How Inference Compute Shapes Frontier LLM Evaluation
Pith reviewed 2026-06-27 00:59 UTC · model grok-4.3
The pith
Fixed low-budget evaluations increasingly understate the capabilities of advancing frontier LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
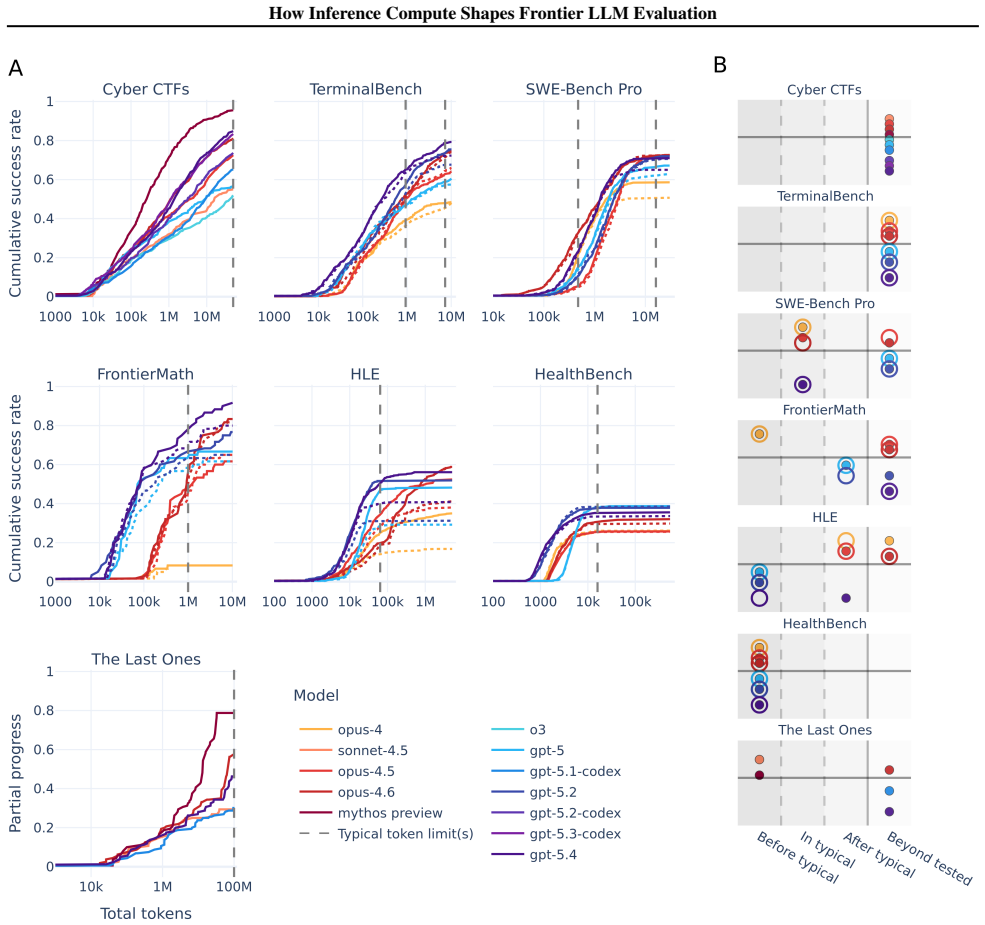
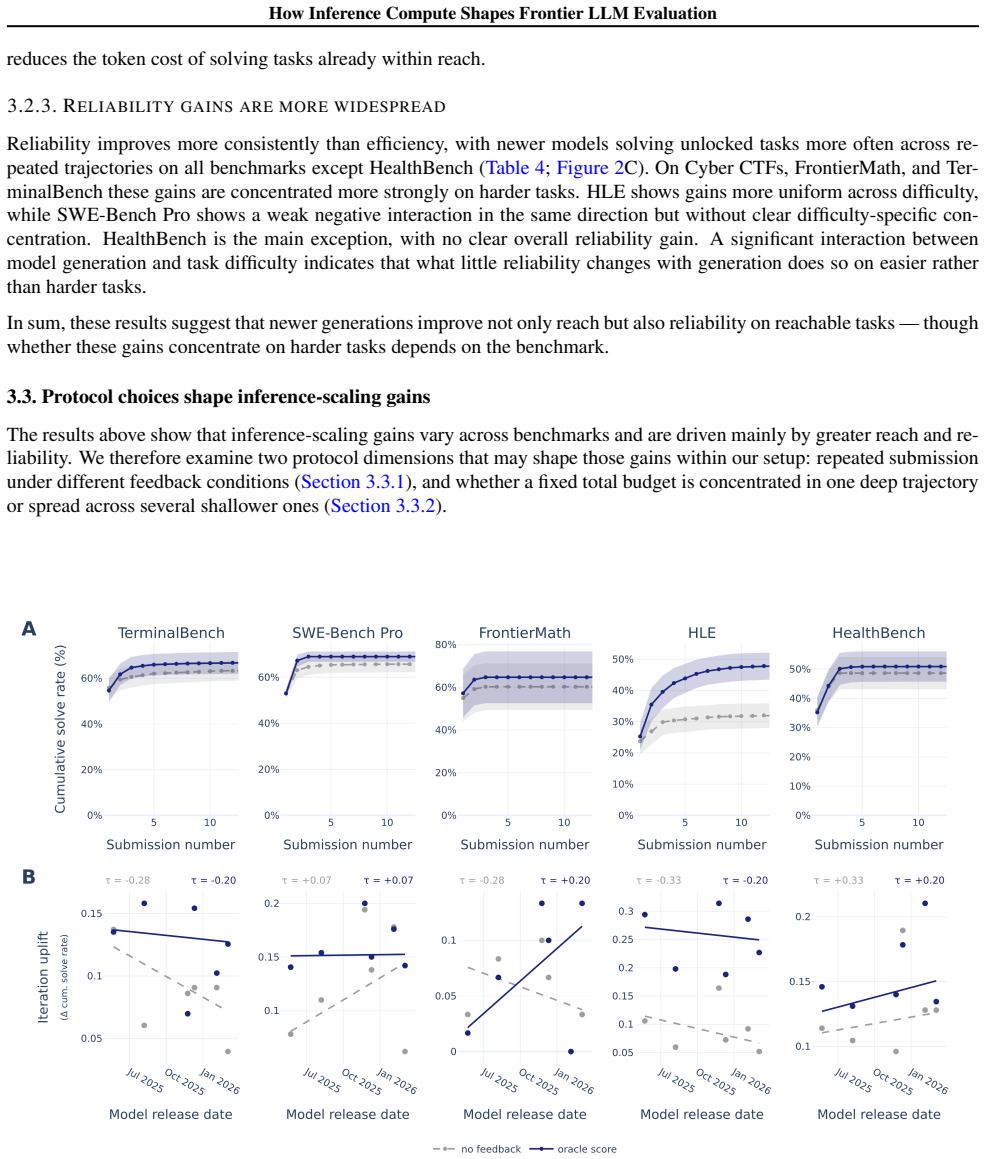
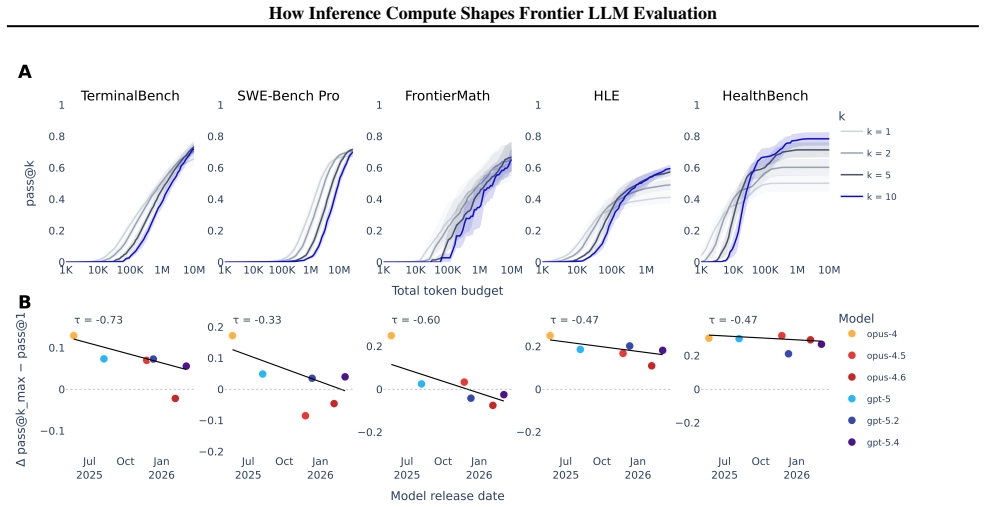
Larger token budgets substantially improve performance on benchmarks across multiple domains. Fixed-budget evaluations can increasingly understate frontier capability as models advance, with newer models reaching higher performance at large budgets where they unlock harder tasks and solve them more reliably. Benchmarks differ in which inference-scaling methods help most, but repeated submission broadly improves results while the value of larger budgets and external feedback varies by task.
