BaRA: Budget-constrained and Reliable Web Data Collection Agent
Pith reviewed 2026-07-02 23:59 UTC · model grok-4.3
The pith
BaRA combines bounded breadth-first search with history-based self-reflection to recover more valid links and downloadable media from websites than pure LLM or browser agents under the same interaction budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
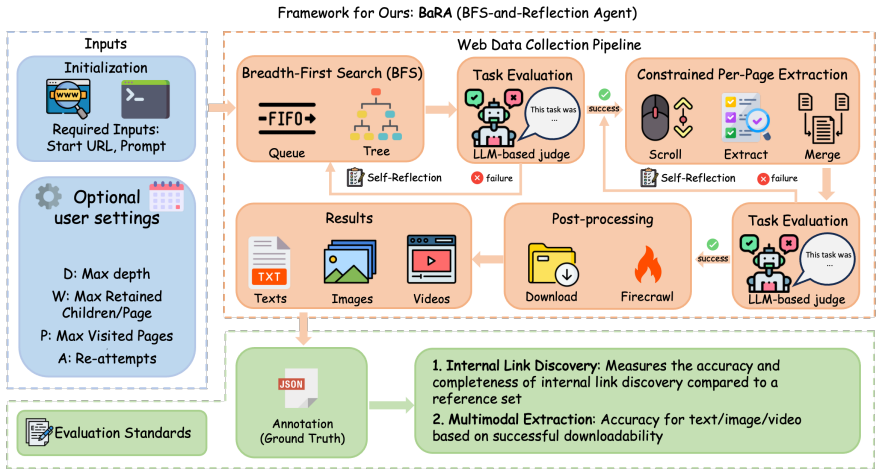
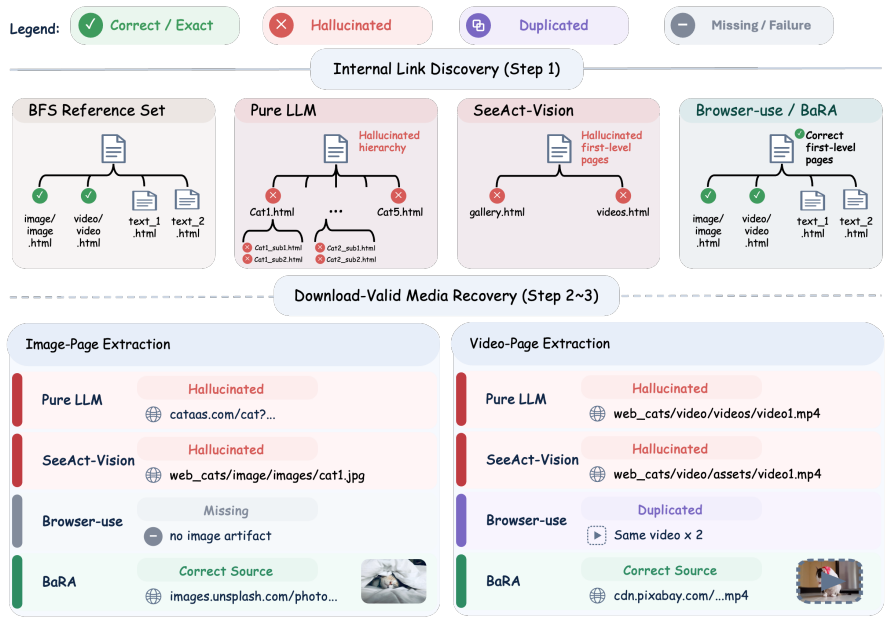
BaRA performs bounded breadth-first search combined with history-based self-reflection to traverse websites and extract links and media under a fixed interaction budget; on 50 synthetic websites with ground-truth sets and on three public sites, it exceeds the link discovery and downloadable multimodal extraction performance of Pure LLM, SeeAct-Vision, and Browser-use, with the largest improvements appearing in the recovery of images and videos that are directly downloadable.
What carries the argument
Bounded breadth-first search traversal paired with history-based self-reflection that decides next actions from past observations.
If this is right
- More complete site coverage becomes possible without writing custom scripts for each target website.
- The share of returned media URLs that actually resolve to downloadable files increases.
- Performance gains are largest on image and video recovery rather than text links alone.
- The same fixed budget constraint still yields measurable improvements on both synthetic and live public sites.
Where Pith is reading between the lines
- Similar bounded-search-plus-reflection patterns could be tested on other structured collection tasks such as product catalog scraping or academic paper harvesting.
