Navigating Unreliable Parametric and Contextual Knowledge: Explicit Knowledge Conflict Resolution for LLM Inference
Pith reviewed 2026-06-26 17:14 UTC · model grok-4.3
The pith
MACR resolves LLM knowledge conflicts by assessing confidence and using multi-agent reasoning to reconcile internal and external sources instead of choosing one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
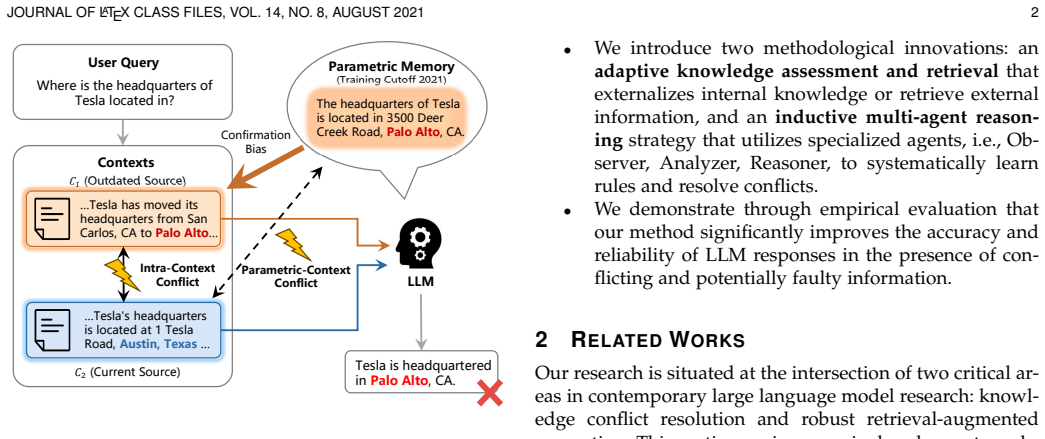
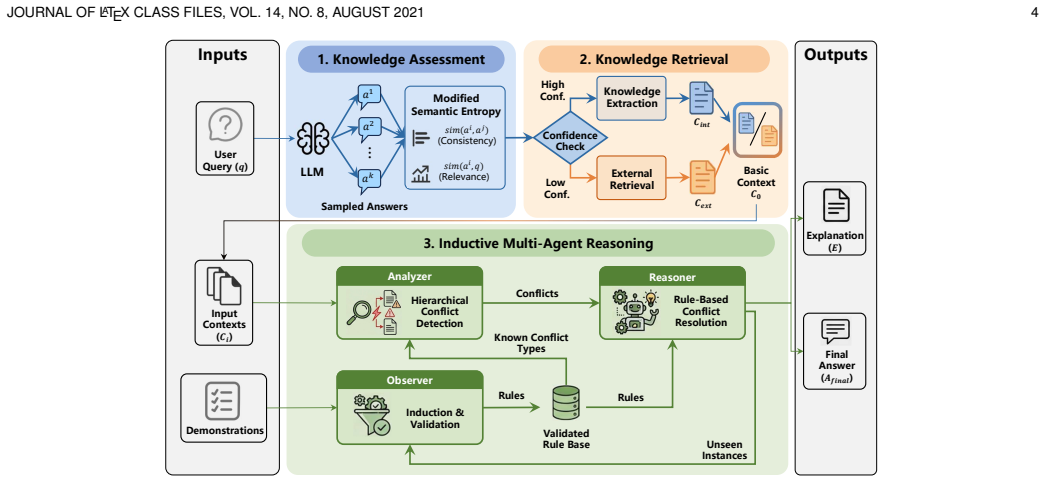
The paper claims that an adaptive knowledge assessment step based on modified semantic entropy, followed by an inductive multi-agent reasoning framework with three agents that respectively induce explicit rules, analyze potential conflicts, and resolve inconsistencies, allows LLMs to actively reconcile unreliable parametric and contextual knowledge rather than privileging one source, yielding higher performance on benchmarks and explicit, interpretable conflict resolutions.
What carries the argument
inductive multi-agent reasoning framework with three specialized agents that induce explicit rules, analyze potential conflicts, and resolve inconsistencies across contexts
If this is right
- MACR can handle cases where both the model's parametric knowledge and the provided contexts contain errors.
