Vera: A Layered Diffusion Model for Content-Preserving Video Editing
Pith reviewed 2026-06-26 09:23 UTC · model grok-4.3
The pith
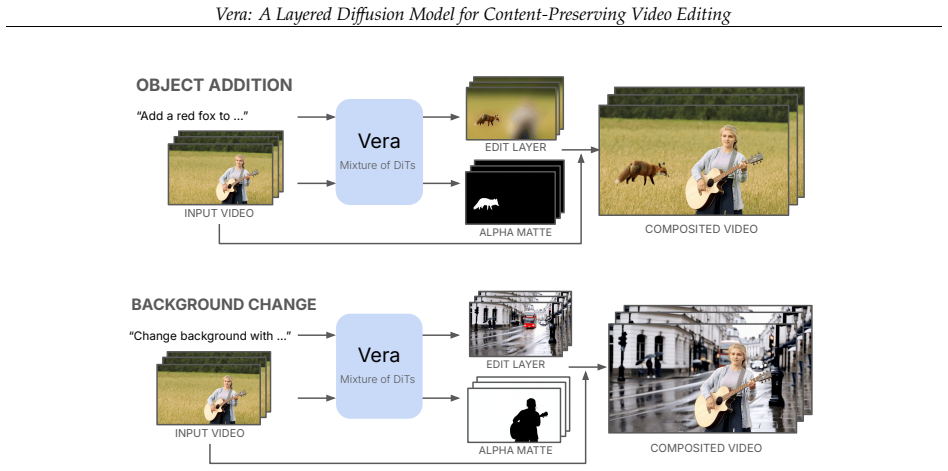
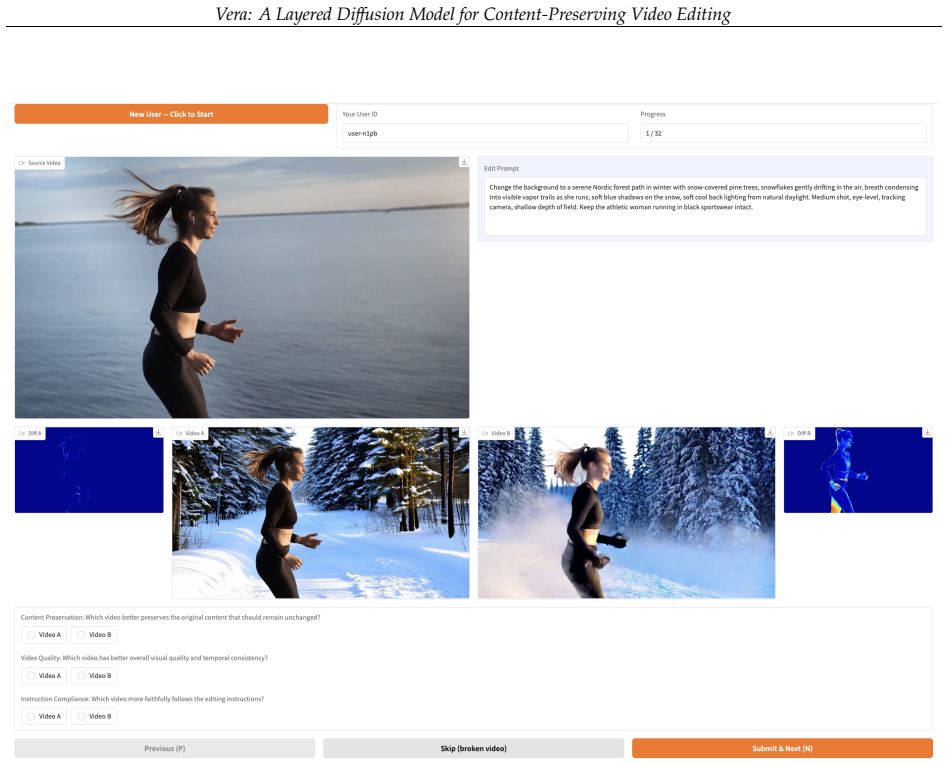
Vera edits videos by generating only a changeable layer plus alpha matte for compositing over the original footage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
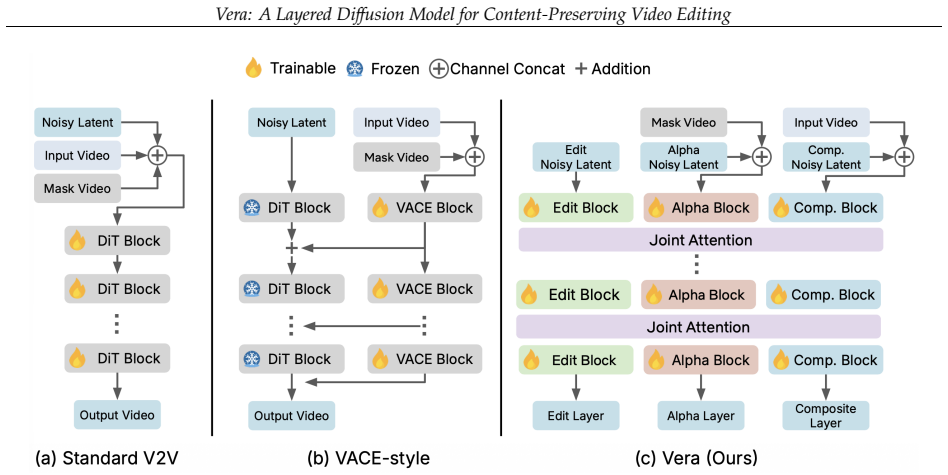
Vera generates an edit layer along with an alpha matte for compositing with the source video, using an extended