What carries the argument
Three inference-scaling interventions (larger token budgets, context compaction, and repeated submission attempts guided by the model or minimal correctness feedback) that vary the amount of compute available during evaluation.
If this is right
- Newer models benefit more from increased inference compute than older models on the tested benchmarks.
- Benchmark scores become more comparable when models are evaluated over a shared range of compute budgets at matched levels.
- Evaluations should report performance explicitly as a function of inference-time compute rather than at a single restrictive budget.
- Protocol choices such as token limits and retry rules must be stated clearly because they affect which models appear strongest.
Where Pith is reading between the lines
- Safety and policy evaluations that use fixed budgets may miss capabilities that appear only at higher inference compute.
- Capability trends across model generations could look different if future comparisons standardize on high rather than low compute protocols.
- Benchmarks could evolve to include adaptive compute allocation as a built-in feature instead of a post-hoc adjustment.
Load-bearing premise
The three inference-scaling interventions isolate the effect of inference compute without introducing new biases or changing the underlying task distribution.
What would settle it
Newer models show no additional performance gains over older models when all are given the same large token budgets on the same benchmarks.
Figures

read the original abstract
AI evaluations are shifting toward harder tasks that benefit from longer trajectories involving tool use and iterative problem solving. As a result, performance is increasingly sensitive to the amount and allocation of compute available at test time ("inference compute"). Yet many evaluations still report performance at a single restrictive budget, meaning that low scores may reflect the evaluation setup rather than the model's underlying capability. To test this, we evaluate up to 12 frontier language models on seven challenging benchmarks spanning software engineering, mathematics, medicine, and cybersecurity. We use a controlled setup combining three simple inference-scaling interventions: larger token budgets, context compaction, and repeated submission attempts, guided either by the model itself or by minimal correctness feedback. We find three main results. First, larger token budgets substantially improve performance on benchmarks across multiple domains, including cybersecurity, FrontierMath, Humanity's Last Exam, and TerminalBench. Second, fixed-budget evaluations can increasingly understate frontier capability as models advance. Newer models reach higher performance at large budgets, where they unlock harder tasks and solve them more reliably. Third, benchmarks differ in which inference-scaling methods help most: repeated submission broadly improves performance, but the value of larger token budgets, external feedback, and parallel attempts varies by benchmark. Overall, our results show that benchmark scores are protocol-dependent. We therefore argue that evaluations should report capability as a function of inference-time compute, specify protocol choices explicitly, and compare model generations over a large shared compute range at matched budgets, especially in safety- or policy-relevant settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that AI benchmark performance is increasingly sensitive to inference-time compute, such that fixed single-budget evaluations understate frontier LLM capabilities as models advance. Using a controlled design with 12 models on 7 benchmarks (software engineering, mathematics, medicine, cybersecurity), the authors apply three interventions—larger token budgets, context compaction, and repeated submissions (model-guided or with minimal correctness feedback)—and report that larger budgets yield substantial gains across domains, newer models benefit disproportionately at high budgets by unlocking harder tasks and solving more reliably, and the value of each scaling method varies by benchmark. They conclude that evaluations should report performance as a function of inference compute and compare models at matched budgets.
Significance. If the central empirical results hold after addressing protocol confounds, the work provides a broad, multi-domain demonstration that benchmark scores are protocol-dependent and that capability should be characterized over compute ranges rather than single points. This has direct implications for safety- and policy-relevant evaluations. The controlled experimental design spanning 12 models and 7 benchmarks is a strength, as is the explicit call for matched-budget comparisons.
major comments (2)
- [Abstract (interventions paragraph)] Abstract (interventions paragraph): The repeated-submission condition that supplies 'minimal correctness feedback' introduces an external oracle signal unavailable under standard single-pass or model-only iterative protocols. This alters the effective task distribution and risks confounding the isolation of inference-compute effects; the manuscript must provide ablations or controls (e.g., comparing model-guided vs. feedback-guided runs at matched budgets) to show that observed differential gains for newer models are not driven by exploitation of the feedback signal.
- [Abstract (second main result)] Abstract (second main result): The claim that 'newer models reach higher performance at large budgets, where they unlock harder tasks and solve them more reliably' is load-bearing for the policy recommendation. Without explicit metrics of task difficulty (e.g., per-task success rates stratified by difficulty) or reliability (e.g., variance across attempts) reported in the results, and without separating the feedback condition, the interpretation that gains reflect genuine capability increases rather than protocol changes remains under-supported.
minor comments (2)
- Provide the exact operational definition and implementation details of 'minimal correctness feedback' (e.g., binary pass/fail vs. partial credit) and confirm it does not leak additional task information beyond what is stated.
