AlignFed: Alignment-Aware Asynchronous Federated Fine-Tuning for Large Language Models in Heterogeneous Edge Environments
Pith reviewed 2026-06-27 19:48 UTC · model grok-4.3
The pith
AlignFed aligns stale model updates across versions using a mini-batch calibration set to reduce drift and balance participation in asynchronous LLM fine-tuning on heterogeneous edges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
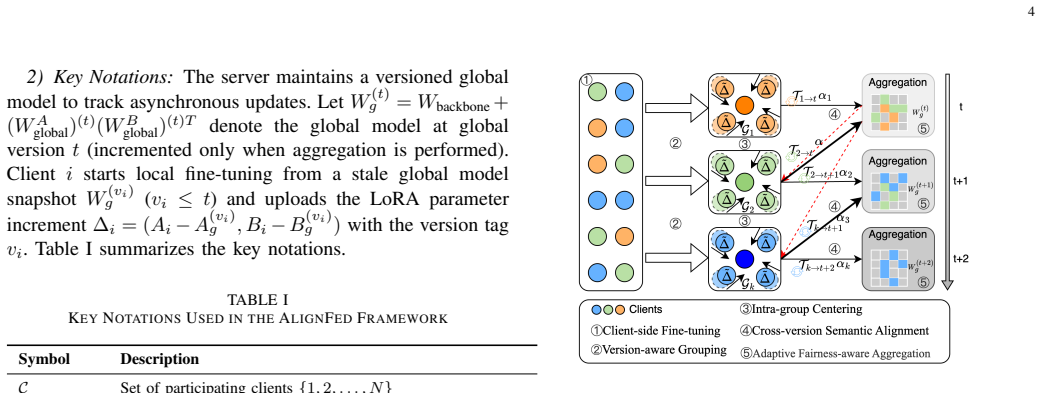
AlignFed is an asynchronous federated fine-tuning framework whose core is a lightweight multi-stage semantic alignment mechanism consisting of version-aware update grouping, cross-version semantic alignment performed on a mini-batch calibration set, and fairness-aware aggregation that combines update freshness with client participation frequency; this mechanism mitigates cross-version model drift, client drift from data heterogeneity, and aggregation fairness imbalance, enabling stable and efficient optimization even when update staleness is high.
What carries the argument
The multi-stage semantic alignment mechanism, whose cross-version step uses a mini-batch calibration set to correct semantic differences between stale and current model versions before aggregation.
If this is right
- Asynchronous aggregation becomes viable for LLM fine-tuning instead of being limited to smaller models.
- System latency drops because fast clients no longer wait for stragglers while still receiving fair credit.
- Aggregation no longer systematically favors clients with faster hardware or easier data.
- Training remains stable when update delays span many communication rounds.
Where Pith is reading between the lines
- The same alignment idea could be applied to other large models beyond language, such as vision or multimodal models on edges.
- If the calibration set must be updated over time, the framework might need an additional mechanism to keep the reference distribution current.
- Hardware heterogeneity could be further reduced by letting the alignment step also adjust for numerical precision differences across devices.
Load-bearing premise
A small shared mini-batch calibration set is representative enough to correct semantic drift from stale updates without adding bias or heavy computation on the edge devices.
What would settle it
Run the same asynchronous training with and without the cross-version alignment step on a fixed heterogeneous client set; if the version without alignment reaches within 1 percent of the aligned version's final accuracy or perplexity, the claimed mitigation of model drift does not hold.