- The method produces interpretable resolutions of explicit conflicts rather than opaque source selection.
- Performance exceeds state-of-the-art baselines that rely on binary privileging of one knowledge source.
- The adaptive assessment step decides when internal knowledge suffices and when external retrieval is needed before multi-agent reasoning begins.
Where Pith is reading between the lines
- The three-agent structure might be extended to additional specialized agents for conflicts involving temporal or domain-specific inconsistencies.
- Embedding the conflict-resolution step inside retrieval-augmented generation pipelines could reduce downstream hallucinations when retrieved documents contradict the model.
- The approach may prove especially useful in high-stakes domains where both model weights and retrieved documents are known to be incomplete.
Load-bearing premise
The modified semantic entropy measure accurately quantifies the LLM's true confidence in its parametric answer for the given query, allowing correct decisions on whether to externalize internal knowledge or retrieve external knowledge.
What would settle it
A test set in which the modified semantic entropy indicates high confidence in an incorrect parametric answer, causing the system to discard correct external knowledge and produce an erroneous resolution.
Figures
read the original abstract
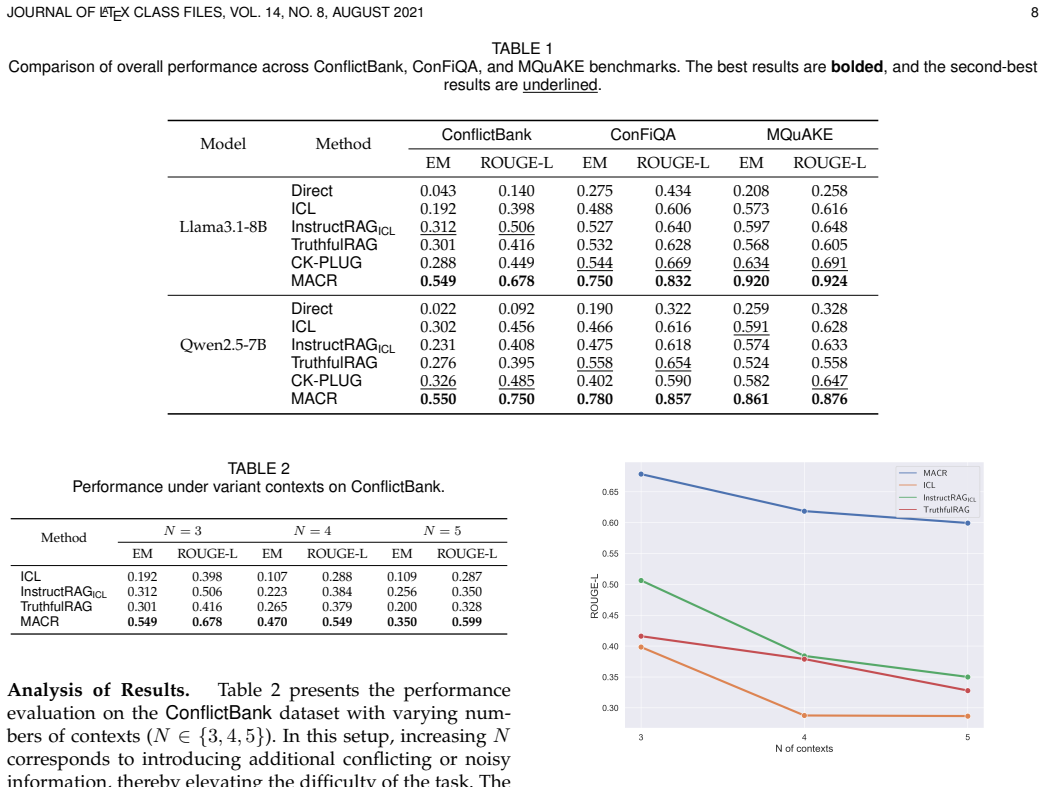
Large language models (LLMs) have achieved strong performance across a wide range of language-based tasks by leveraging both extensive parametric knowledge and in-context learning ability, enabling them to incorporate external information provided in the input prompt. However, the integration of external knowledge can introduce conflicts, not only between the model's internal parametric knowledge and the external information, but also among multiple pieces of external contexts. Existing approaches typically assume that either the model or the provided context is reliable, overlooking the possibility that both sources may contain errors, and avoid conflicts by privileging one source over the other, rather than actively resolving inconsistencies. To address these limitations, we propose a novel framework MACR for LLM knowledge conflict resolution that moves beyond the conventional binary choice paradigm and incorporates an explicit conflict-resolution mechanism based on a multi-agent reasoning approach. Specifically, we first propose an adaptive knowledge assessment and retrieval approach that employs a modified semantic entropy measure to quantify an LLM's confidence in its answer to a given query. Based on this confidence estimation, MACR either externalizes the model's internal knowledge as textual representations or retrieves relevant external knowledge when internal knowledge is insufficient, generating basic contexts for subsequent reasoning. Then we introduce an inductive multi-agent reasoning framework with three specialized agents that, respectively, induce explicit rules, analyze potential conflicts, and resolve inconsistencies across all available contexts. Empirical results demonstrate that MACR significantly outperforms state-of-the-art baselines across benchmarks, while also providing interpretable resolutions of explicit conflicts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MACR, a framework for explicit knowledge conflict resolution in LLMs. It first uses a modified semantic entropy measure in an adaptive assessment step to decide whether to externalize the model's parametric knowledge as text or retrieve external contexts when internal knowledge is deemed insufficient. This generates base contexts that are then processed by an inductive multi-agent reasoning system consisting of three specialized agents (rule induction, conflict analysis, and inconsistency resolution). The central claim is that MACR significantly outperforms state-of-the-art baselines across benchmarks while yielding interpretable explicit conflict resolutions.
