomous improvement loops untrustworthy. Failures are recorded in the log, a run replays exactly from its history, candidate patches scope to typed pipeline seams, gates are auditable, and every promote-or-discard decision is itself an event. Regimes implements this loop on ActiveGraph and applies it to LongMemEval-S, where it discovers reader-prompt repairs that improve final held-out accuracy by 0.05 to 0.10 in four of five seeded splits and by 0.01 in one over-promotion split.
What carries the argument
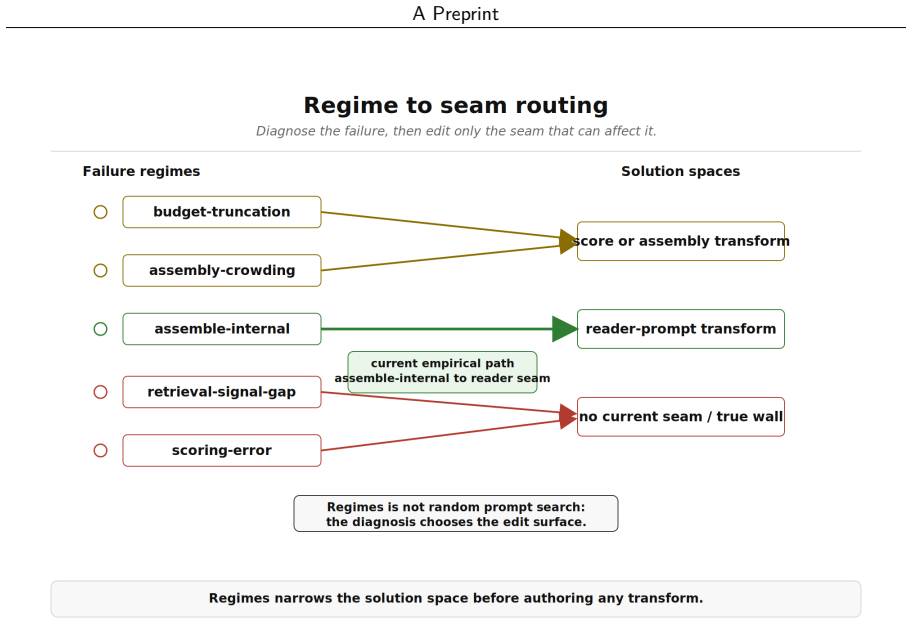
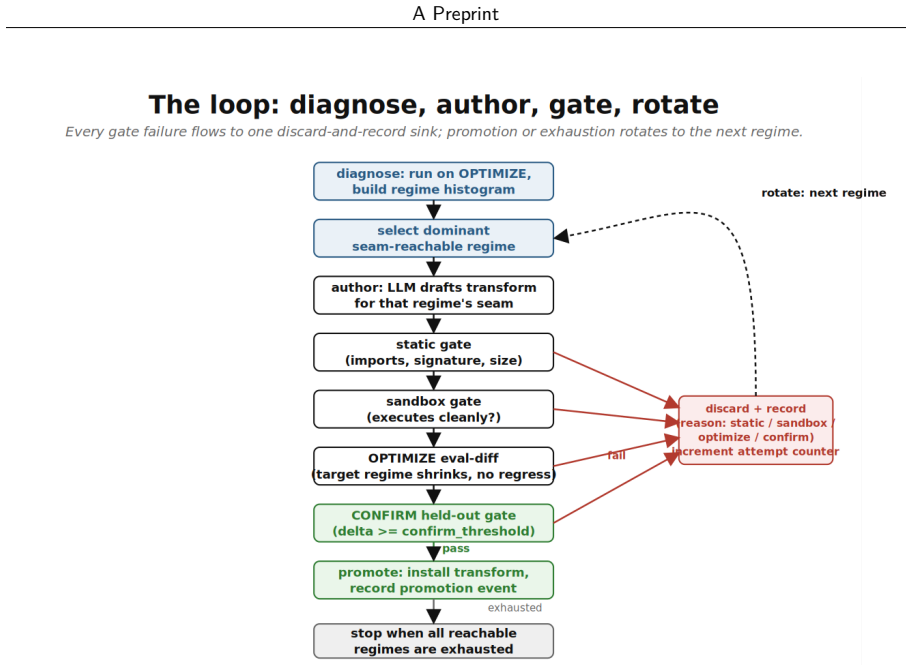
The Regimes loop on the ActiveGraph runtime: it routes failures through a taxonomy to pipeline locations, proposes typed repairs, and gates promotion behind static checks, sandbox execution, in-sample evaluation, and held-out validation.
