Demonstration of Exponential Quantum Speedup with Constant-Depth Compiled Circuits for Simon's Problem
Pith reviewed 2026-05-07 07:51 UTC · model grok-4.3
The pith
Hardware-aware compilation to constant depth demonstrates exponential quantum speedup for restricted Simon's problem on current processors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
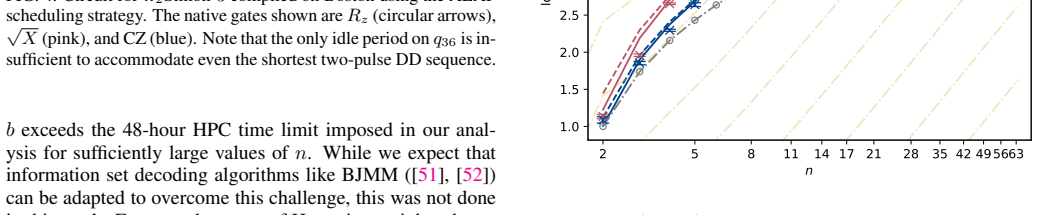
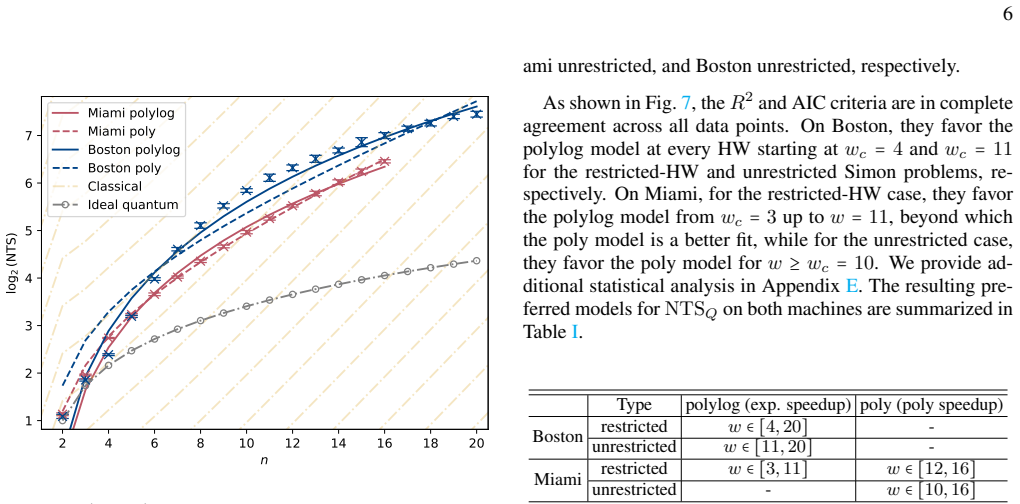
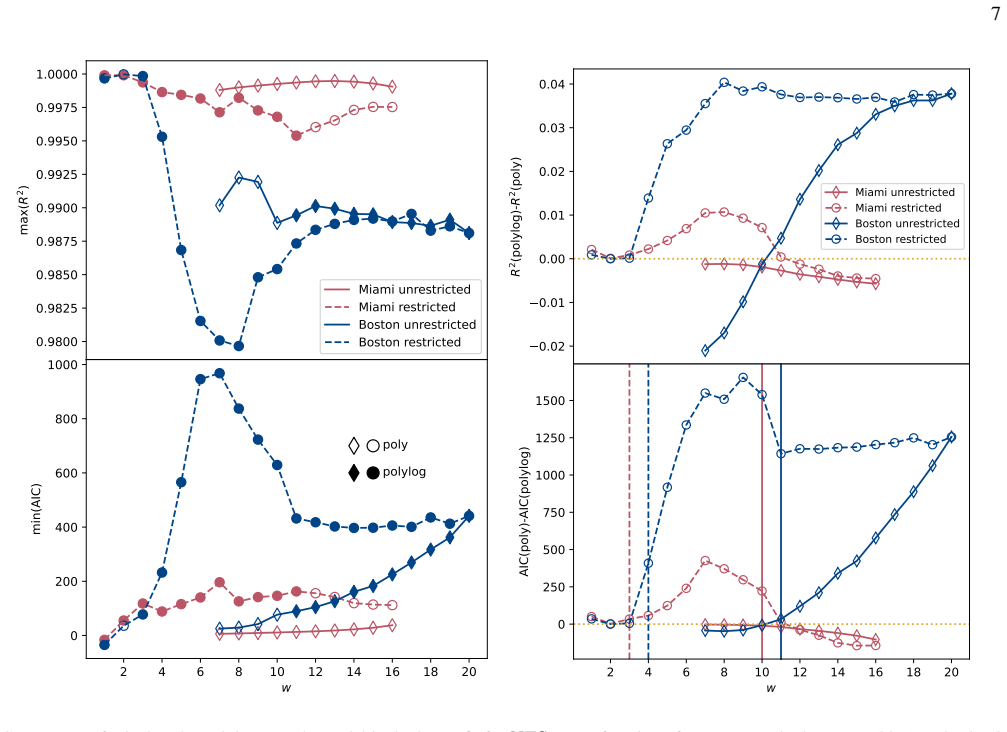
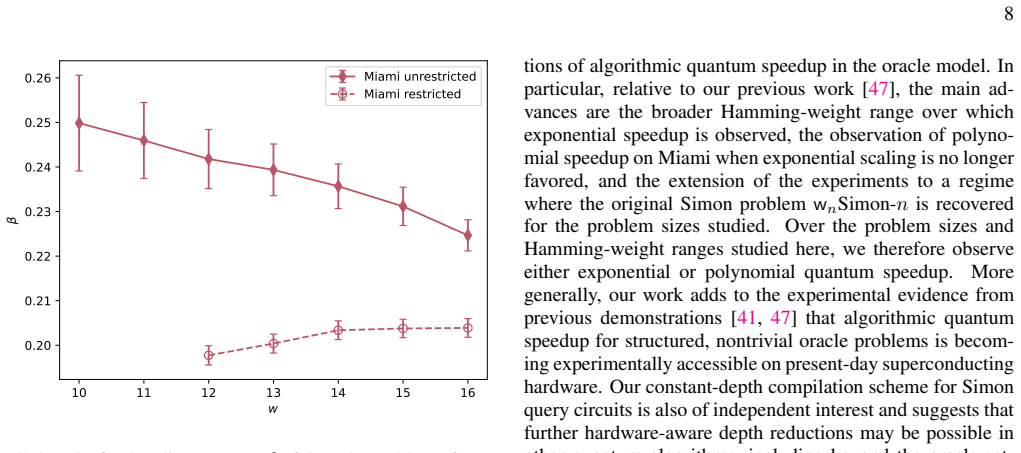
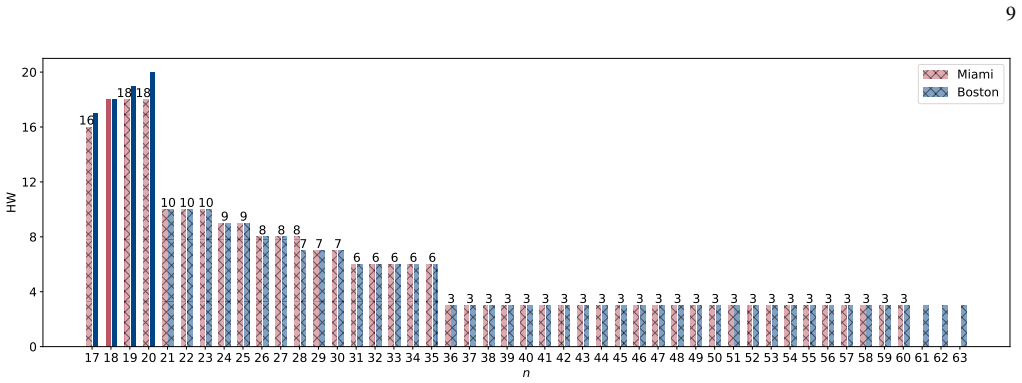
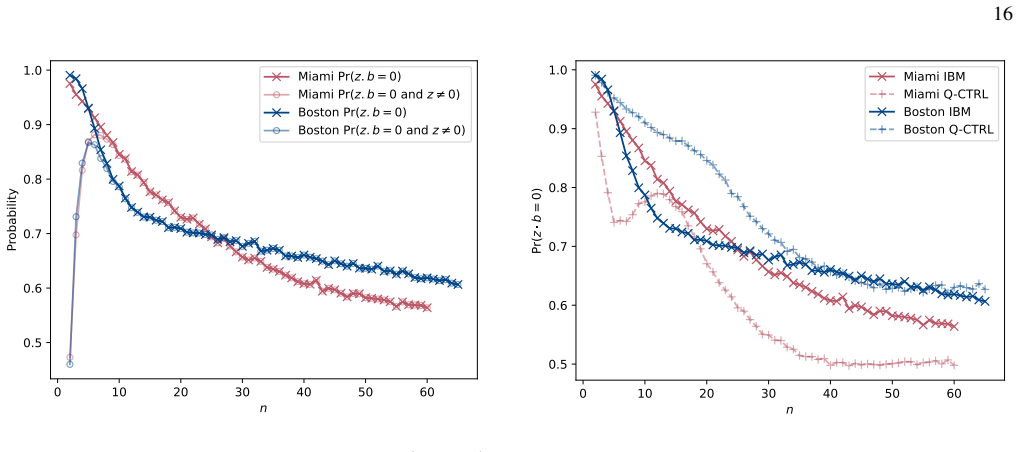
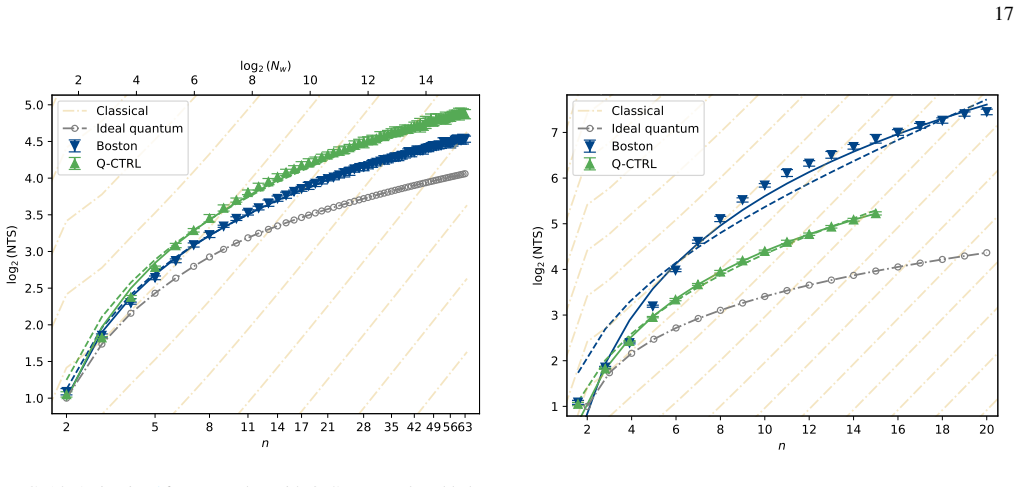
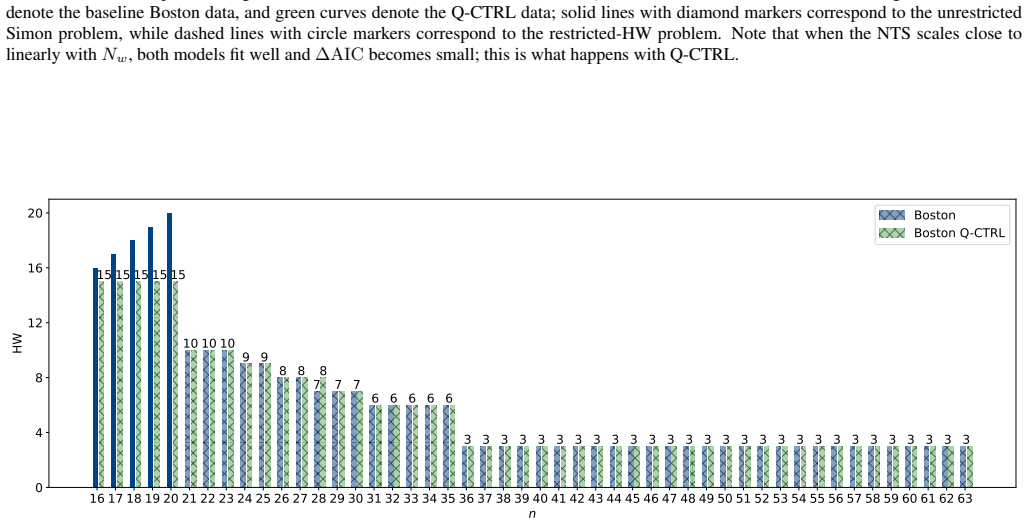