Figures
read the original abstract
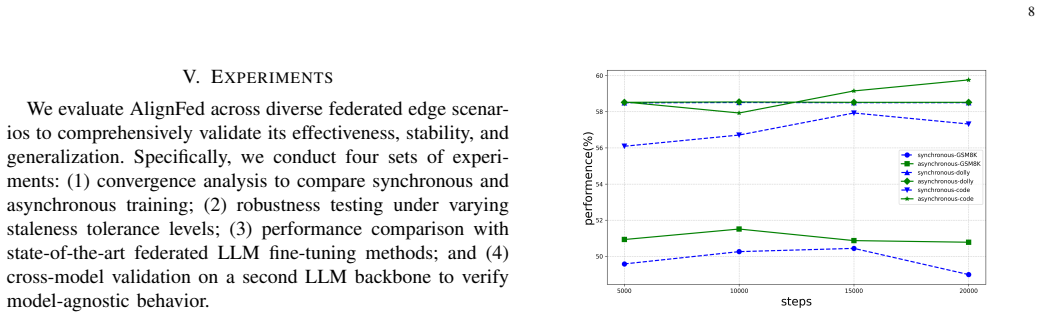
Large Language Models (LLMs) have significantly propelled the advancement of edge intelligence and have been widely deployed across various scenarios, including autonomous driving, industrial inspection, and personalized IoT services. However, the collaborative adaptation of LLMs on edge devices continues to face formidable challenges due to strict data privacy constraints, highly heterogeneous computing and communication resources, and the non-independent and identically distributed (non-IID) nature of local data. Federated Fine-Tuning (FFT) enables the collaborative optimization of distributed models without exposing raw data. Yet, traditional synchronous aggregation suffers from a severe straggler effect, resulting in high system latency and low resource utilization. Existing asynchronous federated learning methods are predominantly designed for small-to-medium-scale models and struggle to address the specific challenges inherent in LLM fine-tuning namely, model drift caused by stale updates, aggravated client drift stemming from data heterogeneity, and aggregation fairness imbalance resulting from the dominance of fast clients. To address these issues, this paper proposes AlignFed, an asynchronous federated fine-tuning framework for LLMs tailored to heterogeneous edge environments. AlignFed employs a lightweight multi-stage semantic alignment mechanism comprising three core modules: version-aware update grouping, cross-version semantic alignment based on a mini-batch calibration set, and fairness-aware aggregation that integrates both update freshness and client participation frequency. This framework effectively mitigates cross-version model drift and client drift while enhancing aggregation fairness, thereby achieving stable and efficient asynchronous federated optimization in scenarios characterized by high heterogeneity and significant update staleness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AlignFed, an asynchronous federated fine-tuning framework for large language models in heterogeneous edge environments. It introduces three core modules: version-aware update grouping, cross-version semantic alignment based on a mini-batch calibration set, and fairness-aware aggregation integrating update freshness and client participation frequency. The framework is claimed to mitigate cross-version model drift, client drift, and aggregation unfairness to achieve stable and efficient optimization under high heterogeneity and update staleness.
Significance. If the proposed mechanisms prove effective, AlignFed could significantly advance federated learning for LLMs on resource-constrained edge devices by addressing key issues like straggler effects and data heterogeneity that plague synchronous and existing asynchronous methods. The semantic alignment approach using calibration sets offers a potentially lightweight way to handle model staleness in large models.
major comments (2)
- [Abstract] Abstract: the central claim that the three-module design 'effectively mitigates cross-version model drift and client drift while enhancing aggregation fairness' is unsupported. The manuscript describes the modules at a high level but contains no experiments, tables, figures, metrics on drift reduction or fairness, ablation studies, or theoretical bounds.
- [Abstract] Abstract: the assumption that a mini-batch calibration set suffices for cross-version semantic alignment without introducing bias or excessive edge-device cost is presented without analysis or validation, yet this is load-bearing for the drift-mitigation claim.
minor comments (1)
- The abstract is dense; the module descriptions could be broken into shorter sentences or a structured list for improved readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where the manuscript's claims require stronger substantiation. We address each point below and will revise the manuscript to incorporate the requested experimental validation and analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the three-module design 'effectively mitigates cross-version model drift and client drift while enhancing aggregation fairness' is unsupported. The manuscript describes the modules at a high level but contains no experiments, tables, figures, metrics on drift reduction or fairness, ablation studies, or theoretical bounds.