If this is right
- The same control flow runs against different tasks through a common interface.
- Every promotion or discard decision is recorded as an event in the agent's history.
- Candidate repairs are scoped to typed pipeline seams rather than arbitrary code changes.
- The dominant failure on LongMemEval-S is reconciliation of evidence already present in the assembled context.
Where Pith is reading between the lines
- If the taxonomy delivers positive marginal value, the same routing approach could be tested on other agent pipelines that combine retrieval and generation steps.
- Treating prompts as discovery probes suggests that similar diagnosis-and-repair loops could be applied to non-prompt components such as retrieval rankers or tool-use policies.
- Because every decision is an event, downstream analyses could replay entire improvement histories to measure cumulative effects across multiple cycles.
- The target-agnostic property implies the loop could be applied to tasks outside LongMemEval without rewriting the control flow.
Load-bearing premise
The failure-regime taxonomy routes each failure to a pipeline location whose marginal value over an unrouted baseline is positive.
What would settle it
Measure accuracy gains from an unrouted improvement baseline versus the same loop using the failure-regime taxonomy on the same five seeded held-out splits of LongMemEval-S.
Figures


read the original abstract
Autonomous improvement loops are hard to trust because the improvement process is usually external scaffolding bolted onto the agent: failures go unlogged, diagnoses cannot be replayed, and promote-or-discard decisions land in a side database rather than the agent's own history. We show that an event-sourced agent runtime removes that friction and turns controlled improvement into a first-class workflow. When the agent's state is a deterministic projection of an append-only event log, failures are recorded, a run replays exactly from its log, candidate patches scope to typed pipeline seams, gates are auditable, and every promotion or discard is itself an event. We demonstrate this with Regimes, a loop on the ActiveGraph runtime that diagnoses failed evaluations, proposes a repair at a pipeline point, and promotes it only after static checks, sandbox execution, in-sample evaluation, and held-out validation. The loop is target-agnostic: the same control flow runs against different tasks through a common interface. On LongMemEval-S the dominant failure is not retrieval but reconciliation: the evidence is already in the assembled context, yet the reader answers incorrectly. Across five seeded held-out splits, Regimes discovers reader-prompt repairs that improve final held-out accuracy by +0.05 to +0.10 in four splits and +0.01 in one over-promotion split; two splits are individually significant (seed 5 unadjusted for its sequential promotion structure), and the pooled count is descriptive only, since the splits share one 500-question pool. The durable contributions are ActiveGraph as an auditable substrate that makes controlled improvement loops tractable, the held-out-gated loop it supports, the failure-regime taxonomy routing each failure to a pipeline location (whose marginal value over an unrouted baseline is the primary open question), and the prompt-as-discovery-probe hypothesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Regimes, an auditable, held-out-gated improvement loop on the ActiveGraph event-sourced runtime. Failures on LongMemEval-S are diagnosed via a failure-regime taxonomy that routes each to a pipeline location; reader-prompt repairs are proposed, statically checked, sandboxed, evaluated in-sample, and promoted only after held-out validation. Across five seeded held-out splits the loop reports accuracy gains of +0.05 to +0.10 in four splits and +0.01 in one over-promotion split, with two splits individually significant; the taxonomy's marginal value over an unrouted baseline is explicitly flagged as the primary open question.
Significance. If the taxonomy's marginal contribution is confirmed by an unrouted control, the work supplies a concrete, replayable substrate that makes controlled agent improvement loops first-class and auditable rather than external scaffolding. The emphasis on deterministic event logs, typed pipeline seams, and promotion-as-event is a clear engineering contribution to reproducible agent workflows.
major comments (2)
- [Abstract] Abstract: the central attribution of the reported +0.05–+0.10 held-out gains to the regime taxonomy lacks any unrouted baseline (always-target-reader, random location, or fixed-location control). Without this comparison the improvements cannot be distinguished from those produced by any systematic repair generator; the manuscript itself identifies this comparison as the primary open question.