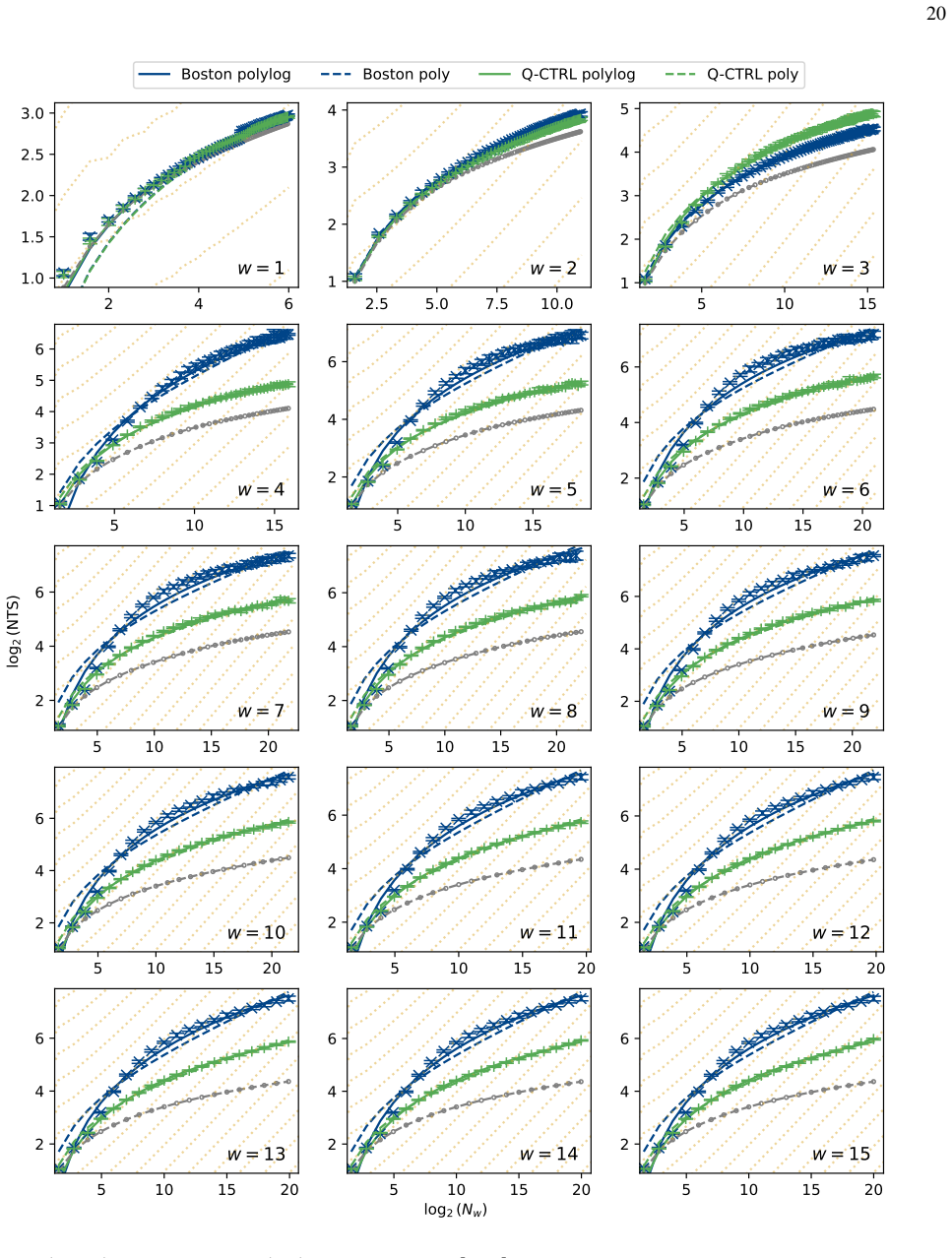
A hardware-aware compilation strategy reduces each Simon query circuit to constant depth while maintaining linear connectivity that maps directly to common device layouts, avoiding routing and SWAP overhead. On IBM's 156-qubit Boston and 120-qubit Miami processors, the resulting circuits reach high enough fidelity to exhibit exponential quantum speedup over the classical lower bound in the number-of-queries-to-solution metric for the restricted-Hamming-weight Simon's problem, without any error suppression. The construction extends to a regime where the original Simon problem is recovered for the problem sizes studied.
