The State of Peer Review in Empirical Software Engineering: A Community Survey on Review Load, Quality, and GenAI Use
Pith reviewed 2026-06-28 05:27 UTC · model grok-4.3
The pith
A survey of 120 empirical software engineering researchers documents current review loads, quality problems, LLM tool use, and improvement ideas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The survey of 120 ESE community members documents perceived review load, quality issues, frequent challenges, LLM-based tool use in reviewing, and community suggestions for improving the peer review system.
What carries the argument
The questionnaire survey with 120 self-selected responses that gathers community perceptions on review load, quality, GenAI use, and system improvements.
If this is right
- Community members experience notable review load that contributes to system strain.
- Review quality is perceived to face recurring challenges and issues.
- LLM-based tools have entered the reviewing workflow with associated concerns.
- The community holds concrete ideas for targeted improvements to peer review processes.
Where Pith is reading between the lines
- If these perceptions hold more widely, conferences and journals may need to adjust reviewer assignment policies or introduce workload caps.
- Similar surveys in adjacent fields such as computer science theory or human-computer interaction could test whether the reported patterns are domain-specific.
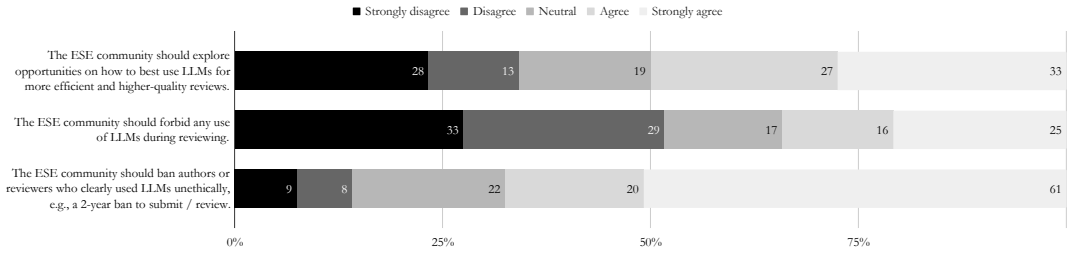
- Explicit guidelines on acceptable LLM assistance during review could become a standard requirement if tool use continues to grow.
Load-bearing premise
The 120 self-selected respondents provide a sufficiently representative picture of the broader empirical software engineering community to support general statements about review load and quality.
What would settle it
A follow-up survey using random sampling or a much larger response pool that finds substantially different average perceptions of review load or quality would undermine the generalizability of these results.
Figures



read the original abstract
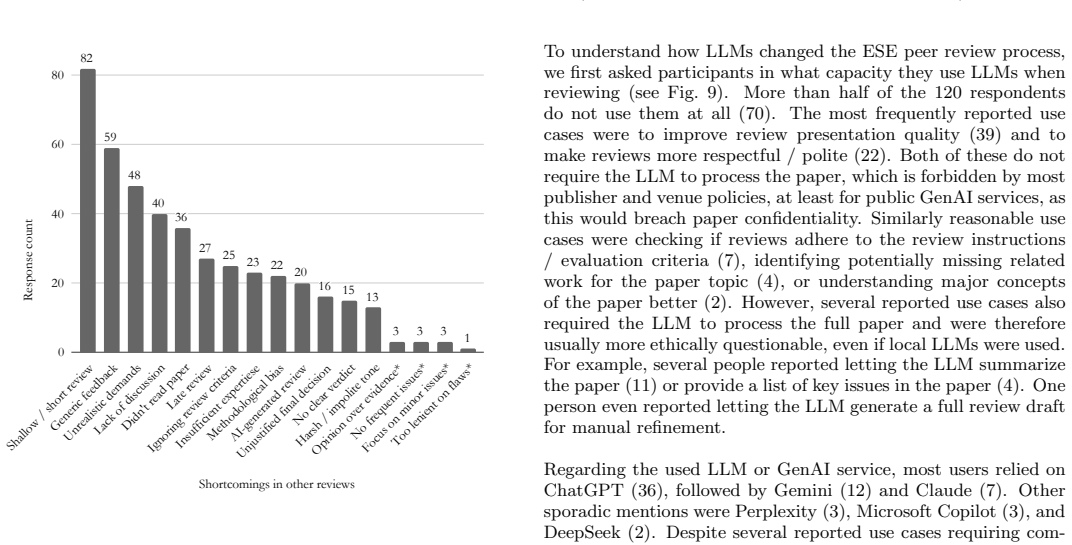
The scientific peer review system has been slowly deteriorating over the last years, and not just within empirical software engineering (ESE) research. Increased submission numbers, high workload, and the rise of generative AI use with all its associated issues have made many cracks in the system more visible. To get a better understanding of the current state of peer review in the ESE community, we conducted a questionnaire survey, which accumulated 120 responses. We report on (i) the perceived review load of community members, (ii) review quality perception as well as frequent challenges for and issues with reviews, (iii) the use of LLM-based tools in the reviewing process, and (iv) the community's suggestions for improving the peer review system. We hope that these community opinions can facilitate more evidence-based discussions about how people want to see the review system change for the better.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents results from an online questionnaire survey that received 120 responses from members of the empirical software engineering (ESE) community. It reports descriptive statistics and qualitative themes on (i) perceived review load, (ii) perceptions of review quality together with common challenges and issues, (iii) use of LLM-based tools during reviewing, and (iv) community suggestions for improving the peer-review system.