- List all model versions, benchmark versions, and exact token-budget ranges used, together with any reproducibility artifacts (code, prompts, or data tables), to allow independent verification of the controlled setup.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The concerns about potential confounding from the feedback condition and the need for stronger support for claims regarding newer models' advantages at scale are well-taken. We address each point below and commit to revisions that strengthen the isolation of effects and the evidentiary basis for our interpretations.
read point-by-point responses
-
Referee: [Abstract (interventions paragraph)] Abstract (interventions paragraph): The repeated-submission condition that supplies 'minimal correctness feedback' introduces an external oracle signal unavailable under standard single-pass or model-only iterative protocols. This alters the effective task distribution and risks confounding the isolation of inference-compute effects; the manuscript must provide ablations or controls (e.g., comparing model-guided vs. feedback-guided runs at matched budgets) to show that observed differential gains for newer models are not driven by exploitation of the feedback signal.
Authors: We agree that the minimal-correctness-feedback condition supplies an external signal and that this must be isolated to support claims about inference-compute scaling. The manuscript already reports results for both model-guided and feedback-guided repeated submissions as distinct conditions. To directly address the concern, we will add matched-budget ablations in the revision that compare the two guidance regimes head-to-head for each model and benchmark, quantifying any differential gains attributable to the feedback signal alone. revision: yes
-
Referee: [Abstract (second main result)] Abstract (second main result): The claim that 'newer models reach higher performance at large budgets, where they unlock harder tasks and solve them more reliably' is load-bearing for the policy recommendation. Without explicit metrics of task difficulty (e.g., per-task success rates stratified by difficulty) or reliability (e.g., variance across attempts) reported in the results, and without separating the feedback condition, the interpretation that gains reflect genuine capability increases rather than protocol changes remains under-supported.
Authors: We acknowledge that the current presentation relies on aggregate performance curves rather than explicit per-task difficulty stratification or reliability statistics, and that the feedback condition is not fully separated in every reported comparison. In the revision we will (i) add task-difficulty stratification where benchmark metadata permit, (ii) report attempt-to-attempt variance as a reliability metric, and (iii) replicate the key scaling comparisons using only the model-guided condition. These additions will allow readers to evaluate whether the reported advantages for newer models persist under stricter controls. revision: yes
Circularity Check
Empirical measurement study with no circular derivation
full rationale
The paper is an empirical evaluation of frontier LLMs on benchmarks under controlled inference-scaling protocols (larger token budgets, context compaction, repeated submissions). No mathematical derivations, fitted parameters, or self-citation chains are present that reduce reported performance scores to quantities defined by the inputs. All results derive directly from observed model outputs on the stated tasks, with no equations or ansatzes that equate predictions to fitted inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Benchmarks remain valid measures of capability when inference protocols change
- domain assumption Minimal correctness feedback does not leak task solution information beyond what the model could generate
Reference graph
Works this paper leans on
-
[2]
URLhttps://www.governance.ai/research-paper/ inference-scaling-and-ai-governance. Yoshua Bengio, Stephen Clare, Carina Prunkl, Shalaleh Rismani, Maksym Andriushchenko, Ben Bucknall, Philip Fox, Tiancheng Hu, Cameron Jones, Sam Manning, Nestor Maslej, Vasilios Mavroudis, Conor McGlynn, Malcolm Murray, Charlotte Stix, Lucia Velasco, Nicole Wheeler, Daniel P...
2025
-
[3]
Claude mythos preview cyber capabilities.https://www.aisi.gov.uk/blog/ our-evaluation-of-claude-mythos-previews-cyber-capabilities, 2026a
UK AI Security Institute. Claude mythos preview cyber capabilities.https://www.aisi.gov.uk/blog/ our-evaluation-of-claude-mythos-previews-cyber-capabilities, 2026a. Accessed 2026-04-
2026
-
[4]
UK AI Security Institute. Evidence for inference scaling in AI cyber tasks.https://www.aisi.gov.uk/blog/ evidence-for-inference-scaling-in-ai-cyber-tasks-increased-evaluation-budgets-reveal-higher-success-rates, 2026b. Accessed 2026-04-22. Meta Superintelligence Labs. Muse spark safety & preparedness report. Technical report, Meta,
2026
-
[5]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Cand`es, and Tatsunori Hashimoto
URL https://epoch.ai/blog/mirrorcode-preliminary-results. Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Cand`es, and Tatsunori Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Processing (EMNLP),
2025
-
[6]
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese
Accessed 2026- 04-22. Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. BrowseComp: A simple yet challenging benchmark for browsing agents
2026
-
[7]
Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, and Jiecao Chen
URLhttps:// metr.org/notes/2026-02-13-measuring-time-horizon-using-claude-code-and-codex/. Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, and Jiecao Chen. Scaling long-horizon LLM agent via context-folding
2026
-
[8]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
-
[9]
doi: 10.1038/s41586-025-09962-4. UK AI Security Institute. How fast is autonomous AI cyber capability advancing?https://www.aisi.gov.uk/ blog/how-fast-is-autonomous-ai-cyber-capability-advancing, 2026c. Accessed 2026-05-15. Vidhisha Balachandran, Jingya Chen, Lingjiao Chen, Shivam Garg, Neel Joshi, Yash Lara, John Langford, Besmira Nushi, Vibhav Vineet, Y...