What carries the argument
The hardware-aware compilation strategy compiling Simon query circuits to constant-depth, linearly connected circuits directly compatible with processor layouts.
Load-bearing premise
The observed speedup in query counts on the quantum processors stems from the quantum algorithm's interference effects rather than the restricted problem being easy to simulate classically or from unmodeled noise artifacts.
What would settle it
Simulating the restricted-Hamming-weight Simon instances classically while incorporating the measured noise characteristics and gate fidelities from the IBM Boston and Miami processors, then comparing the resulting query requirements to the experimental quantum results.
Figures



read the original abstract
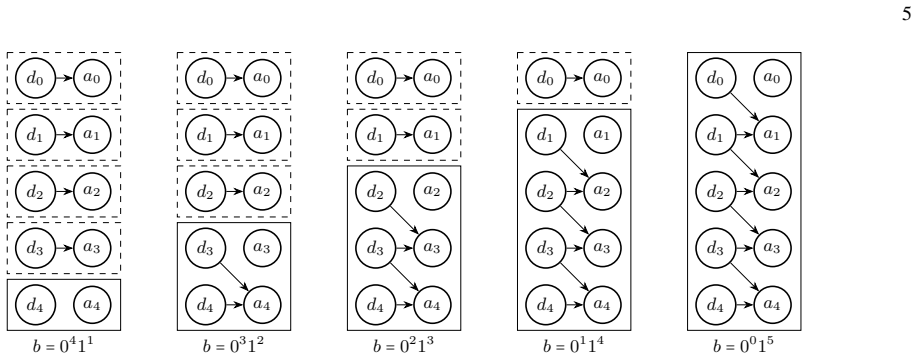
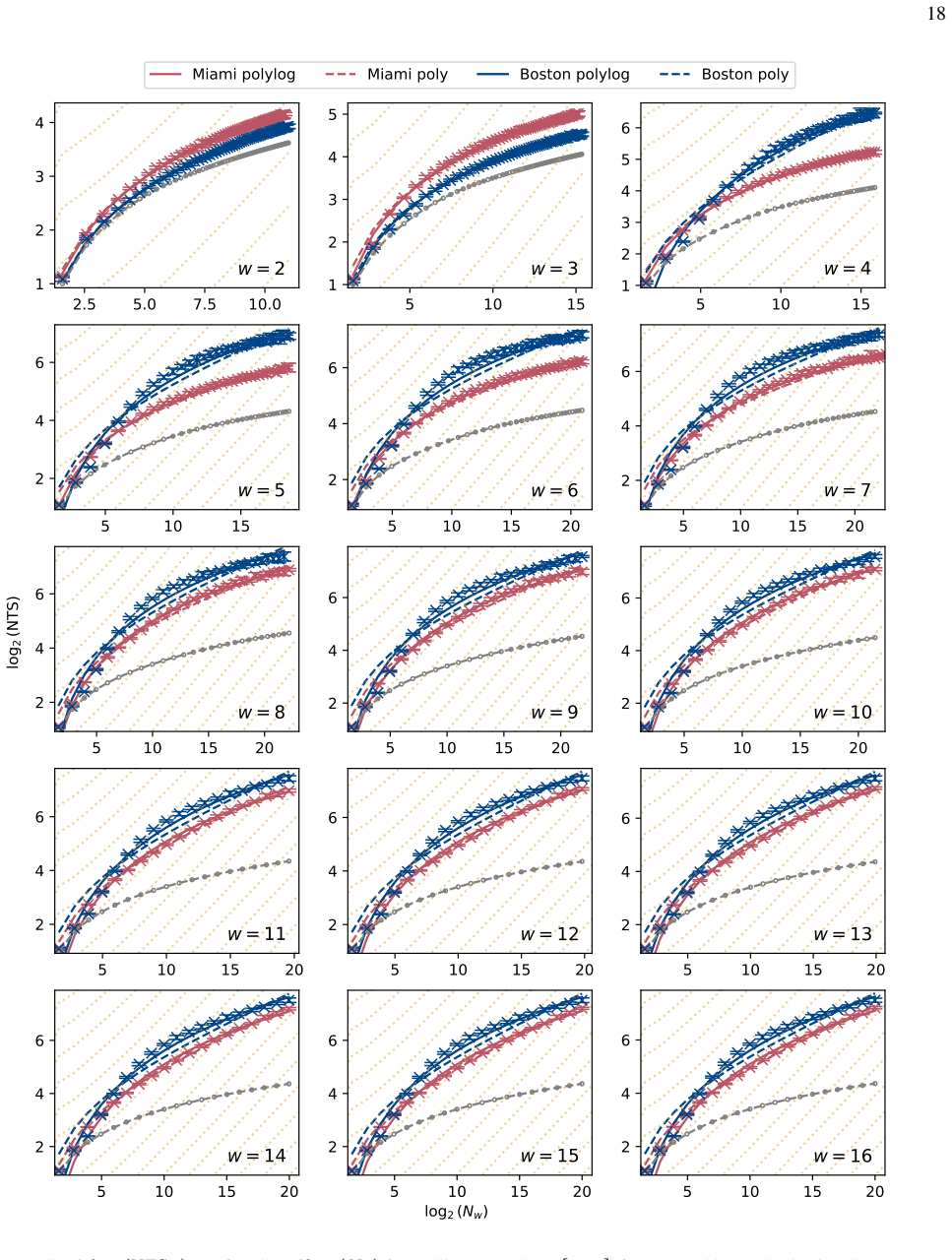
We demonstrate exponential algorithmic quantum speedup for a restricted-Hamming-weight version of Simon's problem, in which the hidden string $b$ is promised to satisfy $\text{HW}(b)\le w$ for a Hamming-weight cutoff $w$, on present-day superconducting quantum processors. We introduce a hardware-aware compilation strategy that reduces the quantum part of each Simon query circuit to constant depth. The resulting compiled circuits have $O(1)$ depth, require only linear nearest-neighbor connectivity, map directly onto common device layouts, and avoid additional routing and SWAP overhead. Implemented on IBM's $156$-qubit Boston and $120$-qubit Miami processors, these circuits achieve sufficient fidelity to exhibit algorithmic