Significance. If the performance gains and the reliability of the modified semantic entropy decision step hold under rigorous validation, the work could meaningfully advance LLM inference by shifting from binary privileging of parametric vs. contextual knowledge to active, multi-agent resolution of inconsistencies. The explicit multi-agent structure offers a structured path to interpretability that is absent in many retrieval-augmented or conflict-avoidance baselines.
major comments (1)
- [Adaptive knowledge assessment and retrieval approach] Adaptive knowledge assessment section: the modified semantic entropy is presented as the load-bearing mechanism for deciding whether to externalize internal knowledge or retrieve external contexts, yet the manuscript supplies no calibration of this measure against ground-truth correctness of parametric answers, no head-to-head comparison against unmodified semantic entropy or alternative uncertainty estimators, and no ablation on the decision threshold. Without these, the subsequent multi-agent stage may be operating on misclassified contexts, directly affecting both the performance and interpretability claims.
minor comments (1)
- The abstract states that MACR 'significantly outperforms state-of-the-art baselines across benchmarks' but does not name the benchmarks or report effect sizes; adding these details would strengthen the summary without altering the technical contribution.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive criticism. We respond to the major comment as follows and plan to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Adaptive knowledge assessment and retrieval approach] Adaptive knowledge assessment section: the modified semantic entropy is presented as the load-bearing mechanism for deciding whether to externalize internal knowledge or retrieve external contexts, yet the manuscript supplies no calibration of this measure against ground-truth correctness of parametric answers, no head-to-head comparison against unmodified semantic entropy or alternative uncertainty estimators, and no ablation on the decision threshold. Without these, the subsequent multi-agent stage may be operating on misclassified contexts, directly affecting both the performance and interpretability claims.
Authors: We concur that the adaptive knowledge assessment using modified semantic entropy requires more rigorous validation to substantiate its role in the framework. The manuscript as submitted does not include calibration against ground-truth, comparisons to unmodified semantic entropy or other estimators, or ablation on the threshold. To address this, we will include in the revision: (1) calibration experiments correlating the entropy measure with actual correctness on datasets with known answers, (2) head-to-head comparisons with standard semantic entropy and alternatives like token-level entropy, and (3) ablation studies varying the decision threshold to show its impact on performance and context selection. These additions will clarify the reliability of the decision step and support the overall claims. revision: yes
Circularity Check
No circularity in MACR framework derivation
full rationale
The paper introduces an empirical framework MACR that uses a modified semantic entropy measure for adaptive knowledge assessment followed by multi-agent conflict resolution. No equations, fitted parameters, or self-referential definitions appear in the abstract or description that would reduce any claimed prediction or result to its own inputs by construction. The approach relies on proposing new components and reporting empirical outperformance rather than a closed derivation chain, self-citation load-bearing premise, or ansatz smuggled through prior work. This is the common case of a self-contained empirical proposal without the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs possess distinct parametric knowledge that can be externalized as text when confidence is high.