Significance. If the sample were demonstrably representative, the work would supply useful community-sourced data on review workload, quality problems, and emerging GenAI practices that could inform evidence-based discussions about peer-review reform in ESE. The paper's strength lies in its direct, unmodeled reporting of respondent answers against external benchmarks; no fitted parameters or invented constructs are introduced.
major comments (1)
- [§3 and Abstract] §3 (Survey Design and Administration) and Abstract: The central claim that the survey documents 'the state of peer review in the ESE community' rests on the assumption that the 120 self-selected respondents are sufficiently representative. The manuscript provides no information on distribution channels, total invitations sent, response rate, handling of non-response bias, or demographic benchmarking of respondents against the ESE population (e.g., via DBLP or conference attendance data). Because every reported percentage, theme, and suggestion depends on this assumption, the absence of these details is load-bearing for the paper's primary contribution.
minor comments (2)
- [Demographics table] Table 1 (or equivalent respondent demographics table): Clarify whether the reported percentages are of all 120 respondents or of the subset who answered each question; missing-data handling should be stated explicitly.
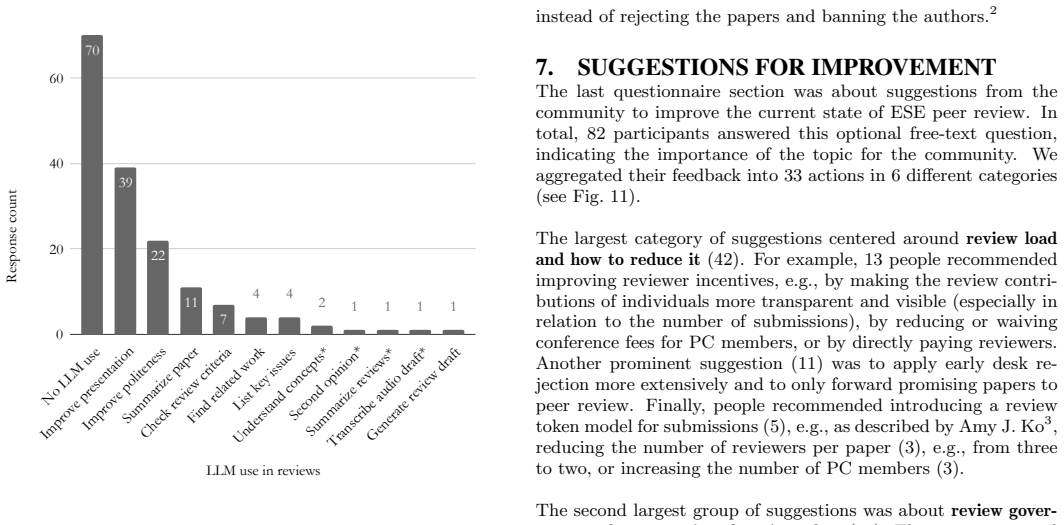
- [§4.3] §4.3 (LLM use): The distinction between 'using LLMs to draft reviews' and 'using LLMs to check grammar' is important for policy implications; ensure the questionnaire items and response categories make this distinction unambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our survey paper. We agree that the sampling approach and its implications require clearer exposition and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3 and Abstract] §3 (Survey Design and Administration) and Abstract: The central claim that the survey documents 'the state of peer review in the ESE community' rests on the assumption that the 120 self-selected respondents are sufficiently representative. The manuscript provides no information on distribution channels, total invitations sent, response rate, handling of non-response bias, or demographic benchmarking of respondents against the ESE population (e.g., via DBLP or conference attendance data). Because every reported percentage, theme, and suggestion depends on this assumption, the absence of these details is load-bearing for the paper's primary contribution.