quantum speedup without error suppression. Using the number-of-queries-to-solution (NTS) metric, we observe exponential speedup over the classical lower-bound benchmark for all restricted-Hamming-weight cutoffs $w\ge 4$ on Boston and across low-to-intermediate Hamming-weight cutoffs on Miami; at higher Hamming-weight cutoffs on Miami, we still observe polynomial speedup. The same construction also enables unrestricted instances of Simon's problem, corresponding to $w=n$ for problem size $n$, over the finite problem-size ranges for which our NTS computation is feasible; in this regime, the observed scaling advantage is not limited to the restricted-Hamming-weight setting. These results show that careful hardware-aware compilation can make quantum speedup experimentally accessible for a canonical hidden-subgroup problem in the NISQ regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to demonstrate exponential quantum speedup for a restricted-Hamming-weight version of Simon's problem on IBM superconducting processors (Boston 156-qubit and Miami 120-qubit) via a hardware-aware compilation strategy that reduces the quantum circuit for each query to constant depth with linear connectivity. Using the number-of-queries-to-solution metric, the authors report exponential scaling advantage over the classical lower bound across the studied Hamming-weight range on Boston and polynomial speedup at higher weights on Miami, while recovering the original Simon problem at the sizes studied. The work emphasizes that high fidelity is achieved without error suppression.