- domain assumption Modified semantic entropy provides a faithful scalar measure of the model's answer confidence.
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P . Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W. Yih, T. Rockt ¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6...
2020
-
[2]
Available: https://proceedings.neurips.cc/paper/ 2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
[Online]. Available: https://proceedings.neurips.cc/paper/ 2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
2020
-
[3]
Resolving knowledge conflicts in large language models,
Y. Wang, S. Feng, H. Wang, W. Shi, V . Balachandran, T. He, and Y. Tsvetkov, “Resolving knowledge conflicts in large language models,”CoRR, vol. abs/2310.00935, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.00935
-
[4]
Knowledge conflicts for LLMs: A survey
R. Xu, Z. Qi, Z. Guo, C. Wang, H. Wang, Y. Zhang, and W. Xu, “Knowledge conflicts for llms: A survey,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, Y. Al-Onaizan, M. Bansal, and Y. Chen, Eds. Association for Computational Linguistics, 2024, pp. 8541–8565. [Onlin...
-
[5]
Time waits for no one! analysis and challenges of temporal misalignment,
K. Luu, D. Khashabi, S. Gururangan, K. Mandyam, and N. A. Smith, “Time waits for no one! analysis and challenges of temporal misalignment,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2022, Seattle, WA, United States, July 10-15, 2022, M. Carpuat, M...
-
[6]
Lost in the Middle: How Language Models Use Long Contexts
B. Dhingra, J. R. Cole, J. M. Eisenschlos, D. Gillick, J. Eisenstein, and W. W. Cohen, “Time-aware language models as temporal knowledge bases,”Trans. Assoc. Comput. Linguistics, vol. 10, pp. 257–273, 2022. [Online]. Available: https://doi.org/10.1162/tacl\ a\ 00459
work page internal anchor Pith review doi:10.1162/tacl 2022
-
[7]
Attacking open-domain question answering by injecting misinformation,
L. Pan, W. Chen, M. Kan, and W. Y. Wang, “Attacking open-domain question answering by injecting misinformation,” inProceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, IJCNLP 2023 -Volume 1: Long Papers, Nusa Dua, Bali, Nov...
-
[8]
Who’s who: Large language models meet knowledge conflicts in practice,
Q. Pham, H. Ngo, A. T. Luu, and D. Q. Nguyen, “Who’s who: Large language models meet knowledge conflicts in practice,” inFindings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16, 2024, Y. Al-Onaizan, M. Bansal, and Y. Chen, Eds. Association for Computational Linguistics, 2024, pp. 10 142–10 151. [Online]. ...
-
[9]
Ai as agency without intelligence: On chatgpt, large language models, and other generative models,
L. Floridi, “Ai as agency without intelligence: On chatgpt, large language models, and other generative models,”Philosophy & technology, vol. 36, no. 1, p. 15, 2023
2023
-
[10]
Adaptive contrastive decoding in retrieval-augmented generation for handling noisy contexts,
Y. Kim, H. J. Kim, C. Park, C. Park, H. Cho, J. Kim, K. M. Yoo, S. Lee, and T. Kim, “Adaptive contrastive decoding in retrieval-augmented generation for handling noisy contexts,” inFindings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16, 2024, Y. Al-Onaizan, M. Bansal, and Y. Chen, Eds. Association for Co...