Authors: We agree that the manuscript should provide more information on the survey administration and explicitly address potential biases. We will revise §3 to include all available details on how the survey was distributed and add a limitations section discussing the self-selected sample, absence of response rate information, and lack of formal benchmarking against the broader ESE population. We will also update the abstract to more accurately reflect that the results capture perceptions from a self-selected group of community members. These changes will strengthen the paper by clarifying the scope of the claims. revision: yes
Circularity Check
No circularity: direct survey reporting with no derivations or self-referential steps
full rationale
This is a questionnaire survey paper reporting aggregated responses from 120 participants on review load, quality, LLM use, and improvement suggestions. The provided abstract and description contain no equations, model derivations, fitted parameters, predictions, or load-bearing self-citations. All content is a direct summary of collected data, with no reduction of claims to inputs by construction. The representativeness of the sample is an external validity concern, not a circularity issue in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 120 self-selected survey responses are representative enough of the ESE community to support statements about review load and quality.
Reference graph
Works this paper leans on
-
[1]
Diek- man, Ayelet Fishbach, Robert L
Balazs Aczel, Ann-Sophie Barwich, Amanda B. Diek- man, Ayelet Fishbach, Robert L. Goldstone, Pablo Gomez, Odd Erik Gundersen, Paul T. Von Hippel, Alex O. Hol- combe, Stephan Lewandowsky, Nazbanou Nozari, Franco Pestilli, and John P. A. Ioannidis. The present and fu- ture of peer review: Ideas, interventions, and evidence. Proceedings of the National Acade...
-
[2]
Rand Alchokr, Jacob Kr ¨uger, Yusra Shakeel, Gunter Saake, and Thomas Leich. Peer-Reviewing and Submission Dynam- ics Around Top Software-Engineering Venues: A Juniors’ Perspective. InThe International Conference on Evalua- tion and Assessment in Software Engineering 2022, pages 60–69, Gothenburg Sweden, June 2022. ACM. ISBN 978-1- 4503-9613-4. doi: 10.11...
-
[3]
Compound Deception in Elite Peer Review: A Failure Mode Taxonomy of 100 Fabricated Citations at NeurIPS 2025, 2026
Samar Ansari. Compound Deception in Elite Peer Review: A Failure Mode Taxonomy of 100 Fabricated Citations at NeurIPS 2025, 2026. URLhttps://arxiv.org/abs/2602. 05930
2025
-
[4]
Towards a More Structured Peer Review Process with Empirical Stan- dards
Arham Arshad, Taher Ghaleb, and Paul Ralph. Towards a More Structured Peer Review Process with Empirical Stan- dards. InEvaluation and Assessment in Software Engineer- ing, pages 353–358, Trondheim Norway, June 2021. ACM. ISBN 978-1-4503-9053-8. doi: 10.1145/3463274.3463359. URLhttps://dl.acm.org/doi/10.1145/3463274.3463359
-
[5]
Dauphin, Percy Liang, and Jen- nifer Wortman Vaughan
Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jen- nifer Wortman Vaughan. Has the Machine Learning Review Process Become More Arbitrary as the Field Has Grown? The NeurIPS 2021 Consistency Experiment, 2023. URL https://arxiv.org/abs/2306.03262
arXiv 2021
- [6]
-
[7]
Ernst, Jeffrey C
Neil A. Ernst, Jeffrey C. Carver, Daniel Mendez, and Marco Torchiano. Understanding peer review of software engi- neering papers.Empirical Software Engineering, 26(5):103, September 2021. ISSN 1382-3256, 1573-7616. doi: 10.1007/ s10664-021-10005-5. URLhttps://link.springer.com/10. 1007/s10664-021-10005-5
2021
-
[8]
Remco Heesen and Liam Kofi Bright. Is Peer Review a Good Idea?The British Journal for the Philosophy of Science, 72 (3):635–663, September 2021. ISSN 0007-0882, 1464-3537. doi: 10.1093/bjps/axz029. URLhttps://www.journals. uchicago.edu/doi/10.1093/bjps/axz029
-
[9]
Scientific production in the era of large language models.Science, 390(6779):1240–1243, 2025
Keigo Kusumegi, Xinyu Yang, Paul Ginsparg, Mathijs De Vaan, Toby Stuart, and Yian Yin. Scientific produc- tion in the era of large language models.Science, 390(6779): 1240–1243, December 2025. ISSN 0036-8075, 1095-9203. doi: 10.1126/science.adw3000. URLhttps://www.science.org/ doi/10.1126/science.adw3000
-
[10]
McFarland, and James Y
Weixin Liang, Zachary Izzo, Yaohui Zhang, Haley Lepp, Hancheng Cao, Xuandong Zhao, Lingjiao Chen, Haotian Ye, Sheng Liu, Zhi Huang, Daniel A. McFarland, and James Y. Zou. Monitoring ai-modified content at scale: a case study on the impact of chatgpt on ai conference peer reviews. In Proceedings of the 41st International Conference on Machine Learning, ICM...