Significance. If the central claims hold, the result is significant: it provides an experimental demonstration that exponential quantum advantage for a canonical hidden-subgroup problem can be realized in the NISQ regime through targeted compilation rather than error correction. The constant-depth, hardware-mapped circuits and direct comparison to a classical lower bound offer a concrete benchmark for future NISQ implementations of Simon's and related algorithms.
major comments (3)
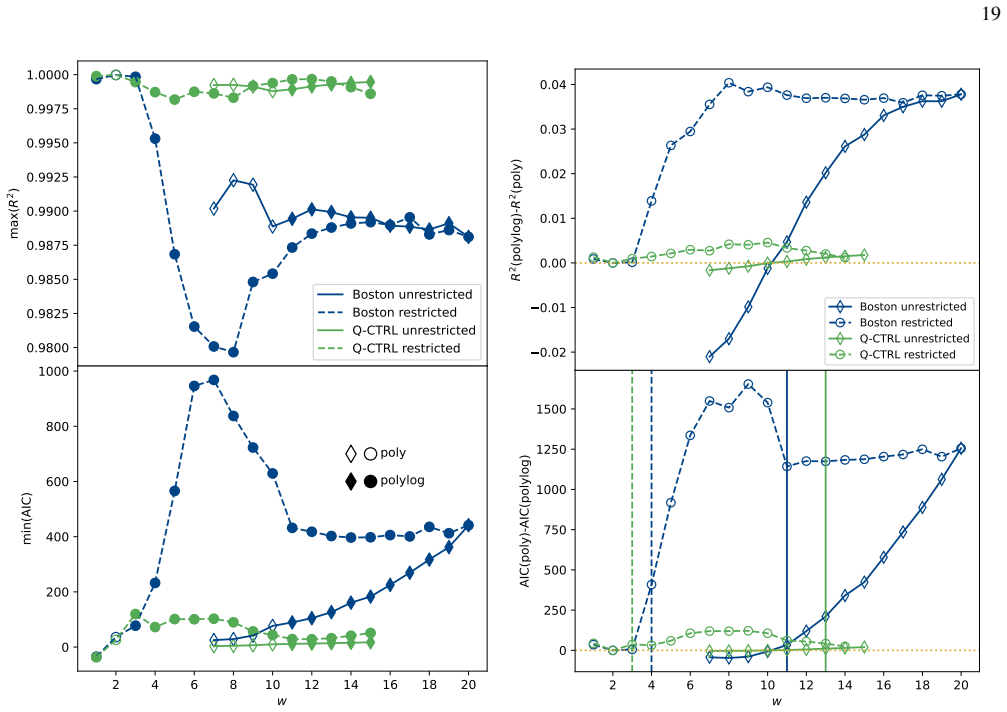
- [§4] §4 (Experimental Results) and the associated figures on queries-to-solution: the exponential speedup claim rests on the observed scaling of the number-of-queries-to-solution metric, yet the manuscript provides no error bars, no description of the exact classical baseline algorithm (including whether it exploits the known Hamming-weight restriction), no statistical tests for the exponential fit, and no data-exclusion criteria. These omissions prevent verification that the reported gap arises from quantum interference rather than noise or baseline mis-specification.
- [Introduction and §2] Introduction and §2 (Problem Definition and Classical Complexity): the headline claim of exponential quantum speedup requires that the classical query complexity remains exponential even when the secret string s is restricted to Hamming weight k. Standard Simon lower bounds apply to unrestricted s; for bounded k the manuscript neither supplies an explicit lower-bound proof nor exhaustive classical simulations of the concrete oracles used. If classical complexity reduces to poly(n,2^k) for the realized k values, the reported exponential gap is not evidence of algorithmic speedup.
- [§3] §3 (Compilation Strategy): while the constant-depth compilation is a technical contribution, the manuscript does not quantify how the restriction to low-Hamming-weight instances interacts with the oracle implementation or whether the compiled circuits remain hard to simulate classically for the k range studied. This information is load-bearing for interpreting the speedup as quantum rather than an artifact of the restricted problem class.
minor comments (3)
- [Abstract] Abstract: the range of Hamming weights k and problem sizes n studied on each device is not stated numerically, making it difficult to assess the scope of the claimed exponential regime.
- [§4] Figure captions and §4: axis labels and legends for the scaling plots should explicitly indicate the classical baseline curve and the fitted exponents; current presentation leaves the comparison visually ambiguous.
- [Introduction] Missing references: prior NISQ demonstrations of Simon's problem (even with error mitigation) and recent work on constant-depth compilation for hidden-subgroup problems should be cited for context.