- The method may reduce the frequency of manual re-scripting when website layouts change, provided the reflection step can be kept lightweight.
- Extending the budget-adaptive logic to multi-site campaigns would be a direct next measurement.
Load-bearing premise
The 50 synthetic websites plus three public sites sufficiently represent the range of real-world dynamic and cluttered layouts that the agent will encounter in deployment.
What would settle it
A new test set of websites containing navigation patterns or media embedding styles absent from the original 53 sites on which BaRA no longer exceeds the baselines in valid media recovery.
Figures
read the original abstract
Large language model (LLM)-based web agents automate web navigation and data collection. However, live web data collection demands capabilities beyond task completion: agents must discover site-internal pages and retrieve text, image, and video artifacts in an accessible form within a fixed interaction budget. We formulate this setting as budget-constrained, site-level multimodal web data collection and propose Budget-constrained and Reliable Agent (BaRA). BaRA performs breadth-first search (BFS)-based link discovery with liveness verification to filter hallucinated and dead links, then validates extracted multimodal artifacts using rule-based provenance and accessibility checks. A history-based self-reflection module recovers from execution failures and incomplete outputs. On controlled synthetic and real-world websites, BaRA consistently improves valid-link discovery and download-valid multimodal extraction over existing agents. Our code is available at https://github.com/MLAI-Yonsei/BaRA-Agent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BaRA, a BFS-and-Reflection Agent for web data collection that integrates bounded breadth-first search with history-based self-reflection to operate under a fixed interaction budget. It evaluates the approach on 50 synthetic websites equipped with ground-truth reference sets and three public websites featuring cluttered or dynamic layouts, claiming superior performance compared to Pure LLM, SeeAct-Vision, and Browser-use baselines in link discovery and downloadable multimodal extraction, with notable improvements in recovering valid images and videos. The code is made available at a GitHub repository.
Significance. Should the reported gains prove robust, BaRA offers a promising direction for reducing manual effort in web data collection tasks, particularly for multimodal content from complex sites. The release of the implementation code supports reproducibility and further research in LLM-based web agents.
major comments (2)
- [Evaluation] The manuscript does not detail the procedure for generating the 50 synthetic websites, any diversity or coverage metrics, or analysis of how well they represent real-world challenges such as heavy JavaScript execution, anti-bot mechanisms, or infinite scrolling. This omission is load-bearing because the central claim of outperformance rests on these test cases being representative.
- [Results] Quantitative results lack accompanying error bars, statistical significance tests, or explicit descriptions of how ground-truth sets were constructed and how download validity was judged, which weakens the ability to interpret the performance differences.
minor comments (1)
- [Abstract] The abstract would benefit from including key quantitative metrics or effect sizes to substantiate the performance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation methodology and results presentation. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Evaluation] The manuscript does not detail the procedure for generating the 50 synthetic websites, any diversity or coverage metrics, or analysis of how well they represent real-world challenges such as heavy JavaScript execution, anti-bot mechanisms, or infinite scrolling. This omission is load-bearing because the central claim of outperformance rests on these test cases being representative.
Authors: We agree that the manuscript would benefit from expanded details on synthetic site generation. In revision, we will add a subsection describing the generation procedure (template-based creation with controlled variations in JS execution, dynamic elements, and layout complexity), report diversity metrics (e.g., page counts, media distribution, depth), and explicitly discuss coverage of real-world challenges. We note that anti-bot mechanisms are not simulated in the synthetic set and are instead addressed via the three public website evaluations; this limitation will be stated clearly. revision: yes
-
Referee: [Results] Quantitative results lack accompanying error bars, statistical significance tests, or explicit descriptions of how ground-truth sets were constructed and how download validity was judged, which weakens the ability to interpret the performance differences.
Authors: We will revise the Evaluation and Results sections to include explicit descriptions of ground-truth construction (manual curation of reference link and media sets per site) and download validity judgment (HTTP response validation plus content-type verification). For error bars and significance tests, the original experiments used deterministic agent configurations; we will add a limitations paragraph and, where multiple runs are feasible without altering the fixed-budget protocol, report variance and basic statistical comparisons in the revision. revision: partial
Circularity Check
No circularity; empirical evaluation on independent benchmarks
full rationale
The paper presents an agent framework (bounded BFS + history-based reflection) evaluated directly on 50 synthetic sites with ground-truth sets plus three public sites. No equations, parameter fitting, or predictions are described that reduce to the inputs by construction. Outperformance claims rest on external comparisons rather than self-referential derivations or self-citation chains. This matches the default case of a self-contained empirical result.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.