2024
-
[11]
SE Journals in 2036: Looking Back at the Future We Need to Have, 2026
Tim Menzies, Paris Avgeriou, Robert Feldt, Mauro Pezz` e, Abhik Roychoudhury, Miroslaw Staron, Sebastian Uchitel, and Thomas Zimmermann. SE Journals in 2036: Looking Back at the Future We Need to Have, 2026. URLhttps: //arxiv.org/abs/2601.19217
arXiv 2036
-
[12]
Major AI conference flooded with peer reviews written fully by AI.Nature, 648(8093):256–257, December 2025
Miryam Naddaf. Major AI conference flooded with peer reviews written fully by AI.Nature, 648(8093):256–257, December 2025. ISSN 0028-0836, 1476-4687. doi: 10. 1038/d41586-025-03506-6. URLhttps://www.nature.com/ articles/d41586-025-03506-6
2025
-
[13]
Towards A Sustainable Fu- ture for Peer Review in Software Engineering, 2026
Esteban Parra, Sonia Haiduc, Preetha Chatterjee, Ramtin Ehsani, and Polina Iaremchuk. Towards A Sustainable Fu- ture for Peer Review in Software Engineering, 2026. URL https://arxiv.org/abs/2601.21761
arXiv 2026
-
[14]
Lutz Prechelt, Daniel Graziotin, and Daniel M´ endez Fern´ an- dez. A community’s perspective on the status and future of peer review in software engineering.Information and Soft- ware Technology, 95:75–85, March 2018. ISSN 09505849. doi: 10.1016/j.infsof.2017.10.019. URLhttps://linkinghub. elsevier.com/retrieve/pii/S0950584917304986
-
[15]
Nihar B. Shah. Challenges, experiments, and computational solutions in peer review.Communications of the ACM, 65(6): 76–87, June 2022. ISSN 0001-0782, 1557-7317. doi: 10.1145/ 3528086. URLhttps://dl.acm.org/doi/10.1145/3528086
-
[16]
Pains and Gains of Peer-Reviewing in Software Engineering.ACM SIGSOFT Software Engineering Notes, 45(1):12–13, January
Jacopo Soldani, Marco Kuhrmann, and Dietmar Pfahl. Pains and Gains of Peer-Reviewing in Software Engineering.ACM SIGSOFT Software Engineering Notes, 45(1):12–13, January
-
[17]
ISSN 0163-5948. doi: 10.1145/3375572.3375575. URL https://dl.acm.org/doi/10.1145/3375572.3375575
-
[18]
The Lean Theorem Prover (System Description)
Stefan Wagner, Daniel Mendez, Michael Felderer, Daniel Graziotin, and Marcos Kalinowski. Challenges in Survey Re- search. InContemporary Empirical Methods in Software En- gineering, pages 93–125. Springer International Publishing, Cham, 2020. ISBN 978-3-030-32489-6. doi: 10.1007/978-3- 030-32489-6 4. URLhttp://link.springer.com/10.1007/ 978-3-030-32489-6_4.8
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.