Mixture-of-Transformers architecture in which separate DiTs for each layer interact through joint self-attention to encourage coherent composition.
What carries the argument
Mixture-of-Transformers architecture with joint self-attention between separate DiTs for the edit layer and source video.
If this is right
- Content preservation improves over full-regeneration methods while edit quality stays competitive.
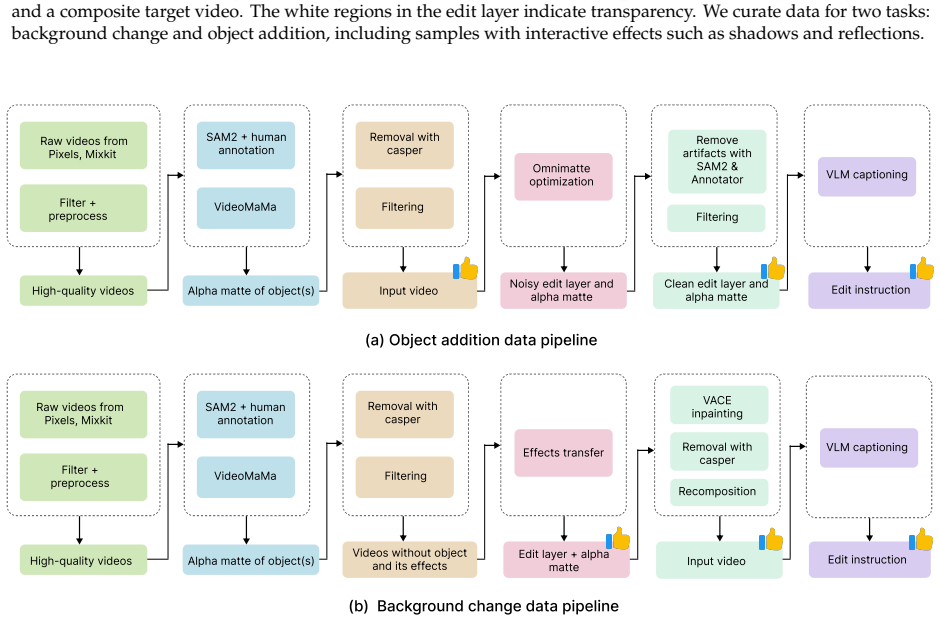
- The approach works with a training set of 486K frames of layered video data.