- [Abstract] Abstract: concrete accuracy deltas are stated without error bars, a full statistical protocol, or details on how the failure-regime taxonomy was derived from the same 500-question pool used for the splits. This weakens the claim that two splits are individually significant.
minor comments (1)
- [Abstract] The manuscript notes that pooled results are descriptive only because splits share the 500-question pool; this limitation should be stated more prominently when presenting the per-split numbers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, noting where the manuscript already acknowledges the limitation and where we will make revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central attribution of the reported +0.05–+0.10 held-out gains to the regime taxonomy lacks any unrouted baseline (always-target-reader, random location, or fixed-location control). Without this comparison the improvements cannot be distinguished from those produced by any systematic repair generator; the manuscript itself identifies this comparison as the primary open question.
Authors: We agree that the manuscript lacks an unrouted baseline comparison. The abstract already explicitly identifies the marginal value of the regime taxonomy over an unrouted baseline as the primary open question and presents the gains with this caveat rather than claiming definitive attribution to the taxonomy. The work is framed as supplying an auditable substrate for such controlled experiments. No revision is required on this point. revision: no
-
Referee: [Abstract] Abstract: concrete accuracy deltas are stated without error bars, a full statistical protocol, or details on how the failure-regime taxonomy was derived from the same 500-question pool used for the splits. This weakens the claim that two splits are individually significant.
Authors: We accept the point. The abstract reports deltas without error bars or a complete statistical protocol, and taxonomy derivation details are not expanded. The manuscript already caveats that the pooled count is descriptive only (due to the shared 500-question pool) and that significance for seed 5 is unadjusted. We will revise the abstract to report error bars across the seeded splits and expand the methods section with taxonomy derivation and statistical protocol details. revision: yes
Circularity Check
No significant circularity; empirical demonstration on held-out splits is independent
full rationale
The paper presents an engineering demonstration of an auditable improvement loop with held-out validation as an explicit gate. The reported accuracy gains are measured on seeded held-out splits, and the abstract explicitly flags the taxonomy's marginal value over an unrouted baseline as the primary open question rather than asserting it as demonstrated. No equations, self-citations, fitted parameters renamed as predictions, or ansatzes appear in the text. The derivation chain consists of a runtime substrate and a gated workflow whose outputs are externally checked on held-out data; it does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[9]
Expel: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. In AAAI, 2024
2024
-
[11]
arXiv preprint arXiv:2605.21997 , year =
The Log is the Agent: Event-Sourced Reactive Graphs for Auditable, Forkable Agentic Systems , author =. arXiv preprint arXiv:2605.21997 , year =
-
[12]
arXiv preprint arXiv:2410.10813 , year =
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , author =. arXiv preprint arXiv:2410.10813 , year =
-
[13]
arXiv preprint arXiv:2605.12493 , year =
LongMemEval-V2: Evaluating Long-Term Agent Memory Toward Experienced Colleagues , author =. arXiv preprint arXiv:2605.12493 , year =
-
[14]
arXiv preprint arXiv:2504.15228 , year =
A Self-Improving Coding Agent , author =. arXiv preprint arXiv:2504.15228 , year =
-
[15]
arXiv preprint arXiv:2605.29668 , year =
GRASP: Gated Regression-Aware Skill Proposer for Self-Improving LLM Agents , author =. arXiv preprint arXiv:2605.29668 , year =
-
[16]
arXiv preprint arXiv:2503.13657 , year =
Why Do Multi-Agent LLM Systems Fail? , author =. arXiv preprint arXiv:2503.13657 , year =
-
[17]
arXiv preprint arXiv:2509.25370 , year =
Where LLM Agents Fail and How They Can Learn From Failures , author =. arXiv preprint arXiv:2509.25370 , year =
-
[18]
arXiv preprint arXiv:2303.11366 , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. arXiv preprint arXiv:2303.11366 , year =
-
[19]
AAAI , year =
ExpeL: LLM Agents Are Experiential Learners , author =. AAAI , year =
-
[20]
arXiv preprint arXiv:2310.03714 , year =
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines , author =. arXiv preprint arXiv:2310.03714 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.