Authors: We agree that the abstract asserts effectiveness without accompanying empirical or theoretical support in the current manuscript. The text provides only a high-level description of the version-aware update grouping, cross-version semantic alignment, and fairness-aware aggregation modules. In the revised version, we will add a dedicated experimental section with quantitative metrics on drift reduction (e.g., model and client drift measures), fairness indicators, ablation studies isolating each module, performance tables/figures, and any applicable theoretical bounds or analysis to substantiate the claims. revision: yes
-
Referee: [Abstract] Abstract: the assumption that a mini-batch calibration set suffices for cross-version semantic alignment without introducing bias or excessive edge-device cost is presented without analysis or validation, yet this is load-bearing for the drift-mitigation claim.
Authors: The manuscript presents the mini-batch calibration set as a lightweight component for semantic alignment but indeed provides no analysis of bias introduction or edge-device computational/communication overhead. We will revise the paper to include a new subsection with validation: empirical measurements of overhead on representative edge hardware, bias assessment (e.g., via distribution comparisons or alignment quality metrics), and discussion of why the mini-batch size suffices under the stated heterogeneity assumptions. revision: yes
Circularity Check
No derivation chain or equations present; central claim is descriptive framework proposal only
full rationale
The manuscript presents AlignFed as a three-module framework (version-aware grouping, cross-version semantic alignment on mini-batch calibration set, fairness-aware aggregation) whose effectiveness is asserted in the abstract and introduction. No equations, derivations, proofs, fitted parameters, or self-citations of uniqueness theorems appear in the provided text. The claim that the design 'effectively mitigates cross-version model drift and client drift' is a high-level assertion without reduction to any input quantity by construction. Because no load-bearing mathematical step exists that could be circular, the circularity score is 0 and the derivation (such as it is) is self-contained as an engineering proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Strict data privacy, high resource heterogeneity, and non-IID local data create severe straggler effects and model drift in synchronous and existing asynchronous federated fine-tuning of LLMs.
invented entities (3)
-
version-aware update grouping
no independent evidence
-
cross-version semantic alignment based on mini-batch calibration set
no independent evidence
-
fairness-aware aggregation integrating update freshness and client participation frequency
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Foundation models for autonomous driving perception: A survey through core capabilities,
R. Sathyam and Y . Li, “Foundation models for autonomous driving perception: A survey through core capabilities,”IEEE Open Journal of Vehicular Technology, 2025
2025
-
[2]
Edgeshard: Efficient llm inference via collaborative edge computing,
M. Zhang, X. Shen, J. Cao, Z. Cui, and S. Jiang, “Edgeshard: Efficient llm inference via collaborative edge computing,”IEEE Internet of Things Journal, 2024
2024
-
[3]
Large language models empowered autonomous edge ai for connected intelligence,
Y . Shen, J. Shao, X. Zhang, Z. Lin, H. Pan, D. Li, J. Zhang, and K. B. Letaief, “Large language models empowered autonomous edge ai for connected intelligence,”IEEE Communications Magazine, vol. 62, no. 10, pp. 140–146, 2024
2024
-
[4]
Pruning-Based Adaptive Federated Learning at the Edge ,