work page internal anchor Pith review doi:10.1038/s41586-025-09962-4 2026
-
[10]
Microsoft Research, MSR-TR-2025-16. Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Qui ˜nonero Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. HealthBench: Evaluating large language models towards improved human health
2025
-
[11]
URL https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/. METR. Time horizon 1.1. METR blog, January
2025
-
[12]
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou
URLhttps://metr.org/blog/ 2026-1-29-time-horizon-1-1/. Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. InInternational Conference on Learning Representations (ICLR),
2026
-
[13]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
-
[14]
The registry ships two prompt variants per task, 1,462 samples across 731 unique instances
via the inspect harborregistry. The registry ships two prompt variants per task, 1,462 samples across 731 unique instances. For comparability with published baselines, we keep a single variant per task, the SWE-bench-format variant whose input begins with <uploaded files>, yielding 731 unique problems. A canonical subset of the first 100 problems is drawn...
2024
-
[15]
Answer:” or “Exact Answer:
via its inspect evalswrapper. We filter the dataset to exact-match questions only, identified by the presence of the phrase “Answer:” or “Exact Answer:” in the sample’s system message, excluding multiple-choice questions that would otherwise allow an iterative agent to guess its way to the correct answer. Grading is performed by an LLM judge, GPT-4o-mini ...
2026
-
[16]
Google DeepMind Gemini 3.1 Pro model card system card 2026- 05? — — — — — — TerminalBench 2.0 (tbench.ai,
2026
-
[17]
tbench.ai leaderboard submission rules leaderboard 2026- 05? — — per-task (benchmark default; not modifiable) 1 — 5 TerminalBench 2.0 (Anthropic,
2026
-
[18]
Claude Mythos Preview release (Glasswing) blog post 2026- 04? 1M per task — per-task (benchmark default; up to 4h on TB 2.1) 1 — 5 TerminalBench 2.0 (Anthropic, 2026b) Claude Opus 4.7 announcement blog post 2026- 04? — — per-task (benchmark default) 1 — 5 TerminalBench 2.0 (Anthropic, 2026c) Claude Sonnet 4.6 system card, section 2.3 system card 2026- 04?...
2026
-
[19]
Terminal-Bench 2.0 paper, Appendices A & F (Terminus-2 harness) preprint 2026- 01 no cap no hard cap per-task (default ˜6 min, max 2h) 1 — 5 SWE-Bench Pro (LLM-Stats,
2026
-
[20]
LLM-Stats SWE-Bench Pro leaderboard leaderboard 2026- 05 — — — — — — SWE-Bench Pro (public) (Scale AI,
2026
-
[21]
Scale SEAL leaderboard leaderboard 2026- 05 — 50–250 — 1 — 1 SWE-Bench Pro (public) (Team, 2026a) Alibaba Qwen 3.6 Max Preview launch blog post 2026- 04 — — — — — — SWE-Bench Pro (public) (Team, 2026b) Alibaba Qwen 3.6 Plus report blog post 2026- 04 — — — — — — SWE-Bench Pro (public) (Anthropic,
2026
-
[22]
Benchmark Citation Source title Source type Date Token limit Turn cap Time limit Submissions / traj
Anthropic Claude Mythos Preview (Project Glasswing) blog post 2026- 04 — — — — — — continued on next page 22 How Inference Compute Shapes Frontier LLM Evaluation Table 8 continued. Benchmark Citation Source title Source type Date Token limit Turn cap Time limit Submissions / traj. Cost cap Independent traj. / task SWE-Bench Pro (public) (Anthropic, 2026b)...