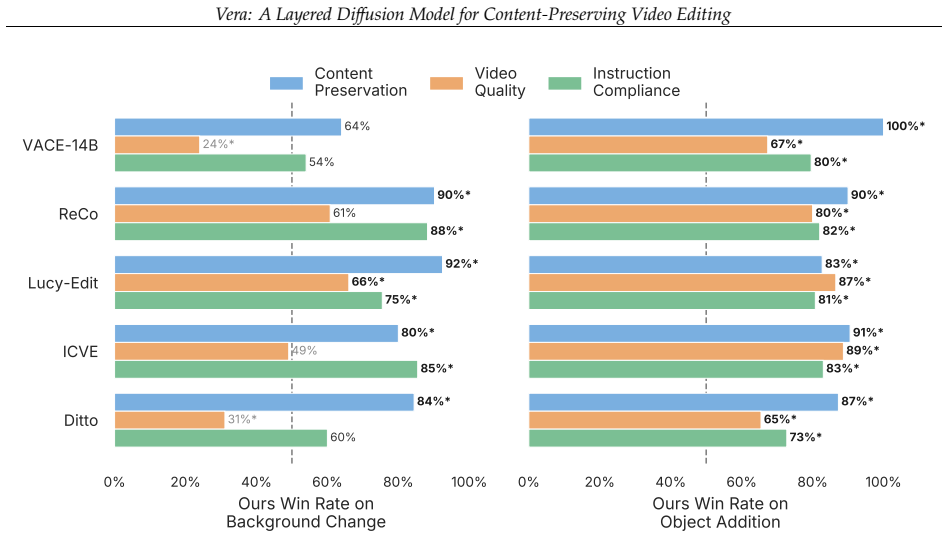
- Quantitative benchmarks and human studies show better preservation results than leading open-source editors.
- The layered output enables direct compositing without regenerating the full video.
Where Pith is reading between the lines
- The same separation of layers could reduce compute for long videos by editing only the changed parts.
- Training data requirements might limit quick adoption to new domains without similar layered collections.
- The method could extend to interactive editing where users adjust only the edit layer after initial generation.
Load-bearing premise
Joint self-attention between the two DiTs produces coherent composition without needing extra constraints or post-processing.
What would settle it
Test footage in which the generated edit layer shows mismatched lighting, shadows, or motion boundaries with the source video after compositing.
Figures







read the original abstract
Video diffusion models have enabled remarkable progress in video generation and editing. However, content preservation remains a core challenge: existing methods regenerate every pixel and often alter elements that should remain unchanged, such as characters or background scenes. We introduce Vera, a layered diffusion framework for content-preserving video editing. Instead of regenerating the entire video, Vera generates an edit layer along with an alpha matte for compositing with the source video, separating creative editing from content preservation by design. To encourage coherent composition with the source video, we extend the text-to-video DiT into a Mixture-of-Transformers (MoT) architecture, with separate DiTs for each layer that interact through joint self-attention. To support the training of Vera, we further construct a high-quality layered dataset with accurate alpha mattes, diverse scenes and dynamics, and visual effects. Across our quantitative benchmark and human preference study, Vera outperforms leading open-source video editing models in content preservation while remaining competitive in edit quality, using 486K frames of layered training data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Vera, a layered diffusion framework for content-preserving video editing. Instead of regenerating the full video, it generates an edit layer and alpha matte for compositing with the source video. The architecture extends text-to-video DiT models into a Mixture-of-Transformers (MoT) with separate DiTs for each layer that interact via joint self-attention. A new high-quality layered dataset of 486K frames with accurate alpha mattes is constructed to support training. The method reports outperforming leading open-source video editing models in content preservation on quantitative benchmarks and human preference studies while remaining competitive in edit quality.
Significance. If the results hold, the layered approach provides a principled way to separate creative editing from content preservation by design, which could reduce unwanted alterations to characters or backgrounds in video editing tasks. The large-scale layered dataset with mattes represents a concrete resource contribution that may benefit the broader community. The MoT extension for joint attention is a targeted architectural adaptation worth exploring further in diffusion-based video models.
major comments (1)
- [Abstract] Abstract: the central claim that joint self-attention in the MoT architecture is sufficient to produce coherent composition (and thereby separate editing from preservation by design) is not accompanied by any mention of explicit constraints, regularization, or auxiliary losses on the alpha matte or edit layer. This is load-bearing because, without such mechanisms, cross-layer attention alone may permit leakage that alters preserved content during denoising, directly undermining the architectural sufficiency argument.
minor comments (2)
- The abstract references a quantitative benchmark and human study but provides no specific metrics, error bars, or ablation details to quantify the claimed improvements in content preservation.