D. Yu, Y . Yuan, Y . Zou, X. Zhang, Y . Liu, L. Cui, and X. Cheng, “ Pruning-Based Adaptive Federated Learning at the Edge ,”IEEE Transactions on Computers, vol. 74, no. 05, pp. 1538–1548, May
-
[5]
Available: https://doi.ieeecomputersociety.org/10.1109/ TC.2025.3533095
[Online]. Available: https://doi.ieeecomputersociety.org/10.1109/ TC.2025.3533095
arXiv 2025
-
[6]
Enabling Optical Network Technologies for 5G and Beyond,
J. Zhang, S. Guo, Z. Qu, D. Zeng, Y . Zhan, Q. Liu, and R. Akerkar, “ Adaptive Federated Learning on Non-IID Data With Resource Constraint ,”IEEE Transactions on Computers, vol. 71, no. 07, pp. 1655–1667, Jul. 2022. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/TC.2021.3099723
-
[7]
Improving lora in privacy-preserving federated learning,
Y . Sun, Z. Li, Y . Li, and B. Ding, “Improving lora in privacy-preserving federated learning,”arXiv preprint arXiv:2403.12313, 2024
arXiv 2024
-
[8]
Asymmetrically Decentralized Federated Learning ,
Q. Li, M. Zhang, N. Yin, Q. Yin, L. Shen, and X. Cao, “ Asymmetrically Decentralized Federated Learning ,”IEEE Transactions on Computers, vol. 74, no. 08, pp. 2745–2756, Aug. 2025. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/TC.2025.3569185
-
[9]
Fed-raa: Resource-adaptive asynchronous federated edge learning with theoretical guarantee,
R. Zhang, X. Wu, Y . Zou, Z. Xie, P. Li, X. Cheng, F. Dressler, and D. Yu, “Fed-raa: Resource-adaptive asynchronous federated edge learning with theoretical guarantee,”IEEE Transactions on Mobile Computing, 2025
2025
-
[10]
Computation offloading for edge-assisted federated learning,
Z. Ji, L. Chen, N. Zhao, Y . Chen, G. Wei, and F. R. Yu, “Computation offloading for edge-assisted federated learning,”IEEE Transactions on Vehicular Technology, vol. 70, no. 9, pp. 9330–9344, 2021
2021
-
[11]
S. Zheng, Z. Zhang, Y . Deng, G. Min, and L. Cui, “ Communication-Efficient Federated Learning by Exploiting Spatio- Temporal Correlations of Gradients ,”IEEE Transactions on Computers, vol. 75, no. 04, pp. 1433–1445, Apr. 2026. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/TC.2026.3654074
-
[12]
Distributed fed- erated learning for ultra-reliable low-latency vehicular communications,
S. Samarakoon, M. Bennis, W. Saad, and M. Debbah, “Distributed fed- erated learning for ultra-reliable low-latency vehicular communications,” IEEE Transactions on Communications, vol. 68, no. 2, pp. 1146–1159, 2019
2019
-
[13]
Fedlc: Accelerating asynchronous federated learning in edge computing,
Y . Xu, Z. Ma, H. Xu, S. Chen, J. Liu, and Y . Xue, “Fedlc: Accelerating asynchronous federated learning in edge computing,”IEEE Transactions on Mobile Computing, vol. 23, no. 5, pp. 5327–5343, 2023
2023
-
[14]
Asynchronous federated optimiza- tion,
C.-S. Xie, S. Koyejo, and I. Gupta, “Asynchronous federated optimiza- tion,” inProceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS), 2019, pp. 2021–2030
2019
-
[15]
Federated learning with buffered asynchronous aggregation,
D. C. Nguyen, M. Ding, P. N. Pathirana, and A. Seneviratne, “Federated learning with buffered asynchronous aggregation,” inProceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2022, pp. 2146–2154
2022
-
[16]
Syncfed: Time- aware federated learning through explicit timestamping and synchro- nization,
B. C. G ¨ul, S. Tziampazis, N. Jazdi, and M. Weyrich, “Syncfed: Time- aware federated learning through explicit timestamping and synchro- nization,”arXiv preprint arXiv:2506.09660, 2025
arXiv 2025
-
[17]
Asynchronous federated learning with non-convex client objective functions and heterogeneous dataset,
A. Forootani and R. Iervolino, “Asynchronous federated learning with non-convex client objective functions and heterogeneous dataset,”IEEE Transactions on Artificial Intelligence, 2025
2025
-
[18]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[19]