2026
-
[23]
Augment Auggie blog (Opus 4.5 on Auggie) blog post 2026- 04 — — — — — — SWE-Bench Pro (public) (Blitzy,
2026
-
[24]
Blitzy SWE-Bench Pro audit blog post 2026- 04 — — — 1 — — SWE-Bench Pro (public) (Cursor,
2026
-
[25]
Cursor Composer 2 release blog post 2026- 04 — — — — — — SWE-Bench Pro (public) (MiniMax,
2026
-
[26]
MiniMax M2.7 launch blog post 2026- 04 — — — — — — SWE-Bench Pro (public) (Moonshot AI,
2026
-
[27]
Moonshot Kimi K2.6 tech blog blog post 2026- 04 — — — — — — SWE-Bench Pro (public) (Labs,
2026
-
[28]
Morph WarpGrep v2 self-reported blog post 2026- 04 — — — — — — SWE-Bench Pro (public) (Zhipu AI,
2026
-
[29]
Zhipu GLM-5.1 release (Z.ai) blog post 2026- 04 32k output — — — — — SWE-Bench Pro (public) (DeepMind,
2026
-
[30]
Google DeepMind Gemini 3.1 Pro model card system card 2026- 03 — — — 1 — 1 SWE-Bench Pro (public) (OpenAI, 2026a) OpenAI GPT-5.4 release blog post 2026- 03 — — — — — — SWE-Bench Pro (public) (Anthropic, 2026d) Anthropic Claude Opus 4.6 release blog post 2026- 02 — — — — — — SWE-Bench Pro (public) (OpenAI, 2026b) OpenAI GPT-5.3-Codex release blog post 2026...
2026
-
[31]
Windsurf/Cognition SWE-1.5 launch blog post 2025- 10 — — — — — — SWE-Bench Pro (public, commercial) (Deng et al.,
2025
-
[32]
SWE-Bench Pro paper preprint 2025- 09 — 50 — 1 $2 1 FrontierMath (tier
2025
-
[33]
Epoch AI substack (GPT-5.2 Pro Tier 4 record) blog post 2026- 01 — — — — — 1 FrontierMath (tiers 1-3) (OpenAI, 2025a) OpenAI GPT-5.2 announcement (science & math) blog post 2025- 12 — — — 1 — 1 FrontierMath (full) (Anthropic,
2026
-
[34]
Anthropic Claude Opus 4.5 announcement blog post 2025- 11 — — — — — — FrontierMath (tiers 1-3) (Burnham,
2025
-
[35]
Benchmark Citation Source title Source type Date Token limit Turn cap Time limit Submissions / traj
Epoch AI 1M-token scaffold sweep (Burnham) blog post 2025- 11 1M — 30s/tool call 1 — 32 FrontierMath (tiers 1-3) (Epoch AI, 2025a) Epoch AI X post (Gemini 3 Pro) blog post 2025- 11 1M — 30s/tool call 1 — 1 continued on next page 23 How Inference Compute Shapes Frontier LLM Evaluation Table 8 continued. Benchmark Citation Source title Source type Date Toke...
2025
-
[36]
(Epoch AI, 2025e) Epoch AI Tier 4 benchmark page leaderboard 2025- 07 1M — 30s/tool call 1 — 1 FrontierMath (tiers 1-3) (Epoch AI, 2025f) Epoch AI scaffold v1.0 (o4-mini eval) blog post 2025- 04 100k — 30s/tool call 1 — 1 FrontierMath (tiers 1-3) (Epoch AI, 2025g) Epoch AI scaffold v1.0 (o3-mini era) blog post 2025- 03 100k — 30s/tool call 1 — 1 FrontierM...
2025
-
[37]
FrontierMath paper (Glazer et al.) preprint 2024- 11 10k conversation — — 1 — 1 HealthBench (full) (OpenAI, 2026d) GPT-5.4 Thinking system card system card 2026- 03 — — — 1 — — HealthBench (full, Hard) (OpenAI, 2025b) GPT-5.2 system card, Section 3.6 system card 2025- 12 — — — 1 — — HealthBench (full, Hard, Consensus) (OpenAI, 2025c) GPT-5 system card sys...
2024
-
[38]
HealthBench paper preprint 2025- 05 4096 output, 16k output, 9k output — — 1 — — HLE (text-only) (Scale AI,
2025
-
[39]
Scale SEAL HLE text-only leaderboard methodology leaderboard 2026- 05 — — — 1 — — HLE (full) (Scale AI, 2026b) Scale SEAL HLE leaderboard methodology leaderboard 2026- 05 — — — 1 — — HLE (full) (DeepMind, 2025a) Google Gemini 3 launch blog post 2025- 11 — — — 1 — — HLE (full) (DeepMind, 2025b) Google Gemini 3 Deep Think blog blog post 2025- 11 — — — 1 — —...