Simulated Author's Rebuttal
We are grateful to the referee for their thorough review and insightful comments, which have helped us identify areas for improvement in our manuscript. We address each of the major comments below and describe the revisions we intend to implement to enhance the clarity and rigor of our claims.
read point-by-point responses
-
Referee: §4 (Experimental Results) and the associated figures on queries-to-solution: the exponential speedup claim rests on the observed scaling of the number-of-queries-to-solution metric, yet the manuscript provides no error bars, no description of the exact classical baseline algorithm (including whether it exploits the known Hamming-weight restriction), no statistical tests for the exponential fit, and no data-exclusion criteria. These omissions prevent verification that the reported gap arises from quantum interference rather than noise or baseline mis-specification.
Authors: We agree that these elements are necessary for rigorous verification of the results. In the revised manuscript we will add error bars derived from repeated experimental runs on both devices, provide an explicit description of the classical baseline (the standard Ω(2^{n/2}) query lower bound for Simon’s problem), include statistical tests (regression analysis and goodness-of-fit metrics) supporting the reported scaling, and state the data-exclusion criteria (runs with measured fidelity below a documented threshold). These additions will allow readers to confirm that the observed gap is consistent with quantum interference. revision: yes
-
Referee: Introduction and §2 (Problem Definition and Classical Complexity): the headline claim of exponential quantum speedup requires that the classical query complexity remains exponential even when the secret string s is restricted to Hamming weight k. Standard Simon lower bounds apply to unrestricted s; for bounded k the manuscript neither supplies an explicit lower-bound proof nor exhaustive classical simulations of the concrete oracles used. If classical complexity reduces to poly(n,2^k) for the realized k values, the reported exponential gap is not evidence of algorithmic speedup.
Authors: We thank the referee for this important observation. The manuscript compares against the standard unrestricted Simon lower bound. For the restricted-Hamming-weight promise, a classical algorithm that enumerates weight-k candidates and verifies collisions can achieve O(binomial(n,k)) queries. In the revision we will (i) add an explicit discussion of this restricted classical complexity, (ii) report exhaustive classical simulations of the concrete oracles for the small-n instances studied, and (iii) qualify the speedup claims by Hamming-weight regime, noting polynomial classical scaling for the smallest k and exponential scaling once binomial(n,k) becomes super-polynomial. Where the data support only polynomial speedup we will adjust the text and figure captions accordingly. revision: partial
-
Referee: §3 (Compilation Strategy): while the constant-depth compilation is a technical contribution, the manuscript does not quantify how the restriction to low-Hamming-weight instances interacts with the oracle implementation or whether the compiled circuits remain hard to simulate classically for the k range studied. This information is load-bearing for interpreting the speedup as quantum rather than an artifact of the restricted problem class.
Authors: We agree that further quantification is required. The low-Hamming-weight restriction permits a simplified oracle construction whose two-qubit gate count and depth scale linearly with k rather than n, enabling the constant-depth compiled circuits. In the revised §3 we will (i) tabulate gate counts and depth versus k, (ii) provide classical simulation cost estimates (state-vector or tensor-network) showing that the compiled circuits remain exponentially hard to simulate for the studied k range because the quantum algorithm still requires maintaining a superposition over 2^n amplitudes, and (iii) argue that the observed query advantage cannot be reproduced by any classical algorithm that merely exploits the promise without performing an equivalent number of oracle calls. Where feasible we will also include small-scale classical circuit simulations as supporting data. revision: yes
Circularity Check
No circularity: experimental demonstration measures queries directly against external classical bound
full rationale
The paper is an experimental hardware demonstration of a constant-depth compiled Simon circuit on IBM processors. It reports measured query counts to solution and compares them to the standard classical lower bound for Simon's problem (cited from prior literature). No derivation chain exists in which a 'prediction' or central result is obtained by fitting parameters to the same experimental data, by self-definition, or by a load-bearing self-citation chain. The hardware-aware compilation is a constructive engineering step whose output is then executed and measured; the speedup claim rests on the observed scaling versus the external benchmark, not on any internal reduction that equates output to input by construction. The restricted-Hamming-weight variant is handled by direct experiment rather than by re-deriving complexity bounds inside the paper. Any debate over whether the classical lower bound remains exponential for bounded Hamming weight is a question of external correctness, not circularity within the paper's logic.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.