On the origins of linear representations in large language models,
Y . Jiang, G. Rajendran, P. Ravikumar, B. Aragam, and V . Veitch, “On the origins of linear representations in large language models,”arXiv preprint arXiv:2403.03867, 2024
arXiv 2024
-
[20]
Orthogonal calibration for asynchronous federated learning,
J. Zhang, S. Li, H. Huang, X. Yu, R. K. Gupta, and J. Shang, “Orthogonal calibration for asynchronous federated learning,”arXiv preprint arXiv:2502.15940, 2025
arXiv 2025
-
[21]
D. Solans, M. Heikkila, A. Vitaletti, N. Kourtellis, A. Anagnostopoulos, I. Chatzigiannakiset al., “Non-iid data in federated learning: A survey with taxonomy, metrics, methods, frameworks and future directions,” arXiv preprint arXiv:2411.12377, 2024
arXiv 2024
-
[22]
Mitigating participation imbalance bias in asynchronous federated learning under client heterogeneity,
X. Chang, M. Yao, S. Krishnamurthy, C. R. Shelton, A. Chakraborty, A. Swami, S. Oymak, and A. Roy-Chowdhury, “Mitigating participation imbalance bias in asynchronous federated learning under client heterogeneity,” 2026. [Online]. Available: https://openreview.net/forum? id=JOeW5Jg7ye
2026
-
[23]
Fadas: Towards federated adaptive asynchronous optimization,
Y . Wang, S. Wang, S. Lu, and J. Chen, “Fadas: Towards federated adaptive asynchronous optimization,”arXiv preprint arXiv:2407.18365, 2024
arXiv 2024
-
[24]
J. Ma, A. Tu, Y . Chen, and V . J. Reddi, “Fedstaleweight: Buffered asynchronous federated learning with fair aggregation via staleness reweighting,”arXiv preprint arXiv:2406.02877, 2024
arXiv 2024
-
[25]
Asynchronous federated learning: A scal- able approach for decentralized machine learning,
A. Forootani and R. Iervolino, “Asynchronous federated learning: A scal- able approach for decentralized machine learning,”IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2026
2026
-
[26]
Feddm: A discrepancy-aware federated learning method based on multi-branch feature fusion for non-iid data environments,
W. Liu, J. Chen, B. Wang, G. Zai, W. She, and Z. Tian, “Feddm: A discrepancy-aware federated learning method based on multi-branch feature fusion for non-iid data environments,”IEEE Internet of Things Journal, 2025
2025
-
[27]
Adaptive parameter- efficient federated fine-tuning on heterogeneous devices,
J. Liu, Y . Liao, H. Xu, Y . Xu, J. Liu, and C. Qian, “Adaptive parameter- efficient federated fine-tuning on heterogeneous devices,”IEEE Trans- actions on Mobile Computing, 2025
2025
-
[28]
Fedpetuning: When federated learning meets parameter-efficient tuning,
X. Yuan, R. Xu, X. Yu, C. Xu, S. Jiet al., “Fedpetuning: When federated learning meets parameter-efficient tuning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 11 740–11 749
2023
-
[29]
Fedlora: Efficient federated fine-tuning of large language models via low-rank adaptation,
H. Zhang, W. Liu, C. Zhang, Y . Xu, and F. Li, “Fedlora: Efficient federated fine-tuning of large language models via low-rank adaptation,” IEEE Transactions on Neural Networks and Learning Systems, 2025, early Access
2025
-
[30]
Federated lora with sparse communication,
K. Kuo, A. Raje, K. Rajesh, and V . Smith, “Federated lora with sparse communication,”arXiv preprint arXiv:2406.05233, 2024
arXiv 2024
-
[31]
Lori: Reducing cross- task interference in multi-task low-rank adaptation,
J. Zhang, J. You, A. Panda, and T. Goldstein, “Lori: Reducing cross- task interference in multi-task low-rank adaptation,”arXiv preprint arXiv:2504.07448, 2025
arXiv 2025
-
[32]
Selective aggre- gation for low-rank adaptation in federated learning,
P. Guo, S. Zeng, Y . Wang, H. Fan, F. Wang, and L. Qu, “Selective aggre- gation for low-rank adaptation in federated learning,” inThe 13th Inter- national Conference on Learning Representations (ICLR)(24/04/2025- 28/04/2025, Singapore), 2025
2025
-
[33]