2026
-
[40]
Kimi K2 Thinking system card 2025- 11 96k thinking, 48k per step 120 — 1 — 8 HLE (full) (OpenAI, 2025d) OpenAI GPT-5 system card system card 2025- 08 — — — 1 — — HLE (text-only) (xAI,
2025
-
[41]
xAI Grok 4 blog post 2025- 07 — — — 1 — 4 HLE (full) (OpenAI, 2025e) OpenAI Deep Research launch blog post 2025- 02 — — — 1 — — HLE (full, text-only) (Phan et al.,
2025
-
[42]
Benchmark Citation Source title Source type Date Token limit Turn cap Time limit Submissions / traj
HLE preprint 2025- 01 8192 output — — 1 — — continued on next page 24 How Inference Compute Shapes Frontier LLM Evaluation Table 8 continued. Benchmark Citation Source title Source type Date Token limit Turn cap Time limit Submissions / traj. Cost cap Independent traj. / task Cyber CTFs (apprentice tier, practitioner/ex- pert tier) (UK AI Security Institu...
2025
-
[43]
Folkerts et al. 2026, Appendix D (AISI CTF suite) preprint 2026- 03 — — — — — 10 Cyber CTFs (47 challenges) (UK AI Security Institute, 2024a) AISI pre-deployment eval of OpenAI o1 blog post 2024- 12 — — — — — — Cyber CTFs (47 challenges) (UK AI Security Institute, 2024b) AISI pre-deployment eval of Claude 3.5 Sonnet (upgraded) blog post 2024- 10 — — — — —...
2026
-
[44]
2026, Table 1 preprint 2026- 03 10M–100M — — — ˜$80 5–10 Google DeepMind
Folkerts et al. 2026, Table 1 preprint 2026- 03 10M–100M — — — ˜$80 5–10 Google DeepMind. Gemini 3.1 pro model card.https://deepmind.google/models/model-cards/gemini-3-1-pro/,
2026
-
[45]
tbench.ai
Accessed 2026-04-22. tbench.ai. tbench.ai leaderboard.https://www.tbench.ai/leaderboard/terminal-bench/2.0,
2026
-
[46]
Anthropic
Accessed 2026-04-22. Anthropic. Claude mythos preview release.https://www.anthropic.com/glasswing, 2026a. Accessed 2026-04-22. Anthropic. Claude opus 4.7 release.https://www.anthropic.com/news/claude-opus-4-7, 2026b. Accessed 2026-04-22. Anthropic. Claude sonnet 4.6 system card.https://www-cdn.anthropic.com/bbd8ef16d70b7a1665f14f306ee88b53f686aa75.pdf, 20...
2026
-
[47]
Scale AI
Accessed 2026-04-22. Scale AI. SEAL leaderboards: SWE-Bench Pro public. Scale Labs leaderboard, 2026a. URLhttps://labs.scale.com/leaderboard/swe_bench_pro_public. Accessed April
2026
-
[48]
Qwen 3.6 max preview launch.https://qwen.alibaba.com/, 2026a
Alibaba Qwen Team. Qwen 3.6 max preview launch.https://qwen.alibaba.com/, 2026a. Accessed 2026-04-22. Alibaba Qwen Team. Qwen 3.6 plus report.https://www.alibabacloud.com/blog/qwen3-6-plus-towards-real-world-agents_603005, 2026b. Ac- cessed 2026-04-22. Augment. Auggie tops SWE-Bench Pro (self-reported).https://www.augmentcode.com/blog/auggie-tops-swe-bench-pro,
2026
-
[49]
Accessed 2026-04-22. Blitzy. Record on SWE-Bench Pro (audit via quesma).https://blitzy.com/blog/blitzy-scores-a-record-66-5-on-swe-bench-pro,
2026
-
[50]
Accessed 2026-04-22. Cursor. Composer 2 release.https://cursor.com/blog/composer-2,
2026
-
[51]
Accessed 2026-04-22. MiniMax. M2.7 launch (self-reported).https://www.minimax.io/news/minimax-m27-en,
2026
-
[52]
Moonshot AI
Accessed 2026-04-22. Moonshot AI. Kimi k2.6 tech blog.https://www.kimi.com/blog/kimi-k2-6,
2026
-
[53]
Morph Labs
Accessed 2026-04-22. Morph Labs. Warpgrep v2 self-report.https://www.morphllm.com/swe-bench-pro,
2026
-
[54]
Zhipu AI
Accessed 2026-04-22. Zhipu AI. GLM-5.1 release.https://docs.z.ai/guides/llm/glm-5,
2026
-
[55]
Accessed 2026-04-22. OpenAI. GPT-5.2 release (self-reported).https://openai.com/index/introducing-gpt-5-2/, 2026c. Accessed 2026-04-22. Windsurf. SWE-1.5 launch.https://windsurf.com/blog/swe-1-5,
2026
-
[56]
Accessed 2026-04-22. Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. SWE-Bench Pro: Can AI...