-
[11]
Parameters vs. context: Fine-grained control of knowledge reliance in language models,
B. Bi, S. Liu, Y. Wang, Y. Xu, J. Fang, L. Mei, and X. Cheng, “Parameters vs. context: Fine-grained control of knowledge reliance in language models,”CoRR, vol. abs/2503.15888, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2503.15888
-
[12]
Plug-and-play adaptation for continuously-updated QA,
K. Lee, W. Han, S. Hwang, H. Lee, J. Park, and S. Lee, “Plug-and-play adaptation for continuously-updated QA,” in Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, May 22-27, 2022, S. Muresan, P . Nakov, and A. Villavicencio, Eds. Association for Computational Linguistics, 2022, pp. 438–447. [Online]. Available: https: ...
-
[13]
Z. Gekhman, J. Herzig, R. Aharoni, C. Elkind, and I. Szpektor, “Trueteacher: Learning factual consistency evaluation with large language models,” inProceedings of the 2023 Conference on JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11 Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, H. Bouamor, J. P...
-
[14]
LLM-blender: Ensembling large language models with pairwise ranking and generative fusion
W. Zhou, S. Zhang, H. Poon, and M. Chen, “Context-faithful prompting for large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, 2023, pp. 14 544– 14 556. [Online]. Available: https://doi.org/10.18653/v...
-
[15]
B. Xue, W. Wang, H. Wang, F. Mi, R. Wang, Y. Wang, L. Shang, X. Jiang, Q. Liu, and K. Wong, “Improving factual consistency for knowledge-grounded dialogue systems via knowledge enhancement and alignment,” inFindings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Associat...
-
[16]
Yu and Sanjiv Kumar , editor =
D. Li, A. S. Rawat, M. Zaheer, X. Wang, M. Lukasik, A. Veit, F. X. Yu, and S. Kumar, “Large language models with controllable working memory,” inFindings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. Association for Computational Linguistics, 2023, pp. 1774–...
-
[17]
Trusting Your Evidence: Hallucinate Less with Context-aware Decoding
W. Shi, X. Han, M. Lewis, Y. Tsvetkov, L. Zettlemoyer, and W. Yih, “Trusting your evidence: Hallucinate less with context-aware decoding,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Short Papers, NAACL 2024, Mexico City, Mexico, June 16-21, 2024, K. Duh,...
-
[18]
IRCAN: mitigating knowledge conflicts in LLM generation via identifying and reweighting context-aware neurons,
D. Shi, R. Jin, T. Shen, W. Dong, X. Wu, and D. Xiong, “IRCAN: mitigating knowledge conflicts in LLM generation via identifying and reweighting context-aware neurons,” in Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, A. Glo...
2024
-
[19]
Defending against disinformation attacks in open-domain question answering,
O. Weller, A. Khan, N. Weir, D. J. Lawrie, and B. V . Durme, “Defending against disinformation attacks in open-domain question answering,” inProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2024 - Volume 2: Short Papers, St. Julian’s, Malta, March 17-22, 2024, Y. Graham and M. Purver, Eds. A...
2024
-
[20]
R. Xu, B. S. Lin, S. Yang, T. Zhang, W. Shi, T. Zhang, Z. Fang, W. Xu, and H. Qiu, “The earth is flat because...: Investigating llms’ belief towards misinformation via persuasive conversation,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024,...
-
[21]
On the Risk of Misinformation Pollution with Large Language Models
Y. Pan, L. Pan, W. Chen, P . Nakov, M. Kan, and W. Y. Wang, “On the risk of misinformation pollution with large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, 2023, pp. 1389–1403. [Online]. Available...
-
[22]
G. Hong, J. Kim, J. Kang, S. Myaeng, and J. J. Whang, “Why so gullible? enhancing the robustness of retrieval- augmented models against counterfactual noise,” inFindings of the Association for Computational Linguistics: NAACL 2024, Mexico City, Mexico, June 16-21, 2024, K. Duh, H. G ´omez- Adorno, and S. Bethard, Eds. Association for Computational Linguis...
-
[23]
Taming knowledge conflicts in language models,
G. Li, Y. Chen, and H. Tong, “Taming knowledge conflicts in language models,”CoRR, vol. abs/2503.10996, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2503.10996
-
[24]
F. Cuconasu, G. Trappolini, F. Siciliano, S. Filice, C. Campagnano, Y. Maarek, N. Tonellotto, and F. Silvestri, “The power of noise: Redefining retrieval for RAG systems,” inProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18, 2024, G. H. Yang, H. Wang,...