Communication-efficient federated learning via knowledge distillation,
C. Wu, F. Wu, L. Lyu, Y . Huang, and X. Xie, “Communication-efficient federated learning via knowledge distillation,”Nature communications, vol. 13, no. 1, p. 2032, 2022
2032
-
[34]
Robust federated learning through representation matching and adaptive hyper-parameters,
H. Mostafa, “Robust federated learning through representation matching and adaptive hyper-parameters,”arXiv preprint arXiv:1912.13075, 2019
arXiv 1912
-
[35]
Fed2: Feature-aligned federated learning,
F. Yu, W. Zhang, Z. Qin, Z. Xu, D. Wang, C. Liu, Z. Tian, and X. Chen, “Fed2: Feature-aligned federated learning,” inProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining, 2021, pp. 2066–2074
2021
-
[36]
Agnostic federated learning,
M. Mohri, G. Sivek, and A. T. Suresh, “Agnostic federated learning,” inICML, 2019
2019
-
[37]
Fair resource allocation in federated learning,
T. Li, A. K. Sahu, A. Talwalkar, and V . Smith, “Fair resource allocation in federated learning,” inICLR, 2019
2019
-
[38]
Fair federated learning under domain skew with local consistency and domain diversity,
Y . Chen, W. Huang, and M. Ye, “Fair federated learning under domain skew with local consistency and domain diversity,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12 077–12 086
2024
-
[39]
Fair federated learning with biased vision-language models,
H. Zeng, Z. Yue, Y . Zhang, L. Shang, and D. Wang, “Fair federated learning with biased vision-language models,” inFindings of the As- sociation for Computational Linguistics ACL 2024, 2024, pp. 10 002– 10 017
2024
-
[40]
Semantic-aware wasserstein policy regularization for large language model alignment,
B. Na, H. Na, Y . Kim, S. Jo, H. Bae, M. Kang, and I.-C. Moon, “Semantic-aware wasserstein policy regularization for large language model alignment,”arXiv preprint arXiv:2602.01685, 2026
arXiv 2026
-
[41]
A step toward federated pretraining of multimodal large language models,
B. Xiong, Y . Xu, X. Yang, Y . Song, Y . Wang, and C. Xu, “A step toward federated pretraining of multimodal large language models,” arXiv preprint arXiv:2603.26786, 2026
arXiv 2026
-
[42]
Federatedscope-llm: A comprehensive package for fine-tuning large language models in federated learning,
W. Kuang, B. Qian, Z. Li, D. Chen, D. Gao, X. Pan, Y . Xie, Y . Li, B. Ding, and J. Zhou, “Federatedscope-llm: A comprehensive package for fine-tuning large language models in federated learning,” inProceed- ings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 5260–5271. 11
2024
-
[43]
Training verifiers to solve math word problems,
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakanoet al., “Training verifiers to solve math word problems,”arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[44]
Code alpaca: An instruction-following llama model for code generation,
S. Chaudhary, “Code alpaca: An instruction-following llama model for code generation,” GitHub Repository, 2023, accessed: 2025-06-02. [Online]. Available: https://github.com/sahil280114/codealpaca
2023
-
[45]
Free dolly: Introducing the world’s first truly open instruction-tuned llm,
M. Conover, M. Hayes, A. Mathur, J. Xie, J. Wan, S. Shah, A. Ghodsi, P. Wendell, M. Zaharia, and R. Xin, “Free dolly: Introducing the world’s first truly open instruction-tuned llm,” Databricks Blog, 2023, accessed: 2025-06-02. [Online]. Available: https://www.databricks.com/blog/2023/ 04/12/dolly-first-open-commercially-viable-instruction-tuned-llm
2023
-
[46]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial intelligence and statistics. PMLR, 2017, pp. 1273– 1282. 12 APPENDIX A. Proof of Lemma IV .1 Proof.Step 1.From the global update rule: W (k+1) g =W (k) g +η∆ (k) g .(19) By (A5) and convex combination: ∥...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.