- The dataset construction is described at a high level (486K frames, diverse scenes, accurate mattes) but lacks specifics on sourcing, annotation process, or public release plans that would strengthen reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the concern point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that joint self-attention in the MoT architecture is sufficient to produce coherent composition (and thereby separate editing from preservation by design) is not accompanied by any mention of explicit constraints, regularization, or auxiliary losses on the alpha matte or edit layer. This is load-bearing because, without such mechanisms, cross-layer attention alone may permit leakage that alters preserved content during denoising, directly undermining the architectural sufficiency argument.
Authors: We agree that the abstract does not explicitly reference the training objective or any auxiliary terms. The full method section describes end-to-end training with the standard diffusion loss applied jointly to the predicted edit layer and alpha matte (conditioned on the source video via the MoT), using the 486K-frame layered dataset. The joint self-attention is presented as the primary mechanism for coherence, with no additional regularization losses introduced. We will revise the abstract to briefly note that training optimizes both outputs under the layered diffusion objective, which supports the separation-by-design claim while remaining accurate to the manuscript. revision: yes
Circularity Check
No circularity: architectural proposal with no derivations or self-referential predictions
full rationale
The paper presents Vera as an empirical architectural extension of text-to-video DiT models into a Mixture-of-Transformers (MoT) setup with joint self-attention for layered editing. No equations, first-principles derivations, fitted parameters renamed as predictions, or uniqueness theorems appear in the abstract or description. Claims rest on dataset construction (486K frames) and comparative evaluation rather than any reduction of outputs to inputs by construction. This is self-contained against external benchmarks with no load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
to obtain high-quality alpha mattes with accurate boundaries.(3) Object removal.Using the alpha mattes, we remove the selected object(s) from the video with a video object removal model (Casper-1.3B (Lee et al., 2025)) to obtain clean background videos. Since the removal model can occasionally produce artifacts, this stage includes a filtering step to dis...
2025
-
[2]
before" video (clean background without the object ) and an
to generate a synthetic background, which is then composited with the object using the alpha matte to produce the input video.(6) Captioning.We first use a VLM to generate detailed captions of both the objects andthescenefortheinputvideoandthetargetcompositeusingthesystempromptinFig.11. Thesecaptions are then provided to a separate VLM call (Fig. 12) to i...
2025
-
[3]
If multiple subjects are present, describe each one and how they relate spatially
Describe the subject(s) accurately - appearance, clothing, distinctive features. If multiple subjects are present, describe each one and how they relate spatially
-
[4]
Describe the motion with details - what each subject is doing, speed and intensity
-
[5]
Describe the environment with details - location, setting, background elements
-
[6]
Include lighting constraints - direction, quality, color temperature, source
-
[7]
Include camera constraints - shot size, focal length feel, angle, motion, background focus
-
[8]
Be specific - textures, colors, spatial relationships DON’T:
-
[9]
nice", "beautiful
Don’t use vague descriptors - avoid "nice", "beautiful", "interesting"
-
[10]
Don’t overcomplicate - one scene, one action, clear description
-
[11]
Don’t add interpretation - describe what you see, not what you infer
-
[12]
Don’t include JSON or structured formatting - output plain text only
-
[13]
depth of field
Never say "depth of field" - instead use the background focus phrases from the vocabulary (e.g., "blurred background", " soft bokeh", "sharp background", "deep focus"). The phrase you choose must be consistent with the actual background sharpness in the video - do not contradict yourself
-
[14]
cowboy shot
Always include focal length feel - wide-angle, normal, or telephoto Vocabulary Reference Shot sizes: extreme wide shot: Vast environment, subject very small or barely visible wide shot: Full body + significant environment around subject full shot: Head to toe, subject fills frame vertically medium wide shot: Knees up ("cowboy shot") medium shot: Waist up ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.