2026
-
[57]
Accessed 2026-04-22. OpenAI. GPT-5.2 for science and math.https://openai.com/index/gpt-5-2-for-science-and-math/, 2025a. Accessed 2026-04-22. Anthropic. Claude opus 4.5 announcement.https://www.anthropic.com/news/claude-opus-4-5,
2026
-
[58]
Greg Burnham
Accessed 2026-04-22. Greg Burnham. Less than 70% of FrontierMath is within reach for today’s models. Epoch AI, Gradient Updates, October
2026
-
[59]
URLhttps://epoch.ai/ gradient-updates/less-than-70-percent-of-frontiermath-is-within-reach-for-todays-models. Epoch AI. X post: Gemini 3 on FrontierMath.https://x.com/EpochAIResearch/status/1991945942174761050, 2025a. Accessed 2026-04-22. Epoch AI. FrontierMath benchmarks page (GPT-5.1 era).https://epoch.ai/benchmarks/frontiermath, 2025b. Accessed 2026-04...
arXiv 2026
-
[60]
GPT-5.4 thinking system card.https://deploymentsafety.openai.com/gpt-5-4-thinking, 2026d
OpenAI. GPT-5.4 thinking system card.https://deploymentsafety.openai.com/gpt-5-4-thinking, 2026d. Accessed 2026-04-22. OpenAI. GPT-5.2 system card.https://cdn.openai.com/pdf/3a4153c8-c748-4b71-8e31-aecbde944f8d/oai_5_2_system-card.pdf, 2025b. Accessed 2026-04-22. OpenAI. GPT-5 system card.https://cdn.openai.com/gpt-5-system-card.pdf, 2025c. Accessed 2026-...
2026
-
[61]
Scale AI
Accessed 2026-04-22. Scale AI. SEAL HLE leaderboard.https://labs.scale.com/leaderboard/humanitys_last_exam, 2026b. Accessed 2026-04-22. Google DeepMind. Gemini 3 launch.https://blog.google/products-and-platforms/products/gemini/gemini-3/, 2025a. Accessed 2026-04-22. Google DeepMind. Gemini 3 deep think.https://blog.google/innovation-and-ai/models-and-rese...
2026
-
[62]
Accessed 2026-04-22. OpenAI. GPT-5 announcement.https://openai.com/index/introducing-gpt-5/, 2025d. Accessed 2026-04-22. 26 How Inference Compute Shapes Frontier LLM Evaluation xAI. Grok 4 launch (grok 4 and grok 4 heavy).https://x.ai/news/grok-4,
2026
-
[63]
Accessed 2026-04-22. OpenAI. Deep research announcement.https://openai.com/index/introducing-deep-research/, 2025e. Accessed 2026-04-22. Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, et al. Humanity’s last exam
2026
-
[64]
arXiv:2501.14249. UK AI Security Institute. Evidence for inference scaling in AI cyber tasks.https://www.aisi.gov.uk/blog/evidence-for-inference-scaling-in-ai-cyber-tasks-increased-evaluation-budgets-reveal-higher-success-rates, 2026a. Accessed 2026-04-22. UK AI Security Institute. Claude mythos preview cyber capabilities.https://www.aisi.gov.uk/blog/our-...
Pith/arXiv arXiv 2026
-
[65]
Your submission was scored. You achievedXout ofYpossible points
AI Security Institute and Irregular. UK AI Security Institute. Pre-deployment evaluation of openai o1.https://www.aisi.gov.uk/blog/pre-deployment-evaluation-of-openais-o1-model, 2024a. Accessed 2026-04-22. UK AI Security Institute. Pre-deployment evaluation of upgraded claude 3.5 sonnet.https://www.aisi.gov.uk/blog/ pre-deployment-evaluation-of-anthropics...
2026
-
[66]
= logit−1 αs(i) +β OOi +β GGi +β G×O(GiOi) ,(6) whereY i is an indicator for eventual success andα s(i) is a task fixed effect. Benchmarkβ O [95% CI]β G [95% CI]β G×O [95% CI] FrontierMath−0.034[−0.353,+0.284]+2.851[+1.862,+3.840]+0.521[−0.047,+1.090] SWE-Bench Pro+0.247[+0.128,+0.365]+0.752[+0.481,+1.022]−0.175[−0.324,−0.027] HealthBench+0.062[−0.088,+0....
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.