-
[25]
Rethinking relevance: How noise and distractors impact retrieval-augmented generation,
——, “Rethinking relevance: How noise and distractors impact retrieval-augmented generation,” inProceedings of the 14th Italian Information Retrieval Workshop, Udine, Italy, September 5-6, 2024, ser. CEUR Workshop Proceedings, K. Roitero, M. Viviani, E. Maddalena, and S. Mizzaro, Eds., vol
2024
-
[26]
CEUR-WS.org, 2024, pp. 95–98. [Online]. Available: https://ceur-ws.org/Vol-3802/paper23.pdf
2024
-
[27]
Faithfulrag: Fact-level conflict modeling for context-faithful retrieval-augmented generation,
Q. Zhang, Z. Xiang, Y. Xiao, L. Wang, J. Li, X. Wang, and J. Su, “Faithfulrag: Fact-level conflict modeling for context-faithful retrieval-augmented generation,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, W. Che, J. Nabende, E. Shut...
2025
-
[28]
S. Liu, Y. Shang, and X. Zhang, “Truthfulrag: Resolving factual- level conflicts in retrieval-augmented generation with knowledge graphs,”CoRR, vol. abs/2511.10375, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2511.10375
-
[29]
Corrective Retrieval Augmented Generation
S. Yan, J. Gu, Y. Zhu, and Z. Ling, “Corrective retrieval augmented generation,”CoRR, vol. abs/2401.15884, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.15884
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.15884 2024
-
[30]
Instructrag: Instructing retrieval- augmented generation via self-synthesized rationales,
Z. Wei, W. Chen, and Y. Meng, “Instructrag: Instructing retrieval- augmented generation via self-synthesized rationales,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. [Online]. Available: https://openreview.net/forum?id=P1qhkp8gQT
2025
-
[31]
S. Liu, Y. Shang, and X. Zhang, “Truthfulrag: Resolving factual-level conflicts in retrieval-augmented generation with knowledge graphs,” inFortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Artificial Intelligence, Sixteenth Symposium on Educational Advances in Artificial Intelligence, AAAI 2026, S...
-
[32]
J. Chen, B. Bi, W. Zhang, J. Sui, X. Zhu, Y. Wang, L. Mei, and S. Liu, “Rethinking all evidence: Enhancing trustworthy retrieval-augmented generation via conflict-driven summarization,”CoRR, vol. abs/2507.01281, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2507.01281
-
[33]
Detecting hallucinations in large language models using semantic entropy , volume =
S. Farquhar, J. Kossen, L. Kuhn, and Y. Gal, “Detecting hallucinations in large language models using semantic entropy,” Nat., vol. 630, no. 8017, pp. 625–630, 2024. [Online]. Available: https://doi.org/10.1038/s41586-024-07421-0
-
[34]
Beyond semantic entropy: Boosting LLM uncertainty quantification with pairwise semantic similarity,
D. Nguyen, A. Payani, and B. Mirzasoleiman, “Beyond semantic entropy: Boosting LLM uncertainty quantification with pairwise semantic similarity,” inFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Association for Computational Linguistic...
2025
-
[35]
Conflictbank: A benchmark for evaluating the influence of knowledge conflicts in llms,
Z. Su, J. Zhang, X. Qu, T. Zhu, Y. Li, J. Sun, J. Li, M. Zhang, and Y. Cheng, “Conflictbank: A benchmark for evaluating the influence of knowledge conflicts in llms,” inAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, A. Globe...
2024
-
[36]
Context-dpo: Aligning language models for context- faithfulness,
B. Bi, S. Huang, Y. Wang, T. Yang, Z. Zhang, H. Huang, L. Mei, J. Fang, Z. Li, F. Wei, W. Deng, F. Sun, Q. Zhang, and S. Liu, “Context-dpo: Aligning language models for context- faithfulness,” inFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar...
2025
-
[37]
Mquake: Assessing knowledge editing in language models via multi-hop questions,
Z. Zhong, Z. Wu, C. D. Manning, C. Potts, and D. Chen, “Mquake: Assessing knowledge editing in language models via multi-hop questions,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, 2023...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.